Pandas
目录
1.1 数据结构
1.1.1 Series
1.1.2 DataFrame
1.2 简单运用
1.2.1 导入模块
1.2.2 读取excel文件
1.2.3 查询数据
2 Pandas的Apply函数
3 loc 和 iloc
4 Pandas实现数据类型转换的一些小技巧汇总
5 Python数据分析库pandas高级接口dt的使用
6 用Python统计推断——交叉表篇 crosstab()
7 pandas中的rolling
7.1 参数说明
7.2 代码示例
7.3 常见用法
7.4 延伸用法
7.5 自定义函数
8 expanding()
8.1 参数说明
8.2 代码示例
1.1 数据结构
Pandas基于两种数据类型: series 与 dataframe 。
1.1.1 Series
一个series是一个一维的数据类型,其中每一个元素都有一个标签。类似于Numpy中元素带标签的数组。其中,标签可以是数字或者字符串。
import numpy as np
import pandas as pd
s = pd.Series([1, 2, 5, np.nan, 6, 8])
print(s)
'''
输出:
1.0
2.0
5.0
NaN
6.0
8.0
dtype: float64
'''1.1.2 DataFrame
一个dataframe是一个二维的表结构。Pandas的dataframe可以存储许多种不同的数据类型,并且每一个坐标轴都有自己的标签。你可以把它想象成一个series的字典项。
#创建一个 DateFrame:
#创建日期索引序列
dates =pd.date_range('20130101', periods=6)
print(type(dates))
#创建Dataframe,其中 index 决定索引序列,columns 决定列名
df =pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df)
'''
输出:
A B C D
2013-01-01 0.406575 -1.356139 0.188997 -1.308049
2013-01-02 -0.412154 0.123879 0.907458 0.201024
2013-01-03 0.576566 -1.875753 1.967512 -1.044405
2013-01-04 1.116106 -0.796381 0.432589 0.764339
2013-01-05 -1.851676 0.378964 -0.282481 0.296629
2013-01-06 -1.051984 0.960433 -1.313190 -0.093666
'''
#字典创建 DataFrame
df2 =pd.DataFrame({'A' : 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1,index=list(range(4)),dtype='float32'),
'D': np.array([3]*4,dtype='int32'),
'E': pd.Categorical(["test","train","test","train"]),
'F':'foo' })
print(df2)
'''
输出:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
''' 1.2 简单运用
1.2.1 导入模块
import pandas as pd
import numpy as np1.2.2 读取excel文件
df = pd.read_csv(path='file.csv')
'''
参数:header=None 用默认行名,0,1,2,3...
names=['A', 'B', 'C'...] 自定义列名
index_col='A'|['A', 'B'...] 给索引列指定名称,如果是多重索引,可以传list
skiprows=[0,1,2] 需要跳过的行号,从文件头0开始,skip_footer从文件尾开始
nrows=N 需要读取的行数,前N行
chunksize=M 返回迭代类型TextFileReader,每M条迭代一次,数据占用较大内存时使用
sep=':'数据分隔默认是',',根据文件选择合适的分隔符,如果不指定参数,会自动解析
skip_blank_lines=False 默认为True,跳过空行,如果选择不跳过,会填充NaN
converters={'col1', func} 对选定列使用函数func转换,通常表示编号的列会使用(避免转换成int)
dfjs = pd.read_json('file.json') 可以传入json格式字符串
dfex = pd.read_excel('file.xls', sheetname=[0,1..]) 读取多个sheet页,返回多个df的字典
'''
#df.to_csv()1.2.3 查询数据
