多标签分类(二):Deep Learning with a Rethinking Structure for Multi-label Classification
深度学习与反思结构的多标签分类
摘要
多标签分类(MLC)是一类重要的机器学习问题,涉及广泛的应用程序,每个应用程序都可能要求不同的评估标准。在解决MLC问题时,我们通常希望学习算法能够考虑到标签之间隐藏的相关性来提高预测性能,提取标签之间隐藏的相关性通常是一项艰巨的任务。在这项工作中,我们提出了一种新颖的深度学习框架,以借助递归神经网络中的内存结构更好地提取隐藏的相关性。存储器将临时猜测存储在标签上,并有效地使框架能够在做出最终预测之前重新考虑猜测的优劣和相关性。 此外,通过重新考虑(Rethinking)过程,可以轻松地适应不同的评估标准,以满足实际应用的需求。 特别是,可以针对任何给定的MLC评估标准以端到端的方式训练此框架。端到端设计可以与其他深度学习技术无缝结合,以解决诸如图像标记之类的具有挑战性的MLC问题。 在许多真实数据集上的实验结果证明,反思(Rethinking)框架确实在不同的评估标准下提高了MLC的性能,并且优越的性能超过最先进的MLC算法。
1、介绍
人类通过反复研究和思考同一个问题来掌握解决特定问题的技能。当一个难题出现在我们面前时,我们的脑海中会出现多次尝试来模拟不同的可能性。在这段时间里,我们对问题的理解加深了,这使得我们最终能够提出更好的解决方案。更深层次的理解来自于我们记忆中的一块巩固的知识,它记录了我们在“反思”尝试过程中如何通过处理和预测来构建问题环境。以上的人反思模型启发我们设计一种新的机器反思深度学习模型,该模型配备了一个记忆结构,以更好地解决多标签分类(MLC)问题。MLC问题的目标是同时将多个相关标签附加到一个输入实例中,并匹配各种应用场景,例如用情感子集标记歌曲或用对象标记图像。MLC应用程序通常带有一个重要的属性,称为标签相关性,例如,当给歌曲贴上情绪标签时,“愤怒”与“快乐”呈负相关;当标记图像时,桌面计算机的存在可能意味着键盘和鼠标的共存(计算机桌面含有的东西),许多现有的MLC工作隐式或显式地将标签相关性考虑在内,以更好地解决MLC问题。
在解决MLC问题时,标签相关性对人类也很重要,例如,在进入一个新房间解决图像标记任务时,我们可能会在第一眼看到一些更明显的物体,比如沙发,餐桌,木地板,这样的物件组合让我们联想到一个客厅,让我们更好地认识到沙发上的“鹅”是毛绒玩具,而不是真的鹅。从沙发到客厅再到毛绒玩具的识别路线需要逐步重新思考预测的相关性。我们提出的机器反思模型模拟了这种人的再思考过程,以消化标签相关性,更准确地解决MLC问题。
接下来,我们介绍一些有代表性的MLC算法,然后将它们与我们提出的机器再思考模型联系起来。二进制相关性(BR) 是一种基本的MLC算法,不考虑标签相关性。对于每个标签,BR学习一个二值分类器来独立预测标签的相关性。分类器链(CC) 通过考虑一些标签相关性扩展了BR。CC将二进制分类器链接为一个链,并将早期分类器的预测作为特性提供给后一个分类器。因此,后面的分类器因此可以利用较早的预测(与之相关)来形成更好的预测。
分类器链介绍:分类器链中的第一个分类器只在输入数据上进行训练,然后每个分类器都在输入空间和链上的所有之前的分类器上进行训练,例如在下面给出的数据集里,我们将X作为输入空间,而Y作为标签。
 在分类器链中,将多标签问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量
在分类器链中,将多标签问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量
 CC(分类器链)的设计可以看作是一种存储早期分类器的标签预测的内存机制。卷积神经网络递归神经网络(CNNRNN) 和带视觉注意力的无顺序神经网络(Att-RNN)算法通过更复杂的基于记忆的模型递归神经网络(RNN)取代机制,对CC进行了扩展。此外,采用RNN可以使算法通过与其他深度学习架构(如CNN-RNN中的卷积神经网络)进行端到端训练,更有效地解决图像标记等任务。
