李宏毅机器学习课程梳理【十一】:Recurrent Neural Network(RNN)
文章目录
- 摘要
- 1 RNN
- 2 Long Short-term Memory
- 3 Training RNN
-
- 3.1 Learning Target
- 3.2 优化技术
- 4 RNN的应用
- 5 结论与展望
摘要
Recurrent Neural Network(RNN)在DNN的基础上加入了Memory结构以及隐状态,能够处理语义理解、语音辨识等注重序列顺序的问题,也因为Memory结构使得RNN的Error Surface变化非常剧烈,所以RNN的训练较为困难。针对RNN Error Surface的特征,优化RNN训练的技术,解决gradient vanishing问题。介绍LSTM,其在处理考虑输入序列顺序的问题上更精准。充分利用其处理语言的能力,应用扩展到机器翻译、诗歌生成、完成听力测试、阅读理解、建立量化交易模型等领域。将RNN等Deep Learning技术与Structure Learning技术合理地结合使用,会得到更佳结果。
1 RNN
场景举例—Slot Filling技术与智能订票系统。系统内设有许多slot,如出发地、目的地和到达时间等等。系统分析客户的话语,把词汇用向量表示,训练模型去填写slot。此情景中,同一个城市前不同意义的动词,会使这个城市名词对应不同的slot。此类情景注重输入序列的元素的顺序。
RNN擅长处理考虑输入序列的元素顺序的问题。RNN比DNN多了memory的设计,它将每一个hidden layer的运算结果储存并不断更新到memory中,但只能记住前一个hidden layer的运算结果。由于memory的作用,在输入序列中相同的元素,得到的输出也不同。
图中是同一个网络使用了三次。这样的架构是Elman Network的架构。
Jordan Network是将每个Output Layer的结果存到memory中。
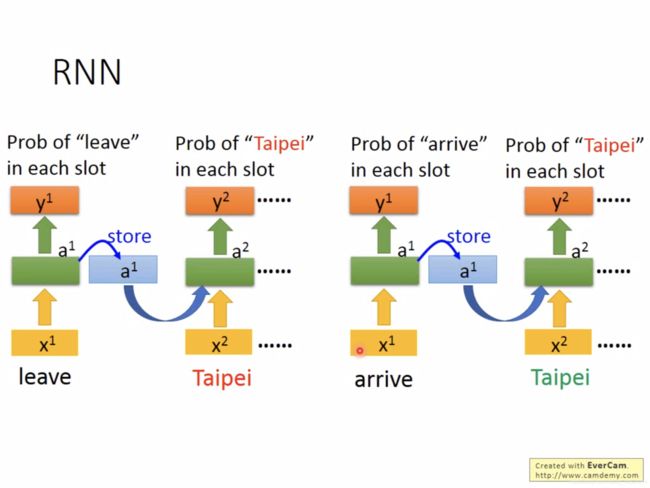
Bidirectional RNN的架构如图3所示。
图中蓝色箭头为memory,双向序列可以将整句话都读到,再给出输出,更精准。
2 Long Short-term Memory
可理解为记忆力较长的短时记忆模型,在RNN中加入Memory Cell结构。
此特殊的神经元输入三个控制数值Input Gate、Output Gate、Forget Gate和一个向量。对输入的数值和向量做Linear Transform,其间的weight和bias通过Training Data由gradient descent得到。因此,假设LSTM与NN有相同数量的神经元,LSTM需要维持4倍数量的参数。
具体的运算如图5所示。
图中三个黑色节点均作乘法,Memory Cell中数值更新为 c ′ c' c′,神经元的输出为 a = h ( c ′ ) f ( z o ) a=h(c')f(z_o) a=h(c′)f(zo),激活函数通常使用Sigmoid function,黑框相当于一个神经元。
下面是LSTM作为RNN如何操作的直观演示。由 x t x^t xt经过四次不同的Transform得到4 vectors,这些vectors的列数与Cell的个数相同,它们合起来操控Cell的运作。注意 z f , z i , z o z^f, z^i, z^o zf,zi,zo都是向量,只不过只选择其中某一分量的数值丢入Cell,如图6所示。
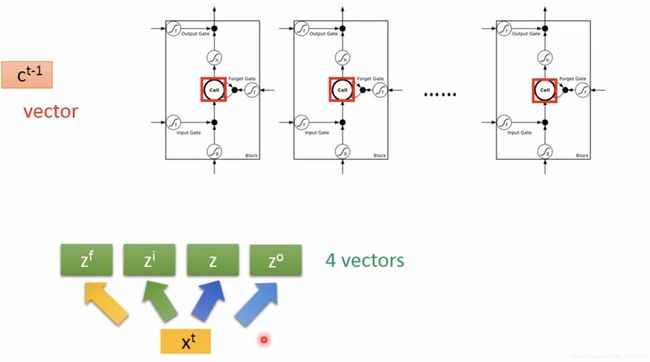
