文本摘要——综述报告
主要内容:
1)文本摘要简介(是什么?)
2)文本摘要现状(怎么样?)
3)文本摘要分类(有哪些?)
4)文本摘要主要技术
5)附页
一、 文本摘要简介(是什么?)
文本摘要是指通过各种技术,对文本或者是文本的集合,抽取、总结或是精炼其中的要点信息,用以概括和展示原始文本的主要内容或大意。随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降维”处理显得非常必要,文本摘要便是其中一个重要的手段。作为文本生成任务的主要方向之一,从本质上而言,这是一种信息压缩技术。文本摘要的目的就是为了让用户在当今世界海量的互联网数据中找到有效的信息。
二、 文本摘要现状(怎么样?)
1、研究热点
随着互联网上的信息呈爆炸式增长,如何从海量信息中提取有用信息成了一个关键的技术问题。文本摘要技术能够从大数据中压缩提炼出精炼简洁的文档信息,有效降低用户的信息过载问题,成为研究热点。
2、研究难点
因为文本摘要技术,尤其是生成式文本摘要,涉及到很深层次的自然语言处理(自然语言理解、自然语言生成等)的能力,所以一直以来它都是自然语言技术的一个研究难点。
3、国际现状
国际上对文本摘要技术已经进行了多年的研究,相关研究成果主要发表在自然语言处理相关学术会议与期刊上,例如ACL、EMNLP、NAACL、COLING、AAAI、IJCAI、SIGIR、INLG等,有很多关于文本摘要技术的研究成果都发表在上面。我已将上面各个学术会议与期刊的简介与网址放在附页一中。
国际上几个主要的研究单位包括密歇根大学、南加州大学、哥伦比亚大学、北德克萨斯大学、爱丁堡大学等。有很多优秀的算法,理论都产自这几所大学。
4、国内现状
相比机器翻译、自动问答、知识图谱、情感分析等热门领域,文本摘要在国内并没有受到足够的重视,主要也是由于有着很多难以突破的难点(很深层次的自然语言处理、自然语言理解、自然语言生成等的能力),在文本摘要方面从事过研究的国内单位包括北京大学计算机科学技术研究所、北京大学计算语言所、哈工大信息检索实验室、清华大学智能技术与系统国家重点实验室等。
其中,北京大学计算机科学技术研究所在文本摘要方面进行了长期深入的研究,提出了多种基于图排序的自动摘要方法与压缩式摘要方法,并且探索了跨语言摘要、比较式摘要、演化式摘要等多种新颖的摘要任务。在学术文献摘要方面,则分别提出基于有监督学习和整数线性规划模型的演示幻灯片的自动生成方法与学术论文相关工作章节的自动生成方法。
国内早期的基础资源与评测举办过单文档摘要的评测任务,但测试集规模比较小,而且没有提供自动化评价工具。2015年CCF中文信息技术专委会组织了NLPCC评测,其中包括了面向微博的新闻摘要任务,提供了规模相对较大的样例数据和测试数据,并采用自动评价方法,吸引了多支队伍参加评测,目前这些数据可以公开获得。但上述中文摘要评测任务均针对单文档摘要任务,目前还没有业界认可的中文多文档摘要数据,这在事实上阻碍了中文自动摘要技术的发展。
5、现状总结
总的来说,国际上对自然语言处理的文本摘要方向已有多年的研究,研究成果也较为丰厚,但是国内由于中文涉及到很多难以突破的难点(很深层次的自然语言处理、自然语言理解、自然语言生成等的能力)得原因,研究成果相比英语的文本摘要相对较少,而且国内相比机器翻译、自动问答、知识图谱、情感分析等热门领域,文本摘要在国内并没有受到足够的重视。
三、 文本摘要分类(有哪些?)
