经典论文-卷积神经网络可视化与理解及实践
Visualizing and Understanding Convolutional Networks
卷积神经网络的可视化与理解
-
作者:Matthew D. Zeiler, Rob Fergus
-
单位:纽约大学
-
文章地址:https://arxiv.org/abs/1311.2901
-
项目地址:https://github.com/sar-gupta/convisualize_nb
摘要
大型卷积网络模型最近在ImageNet基准测试上表现出了令人印象深刻的分类性能(Krizhevesty等人,2012)。然而,目前还不清楚为什么它们表现得如此好,也不清楚如何改进。在本文中,讨论了这两个问题。本文介绍了一种新的可视化技术,可以深入了解中间特征层的功能和分类器的操作,作为一个诊断工具使用,这些可视化允许我们找到在ImageNet分类基准上优于Krizhevsky等人的模型架构。此外还进行了一项消融实验研究,以发现来自不同模型层的性能贡献。最后展示了我们的ImageNet模型可以很好地推广到其他数据集:当softmax分类器被再训练时,它令人信服地击败了目前在加州理工101和加州理工256数据集上的最先进的结果。
1 引言
自20世纪90年代初被(LeCunetal.,1989)引入以来,卷积网络(convnets)在手写数字分类和人脸检测等任务上表现出了出色的性能。在过去的一年中,一些论文表明,它们在更具挑战性的视觉分类任务上也能提供出色的表现。(Ciresan等人,2012年)在NORB和CIFAR-10数据集上展示了最先进的性能。最值得注意的是,(Krizhevestetal.,2012)在ImageNet2012分类基准上获得了16.4%的错误率,而第二名的错误率为26.1%。有几个因素导致了这种有趣的现象:(i)大量的已标注的训练数据;(ii)强大的 GPU训练;(iii)更好的正则化方法如 Dropout(Hinton et al,2012)
尽管取得了这些令人鼓舞的进展,但对于这些复杂模型的内部操作和行为,以及它们如何实现如此好的性能,我们仍然知之甚少。从科学的角度来看,这是非常不令人满意的。如果不清楚地理解它们是如何以及为什么工作的,更好的模型的开发就会被简化为不断的试错。在本文中,我们介绍了一种可视化技术,它揭示了刺激模型中任何一层的单个特征映射的输入刺激。它还允许我们在训练过程中观察特征的演变,并诊断模型的潜在问题。我们提出的可视化技术是使用的多层反卷积网络(反卷积网络,Zeileretal 2011),将特征激活投影回输入像素空间。我们还通过遮挡输入图像的部分来对分类器输出进行敏感度分析,揭示了场景图像中的哪些部分对分类器是重要的。
使用这些工具,我们从(Krizhevesk等人,2012)的架构开始,探索不同的架构,发现在ImageNet上优于其结果的架构。然后,探索了模型对其他数据集的泛化能力,只需在网络头部重新训练softmax分类器。因此,这是一种有监督的预训练形式,该方式与(Hinton等,2006)和其他(Bengio等,2007)推广的无监督预训练方法形成对比;
1.1 相关工作