CC(分类器链)的设计可以看作是一种存储早期分类器的标签预测的内存机制。卷积神经网络递归神经网络(CNNRNN) 和带视觉注意力的无顺序神经网络(Att-RNN)算法通过更复杂的基于记忆的模型递归神经网络(RNN)取代机制,对CC进行了扩展。此外,采用RNN可以使算法通过与其他深度学习架构(如CNN-RNN中的卷积神经网络)进行端到端训练,更有效地解决图像标记等任务。
据报道,上述利用标签相关性的CC系列算法比BR具有更好的性能。但是,由于预测是在链内顺序进行的,因此这些算法通常会遇到标签排序问题。特别是,位于链的不同位置的分类器接收不同级别的信息,最后一个分类器使用来自其他分类器的所有信息进行预测,而第一个分类器的标签预测不使用其他信息。Att-RNN(论文是 Order-free RNN with visual attention for multi-label classification)通过波束搜索近似标签的最优排序解决了这个问题,而基于动态规划的分类器链(CC-DP) (论文是 On the optimality of classifier chain for multi-label classification)通过动态规划搜索最优排序。Att-RNN和CC-DP在搜索最优排序时都很耗时,即使确定了一个很好的排序,在预测过程中标签相关信息仍然不能平均共享。
我们提出的深度学习模型,称为RethinkNet,通过以不同的方式查看CC来解决标签排序问题。将cc族算法作为基于早期分类器的部分预测的再思考模型,我们建议在再思考过程中完全记住所有分类器的临时预测。也就是说,我们不是形成一个二进制分类器链,而是形成一个多标签分类器链,作为一个重新思考的序列。RethinkNet学会在链的早期分类器中形成初步的猜测,将这些猜测存储在内存中,然后在后面的分类器中使用标签相关性纠正这些猜测。与CNN-RNN和Att-RNN相似,RethinkNet采用RNN进行基于内存的顺序预测。我们为RethinkNet设计了一个全局内存来存储关于标签相关性的信息,该全局内存允许所有分类器共享相同的信息,而不受标签排序问题的影响。
RethinkNet的另一个优势是解决现实世界中对成本敏感的多标签分类(CSMLC)的重要需求。(论文对应:Condensed filter tree for cost-sensitive multi-label
classification) 特别是,不同的MLC应用程序通常需要不同的评估标准。 为了在广泛的应用范围内得到广泛的应用,因此设计CSMLC算法是很重要的,该算法在学习过程中考虑了标准(成本),从而能够轻松适应不同的成本。最先进的CSMLC算法包括压缩滤波树(CFT) 和概率分类链(PCC),PCC通过根据准则进行贝叶斯最优预测,将CC扩展到CSMLC,CFT也是由CC扩展而来,但在CC内训练每个二分类器时,通过将准则转换为重要度权值实现了代价敏感性。CFT中的转换步骤通常需要了解所有分类器的预测,这些预测已轻松存储在内存或RethinkNet中。 因此,RethinkNet可以轻松地与CFT中的重要性加权概念相结合,以实现成本敏感性.
在真实世界的数据集上进行的广泛实验验证了RethinkNet确实在不同的评估标准下提高了MLC的性能,并且优于目前最先进的MLC和CSMLC算法。此外,在图像标记方面,实验结果表明RethinkNet的性能优于CNN-RNN和Att-RNN。结果证明了RethinkNet的有效性。
2、准备工作
在多标签分类(MLC)问题中,目标是将多个标签附加到一个特征向量
x ∈ X ⊆ R d x \in \mathcal{X}\subseteq \Bbb{R}^{d} x∈X⊆Rd,其中 x x x为 d d d维向量。假设总共有 K K K个标签,标签由标签向量表示 y ∈ Y ⊆ { 0 , 1 } K y\in \mathcal{Y}\subseteq\{0,1\}^{K} y∈Y⊆{0,1}K,当且仅当第 k k k个标签与 x x x相关时,第 k k k位 y [ k ] = 1 y[k] = 1 y[k]=1,我们分别称 X \mathcal{X} X和 Y \mathcal{Y} Y为特征空间和标签空间.