1、按摘要方法分
文本摘要按照摘要方法可以分为抽取式文本摘要、生成式文本摘要和生成-抽取式文本摘要三种。
(1)抽取式文本摘要
抽取式文本摘要,顾名思义,就是从文档或者文档集中抽取其中的一句或者几句话,构成摘要。通过对文档中句子的得分进行计算,得分代表重要性程度,得分越高代表句子越重要,然后通过依次选取得分高的若干个句子组成摘要,摘要的长度取决于压缩率。这种方案的好处在于简单实用,不会完全脱离于文档本身。换言之,域值比较好判断,不容易产生完全偏离文章主旨的点。
(2)生成式文本摘要
抽取式文本摘要尽管有其优点,但也可能有着生成摘要不连贯、字数不好控制、目标句主旨不明确等缺点,甚至可以说,其摘要好坏决定于原文。而生成式文本摘要就没有这样的问题,生成式摘要方法不是单纯地利用原文档中的单词或短语组成摘要,而是从原文档中获取主要思想后以不同的表达方式将其表达出来。生成式摘要方法为了传达原文档的主要观点,可以重复使用原文档中的短语和语句,但总体上来说,摘要需要用作者自己的话来概括表达。生成式摘要方法需要利用自然语言理解技术对原文档进行语法语义的分析,然后对信息进行融合,通过自然语言生成的技术生成新的文本摘要。这也是前面所说的文本摘要技术现阶段的研究难点,因为生成式文本摘要是一个端到端的过程,这种技术方案,趋同于翻译任务和对话任务,从而可以吸收、借鉴翻译任务和对话任务的成功经验。
(3)生成-抽取式文本摘要
凡事都还还想着两全齐美呢,集合抽取式文本摘要和生成式文本摘要的理想技术。
2、按文档数量分
文本摘要按照文档数量可以分为单文档摘要和多文档摘要两种。
(1)单文档摘要
单文档摘要是指针对单个文档,对其内容进行抽取总结生成摘要。
(2)多文档摘要
多文档摘要是指从包含多份文档的文档集合中生成一份能够概括这些文档中心内容的摘要。
3、按学习方法分
文本摘要按照学习方法可以分为有监督摘要和无监督摘要两种。
(1) 有监督摘要
有监督摘要即需要从文件中选取主要内容作为训练数据,大量的注释和标签数据是学习所需要的。这些文本摘要的系统在句子层面被理解为一个二分类问题,其中,属于摘要的句子称为正样本,不属于摘要的句子称为负样本。机器学习中的支持向量机和神经网络也会用到这样分类的方法。
(2) 无监督摘要
无监督的文本摘要系统不需要任何训练数据,它们仅通过对文档进行检索即可生成摘要。
四、 文本摘要主要技术
1、 基于统计学的文本摘要方法
早期的文本摘要方式主要是抽取式文本摘要,基于统计学的文本摘要方法就主要用于抽取式文本摘要。基于统计学的文本摘要方法是基于统计特征,如词频、句子位置、句子与标题的相似性、句子的相对长度等统计特征来生成摘要的。
(1)基于“词频”的文本摘要方法
基于“词频”的文本摘要是指使用“词频” 这一简单的文本特征对文档的重要句子和词组进行抽取生成摘要。
方法介绍:
在基于“词频”的文本摘要方法中,除去停用词以外,文中出现频率越高的单词,其重要性也就越高。根据单词的词频高低分别设置相应的词权重,词频越高,对应的权重也就越高;句子的权重是组成句子单词的权重之和。然后从文档中抽取权重高的单词和句子组成摘要,这就是简单的基于词频的文本摘要方法。
实例演示:
文本:
《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。在看完初舞台之后,很多观众就都清楚了哪些姐姐的实力是不错的,哪些姐姐是比较弱的了。不过呢只看了初舞台就认定姐姐们的实力是片面的了,因为小编发现在这么多“姐姐”中其实有一些姐姐是黑马选手呀。
像是在最新一期节目中,小编就发现了一位“黑马”姐姐,而这个人是谁呢?就是王智了,在最新播出的这一期节目中,王智可是成功逆袭了,她这回成功让观众们看到了她,让导师认可了自己的实力。《浪姐》出现“黑马”姐姐,初舞台最后一名,这一期却连连被夸!说到王智,在初舞台的时候小编对她的印象是不深的。
而在这一期节目中呢当小组在排练的时候,王智会反复跟老师强调自己是“最后一名”,这下小编采知道她原来在初舞台的时候是最后一名。王智在初舞台得到了最后一名,这打击对她来说还是挺大的,在排练的时候大家也可以看出了她的不自信。然而这回她很幸运地遇到了伊能静,在伊能静的教学下,最后她可是受到了老师的连连夸赞。
《浪姐》出现“黑马”姐姐,初舞台最后一名,这一期却连连被夸!此次节目中姐姐们进行了一段时间的练习,就去进行评测了,而在王智这一组表演完后,最终导师们也给出了评价,在她们三个人这一组中,王智就是被夸得最多的那一个。当在看了王智这次的表演后,最后赵兆老师竟然跟她道歉了。
赵兆老师说昨天很抱歉给她打了最低分,但是今天呢她真的让他觉得“傻”了,因为他将这首歌演唱得太好了,他觉得王智非常适合这首歌呢!一向比较严格的赵兆老师这回对王智很是赞扬,看来是被她的表演给惊喜到了。能够得到了专业的赵兆老师的赞扬,可见王智的实力那是很棒的呀。
而在赵兆说完后,黄晓明也补充说道“真的是,你一张嘴我们都惊了,真的。”这次可以从导师们的话中了解到王智的进步真的是很大了,她这次选择了一首合适自己的歌曲,并且有认真努力地去唱好它,就将它很好地诠释了出来了!这个姐姐其实并不是没有实力,只是实力没有一开始就表现出来。她真的是一匹“黑马”了,当看了这一期节目后,现在观众们都在期待着她后面带来的惊喜了!思路:
1)将文本分词,统计一段文本的词频(去除停用词之后的词频),得到{词:词频};
2)对文本进行分句;
3)对句子进行打分,统计这个句子中出现的每个词的词频,句子得分=句子中每个词的词频之和;
4)找到得分最高的几个句子作为摘要。
代码:
#读取文件
f=open('乘风破浪的姐姐.txt',encoding='utf-8')
data = f.readlines() # 直接将文件中按行读到list里,读取后的文件格式为数组
f.close() # 关
#将文件转换成字符串
text=""
for line in data:
text += line
print(text)
#清洗数据
import re #导入库
import jieba
text = re.sub(r'[[0-9]*]',' ',text)#去除类似[1],[2]
text = re.sub(r'\s+',' ',text)#用单个空格替换了所有额外的空格
sentences = re.split('(。|!|\!|\.|?|\?)',text)#分句:re.split(’(。|!|!|.|?|?)’,text) 加括号则保留分句符号如。!,不加则不保留分句符号
print(sentences)
#加载停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='UTF-8').readlines()]
return stopwords
stopwords = stopwordslist("停用词1.txt")
#统计文本词频
word2count = {} #创建一个空字典
for word in jieba.cut(text): #对整个文本分词,对每个单词循环
if word not in stopwords: #检查单词是否在stopwords停用词中,然后再次检查单词是否在word2count词频key中,不在则把word2count [word]置为1,否则word2count [word] 加1。
if word not in word2count.keys():
word2count[word] = 1
else:
word2count[word] += 1
for key in word2count.keys(): #最后对词频归一化
word2count[key] = word2count[key] / max(word2count.values())
print(word2count)
#计算句子得分
sent2score = {} #创建一个空字典
for sentence in sentences: #对sentences中每个sentence进行循环
for word in jieba.cut(sentence): #将sentence分词,对每个word循环
if word in word2count.keys(): #使用if检查word2count.keys()中是否存在该单词
if len(sentence)<200: #这里我指定计算句子长度小于200的那部分,可以根据需要更改
if sentence not in sent2score.keys(): #再次使用if-else条件,判断如果句子不存在于sentence2keys()中,则执行 sent2score [sentence] = word2count [word],否则执行 sent2score [sentence] + = word2count [word]
sent2score[sentence] = word2count[word]
else:
sent2score[sentence] += word2count[word]
print(sent2score)
#字典排序
def dic_order_value_and_get_key(dicts, count): #定义函数
# by hellojesson
# 字典根据value排序,并且获取value排名前几的key
final_result = []
# 先对字典排序
sorted_dic = sorted([(k, v) for k, v in dicts.items()], reverse=True)
tmp_set = set() # 定义集合 会去重元素
for item in sorted_dic:
tmp_set.add(item[1])
for list_item in sorted(tmp_set, reverse=True)[:count]:
for dic_item in sorted_dic:
if dic_item[1] == list_item:
final_result.append(dic_item[0])
return final_result
#选取句子得分最高的5句话作为摘要选取句子得分最高的5句话作为摘要
final_resul=dic_order_value_and_get_key(sent2score,5)