可视化特征以获得对网络的直觉是一种常见的做法,但大多局限于第一层,其中对像素空间的投影是可能的。在更高的层次中,情况并非如此,而且解释活动的方法也很有限。(Erhanetal,2009)通过在图像空间中进行梯度下降来寻找每个单元的最佳刺激,以最大限度地提高单元的激活量,这需要仔细的初始化,并且不提供任何关于单元不变性的信息。由于后者的不足,(Leetal.,2010)(扩展了(Berkes&Wiskott,2006))展示了如何围绕最优响应数值计算给定单元的黑塞矩阵,提供了对不变性的一些见解。问题是,对于更高的层,不变性是非常复杂的,所以不能通过一个简单的二次近似法描述。相比之下,我们的方法提供了一个非参数化的不变性视图,显示了来自训练集中的哪些模式激活了特征映射。(Donahueetal 2013)显示了在数据集中识别补丁(patches)的可视化,这些补丁负责在模型中更高层的强激活。我们的可视化的不同之处在于,它们不仅是输入图像的裁剪(crop),而是自上而下的投影,揭示了每个补丁中刺激特定特征地图的结构。
2 方法
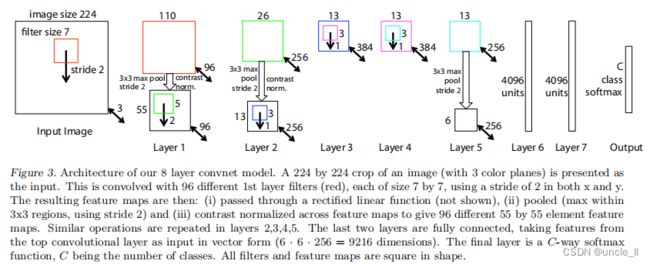
本文采用了由(LeCun etal. 1989)以及(Krizhevsky etal 2012)提出的标准的有监督学习的卷积网络模型,该模型通过一系列隐藏层,将输入的二维彩色图像映射成长度为C的一维概率向量,向量的每个概率分别对应 C 个不同分类,每层包含以下部分:
- 1 卷积层,每个卷积图都由前面一层网络的输出结果(对于第一层来说,上层输出结果就是输入图片),与学习获得的卷积核进行卷积运算
- 2 修正线性激活层,对每个卷积结果都进行激活运算 r e l u ( x ) = M a x ( 0 , 1 ) relu(x) = Max(0, 1) relu(x)=Max(0,1)
- 3 [可选]池化层(max pooling),对激活运算结果进行邻域内的 max pooling 操作,获得降采样图
- 4 [可选] 对降采样图进行对比度归一化操作,使得输出特征平稳。更多操作细节,请参考(Krizhevsky et al 2012)以及(Jarrett et al 2009)
- 5.全连接层,模型最顶部少量的全连接层,输出层是一个 Softmax 分类器,图3上部展示了这个模型
我们使用 N 张已标记的图片 ( x , y ) (x, y) (x,y)构成的数据集来训练模型,其中标签$ y_i$ 是一个离散变量,用来表示图片的类别。用交叉熵损失函数来评估输出标签$ y_i^hat$ 和真实标签 y i y_i yi 的差异。整个网络参数(包括卷积层的卷积核,全连接层的权值矩阵和偏置值)通过反向传播算法进行训练,选择随机梯度下降法更新权值,具体细节参见章节3。
2.1 反卷积可视化
要想深入了解卷积网络,就需要了解中间层特征的作用。本文将中间层特征反向映射到像素空间,观察出什么输入会导致特征图中激活值的输出,可视化过程基于(Zeiler et al 2011)提出的反卷积网络实现。一层反卷积网可以看成是一层卷积网络的逆操作,他们拥有相同的卷积核和 pooling函数(准确来讲,应该是逆函数),因此反卷积网是将输出特征逆映射成输入信号。在(Zeiler et al 2011)中,反卷积网络被用作无监督学习,本文仅仅只是用来进行可视化演示,类似于一个探针,并不参与网络的训练。
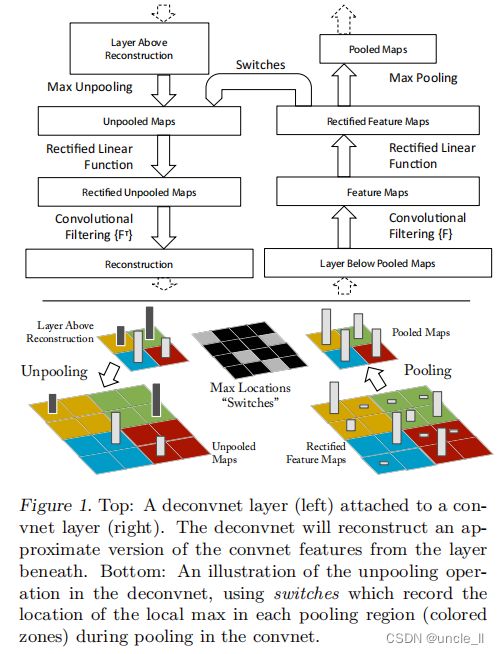
为了查看卷积网络,在本文的模型中,卷积网络的每一层都附加了一个反卷积层,参见图1,提供了一条由输出特征到输入图像的反通路。首先,输入图像通过卷积网模型,每层都会产生特定特征。之后,我们将反卷积网中观测层的其他连接权值全部置零,将卷积层产生的特征当做输入,送到对应的反卷积层,依次进行以下操作:
- 1 unpool,反池化操作;
- 2 rectify, 与卷积层一样的修正线性激活relue;
- 3 反卷积(过滤器重建下面层的活动,产生所选择的激活。然后重复此操作直至达到输入像素空间)