训练时,MLC算法取训练数据集 D = ( x n , y n ) n = 1 N \mathcal{D}={(x_{n},y_{n})}_{n=1}^{N} D=(xn,yn)n=1N,数据集中包含 N N N个例子, x n ∈ X , y n ∈ Y x_{n}\in\mathcal{X},y_{n}\in\mathcal{Y} xn∈X,yn∈Y来学习一个分类器: f : X → Y f:\mathcal{X}\rightarrow\mathcal{Y} f:X→Y,分类器将一个特征向量 x ∈ X x \in \mathcal{X} x∈X映射到其在 Y \mathcal{Y} Y中的预测标签向量。从生成训练数据集 D \mathcal{D} D的同一分布中提取 N ˉ \bar{N} Nˉ个测试示例 { ( x n ˉ , y n ˉ , ) } n = 1 N ˉ \{(\bar{x_{n}},\bar{y_{n}},)\}_{n=1}^{\bar{N}} {(xnˉ,ynˉ,)}n=1Nˉ,MLC算法的目标是学习一个分类器 f f f,使预测的向量 { y ^ n } n = 1 N ˉ = { f ( x n ˉ ) } n = 1 N ˉ \{\hat{y}_{n}\}_{n=1}^{\bar{N}}=\{f(\bar{x_{n}})\}_{n=1}^{\bar{N}} {y^n}n=1Nˉ={f(xnˉ)}n=1Nˉ使得 { y ^ n } n = 1 N ˉ \{\hat{y}_{n}\}_{n=1}^{\bar{N}} {y^n}n=1Nˉ与真实向量 { y ˉ n } n = 1 N ˉ \{\bar{y}_{n}\}_{n=1}^{\bar{N}} {yˉn}n=1Nˉ接近。
标签向量之间的接近程度通过评估标准进行衡量,不同的应用程序可能需要不同的评估标准,这需要更通用的设置,被称为成本敏感的多标签分类(CSMLC)。 在这项工作中,我们遵循先前工作的背景,并考虑特定的评估标准系列,这套标准用于衡量单个预测向量 y ^ \hat{y} y^和单个地面真实向量 y y y之间的接近度,具体来说,这些标准可以写成成本函数 C : Y × Y → R C:\mathcal{Y}\times \mathcal{Y}\rightarrow\Bbb{R} C:Y×Y→R,其中 C ( y , y ^ ) C(y,\hat{y}) C(y,y^)表示将 y y y预测为 y ^ \hat{y} y^的成本(差),这样,可以通过测试示例上的平均成本 1 N ∑ n = 1 N ˉ C ( y n ˉ , y n ^ ) \frac{1}{N}\sum_{n=1}^{\bar{N}}C(\bar{y_{n}},\hat{y_{n}}) N1∑n=1NˉC(ynˉ,yn^)来评估分类器f
在CSMLC设置中,我们假设在训练之前就知道评估标准,即CSMLC算法可以通过训练数据集 D D D和成本函数 C C C来学习 f f f,并且应该能够轻松地适应不同的 C C C,通过使用这些额外的成本信息,CSLMC算法旨在将测试数据集 E ( x , y ) ∼ D [ C ( y , f ( x ) ) ] \Bbb{E}_{(x,y)\sim\mathcal{D}}[C(y,f(x))] E(x,y)∼D[C(y,f(x))]的预期成本降至最低。常见的成本函数如下。常见成本函数如下所示。 请注意,一些常见的“成本”函数使用较高的输出来表示更好的预测-我们称这些为‘得分函数’,为了将其与使用较低输出表示较好的预测的常规成本(损失)函数区分开来:
∙ H a m m i n g \bullet Hamming ∙Hamming l o s s loss loss(汉明损失)
表示所有label中错误样本的比例,所以该值越小则网络的分类能力越强
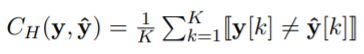