print(final_resul)
(2)TF-IDF(词频−逆向文件频率)方法
TF-IDF也是一种著名的基于统计学的文本摘要方法,这种方法通过词频和逆向文件频率共同评估一个词在一个文件集或语料库中的重要程度,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。然后将句子按照重要性得分排序,依据文本摘要的大小依次选取重要性得分从高到低的若干个句子组成摘要。
TF-IDF是Term Frequency -
Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由TF和IDF两部分组成,TF就是前面说到的词频,关键是后面的这个IDF,即“逆文本频率”如何理解?IDF就是来反映这个词的重要性的,进而修正仅仅用词频表示的词特征值。概括来讲, IDF反映一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低;而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高;极端情况是一个词在所有的文本中都出现,那么它的IDF值应该为0。
上面从定性上说明了IDF的作用,那么如何对一个词的IDF进行定量分析计算呢?这里直接给出一个词x的IDF的基本公式如下:
![]()
其中,N代表语料库中文本的总数,N(x)代表语料库中包含词x的文本总数。
但是在一些特殊情况下上面的公式会有一些小问题,比如某一个生僻词在语料库中没有,则分母为0,那么IDF就没有意义了。所以我们经常需要对IDF做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。平滑的方法有很多种,最常见的IDF平滑后的公式之一如下:
![]()
进而可以计算某一个词的TF-IDF值:
![]()
计算方法:
- TF=(该词在文件中的出现次数)/(在文件中所有字词的出现次数之和)
- IDF=(语料库中的文件总数)/(包含该词语的文件数目)
- 最后计算TF*IDF
# -*-coding:utf-8 -*-
# 在词袋模型中,文档的特征就是其包含的word,corpus的每一个元素对应一篇文档
texts = [['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'use', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
# 训练语料的预处理,将原始文本特征表达转换成词袋模型对应的系数向量
from gensim import corpora
# from gensim.models.word2vec import Word2Vec
dictionary = corpora.Dictionary(texts) # texts就是若干个被拆成单词集合的文档的集合,而dictionary就是把所有单词取一个set(),并对set中每个单词分配一个Id号的map
print(dictionary)
# 是把文档 doc变成一个稀疏向量,[(0, 1), (1, 1)],表明id为0,1的词汇出现了1次,至于其他词汇,没有出现,在这里可以看出set()中computer的id是0,human的id是1...
corpus = [dictionary.doc2bow(text) for text in texts]
print(corpus) # 输出为[(0, 1), (1, 1), (2, 1)],就表示id为0,1,2,即单词computer,human,interface,在第一个维度中都出现了一次
# tf-idf的计算
from gensim import models
tfidf = models.TfidfModel(corpus)
print(tfidf)
doc_bow = [(0, 1), (1, 1)]
print(tfidf[doc_bow])
print(tfidf.idfs)
~
基于统计学的文本摘要方法主要适用于格式相对比较规范的文档摘要。此类方法比较经典,首次在自动文本摘要方面取得了重大突破,但由于此类方法只是基于句子和单词本身的表层特征进行统计,未能充分利用词义关系、词间关系等特征,所以还有很大的局限性,因此针对这些问题,一些改进的方法随后被接连提出。
2、基于图排序的方法
互联网网页上的文档具有较松散且涉及主题较多的结构特点,在此基础上,研究出了一些专门针对生成网页文档摘要的自动摘要技术,就是基于图排序的文本摘要的方法。
基于图排序的文本摘要的主要方法是通过把文章分成若干个段落或句子的集合,每个集合对应一个图的顶点,集合之间的关系对应边,后通过图排序的算法(如 PageRank、HITS等)计算各个顶点后的得分,然后依据得分高低生成文本摘要。
(1) PageRank算法
算法来源:
这个要从搜索引擎的发展讲起。最早的搜索引擎采用的是分类目录的方法,即通过人工进行网页分类并整理出高质量的网站。那时Yahoo 和国内的hao123 就是使用的这种方法。