df.shape #显示数据的多少行和多少列
df.dtypes #显示数据的格式
df.columns #显示数据的所有列名
df.head(n) #显示数据的前n=5行
df.tail(n) #显示数据的后n=5行
df.head(1)[‘date’] #获取第一行的date列
df.head(1)[‘date’][0] #获取第一行的date列的元素值
df.describe(include='all') # all代表需要将所有列都列出
df.columns.tolist() #把列名转换为list
df.T #对数据的转置:
df.notnull() #df的非空值为True
df.isnull() #isnull是Python中检验空值的函数,返回的结果是逻辑值,包含空值返回True,不包含则返回False。可以对整个数据表进行检查,也可以单独对某一列进行空值检查。
df[“列名”] #返回这一列(“列名”)的数据
df[[“name”,”age”]] #返回列名为name和 age的两列数据
df[‘列字段名’].unique() #显示数据某列的所有唯一值, 有0值是因为对数据缺失值进行了填充
df = pd.read_excel(file,skiprows=[2] ) #不读取哪里数据,可用skiprows=[i],跳过文件的第i行不读取
df.loc[0] #使用loc[]方法来选择第一行的数据
df.loc[0][“name”] #使用loc[]方法来选择第一行且列名为name的数据
df.loc[2:4] #返回第3行到第4行的数据
df.loc[[2,5,10]] #返回行标号为2,5,10三行数据,注意必须是由列表包含起来的数据。
df.loc[:,’test1’] #获取test1的那一列,这个冒号的意思是所有行,逗号表示行与列的区分
df.loc[:,[‘test1’,’test2’]] #获取test1列和test2列的数据
df.loc[1,[‘test1’,’test2’]] #获取第二行的test1和test2列的数据
df.at[1,’test1’] #表示取第二行,test1列的数据,和上面的方法类似
df.iloc[0] #获取第一行
df.iloc[0:2,0:2] #获取前两行前两列的数据
df.iloc[[1,2,4],[0,2]] #获取第1,2,4行中的0,2列的数据2 Pandas的Apply函数
https://blog.csdn.net/qq_19528953/article/details/79348929
apply函数是`pandas`里面所有函数中自由度最高的函数。该函数如下:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据
结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数
会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
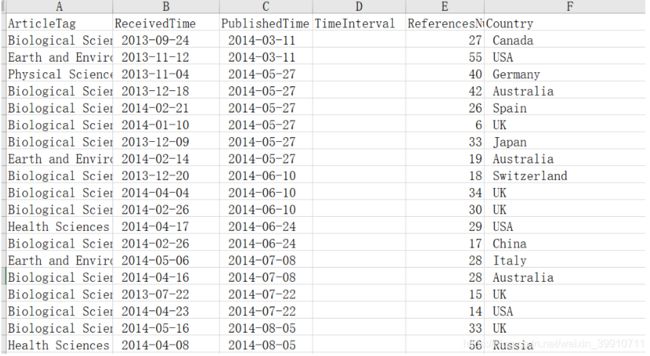
假如我们想要得到表格中的PublishedTime和ReceivedTime属性之间的时间差数据,就可以使用下面的函数来实现:
import pandas as pd
import datetime #用来计算日期差的包
def dataInterval(data1,data2):
d1 = datetime.datetime.strptime(data1, '%Y-%m-%d')
d2 = datetime.datetime.strptime(data2, '%Y-%m-%d')
delta = d1 - d2
return delta.days
def getInterval(arrLike): #用来计算日期间隔天数的调用的函数
PublishedTime = arrLike['PublishedTime']
ReceivedTime = arrLike['ReceivedTime']
# print(PublishedTime.strip(),ReceivedTime.strip())
days = dataInterval(PublishedTime.strip(),ReceivedTime.strip()) #注意去掉两端空白
return days
if __name__ == '__main__':
fileName = "NS_new.xls";
df = pd.read_excel(fileName)
df['TimeInterval'] = df.apply(getInterval , axis = 1)
有时候,我们想给自己实现的函数传递参数,就可以用的apply函数的*args和**kwds参数,比如同样的时间差函数,我希望自己传递时间差的标签,这样没次标签更改就不用修改自己实现的函数了,实现代码如下:
import pandas as pd
import datetime #用来计算日期差的包