它直接统计了被误分类label的个数(不属于这个样本的标签被预测,或者属于这个样本的标签没有被预测)。为0表示所有的每一个data的所有label都被分对了
∙ F 1 \bullet F1 ∙F1 score

它同时兼顾了分类模型的精确率和召回率,其中 ∥ y ∥ 1 \left \|y\right\|_{1} ∥y∥1实际上就等于在标签向量 y y y中1的个数。
(额外补充):精确率和召回率都可以从这篇文章中着手:https://www.jianshu.com/p/1afbda3a04ab,文章中将飞机上的恐怖分子作为正例,将一般的乘客作为反例,由于恐怖分子数量极低,呈现出来的是不平衡分类。
真正例(TP):实际上是正例的数据点被标记为正例(实际是恐怖分子,被标记为恐怖分子)
假正例(FP):实际上是反例的数据点被标记为正例(实际是普通乘客,被标记为恐怖分子)
真反例(TN):实际上是反例的数据点被标记为反例(实际是普通乘客,被标记为普通乘客)
假反例(FN):实际上是正例的数据点被标记为反例(实际是恐怖分子,被标记为普通乘客)其中T:True F:False P:Positive N:Negative
召回率可以被理解为模型找到数据集中所有感兴趣的数据点的能力,如例子所示,找的全是实际为恐怖分子(正例)的数据:
r e c a l l ( 召 回 率 ) = 真 正 例 ( T P ) 真 正 例 ( T P ) + 假 反 例 ( F N ) recall(召回率)=\frac{真正例(TP)}{真正例(TP)+假反例(FN)} recall(召回率)=真正例(TP)+假反例(FN)真正例(TP)
= 实 际 是 恐 怖 分 子 , 被 标 记 为 恐 怖 分 子 实 际 是 恐 怖 分 子 , 被 标 记 为 普 通 乘 客 + 实 际 是 恐 怖 分 子 , 被 标 记 为 普 通 乘 客 =\frac{实际是恐怖分子,被标记为恐怖分子}{实际是恐怖分子,被标记为普通乘客+实际是恐怖分子,被标记为普通乘客} =实际是恐怖分子,被标记为普通乘客+实际是恐怖分子,被标记为普通乘客实际是恐怖分子,被标记为恐怖分子
精度(查准率)表达模型找到的数据点中实际相关的比例,如例子所示,找到的全都是被标记为恐怖分子的数据
p r e c i s i o n ( 精 度 ) = 真 正 例 ( T P ) 真 正 例 ( T P ) + 假 正 例 ( F P ) precision(精度)=\frac{真正例(TP)}{真正例(TP)+假正例(FP)} precision(精度)=真正例(TP)+假正例(FP)真正例(TP)
= 实 际 是 恐 怖 分 子 , 被 标 记 为 恐 怖 分 子 实 际 是 恐 怖 分 子 , 被 标 记 为 恐 怖 分 子 + 实 际 是 普 通 乘 客 , 被 标 记 为 恐 怖 分 子 =\frac{实际是恐怖分子,被标记为恐怖分子}{实际是恐怖分子,被标记为恐怖分子+实际是普通乘客,被标记为恐怖分子} =实际是恐怖分子,被标记为恐怖分子+实际是普通乘客,被标记为恐怖分子实际是恐怖分子,被标记为恐怖分子
简而言之,随着精度的增加,召回率会降低。若我们想要找到精度和召回率的最佳组合,我们可以使用 F1 score 来对两者进行结合,F1 score 是对精度和召回率的调和平均:
F 1 = 2 ∗ r e c a l l ∗ p r e c i s i o n r e c a l l + p r e c i s i o n F_{1}=\frac{2*recall*precision}{recall+precision} F1=recall+precision2∗recall∗precision
∙ \bullet ∙准确率
准确率是分类正确的样本占总样本个数

∙ \bullet ∙Rank loss

2.1相关工作