后来网页越来越多,人工分类已经不现实了。搜索引擎进入了文本检索的时代,即计算用户查询关键词与网页内容的相关程度来返回搜索结果。这种方法突破了数量的限制,但是搜索结果不是很好。因为总有某些网页来回地倒腾某些关键词使自己的搜索排名靠前。
后来,谷歌的两位创始人,当时还是美国斯坦福大学
(Stanford University) 研究生的佩奇 (Larry Page) 和布林 (Sergey Brin) 开始了对网页排序问题的研究。他们借鉴了学术界评判学术论文重要性的通用方法,那就是看论文的引用次数。由此想到网页的重要性也可以根据这种方法来评价。于是就诞生了PageRank的核心思想:
1、如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
2、如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高
相应的代码:
# -*- coding: utf-8 -*-
from pygraph.classes.digraph import digraph
class PRIterator:
__doc__ = '''计算一张图中的PR值'''
def __init__(self, dg):
self.damping_factor = 0.85 # 阻尼系数,即α
self.max_iterations = 100 # 最大迭代次数
self.min_delta = 0.00001 # 确定迭代是否结束的参数,即ϵ
self.graph = dg
def page_rank(self):
# 先将图中没有出链的节点改为对所有节点都有出链
for node in self.graph.nodes():
if len(self.graph.neighbors(node)) == 0:
for node2 in self.graph.nodes():
digraph.add_edge(self.graph, (node, node2))
nodes = self.graph.nodes()
graph_size = len(nodes)
if graph_size == 0:
return {}
page_rank = dict.fromkeys(nodes, 1.0 / graph_size) # 给每个节点赋予初始的PR值
damping_value = (1.0 - self.damping_factor) / graph_size # 公式中的(1−α)/N部分
flag = False
for i in range(self.max_iterations):
change = 0
for node in nodes:
rank = 0
for incident_page in self.graph.incidents(node): # 遍历所有“入射”的页面
rank += self.damping_factor * (page_rank[incident_page] / len(self.graph.neighbors(incident_page)))
rank += damping_value
change += abs(page_rank[node] - rank) # 绝对值
page_rank[node] = rank
print("This is NO.%s iteration" % (i + 1))
print(page_rank)
if change < self.min_delta:
flag = True
break
if flag:
print("finished in %s iterations!" % node)
else:
print("finished out of 100 iterations!")
return page_rank
if __name__ == '__main__':
dg = digraph()
dg.add_nodes(["A", "B", "C", "D", "E"])
dg.add_edge(("A", "B"))
dg.add_edge(("A", "C"))
dg.add_edge(("A", "D"))
dg.add_edge(("B", "D"))
dg.add_edge(("C", "E"))
dg.add_edge(("D", "E"))
dg.add_edge(("B", "E"))
dg.add_edge(("E", "A"))
pr = PRIterator(dg)
page_ranks = pr.page_rank()
print("The final page rank is\n", page_ranks)
~PageRank算法的缺点:
1、没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现PageRank值的传递关系。
2、没有过滤广告链接和功能链接(例如常见的“分享到微博”)。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
