数据增强的原理和指导方法
一、数据增强产生的背景
深度学习网络在处理计算机视觉任务中获得巨大的成功。而这些网络都有着大量的参数,需要大量的数据来学习网络中的参数,从而避免出现过拟合现象。
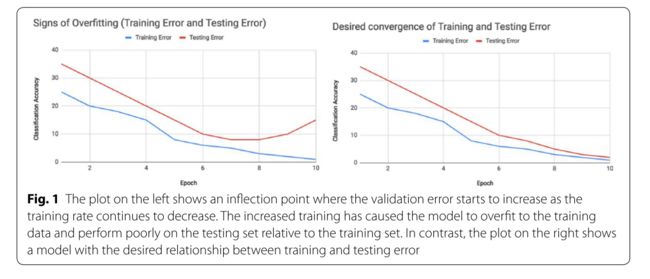
要解决过拟合问题,目前实施的策略主要分为两个方向:
1.模型结构的改进
- Dropout 正则化方法
- Batch Normalization 正则化方法
- 迁移学习
2.数据集的改进
-
数据增强(本节关注的内容)
数据增强是一种解决过拟合问题的非常有效的方法。它假定可以通过增强从原始数据集中提取出更多的信息,使得增强后的数据集代表更为全面的数据集合,进而缩小训练集和验证集之间的差距。
举一个例子:如果有图像分类的任务,目的是识别两类汽车。而我们已有的数据集,福特的汽车都朝向左边,雪佛兰的汽车都朝向右边。

而真实应用场景中,福特的汽车也可能朝向右边。当我们喂给当今最优秀的分类网络一张朝向右边的福特时,它的结果大概率仍然会识别为雪佛兰。
原因在哪儿呢? 我们可以说模型过拟合了,学到了不重要的特征,在测试集上不具有良好的泛化能力。改变的一种方式是可以通过翻转使每个类型的车辆都有左边和右边的图像,就使得网络不会过于关注位置信息,更关注外形、轮廓等信息。
二、数据增强的两种形式
2.1 离线增强
离线数据增强的特点是预先对已有数据集进行所有必要的变换,使得增强后的数据数量变为原始数据数量的N倍(N为增强因子)。
离线数据增强的主要考虑因素是与扩增数据带来的额外内存和计算约束。因此,这种方式更适用于小数据集。
2.2 在线增强
在线数据增强的特点是不需要预先对已有数据集进行所有必要的变换。而是在训练阶段,在线的对图像进行各类转换。
我们知道,对于一个训练过程,设置有多个epoch。对于每个epoch来说,都会对原始数据集进行翻转、旋转、平移等操作按照指定概率的转换。因为每种数据增强方式都包含一个随机因子,那么下一次epoch的训练数据就会生成一批新的数据。
只要训练的epoch 够大,就等价于扩充了原始数据集的N倍数量(N为增强因子)。
在线增强的优点是节省内存空间、不需要额外进行数据预处理。在线增强的缺点是会降低训练速度。
三、数据增强方法
下图是数据增强方法的总览图。里面包括几何变换、颜色空间变换、内核过滤器、混合图像、随机擦除、对抗训练、基于生成对抗网络的增强、神经风格转移 等内容。
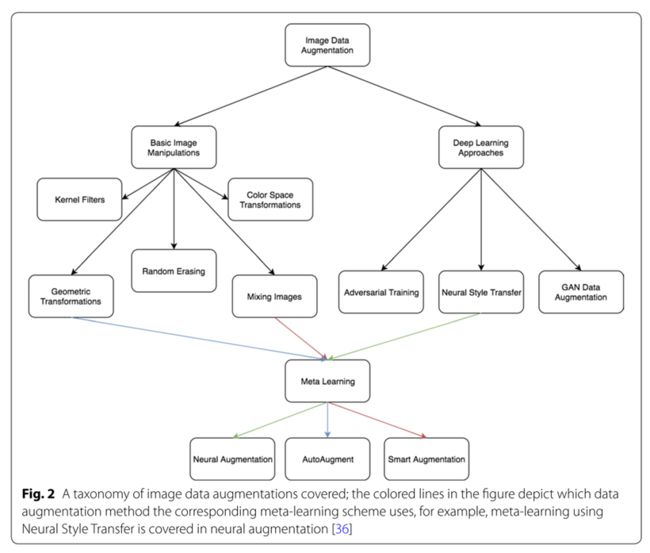
3.1 几何变换
针对于训练数据中存在的位置偏差,几何变换是一种非常好的解决方案。几何变换在所有数据增强方案中最为常用和有效。
挑战:在几何变换的过程中,要考虑应用的“安全性”,即保证变换后的图像仍保持标签不发生改变。
一、翻转
可以选择水平或者垂直翻转图像,且水平翻转比垂直翻转更常用。在ImageNet 和 CIFAR-10等数据集上已经证明是有效的。
但对于有些数据集不支持垂直翻转,比如数字手写体识别,数字6和9的垂直翻转会导致两个数字无法区别。


