2021李宏毅机器学习笔记--9 Recurrent Neural Network
2021李宏毅机器学习笔记--9 Recurrent Neural Network
- 摘要
- 一、 RNN
-
- 1.1 Slot Filling
- 1.2 RNN
- 二、 Deep RNN
- 三、 RNN 变型
-
- 3.1 Elman network
- 3.2 Jordan network
- 3.3 bidirectional RNN
- 四、 LSTM
- 五、 training RNN
-
- 5.1 BPTT
- 5.2 Training RNN的问题及原因
- 5.3 解决方法
- 5.4 GRU
- 六、 RNN 实际应用
-
- 6.1 电影评价总结
- 6.2 文章关键词抓取
- 6.3 语音辨识
-
- 6.3.1 CTC
- 6.4 sequence to sequence learning
-
- 6.4.1 Beyond Sequence
- 6.4.2 Auto-encoder-text
- 6.4.3 Auto-encoder-speech
- 总结
摘要
本节主要介绍了RNN的概念,与其他的神经网络不同的是隐藏神经元的输出值都被保存在记忆单元中,到下一次再计算时,记忆单元中的值会作为输入的一部分考虑,并且输入序列的顺序会影响输出的结果。本文还介绍了RNN的几种不同类型,重点介绍了LSTM以及在训练RNN过程中的问题,还有实际生活中很多地方会应用到RNN来解决问题。
一、 RNN
1.1 Slot Filling
在介绍RNN之前,先看一个例子,比如现在的订票系统,里面会使用到Slot Filling的技术,比如说,输入你想什么时间去什么地方,系统会自动的找出你的目的地和时间进行推荐,那么他找出目的地和时间使用的方法就是Slot Filling。目的地和时间在系统里面都有对用的Slot,当句式中出现相应的输入时,系统会自动的将这两个量输出。
 但是这样会出现一个问题,当两句相似的话出现时,即便这两句话意思完全相反,但是系统只记得目的地和时间等词语,不知道离开和到达是什么意思,就会导致完全相反的两句话输出的结果却是一样的,所以我们需要一个有记忆的神经网络,他会记得在台北出现之前,是离开还是到达,这样就会有不同的输出。
但是这样会出现一个问题,当两句相似的话出现时,即便这两句话意思完全相反,但是系统只记得目的地和时间等词语,不知道离开和到达是什么意思,就会导致完全相反的两句话输出的结果却是一样的,所以我们需要一个有记忆的神经网络,他会记得在台北出现之前,是离开还是到达,这样就会有不同的输出。

1.2 RNN
有记忆的神经网络就是RNN。每次隐藏层的输出会被储存起来,等再一次输入时,上一次储存的输出值也作为一个输入考虑。
 比如上述的订票系统,使用RNN之后会变成这样,输入一句话,arrive先丢进系统,会输出一个可能性同时把arrive存储起来,在taipei输入时也同时考虑arrive的影响再输出概率值同时也对taipei进行存储。以此类推直至结束输出最终的结果,过程中是同一个网络重复工作。
比如上述的订票系统,使用RNN之后会变成这样,输入一句话,arrive先丢进系统,会输出一个可能性同时把arrive存储起来,在taipei输入时也同时考虑arrive的影响再输出概率值同时也对taipei进行存储。以此类推直至结束输出最终的结果,过程中是同一个网络重复工作。
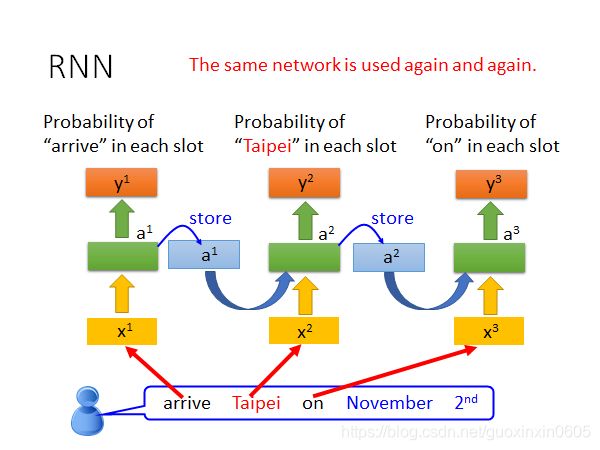 这样的话,输入arrive和leave,经过神经网络后会得到不同的结果。
这样的话,输入arrive和leave,经过神经网络后会得到不同的结果。