3、对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高PR值的页面仍需要很长时间的推广。
3、 基于机器学习的方法
有监督的机器学习方法今年来在自然语言处理领域也得到了极其广泛的利用。全监督、半监督的机器学习方法通过对数据集的语料进行人工标注,人为地判定划分得到句子的文本特征以及句子重要性的关系模型,在此模型的基础上,对未被标注的语料进行训练,预测未被标注语料中句子的重要性排序,然后依据句子重要性排序,依次选取若干句子生成后所需要的文本摘要。
要将自然语言处理的问题转化成为一个机器学习的问题,首先需要让机器能够理解自然语言,所以第一步就是将自然语言转化为机器可以理解的语言,于是想到将它进行符号数学化,为了能表示多维特征,增强其泛化能力,想到用向量对其进行表示,因此也就引出了对词向量、句向量的研究。但是词向量和句向量的生成仍然具有一定的难度,将文本中不同单词、句子用词向量或句向量进行唯一的表示,这样可以方便其在自然语言处理过程中进行各种操作变换和计算。
虽然现在看来将文本中的词、句转化成唯一对应的词、句向量还具有相当大的难度,但由于其在自然语言理解中是关键的一步,因此这将是今后研究中仍待解决的问题和重点研究的方向之一。
4、 基于深度学习的方法
深度学习是利用多层感知器结构对非线性信息进行处理的一种学习方法。
目前深度学习方法在对自然语言处理方面的基本方向是通过对文档上下文进行学习训练,对于中文文档,还需要先进行中文分词处理,然后将文档中的词语、句子分别用连续实值向量进行表示,形成的向量称为嵌入向量,这样做是为了方便处理文本语义特征,将词语、句子用向量表示,在处理文本语义特征时,对词向量、句向量直接进行向量上的计算即可表征它们之间的文本语义关系。
将文本中的词、句转化成唯一对应的词、句向量还具有相当大的难度,但由于其在自然语言理解中是关键的一步,因此这将是今后研究中仍待解决的问题和重点研究的方向之一。
Sequence-to-Sequence模型广泛应用于机器翻译、语音识别、视频图片处理、文本摘要等多个领域。现在新的一些基于深度学习研究文本摘要生成方法的也都是基于这个模型进行的。
基于Seqence-to-Sequence模型的文本摘要需要解决的问题是从原文本到摘要文本的映射问题。先是基于递归神经网络(RNN )的 Seqence-to-Sequence 模型用于文本摘要起到了一定的效果,之后考虑到RNN具有长程依赖性,为了减小长程依赖性,提出了基于长短时记忆网络(LSTM)的Seqence-to-Sequence模型用于文本摘要的生成。考虑到句子中的某些特定词或特定词性的词更具有影响句子中心意思的作用,引入了广泛应用于机器翻译中的注意力机制(attentionmechanism)对句子的不同部分赋予不同的偏重,即权重。
Sequence-to-Sequence Models:
在NLP领域,sequence to sequence模型有很多应用,比如机器翻译、自动应答机器人等。在看了一些相关的论文后,很多都感觉非常晦涩难懂,
在NLP中最为常见的模型是language model,它的研究对象是单一序列,而sequence to sequence模型同时研究两个序列。经典的sequence-to-sequence模型由两个RNN网络构成,一个被称为“encoder”,另一个则称为“decoder”,前者负责把variable-length序列编码成fixed-length向量表示,后者负责把fixed_length向量表示解码成variable-length序列输出,它的基本网络结构如下: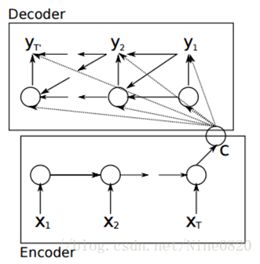
其中每一个小圆圈代表一个cell,比如GRUcell、LSTMcell、multi-layer-GRUcell、multi-layer-GRUcell等。这里比较直观的解释就是,encoder的最终隐状态c包含了输入序列的所有信息,因此可以使用c进行解码输出。尽管“encoder”或者“decoder”内部存在权值共享,但encoder和decoder之间一般具有不同的一套参数。在训练sequence-to-sequence模型时,类似于有监督学习模型,最大化目标函数。
Github源代码解析
整个工程主要使用了四个源文件,seq2seq.py文件是一个用于创建sequence-to-sequence模型的库,data_utils.py中包含了对原始数据进行预处理的一些操作,seq2seq_model.py用于定义machine
translation模型,translate.py用于训练和测试所定义的翻译模型。
由于找到的论文和博客对我来说难度过大,晦涩难懂,时间原因,暂时没有理解透彻具体的源代码实现,就不在这里说明。
5、 各方法优缺点分析
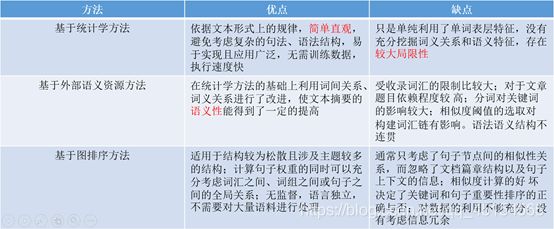
原文链接:
https://blog.csdn.net/qq_45154565/article/details/109173981