详解 Python 中的多线程
3 线程和 Python
3.1 全局解释器锁
Python 代码的执行是由 Python 虚拟机(又名解释器主循环)进行控制的。 Python 在设计时是这样考虑的,在主循环中同时只能有一个控制线程在执行,就像单核 CPU 系统中的多进程一样。内存中可以有许多程序,但是在任意给定时刻只能有一个程序在运行。同理,尽管 Python 解释器中可以运行多个线程,但是在任意给定时刻只有一个线程会被解释器执行。
对 Python 虚拟机的访问是由全局解释器锁(GIL)控制的。这个锁就是用来保证同时只能有一个线程运行的。在多线程环境中, Python 虚拟机将按照下面所述的方式执行。
1.设置 GIL。
2.切换进一个线程去运行。
3.执行下面操作之一。
a.指定数量的字节码指令。
b.线程主动让出控制权(可以调用 time.sleep(0)来完成)。
4.把线程设置回睡眠状态(切换出线程)。
5.解锁 GIL。
6.重复上述步骤。
当调用外部代码(即,任意 C/C++扩展的内置函数)时, GIL 会保持锁定,直至函数执行结束(因为在这期间没有 Python 字节码计数)。编写扩展函数的程序员有能力解锁 GIL,然而,作为 Python 开发者, 你并不需要担心 Python 代码会在这些情况下被锁住。
3.2 退出线程
当一个线程完成函数的执行时,它就会退出。另外,还可以通过调用诸如 thread.exit()之类的退出函数,或者 sys.exit()之类的退出 Python 进程的标准方法,亦或者抛出 SystemExit异常,来使线程退出。不过,你不能直接“终止”一个线程。
3.3 在 Python 中使用线程
Python 虽然支持多线程编程,但是还需要取决于它所运行的操作系统。如下操作系统是支持多线程的:绝大多数类 UNIX 平台(如 Linux、 Solaris、 Mac OS X、 *BSD 等),以及Windows 平台。 Python 使用兼容 POSIX 的线程,也就是众所周知的 pthread。
默认情况下,从源码构建的 Python(2.0 及以上版本)或者 Win32 二进制安装的 Python,线程支持是已经启用的。要确定你的解释器是否支持线程,只需要从交互式解释器中尝试导入 thread 模块即可,如下所示(如果线程是可用的,则不会产生错误)。

如果你的 Python 解释器没有将线程支持编译进去,模块导入将会失败。Python3使用import _thread。