二、 Deep RNN
RNN的架构是可以任意设计的,当然也可以是deep的RNN,可以让中间的隐藏层更多就变成了deep的,每一个隐藏层的输出都会被存储在网络中,在下一个时间点的时候作为输入考虑。

三、 RNN 变型
3.1 Elman network
隐藏层的输出在下一个时间点作为输入读出来叫做Elman network。

3.2 Jordan network
与Elman network不同的是,他存起来的是上一层的输出结果而不是隐藏层的输出,在下一个时间点将这个结果考虑为输入。Jordan network会有比较好的性能表现,因为在这里y有清楚的target,我们清楚y里面放的是概率。

3.3 bidirectional RNN
双向的RNN,一句话可以同时train一个正向的一个反向的,然后把两种的输出结果整合在一起,这样做的好处是神经网络看的范围更广了。如果只有正向的,他只会看到前半部分,如果有反向的,他可以把反向的那些也看到,范围更大。

四、 LSTM
上述提到的RNN是最简单的RNN,可以随时进行存储和读取,那么LSTM(long short-term memory)就比较复杂,他有4个输入,1个输出。
z:是一个数值
z_i:是操控z可不可以输入的一个关卡,它的值是1和0,0代表z不可通过,1代表可以。
z_f: 是记忆体中的值c是否通过的关卡,1表示可以通过。
z_o: 是操控最后的值可不可以输出的关卡,1表示可以通过。
 为了方便理解,举一个例子,用数字和线性的运算更直观的帮助理解。输入是三维的x,和一个偏移,输出是一维的y。
为了方便理解,举一个例子,用数字和线性的运算更直观的帮助理解。输入是三维的x,和一个偏移,输出是一维的y。
z:只有x1起作用,其余的权重为0。
z_i:通常是关闭的,当x2有正值时,且值比较大,一加起来可能就打开了,表示可以通过。
z_f :通常都是被打开的,当x2给他一个负值时,可能就关闭了。
z_o:通常是关闭的,当x3给他一个正值时,可能就被打开了。
 假设存储值初始时为0,输入3 1 0,最后结果为0,记忆体中为3,
假设存储值初始时为0,输入3 1 0,最后结果为0,记忆体中为3,
 再输入4 1 0 ,经过计算结果为0,记忆体中更新为7
再输入4 1 0 ,经过计算结果为0,记忆体中更新为7
 再输入2 0 0 ,经过计算结果为0,记忆体中更新为7
再输入2 0 0 ,经过计算结果为0,记忆体中更新为7
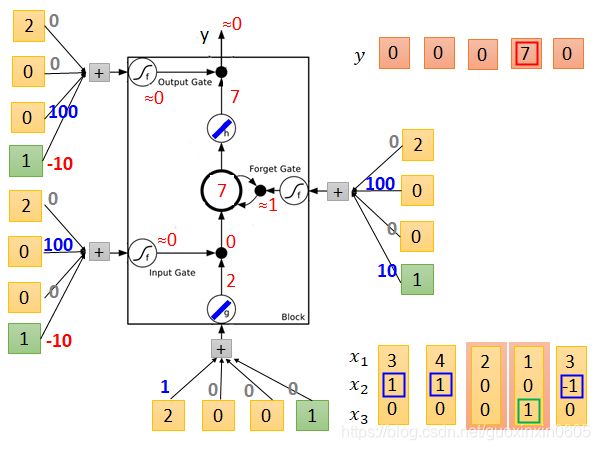
再输入1 0 1 ,经过计算结果为7,记忆体中更新为7
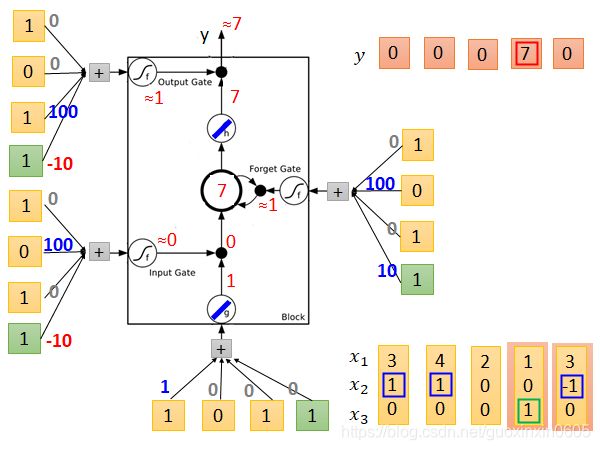 再输入3 -1 0 ,经过计算结果为0,记忆体中更新为0。
再输入3 -1 0 ,经过计算结果为0,记忆体中更新为0。