二、旋转
旋转增强是通过在1和359度之间的轴上左右旋转图像来完成的。旋转增强的安全性在很大程度上取决于旋转度参数。1到20****度之间的轻微旋转可能对数字识别任务(如MNIST)有用,但随着旋转程度的增加,数据的标签在转换后不再保留。
三、平移
向左、向右、向上或向下移动图像是一种非常有用的变换,可以避免数据中的位置偏差。当原始图像在一个方向上平移时,剩余的空间可以用常数值(如0或255)填充,也可以用随机或高斯噪声填充。这种填充保留了图像增强后的空间维度。
注意:图像平移也有可能会数据的标签发生改变。

四、缩放
对图像进行放大或者缩小处理。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像进行裁切。
五、剪裁
随机裁剪:从原始图像随机裁剪一个区域
中心裁剪:从原始图像的中心区域进行裁剪
六、噪声注入
过拟合经常会发生在神经网络试图学习高频特征(即非常频繁出现的无意义模式)的时候,而学习这些高频特征对模型提升没什么帮助。
那么如何处理这些高频特征呢?一种方法是采用具有零均值特性的高斯噪声,它实质上在所有频率上都能产生数据点,可以有效的使高频特征失真,减弱其对模型的影响。
但这也意味着低频的成分(通常是你关心的特征)同时也会受到影响,但是神经网络能够通过学习来忽略那些影响。事实证明,通过添加适量的噪声能够有效提升神经网络的学习能力,即给图像添加噪声可以帮助网络学习更健壮的特征。
3.2 颜色空间变换
光照偏差是图像识别问题中最常见的挑战之一。因此,颜色空间变换的有效性,也称为光度变换。
颜色空间变换包含的方式有随机色调、饱和度、值变化;随机平移R、G、B通道值;随机亮度;随机对比度;
**颜色变换可能会丢弃重要的颜色信息,因此并不总是保持标签的变换。**例如,对于某些任务来说,颜色是一个非常重要的区别特征,这种情况若进行颜色空间转换将消除数据集中存在的有利于空间特征的颜色偏差,以至不利于图像分类识别。

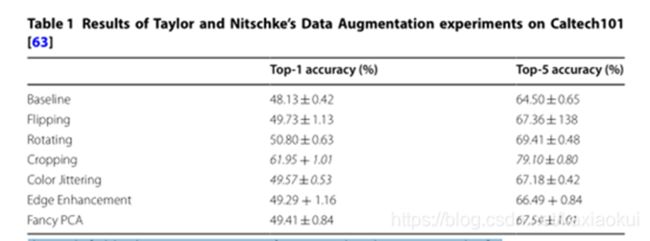
几何、颜色变换的实验效果
在Caltech101数据集上进行了4倍交叉验证,筛选出8421张大小为256 × 256的图像,并对这些扩展进行了测试。研究表明,对于以下方法的对比,剪裁在图像增强过程中的增强效果更加明显。
3.3 内核过滤器
内核过滤器是一种非常流行的图像处理技术,用于锐化和模糊图像。
这些滤镜通过在图像上滑动n × n矩阵来工作,既可以使用高斯模糊过滤(这会导致图像更模糊),也可以使用高对比度垂直或水平边缘过滤(会导致边缘图像更清晰)。
直观地说,用于数据增强的模糊图像可能导致对运动模糊的更高抵抗力。为数据增强而锐化图像可以封装更多感兴趣对象的细节。常用的方法有高斯模糊、运动模糊、中值模糊。