def dataInterval(data1,data2):
d1 = datetime.datetime.strptime(data1, '%Y-%m-%d')
d2 = datetime.datetime.strptime(data2, '%Y-%m-%d')
delta = d1 - d2
return delta.days
def getInterval_new(arrLike,before,after): #用来计算日期间隔天数的调用的函数
before = arrLike[before]
after = arrLike[after]
# print(PublishedTime.strip(),ReceivedTime.strip())
days = dataInterval(after.strip(),before.strip()) #注意去掉两端空白
return days
if __name__ == '__main__':
fileName = "NS_new.xls";
df = pd.read_excel(fileName)
df['TimeInterval'] = df.apply(getInterval_new ,
axis = 1, args = ('ReceivedTime','PublishedTime')) #调用方式一
#下面的调用方式等价于上面的调用方式
df['TimeInterval'] = df.apply(getInterval_new ,
axis = 1, **{'before':'ReceivedTime','after':'PublishedTime'}) #调用方式二
#下面的调用方式等价于上面的调用方式
df['TimeInterval'] = df.apply(getInterval_new ,
axis = 1, before='ReceivedTime',after='PublishedTime') #调用方式三
修改后的getInterval_new函数多了两个参数,这样我们在使用apply函数的时候要自己传递参数,代码中显示的三种传递方式都行。
3 loc 和 iloc
官网:https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.loc.html?highlight=loc#pandas.DataFrame.loc
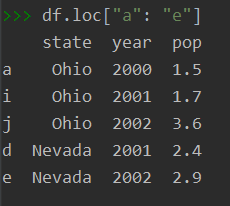
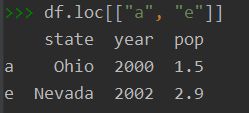
- df.loc主要是依赖于行列的index字符串名,去索取指定行列位置处的值。loc[]括号内还可以加条件,如df.loc[df[‘shield’] > 6]。主要是由字符串作为标签获取,有时也可用布尔型去获取。
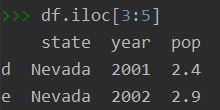
- df.iloc由行列号去获取,如果获取指定行列号处的值,而表中又没有行列名使用,或者只有列名,没有行名(大多数情况下),那么推荐使用iloc。
import pandas as pd
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
df= pd.DataFrame(data, index=["a", "i", "j", "b", "e", "f"])

4 Pandas实现数据类型转换的一些小技巧汇总
https://www.jb51.net/article/139630.htm
5 Python数据分析库pandas高级接口dt的使用
(1) dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。 这里先简单创建一个dataframe。

(2)dt.year、dt.month、dt.day、dt.hour、dt.minute、dt.second、dt.week (dt.weekofyear和dt.week一样)分别返回日期的年、月、日、小时、分、秒及一年中的第几周
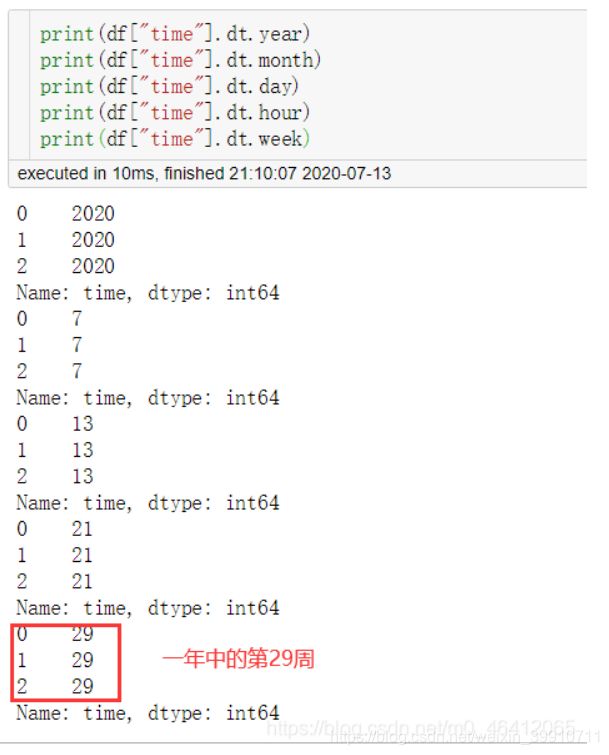
(3)dt.weekday(dt.dayofweek一样)返回一周中的星期几,0代表星期一,6代表星期天,dt.weekday_name返回星期几的英文。

(4)dt.dayofyear 返回一年的第几天,dt.quarter得到每个日期分别是第几个季度。

(5)dt.is_month_start和dt.is_month_end 判断日期是否是每月的第一天或最后一天,可以将month换成year和quarter相应的判断日期是否是每年或季度的第一天或最后一天.

(6)dt.is_leap_year 判断是否是闰年

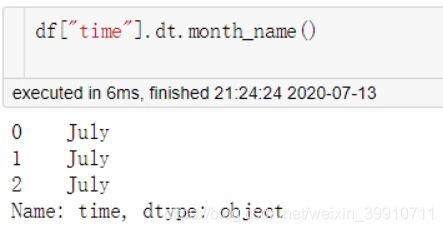
(7)dt.month_name() 返回月份的英文名称.