LSTM能够统一控制各输入向量 z , z f , z i , z o z, z^f, z^i, z^o z,zf,zi,zo,而且最原始的输入向量也不仅有 x t x^t xt,还有上一层Neuron的输出值 h t − 1 h^{t-1} ht−1和Memory Cell的值 c t − 1 c^{t-1} ct−1,三者合起来做Transform,叠加多层,最终得到LSTM,如图7所示。
3 Training RNN
3.1 Learning Target
定义Loss function:每个词汇的output与其对应标签的reference vector的交叉熵,reference vector的长度是slot的数量、取值是除标签所属的slot为1外其余位全为0。
RNN Training:Backpropagation through time(BPTT)
RNN难以训练的原因不是参数过多,而是因为同样的参数反复使用,即从memory接到neuron的那组weight反复使用。如果那组weight发生变化,要么产生微小的变化(error surface像斜面),要么产生非常巨大的变化(error surface像垂直断面)。
3.2 优化技术
LSTM
Memory的数值更新 c ′ = g ( z ) f ( z i ) + c f ( z f ) c'=g(z)f(z^i)+cf(z^f) c′=g(z)f(zi)+cf(zf),其memory和input是相加的,可以解决gradient vanishing问题,继而全局都可使用较小的learning rate。
Gated Recurrent Unit(GRU)门控循环单元
含有2个Gate,Update gate和Reset gate,比LSTM参数量少一些。Update gate将Input gate与Forget gate联动起来,决定丢弃哪些旧信息,添加哪些新信息;Reset gate决定写入多少上一时刻的网络状态,旧的不去新的不来。结构更简洁、计算更高效。
Clockwise RNN
Structurally Constrained Recurrent Network(SCRN)
4 RNN的应用
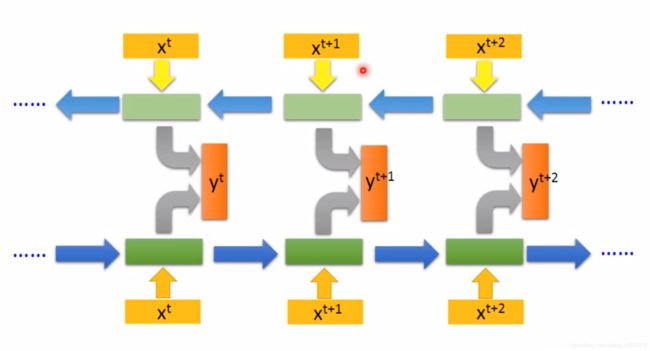
上文例子中Slot Filling的输入和输出是元素数量相同的序列,不过RNN还可以解决Many to One(如Sentiment Analysis)、Many to Many(如Speech Recognition)、甚至是树形结构(如Syntactic parsing)问题。
上图为Sequence-to-sequence Auto-encoder同时训练RNN Encoder与RNN Decoder得到Loss function结果,进而完成训练的过程。
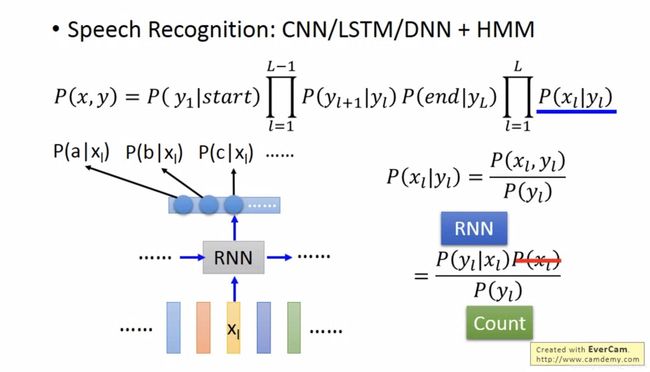
Deep&Structure结合:输入的feature先通过RNN,LSTM,得到的输出作为HMM,CRF,Structured Perceptron/SVM的输入,最终得到较好的结果。语音辨识中,x表示声音讯号,y表示辨识结果。图中公式蓝色下划线部分优化成由NN得到。
5 结论与展望
文章通过Slot Filling技术引入RNN的架构,介绍了Elman Network、Jordan Network和Bidirectional RNN的优势。介绍了LSTM的运作过程与完整结构。接下来介绍了RNN难以训练的根源与优化技术。最后介绍了RNN的众多应用。将Deep与Structure Learning巧妙结合会达到更好效果。后续文章将介绍半监督学习与无监督学习。