3.4 随机擦除
随机擦除主要应用遮挡的场景,能够减低遮挡偏差。具体原理是随机选择图像的矩形区域,并使用随机值擦除其像素,生成具有遮挡级别的训练图像,会降低过拟合风险并使得模型对遮挡具有一定的鲁棒性。

四、数据增强库的使用与性能分析
Albumentation库
- 支持所有常见的计算机视觉任务,如分类、语义分割、实例分割、目标检测和姿态估计。
- 该库提供了一个简单的统一API来处理所有数据类型:图像(RBG图像、灰度图像、多光谱图像)、分割掩码、边界框和关键点。
- 该库包含70多个不同的扩充,用于从现有数据生成新的训练样本。
- 速度很快。我们对每个新版本进行基准测试,以确保增强提供最大的速度。
- 它适用于流行的深度学习框架,如PyTorch和TensorFlow。
下图是使用Intel Xeon Gold 6140 CPU在ImageNet验证集中的前2000个图像上运行基准测试的结果。所有的输出都转换成一个连续的NumPy数组。该表显示了每秒可在单个核心上处理多少图像,越高越好。
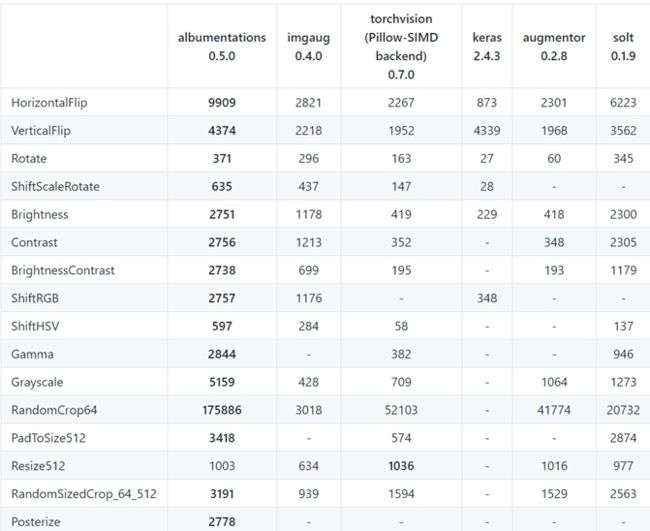
主流数据增强库的使用
torchvision

albumentation
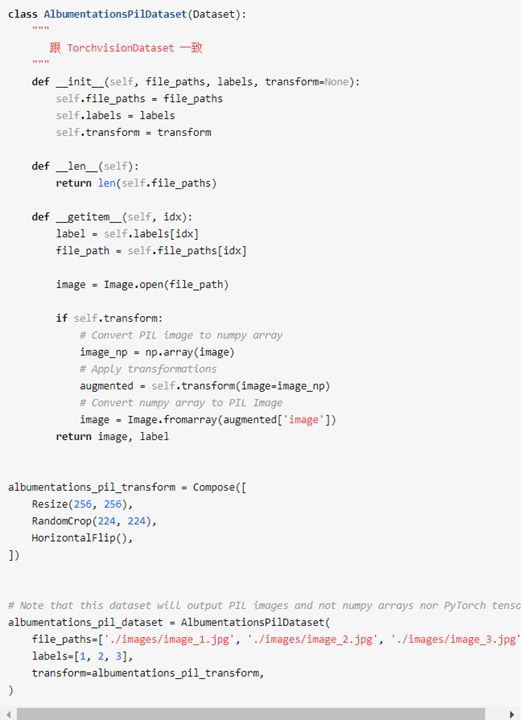
albumentation高级特性

写在最后的话
我将以上内容整理为PDF文档

需要PDF版本的朋友加我好友我发给你