MLC算法有许多不同的系列。 在这项工作中,我们重点研究基于链的算法,该算法按顺序逐个标签地进行预测,而每个预测都将先前预测的标签作为输入,分类器链(Classifier chain, CC) 是链族中最经典的算法。CC根据每个标签学习一个子分类器。具体来说,CC对标签进行一个一个的预测,前一个标签的预测反馈给下一个子分类器来预测下一个标签。CC允许子分类器通过建立子分类器之间的相关性来利用标签相关性。
然而,为CC决定标签的顺序可能是困难的,而标签的顺序对性能是至关重要的,链的后半部分中的子分类器可以从其他子分类器接收更多信息,而其他子分类器则接收较少的信息。为了解决标签排序问题,已经开发了一些算法,通过使用不同的方法来搜索一个更好的标签排序。
CC可以被解释为一个深度学习架构。深度学习架构的每一层预测一个标签,并将预测传递给下一层,卷积神经网络递归神经网络(CNN-RNN) 算法将构建子分类器之间关联的思想转化为维护子分类器之间的记忆,进一步采用递归神经网络(RNN)来推广CC的深度学习架构。Att-RNN加入了注意力模型来提高它们的性能和互操作性,此外,Att-RNN使用波束搜索方法来搜索一个更好的排序的标签。但由于Att-RNN和CNN-RNN都不具有成本敏感性,因此无法充分利用成本信息。
综上所述,开发MLC算法有三个关键方面。算法能否有效利用标签相关信息,算法能否考虑代价信息,算法能否扩展到现代应用的深度学习结构,在利用标签相关信息方面,目前基于链的MLC算法由于链的顺序特性,需要解决标签排序问题,链中的第一个标签和最后一个标签注定要从其他标签接收到不同数量的信息。通常,通过适应RNN,基于链的算法通常可以扩展到其他深度学习架构。 但是,当前在基于链的系列中没有MLC算法在设计时既考虑成本信息,又可与其他深度学习架构一起扩展
2.2RNN
递归神经网络(RNN)是一类用于解决序列预测问题的神经网络模型。在序列预测问题中,设有 B B B次迭代,每一次迭代都有一个输出。RNN使用内存将信息从一个迭代传递到下一个迭代。RNN学习两种转换,所有的迭代都共享这两种转换。特征变换 U ( ⋅ ) U(·) U(⋅)接受特征向量并将其变换到输出空间。 内存转换 W ( ⋅ ) W(·) W(⋅)接受上一次迭代的输出,并将其转换为与 U U U的输出相同的输出空间,在 1 ≤ i ≤ B 1\leq i\leq B 1≤i≤B,我们使用 x ( i ) x^{(i)} x(i)表示第i次迭代的特征向量,并且使用 o ( i ) o^{(i)} o(i)表示其输出向量,当 2 ≤ i ≤ B 2\leq i\leq B 2≤i≤B,让 σ ( ⋅ ) σ(·) σ(⋅)表示激活函数,则RNN模型可以写为:
![]()
如下图所示:

即在第一个时间步,只需要输入特征向量变换到输出空间中的信息(类似于标签嵌入),后面几个时间步都是输入上一个时间步的输出和特征向量变换。
RNN的基本变化称为简单RNN (SRN) 。SRN假设W和U是线性变换。SRN能够在迭代之间链接信息,但是由于梯度的衰减,它很难训练。总而言之,RNN提供了一个基础,共享信息之间的标签预测序列使用内存。
3、提出模型
通过迭代完善预测来改善预测结果的想法是“重新思考”过程。 这个过程可以看作是序列预测问题,RethinkNet采用RNN对该过程进行建模。图1说明了RethinkNet是如何设计的。RethinkNet由RNN层和稠密(全连接)层组成。全连接层学习标签嵌入(降低维度)以将RNN层的输出转换为标签向量,RNN层用于对“重新思考”过程进行建模。 RNN层经历了总共 B B B次迭代。RNN中的所有迭代都共享相同的特征向量,因为它们正在解决相同的MLC问题,第 t t t次迭代时,RNN层的输出为 o ^ ( t ) \hat{o}^{(t)} o^(t),它表示标签向量 y ^ ( t ) \hat{y}^{(t)} y^(t)的嵌入.每个 o ^ ( t ) \hat{o}^{(t)} o^(t)在RNN层中向下传递到 ( t + 1 ) (t +1) (t+1)次迭代.