这种情况下,你可能需要重新编译你的 Python 解释器才能够使用线程。一般可以在调用configure 脚本的时候使用--with-thread 选项。查阅你所使用的发行版本的 README 文件,来获取如何在你的系统中编译线程支持的 Python 的指定指令。
3.4 不使用线程的情况
我们将使用 time.sleep()函数来演示线程是如何工作的。 time.sleep()函数需要一个浮点型的参数,然后以这个给定的秒数进行“睡眠”,也就是说,程序的执行会暂时停止指定的时间。
创建两个时间循环:一个睡眠 4 秒(loop0());另一个睡眠 2 秒(loop1())(这里使用“loop0”和“loop1”作为函数名,暗示我们最终会有一个循环序列)。如果在一个单进程或单线程的程序中顺序执行 loop0()和 loop1(),就会像示例 4-1 中的 onethr.py 一样,整个执行时间至少会达到 6 秒钟。而在启动 loop0()和 loop1()以及执行其他代码时,也有可能存在 1 秒的开销,使得整个时间达到 7 秒。
可以通过执行 onethr.py 来验证这一点,下面是输出结果。
现在,假设 loop0()和 loop1()中的操作不是睡眠,而是执行独立计算操作的函数,所有结果汇总成一个最终结果。那么,让它们并行执行来减少总的执行时间是不是有用的呢?这就是现在要介绍的多线程编程的前提。
3.5 Python 的 threading 模块
Python 提供了多个模块来支持多线程编程,包括 thread、 threading 和 Queue 模块等。程序是可以使用 thread 和 threading 模块来创建与管理线程。 thread 模块提供了基本的线程和锁定支持;而 threading 模块提供了更高级别、功能更全面的线程管理。使用 Queue 模块,用户可以创建一个队列数据结构,用于在多线程之间进行共享。

4 thread 模块
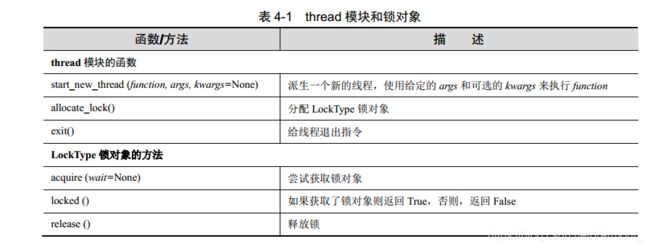
让我们先来看看 thread 模块提供了什么。除了派生线程外, thread 模块还提供了基本的同步数据结构,称为锁对象(lock object,也叫原语锁、 简单锁、 互斥锁、 互斥和二进制信号量)。如前所述,这个同步原语和线程管理是密切相关的。
表 4-1 列出了一些常用的线程函数,以及 LockType 锁对象的方法。