unpooling
严格来讲,max pooling 操作是不可逆的,本文用了一种近似方法来计算 max pooling 的逆操作:在卷积操作执行 max pooling 过程中,用 Max locations “Switches”表格记录下每个最大值的位置,在 unpooling 过程中,将最大值标注回记录所在位置,其余位置填 0,图1底部显示了这一过程。即在训练过程中记录每一个池化操作的 z*z 的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补0。
Rectifification
在卷积网络中,为了保证特征的有效性,通过 relu 非线性函数来保证所有输出都为非负数,这个约束对反卷积过程依然成立,因此将重构信号也送入到 relu 函数中。
Filtering
卷积神经网络使用学习到的滤波器对上一层的特征映射进行卷积。为了实现逆过程,**反卷积网络使用相同卷积核的转置作为卷积核,与矫正后的特征进行卷积运算。**反卷积其实是一个误导,真正的名字应该是转秩卷积。
在 unpooling过程中,由于“Switches”只记录了极大值的位置信息,其余位置均用 0 填充,因此重构出的图片看起来会不连续,很像原始图片中的某个碎片,这些碎片就是训练出高性能卷积网的关键。由于这些重构图像不是从模型中采样生成,因此中间不存在生成式过程。
3 训练细节
图3中的网络模型与(Krizhevsky et al 2012)使用的卷积模型很相似,不同点在于:
- Krizhevsky在3, 4, 5层使用的是稀疏连接(由于该模型被分配到了两个 GPU上),而本文用了稠密连接;
- 另一个重要的不同将在章节4.1 和 图6中详细阐述;
本文选择了 ImageNet 2012 作为训练集(130万张图片,超过 1000 个不同类别),首先截取每张 RGB图片最中心的 256 x 256 256x256 256x256区域,然后减去整张图片颜色均值,再截出 10 个不同的 224 x 224 224x224 224x224 窗口(四个角+中心,翻转x2)。采用随机梯度下降法学习,batchsize选择128, 学习率选择 0.01,动量系数选择 0.9;当误差趋于收敛时,手动调整学习率:Dropout 策略(Hinton et al 2012)运用在全连接层中,系数设为 0.5,所有权值初始化值设为 0.01, 偏置值设为0。
图6(a)展示了部分训练得到的第1层卷积核,其中有一部分核数值过大,为了避免这种情况,我们采取了如下策略:均方根超过 0.1 的核将重新进行归一化,使其均方根为 0.1。该步骤非常关键,因为第1层的输入变化范围在 [-128, 128]之间。前面提到我们通过滑动窗口截取和对原始图像的水平翻转来提高训练集的大小,这一点和(Krizhevsky et al 2012)相同。整个训练过程基于(Krizhevsky et al 2012)的代码实现,在单块 GTX580 GPU 上进行,总共迭代了 70个epoch,耗时12天。

4 卷积网络可视化
通过上述描述的网络结构框架,本节使用反卷积网来可视化ImageNet验证集上的特征激活。
特征可视化
图2展示了训练结束后,模型中各个隐含层提取的特征,图2显示了在给定输出特征的情况下,反卷积层产生的最强的9个输入特征。将这些计算所得的特征,用像素空间表示后,可以清楚的看到:一组特定的输入特征(通过重构获得),将刺激卷积网络产生一个固定的输出特征。这一点解释了为什么当输入存在一定畸变时,网络的输出结果保持不变。在可视化结果的右边是对应的输入图片,和重构特征相比,输入图片之间的差异性很大,而重构特征只包含哪些具有判别能力纹理结构。举例说明:层5第1行第2列的9张输入图片各不相同,差异很大,而对应的重构输入特征则都显示背景中的草地,而不是显示前景中的物体。