RNN层中的每一次迭代都代表一次重新思考迭代,在第一次迭代中,Rethink Net仅基于特征向量进行预测,它针对的是更易于识别的标签,第一预测 y ^ ( 1 ) \hat{y}^{(1)} y^(1)与BR相似,它不考虑其他标签的信息,独立预测每个标签。从第二次迭代开始,RethinkNet开始使用前一次迭代的结果进行更好的预测 y ^ ( 2 ) , y ^ ( B ) \hat{y}^{(2)},\hat{y}^{(B)} y^(2),y^(B), y ^ ( B ) \hat{y}^{(B)} y^(B)作为最终预测 y ^ \hat{y} y^。 随着RethinkNet完善预测,最终将更加准确地标记困难标签。
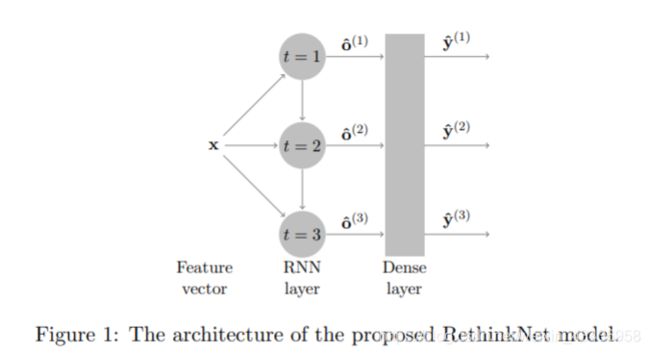 看得出来,一个特征向量会扔到所有的RNN层当中作为输入,也就是为了让RNN网络进行再思考,在每一次一共会再思考 B B B次,首先是在 t = 1 t=1 t=1的时候将特征向量 x x x进行输入(也可以看做是图像的特征向量),然后经过RNN层输出一个状态 o ^ ( t ) \hat{o}^{(t)} o^(t),这个状态不仅用于全连接层,通过标签嵌入从而转换为一个标签 y ^ ( 1 ) \hat{y}^{(1)} y^(1),同时也作为 t = 2 t=2 t=2时刻的输入,此时网络又根据相同的 x x x然后结合上一个时间步的输出 y ^ ( 1 ) \hat{y}^{(1)} y^(1)来进一步对RNN的输出来进行思考和优化,以达到这次的输出更加的精确,通过 B B B次迭代,网络能够做到对一个标签进行再三衡量最终获得一个精准的标签。
看得出来,一个特征向量会扔到所有的RNN层当中作为输入,也就是为了让RNN网络进行再思考,在每一次一共会再思考 B B B次,首先是在 t = 1 t=1 t=1的时候将特征向量 x x x进行输入(也可以看做是图像的特征向量),然后经过RNN层输出一个状态 o ^ ( t ) \hat{o}^{(t)} o^(t),这个状态不仅用于全连接层,通过标签嵌入从而转换为一个标签 y ^ ( 1 ) \hat{y}^{(1)} y^(1),同时也作为 t = 2 t=2 t=2时刻的输入,此时网络又根据相同的 x x x然后结合上一个时间步的输出 y ^ ( 1 ) \hat{y}^{(1)} y^(1)来进一步对RNN的输出来进行思考和优化,以达到这次的输出更加的精确,通过 B B B次迭代,网络能够做到对一个标签进行再三衡量最终获得一个精准的标签。
3.1 标签相关建模
RethinkNet在RNN层的内存中建立标签相关性模型,为了简化说明,我们假设激活函数 σ ( ⋅ ) σ(·) σ(⋅)为sigmoid函数,全连接层为恒等变换(此时默认为 o ^ ( t ) = y ^ ( t ) \hat{o}^{(t)}=\hat{y}^{(t)} o^(t)=y^(t))。在神经网络层中使用SRN是因为其他形式的神经网络源于SRN,具有相似的特性。在SRN中,内存变换和特征变换分别表示为矩阵 W ∈ R K × K W∈R^{K×K} W∈RK×K和 U ∈ R K × d U∈R^{K×d} U∈RK×d(其实相当于映射矩阵将内存的输出和特征向量映射到低维空间中),RNN层输出 o ^ ( t ) \hat{o}^{(t)} o^(t)将是一个长度为 K K K的标签向量.