thread 模块的核心函数是 start_new_thread()。它的参数包括函数(对象)、函数的参数以及可选的关键字参数。将专门派生新的线程来调用这个函数。
把多线程整合进 onethr.py 这个例子中。把对 loop*()函数的调用稍微改变一下,得到示例4-2 中的 mtsleepA.py 文件。
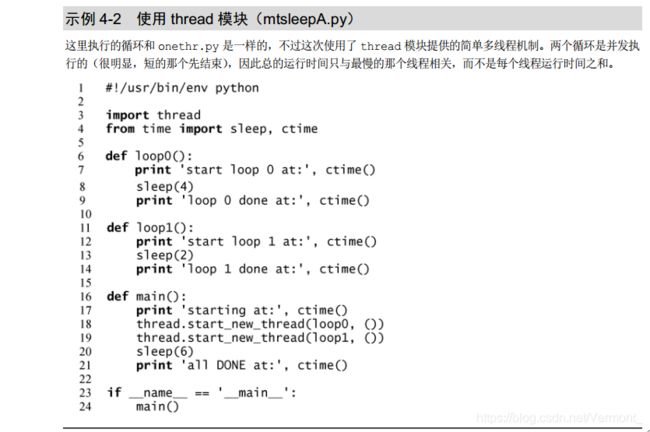
start_new_thread()必须包含开始的两个参数,于是即使要执行的函数不需要参数,也需要传递一个空元组。
与之前的代码相比,本程序执行后的输出结果有很大不同。原来需要运行 6~7 秒的时间,而现在的脚本只需要运行 4 秒,也就是最长的循环加上其他所有开销的时间之和。

睡眠 4 秒和睡眠 2 秒的代码片段是并发执行的,这样有助于减少整体的运行时间。你甚至可以看到 loop 1 是如何在 loop 0 之前结束的。
这个应用程序中剩下的一个主要区别是增加了一个 sleep(6)调用。为什么必须要这样做呢?这是因为如果我们没有阻止主线程继续执行,它将会继续执行下一条语句,显示“all done”然后退出,而 loop0()和 loop1()这两个线程将直接终止。
我们没有写让主线程等待子线程全部完成后再继续的代码,即我们所说的线程需要某种形式的同步。在这个例子中,调用 sleep()来作为同步机制。将其值设定为 6 秒是因为我们知道所有线程(用时 4 秒和 2 秒的)会在主线程计时到 6 秒之前完成。
再一次修改代码,引入锁,并去除单独的循环函数,修改后的代码为 mtsleepB.py。我们可以看到输出结果与 mtsleepA.py 相似。唯一的区别是我们不需要再像mtsleepA.py 那样等待额外的时间后才能结束。通过使用锁,我们可以在所有线程全部完成执
行后立即退出。其输出结果如下所示。
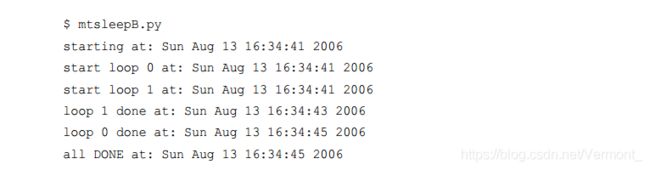
与 mtsleepA.py 中调用 sleep()来挂起主线程不同,锁的使用将更加合理。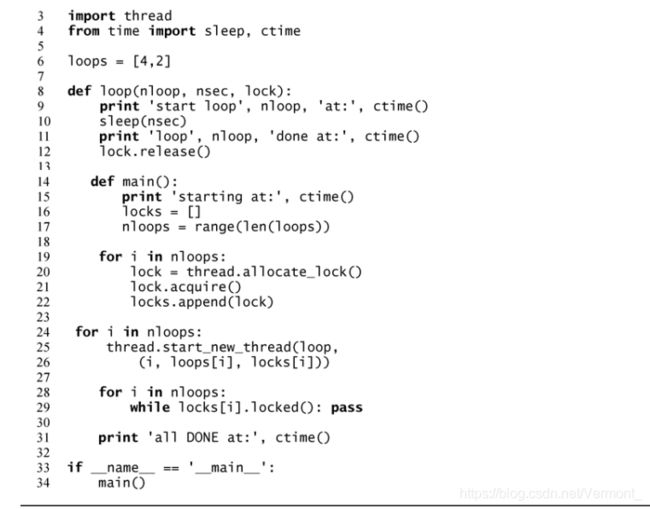
5 threading 模块
现在介绍更高级别的 threading 模块。除了 Thread 类以外,该模块还包括许多非常好用的同步机制。表 4-2 给出了 threading 模块中所有可用对象的列表。
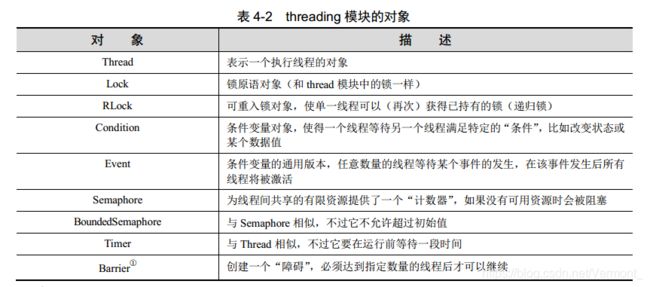