最后总的输出为0 0 0 7 0
其实LSTM就是把原来比较简单的神经网络中的隐藏层替换成比较复杂一点的上述结构。
 进而简化一下,将一个输入变成4个变量进行输入计算,这四个分量各自有自己的位置。
进而简化一下,将一个输入变成4个变量进行输入计算,这四个分量各自有自己的位置。
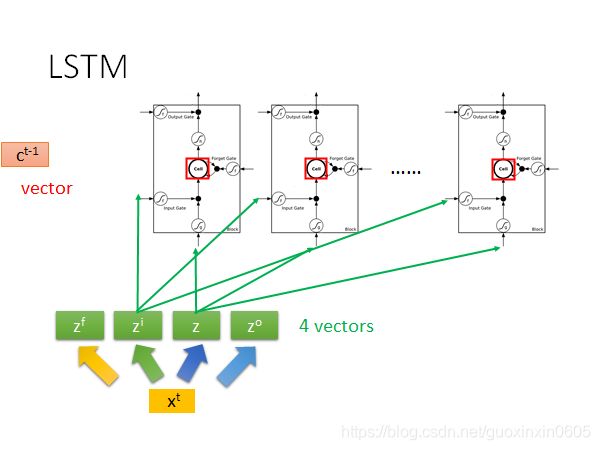 那么LSTM就可以化作这种形式
那么LSTM就可以化作这种形式
 在系统运行过程中可以简化成下图,下一个时间点在运行时,不仅把记忆体中的值考虑进来,还有上一个时间点的输出结果一起考虑。所以有三个不同的值并在一起,然后乘以不同的权重分成四个值进行运算。
在系统运行过程中可以简化成下图,下一个时间点在运行时,不仅把记忆体中的值考虑进来,还有上一个时间点的输出结果一起考虑。所以有三个不同的值并在一起,然后乘以不同的权重分成四个值进行运算。
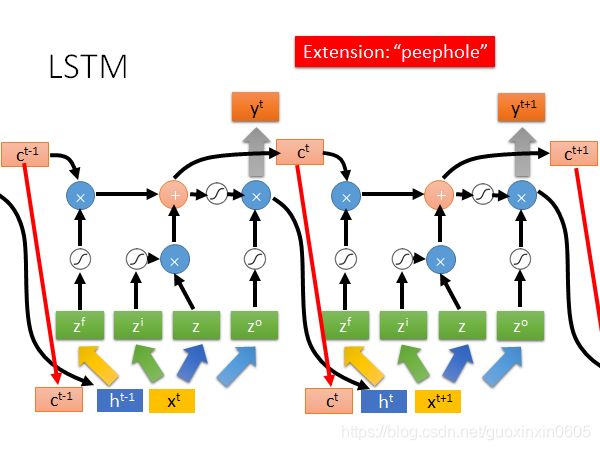
五、 training RNN
5.1 BPTT
无论在任何网络中的训练过程中,都要考虑损失函数,要用到gradient descent的方法,那么梯度下降在神经网络中比较有效率的算法是backpropagation,那么在RNN中是backpropagation的进阶版BPTT。是考虑时间的梯度下降。