在此设置下,预测的标签向量为 y ^ ( t ) = o ^ ( t ) = σ ( U x + W o ^ ( t − 1 ) ) \hat{y}^{(t)}=\hat{o}^{(t)}=σ(Ux+W\hat{o}^{(t-1)}) y^(t)=o^(t)=σ(Ux+Wo^(t−1)).该方程式可以分为两部分,特征项 U x Ux Ux像BR一样进行预测,存储项 W o ^ ( t − 1 ) W\hat{o}^{(t-1)} Wo^(t−1)可以将先前的预测转换为当前标签向量空间。此内存转换充当标签关联的模型. W [ i , j ] W[i,j] W[i,j]表示 W W W的第 i i i行和第 j j j列,它表示第 i i i和第 j j j标签之间的相关性,第 j j j个标签的预测是 ( U x ) [ j ] (Ux)[j] (Ux)[j]和 o ^ ( t ) [ j ] = ∑ i = 1 K o ^ ( t − 1 ) [ i ] ∗ W [ i , j ] \hat{o}^{(t)}[j]=\sum_{i=1}^{K}\hat{o}^{(t-1)}[i]\ast W[i,j] o^(t)[j]=∑i=1Ko^(t−1)[i]∗W[i,j]的结合(也就是说如果要对第 j j j个标签进行预测,我们就需要知道此标签与其他所有标签的相关性,从第一个标签到最后一个标签,计算每一个标签的的标签向量和此标签与第 j j j个标签的相关性的乘积),如果我们预测 o ^ ( t − 1 ) [ i ] \hat{o}^{(t-1)}[i] o^(t−1)[i]在第 t − 1 t-1 t−1次迭代时与 j j jshi 相关的,且 W [ i , j ] W[i, j] W[i,j]高,说明第j个标签与标签 i i i更有可能是相关的.如果 W [ i , j ] W[i, j] W[i,j]为负,说明第 i i i个标签和第 j j j个标签可能是负相关的。
图2绘制了学习内存变换矩阵和标签的相关系数.我们可以清楚地看到RethinkNet能够捕获标签相关性信息,尽管我们还发现这样的结果在某些数据集中可能是有噪声的。这一发现表明, W W W不仅具有标签相关性,还具有其他数据集因素.例如,RNN模型可以了解到对某个标签的预测并不具有很高的准确性,因此,即使另一个标签与这个标签高度相关,模型也不会给予它很高的权重。

上图表示具有SRN的训练后的内存转换矩阵W和酵母数据集的相关系数。每个单元代表两个标签之间的相关性。 存储器权重的每一行都将对角元素标准化为1,因此可以将其与相关系数进行比较。
3.2 成本敏感的再加权损失函数
在解决MLC问题时,成本信息是另一个需要考虑的重要信息。每个标签的成本函数值不同,所以我们应该对每个标签的重要性进行不同的设置。对这种特性进行编码的一种方法是,根据损失的重要性对损失函数中的每个标签进行加权。 问题将变成如何估计标签的重要性。
在成本函数下正确和错误地预测的标签之间的差异可用于估计标签的重要性。为了评估单个标签的重要性,了解其他标签是需要花费大部分成本的。我们利用了RethinkNet的顺序特性,在每个迭代之间进行临时预测。使用临时预测来填写所有其他标签,我们将能够估算每个标签的重要性。
每个标签的权重设计为式(1),对于 t = 1 t = 1 t=1,其中不存在先验预测,则将标签设置为同等重要,当 t > 1 t>1 t>1,当第 i i i个标签分别设为0和1时,我们使用 y ^ n ( t ) [ i ] 0 \hat{y}_{n}^{(t)}[i]_{0} y^n(t)[i]0和 y ^ n ( t ) [ i ] 1 \hat{y}_{n}^{(t)}[i]_{1} y^n(t)[i]1来表示标签向量 y ^ n ( t ) \hat{y}_{n}^{(t)} y^n(t)(一共K个标签),第 i i i个标签的权值是 y ^ n ( t ) [ i ] 0 \hat{y}_{n}^{(t)}[i]_{0} y^n(t)[i]0和 y ^ n ( t ) [ i ] 1 \hat{y}_{n}^{(t)}[i]_{1} y^n(t)[i]1之间的代价差。在给定的成本函数下,该加权方法可以用来估计每个标签在当前预测下的效果。这种方法符合CFT的设计要求。