本节将研究如何使用 Thread 类来实现多线程。由于之前已经介绍过锁的基本概念,因此这里不会再对锁原语进行介绍。因为 Thread()类同样包含某种同步机制,所以锁原语的显式使用不再是必需的了。

5.1 Thread 类
threading 模块的 Thread 类是主要的执行对象。它有 thread 模块中没有的很多函数。
表 4-3 给出了它的属性和方法列表。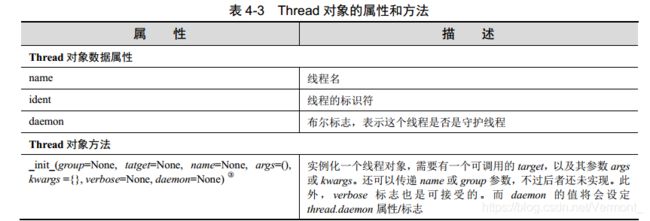
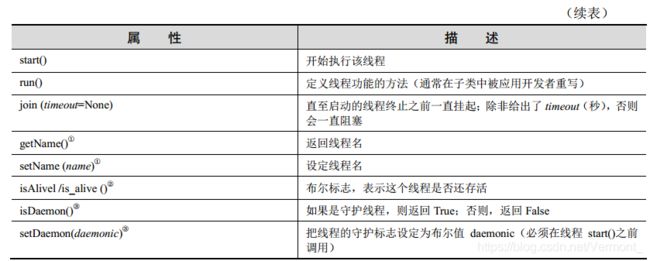

使用 Thread 类,可以有很多方法来创建线程。我们将介绍其中比较相似的三种方法。选择你觉得最舒服的,或者是最适合你的应用和未来扩展的方法(我们更倾向于最后一种方案)。
• 创建 Thread 的实例,传给它一个函数。
• 创建 Thread 的实例,传给它一个可调用的类实例。
• 派生 Thread 的子类,并创建子类的实例。
你会发现你将选择第一个或第三个方案。当你需要一个更加符合面向对象的接口时,会选择后者;否则会选择前者。老实说,你会发现第二种方案显得有些尴尬并且稍微难以阅读。
5.2 threading 模块的其他函数
除了各种同步和线程对象外, threading 模块还提供了一些函数,如表 4-4 所示。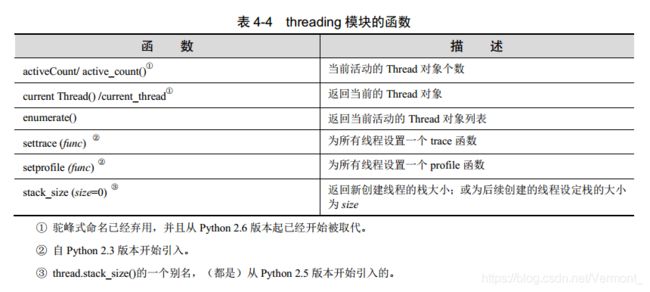
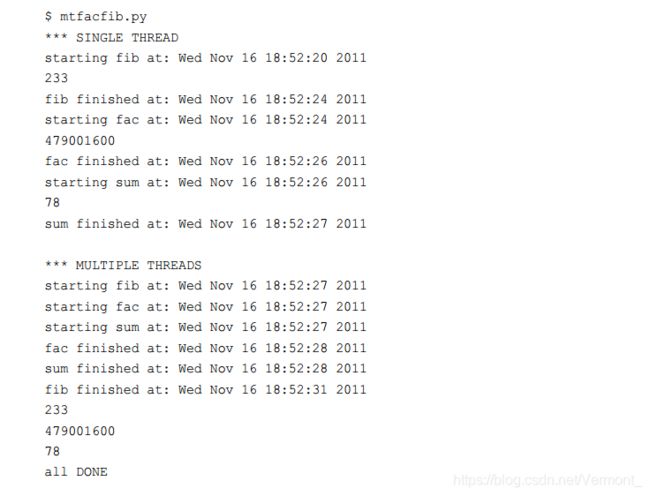
6 单线程和多线程执行对比
示例 4-8 的 mtfacfib.py 脚本比较了递归求斐波那契、阶乘与累加函数的执行。该脚本按照单线程的方式运行这三个函数。之后使用多线程的方式执行同样的任务,用来说明多线程环境的优点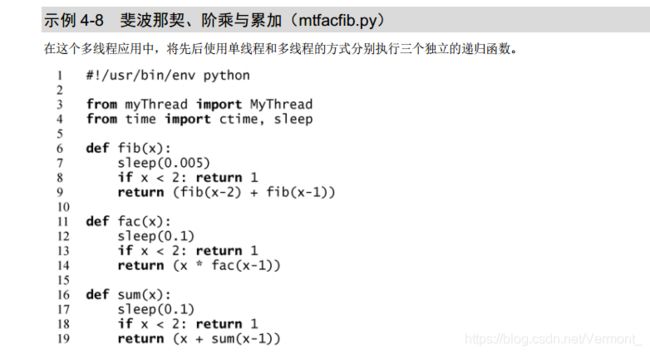


以单线程模式运行时,只是简单地依次调用每个函数,并在函数执行结束后立即显示相应的结果。
而以多线程模式运行时,并不会立即显示结果。 因为我们希望让 MyThread 类越通用越好(有输出和没有输出的调用都能够执行),我们要一直等到所有线程都执行结束,然后调用getResult()方法来最终显示每个函数的返回值。因为这些函数执行起来都非常快(也许斐波那契函数除外),所以你会发现在每个函数中都加入了 sleep()调用,用于减慢执行速度,以便让我们看到多线程是如何改善性能的。在实际工作中,如果确实有不同的执行时间,你肯定不会在其中调用 sleep()函数。无论如何,下面是程序的输出结果。