6 用Python统计推断——交叉表篇 crosstab()
https://zhuanlan.zhihu.com/p/52368125
7 pandas中的rolling
https://www.cnblogs.com/traditional/p/13776180.html
7.1 参数说明
DataFrame.rolling(window, min_periods=None, center=False, win_type=None,
on=None, axis=0, closed=None)
- window:表示时间窗的大小,有两种形式:1)使用数值int,则表示观测值的数量,即向前几个数据;2)也可以使用offset类型,这种类型较复杂,使用场景较少,此处暂不做介绍;
- min_periods:每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认None。offset情况下,默认为1;
- center: 把窗口的标签设置为居中,布尔型,默认False,居右
- win_type: 窗口的类型。截取窗的各种函数。字符串类型,默认为None;
- on: 可选参数。对于dataframe而言,指定要计算滚动窗口的列。值为列名。
axis: 默认为0,即对列进行计算
closed:定义区间的开闭,支持int类型的window。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left、both等。
7.2 代码示例
- 示例中,由于窗口大小为3(window),前两个元素有空值,第三个元素的值将是n,n-1和n-2元素的平均值。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(7, 4),
index = pd.date_range('1/1/2020', periods=7),
columns = ['A', 'B', 'C', 'D'])
df
A B C D
2020-01-01 -0.103252 -0.378633 -0.689324 -1.150870
2020-01-02 -0.838289 0.036139 -0.481754 -0.006116
2020-01-03 -0.832013 -0.770184 -1.818931 0.253601
2020-01-04 -1.696006 -0.021195 0.772365 0.332447
2020-01-05 -2.136677 1.088825 1.166188 0.140585
2020-01-06 -0.705095 0.709978 1.077941 0.055677
2020-01-07 0.990198 0.764884 0.858504 -0.903039
df.rolling(window=3).mean()
A B C D
2020-01-01 NaN NaN NaN NaN
2020-01-02 NaN NaN NaN NaN
2020-01-03 0.079891 -0.714177 -0.453193 0.232669
2020-01-04 -0.479782 -0.513903 -0.631638 0.034099
2020-01-05 -0.574793 -0.532310 -0.544511 -0.535417
2020-01-06 -0.675196 0.421606 -0.214320 -0.463122
2020-01-07 -0.118239 0.637363 -0.270283 -0.653187
df.rolling(window=3, min_periods=1).mean() 设置最少观测值数量为1
A B C D
2020-01-01 -0.103252 -0.378633 -0.689324 -1.150870
2020-01-02 -0.470771 -0.171247 -0.585539 -0.578493
2020-01-03 -0.591185 -0.370893 -0.996670 -0.301128
2020-01-04 -1.122103 -0.251747 -0.509440 0.193311
2020-01-05 -1.554899 0.099149 0.039874 0.242211
2020-01-06 -1.512593 0.592536 1.005498 0.176237
2020-01-07 -0.617191 0.854562 1.034211 -0.2355927.3 常见用法
- rolling()函数除了mean(),还支持很多函数,比如:
- count() 非空观测值数量
- sum() 值的总和
- median() 值的算术中值
- min() 最小值
- max() 最大
- std() 贝塞尔修正样本标准差
- var() 无偏方差
- skew() 样品偏斜度(三阶矩)
- kurt() 样品峰度(四阶矩)
- quantile() 样本分位数(百分位上的值)
- cov() 无偏协方差(二元)
- corr() 相关(二进制)
借助 agg ()函数可以快速实现多个聚类函数,并输出结果,同时还可以进行重命名;
代码示例:
df2 = pd.DataFrame({
"date": pd.date_range("2018-07-01", periods=7),
"amount": [12000, 18000, np.nan, 12000, 9000, 16000, 18000]})
df2
date amount
0 2018-07-01 12000.0
1 2018-07-02 18000.0
2 2018-07-03 NaN
3 2018-07-04 12000.0
4 2018-07-05 9000.0
5 2018-07-06 16000.0
6 2018-07-07 18000.0
窗口大小为2
df2.rolling(window=2, on="date").sum()
date amount
0 2018-07-01 NaN
1 2018-07-02 30000.0
2 2018-07-03 NaN
3 2018-07-04 NaN
4 2018-07-05 21000.0
5 2018-07-06 25000.0
6 2018-07-07 34000.0
窗口大小为2,最少观测值数量为1
df2.rolling(window=2, on="date", min_periods=1).sum()
date amount
0 2018-07-01 12000.0
1 2018-07-02 30000.0
2 2018-07-03 18000.0
3 2018-07-04 12000.0