5.2 Training RNN的问题及原因
但是不幸的是在训练过程中发现RNN是非常不容易被训练出来的,我们期待得到的结果蓝色的较为平滑的线,但是在实际训练过程中得到的却是绿色的线条,有剧烈的变化。

那么通过研究发现,error 的表面是非常粗糙的,有时候是非常平坦的,有时候又非常陡峭,在计算梯度时,如果经过陡峭的地方,梯度会突然暴增,再乘以一个学习率,
就导致计算出来的error表面非常粗糙,如果让学习率变得很小,那么在0.01和0.99计算结果上就没有差别了。因为他们是同样的东西在时间转换时反复使用。


5.3 解决方法
LSTM可以解决error表面崎岖问题,它可以让表面不那么崎岖。它可以解决梯度消失的问题,记忆体和输入是加法关系,而且这种影响是不会消失的,除非z_f是关闭的。如果z_f是打开状态的话,不会出现非常平坦的情况,那么就可以放心的把learning rate设的小一点。

5.4 GRU
gated recurrent unit是更为简单的LSTM,他需要的参数量是比较少的,他将input gate和forget gate联动起来了,一个打开另一个就会关闭。
六、 RNN 实际应用
在现实生活中,RNN可以用于很多方面,有些是many to one多对一的,多个输入,只有一个输出。有些many to many,多个输入,有多个输出。
6.1 电影评价总结
比如一部电影上映,会有许多人在网络上进行评价,会有特别大的数据量,不可能一条一条的查看,这时候可以写一个程序对这些评价进行分析,他是正面的还是负面的,最后可以知道人们对于电影的态度。

6.2 文章关键词抓取
有一篇文章,想知道里面有哪些关键词,可以写一个程序抓取关键词。

6.3 语音辨识
输入一段长的语音,输出给一些话。对于这段语音讯号,每隔很小的一段时间作为一个向量,会识别出很多的重复的字,需要去重后输出一句话。
 但是这样做的语音辨识有一个缺点是,当有叠词时不能分辨。
但是这样做的语音辨识有一个缺点是,当有叠词时不能分辨。

6.3.1 CTC
如何解决这个问题呢?用CTC(connectionist temporal classification)在进行输出时,不仅输出中文符号,还有一个null,空的。只需要把null的部分拿掉就可以了。那么CTC在训练时怎么做呢?穷举出所有可能的结果。

6.4 sequence to sequence learning
不确定输入跟输出到死谁比较长一点。比如ML翻译成中文机器学习。这两个词语不知道谁比较长或比较短,那么这种情况应该怎么做呢?如果他不知道停止一直翻译怎么办?
 给他设置一个断的点,当输出这个断时就停下来。
给他设置一个断的点,当输出这个断时就停下来。

6.4.1 Beyond Sequence
对一个句子进行解析,得到它的树状结构。

6.4.2 Auto-encoder-text
如果要理解一个句子的意思,不可以忽略句子的顺序,比如下面两句话,单词都差不多,但是句子的意思是截然相反的,不可以只关注关键词。
 怎么做呢,把句子拆成向量,把这个向量作为encoder的输入,然后经过decoder把信号解析出来。
怎么做呢,把句子拆成向量,把这个向量作为encoder的输入,然后经过decoder把信号解析出来。

6.4.3 Auto-encoder-speech
上述对于文本的应用同样可以用于语音上面,它可以把一个音频段变成固定长度的向量,这个可以拿来做语音的搜寻,比如语音里出现了某词语,在搜寻时,与该词语有关的都会被列举出来。

总结
本文主要介绍了RNN的原理,隐藏层的值会被存储起来,在下次输入时作为输入值一起考虑。目前应用最广泛的是LSTM,他在原有的基础上增加了输入门,输出门,忘记门三个控制单元,它可以把句子转化成向量,同时记住句子中比较重要的单词,并且让记忆保持比较长的时间,目前RNN在现实生活中也有很多应用,比如总结海量的电影评价,抓取文章的关键词等。