![]()
(1)式表示:当时间步为1时,对 K K K个标签来说,每一个标签的权重都为1(就是相等),当时间步>1时,此时先要需要获得之前的标签权重对目前的权重产生的影响,也就是先获得将 y n y_{n} yn预测为上一个时间步输出的第 i i i个标签为0时的成本差,然后获得也就是先获得将 y n y_{n} yn预测为上一个时间步输出的第 i i i个标签为1时的成本差, y n y_{n} yn应该代表上一个时间步所有标签预测的0或者1,然后将两个成本差相减并取绝对值,从而获得此时间步第 i i i个标签的权重
在通常的MLC设置中,神经网络采用的损失函数为二值交叉,为了接受损失函数中的权值,我们将加权二元交叉矩阵表示为式(2),当t = 1时,由于没有预测参考,所以所有标签的权值都设置为1,当 t = 2 , … K t = 2,…K t=2,…K,使用之前的预测更新权重,请注意,当给定的成本函数为汉明损失时,每个迭代中的标签都有相同的权重,权重减小为与BR中的相同。
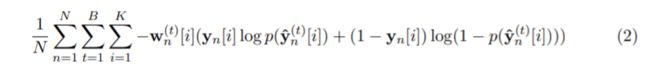
表1显示了MLC算法之间的比较。RethinkNet能够同时考虑标签相关性和成本信息,它的结构使其可以轻松地与其他神经网络一起扩展以进行高级特征提取,因此可以轻松地用于解决图像标记问题,因此可以很容易地用于解决图像标记问题

4、实验
实验在11个真实数据集上进行评估。数据集统计量如表2所示。随机对数据集进行75%训练和25%测试的分割,将特征向量缩放到[0,1]。实验重复10次,记录测试损失/分数的平均值和标准误差(ste),用Hamming loss、Rank loss、F1 score、Accuracy score对结果进行评价,↓表示越低越好,↑表示越高越好

4.1再反思
在第3节中,我们声明RethinkNet能够通过反复思考来改进。我们用这个实验来证明我们方法是合理的。在本次实验中,我们在RethinkNet的RNN层中使用了RNN最简单的形式SRN,该RNN层的维数固定为128。我们设置反思迭代的次数B = 5。
为了进一步观察反思过程,我们还在MSCOCO上训练了RethinkNet ,在MSCOCO数据集并观察其在真实世界图像上的行为。 以下图为例。 在第一次迭代中,RethinkNet预测图中将出现标签“人”,“杯子”,“叉”,“碗”,“椅子”,“餐桌”。 这些是易于检测的标签。 利用这些知识可能是餐桌上的场景,应该增加存在“刀”或“勺”的可能性。在第二次迭代中,RethinkNet进一步预测“刀,勺,瓶子”。 在第三次迭代中,RethinkNet发现瓶子不在图像中,将其移出预测。

4.2图像数据集的比较
针对图像标记问题,分别设计了CNN-RNN和Att-RNN算法。这个实验的目的是为了了解RethinkNet是如何与CNN-RNN和Att-RNN进行比较的.我们使用数据集MSCOCO和他们提供的训练测试分割。采用预训练的Resnet-50 进行特征提取。竞争模型包括logistic回归基线模型、CNN-RNN模型、Att-RNN模型和RethinkNet模型,Att-RNN的实现来自原始作者,其他模型使用keras实现,模型与预训练的Resnet-50进行了微调。测试数据集的结果如表5所示。结果表明,RethinkNet能够超过先进的深度学习模型的图像标记设计。

5、结论
经典的多标签分类算法(MLC)将标签预测为一个序列,以模拟标签的相关性。但是,这些方法都面临着标签按顺序排序的问题。在本文中,我们重新构造序列预测问题来避免这一问题。通过模拟人类反思的过程,我们提出了一个新的成本敏感的多标签分类(CSMLC)算法,称为RethinkNet。RethinkNet将其预测的逐步打磨过程作为预测的顺序。 我们采用递归神经网络(RNN)预测序列,然后可以使用RNN中的内存存储标签相关信息。 我们还修改了损失函数,以纳入成本信息,从而使RethinkNet成本敏感。大量实验表明,RethinkNet能够在常规数据集上胜过其他MLC和CSMLC算法。 在图像数据集上,RethinkNet的性能还可以超越最新的图像标记算法。 结果表明,RethinkNet是一种使用神经网络解决CSMLC的有前途的算法。