4 2018-07-05 21000.0
5 2018-07-06 25000.0
6 2018-07-07 34000.0
返回多个聚合结果,如sum()、mean()
df2.rolling(window=2, min_periods=1)["amount"].agg([np.sum, np.mean])
sum mean
0 12000.0 12000.0
1 30000.0 15000.0
2 18000.0 18000.0
3 12000.0 12000.0
4 21000.0 10500.0
5 25000.0 12500.0
6 34000.0 17000.0
返回多个聚合结果,并进行重命名
df2.rolling(window=2, min_periods=1)["amount"].agg({"amt_sum": np.sum, "amt_mean": np.mean})
amt_sum amt_mean
0 12000.0 12000.0
1 30000.0 15000.0
2 18000.0 18000.0
3 12000.0 12000.0
4 21000.0 10500.0
5 25000.0 12500.0
6 34000.0 17000.0
7.4 延伸用法
通过rolling()函数与聚合函数的拼接,组成新的函数,可以更方便地实现窗口函数的功能;
这种用法,功能强大,代码简单,所有参数的设置基本一致;
列举如下:
- rolling_count() 计算各个窗口中非NA观测值的数量
- rolling_sum() 计算各个移动窗口中的元素之和
- rolling_mean() 计算各个移动窗口中元素的均值
- rolling_median() 计算各个移动窗口中元素的中位数
- rolling_var() 计算各个移动窗口中元素的方差
- rolling_std() 计算各个移动窗口中元素的标准差
- rolling_min() 计算各个移动窗口中元素的最小值
- rolling_max() 计算各个移动窗口中元素的最大值
- rolling_corr() 计算各个移动窗口中元素的相关系数
- rolling_corr_pairwise() 计算各个移动窗口中配对数据的相关系数
- rolling_cov() 计算各个移动窗口中元素的的协方差
- rolling_quantile() 计算各个移动窗口中元素的分位数
7.5 自定义函数
- 除了支持聚合函数,通过rolling().apply()方法,还可以在移动窗口上使用自己定义的函数,实现某些特殊功能;
- 唯一需要满足的是,在数组的每一个片段上,函数必须产生单个值;
代码示例:
# 自定义方法:求和后,除以100
df2.rolling(2, min_periods=1)["amount"].apply(lambda x: sum(x)/100, raw=False)
0 120.0
1 300.0
2 NaN
3 NaN
4 210.0
5 250.0
6 340.08 expanding()
8.1 参数说明
DataFrame.expanding(min_periods = 1,center = False,axis = 0)
- expanding()函数的参数,与rolling()函数的参数用法相同;
- rolling()函数,是固定窗口大小,进行滑动计算,expanding()函数只设置最小的观测值数量,不固定窗口大小,实现累计计算,即不断扩展;
- expanding()函数,类似cumsum()函数的累计求和,其优势在于还可以进行更多的聚类计算;
- 事实上,当rolling()函数的参数window=len(df)时,实现的效果与expanding()函数是一样的。
8.2 代码示例
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4),
index = pd.date_range('1/1/2018', periods=10),
columns = ['A', 'B', 'C', 'D'])
df
A B C D
2018-01-01 -0.349086 -0.225357 -0.108829 1.662773
2018-01-02 1.056407 -0.159644 0.042278 0.298922
2018-01-03 -1.376891 0.112999 -0.719286 0.254892
2018-01-04 0.741323 1.510449 0.615251 -1.896209
2018-01-05 1.305841 0.380900 -0.961663 -0.654108
2018-01-06 -1.079804 -0.883547 0.149659 -0.065931
2018-01-07 0.240168 -0.409613 -0.543655 0.797564
2018-01-08 0.716836 -0.329991 0.271236 -2.138515
2018-01-09 -1.448734 1.261487 0.795663 -1.492216
2018-01-10 -1.212092 -1.039160 1.581169 1.156089
df.expanding(min_periods=2).mean()
A B C D
2018-01-01 NaN NaN NaN NaN
2018-01-02 0.353660 -0.192500 -0.033276 0.980848
2018-01-03 -0.223190 -0.090667 -0.261946 0.738863
2018-01-04 0.017938 0.309612 -0.042647 0.080095
2018-01-05 0.275519 0.323869 -0.226450 -0.066746
2018-01-06 0.049632 0.122633 -0.163765 -0.066610
2018-01-07 0.076851 0.046598 -0.218035 0.056843
2018-01-08 0.156849 -0.000475 -0.156876 -0.217576
2018-01-09 -0.021549 0.139743 -0.051038 -0.359203
2018-01-10 -0.140603 0.021852 0.112182 -0.207674
# 判断expanding()的求和结果,与cumsum()结果,相同
result1 = df.expanding(min_periods=1).sum()
result2 = df.cumsum()
np.allclose(result1, result2)
True