每层的可视化结果都展示了网络的层次化特点。层2展示了物体的边缘和轮廓,以及与颜色的组合;层3拥有了更复杂的不变性,捕获类似的纹理(例如:第1行第1列的网格模型;第2行第4列的花纹);层4不同组重构特征存在着重大差异性,开始体现类与类之间的差异:狗狗的脸(第一行第一列),鸟的腿(第4行第2列);层5显示了具有显著姿态变化的整个物体,例如:键盘(第1行第1列),狗(第4行)

特征在训练过程中的演化
图4展示了在训练过程中,由特定输出特征反向卷积,所获得的最强重构输入特征(从所有训练样本中选出)是如何演化的,当输入图片中的最强刺激源发生变换时,对应的输出特征轮廓发生跳变。经过一定次数的迭代后,底层特征趋于稳定。但更高层的特征则需要更多的迭代才能收敛(约 40~50个周期),这表明:需要让模型训练直到所有层都收敛时,模型的效果才会比较好。

特征不变性
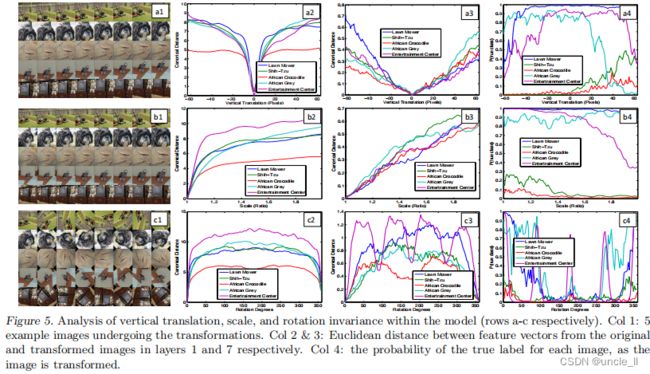
图5展示了5个不同的例子,他们分别被平移,旋转和缩放,同时观察模型顶部和底部各层的特征向量的变化。图5右边显示了不同层特征向量所具有的不变性能力。在第1层,很小的微变都会导致输出特征变换明显,但越往高层走,平移和尺度变换对最终结果的影响越小。总体来说:卷积网络无法对旋转操作产生不变性,除非物体具有很强的对称性。
4.1 网络结构选择
对训练过的模型的可视化可以深入了解其操作,此外,它还可以首先帮助研究者选择更好的架构。通过可视化Krizhevsky 等人的第一层和第二层的架构(图6(b)和(d)),各种问题都是显而易见的。第一层滤波器是极高和低频信息的混合,很少覆盖中频。此外,第二层可视化显示了由第一层卷积中使用的大步幅4造成的混叠伪影。为了解决这些问题,对模型进行了改进:
- (i) 将第一层滤波器的大小从11x11减少到7x7;
- (ii) 使卷积的步幅为2,而不是4。
这种新的架构在第一层和第二层的特征中保留了更多的信息,如图6©&(e)所示。更重要的是,它还提高了分类性能;

4.2 遮挡敏感性
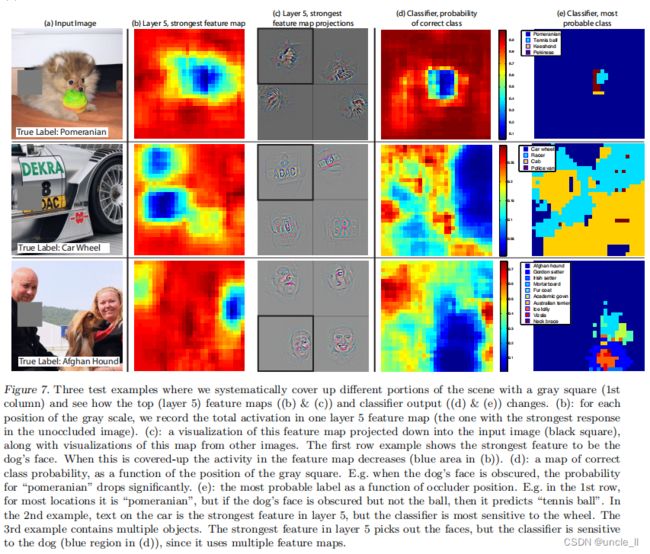
对于图像分类方法,一个很自然的问题是,模型是否真的识别出了物体在图像中的位置,还是仅仅使用了周围的上下文。图7试图通过用灰色方块系统地遮蔽输入图像的不同部分,并监控分类器的输出来回答这个问题。这些例子清楚地表明,该模型正在定位场景中的对象,因为当对象被遮挡时,正确的类的概率会显著下降。图7还显示了从顶部卷积层的最强特征图中的可视化,以及该图中的活动(空间位置的总和)作为遮挡块的函数。当遮挡块覆盖可视化中出现的图像区域时,会看到特征图中活动的强烈下降。这表明,可视化确实对应于刺激该特征图的图像结构,从而验证了图4和图2中所示的其他可视化。
4.3 相关性分析
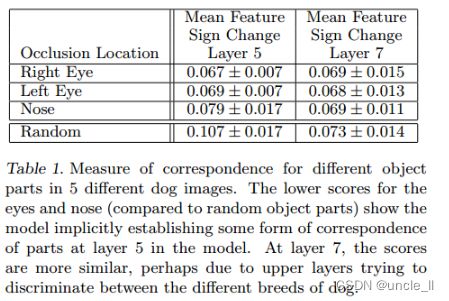
深度模型与许多现有的识别方法的不同之处在于,没有明确的机制来建立不同图像中特定对象部分之间的对应关系(例如,人脸具有眼睛和鼻子的特定空间配置)。然而,一个有趣的可能性是,深度模型可能正在隐式地计算它们,为了探索这一点,随机抽取了5张正面姿势的狗狗图像,并系统性地挡住狗狗所有照片的一部分(例如:所有的左眼,参见图8)。对于每张图I,计算:
![]()
其中 x i l xi^l xil 和 x i h l xi^{h_l} xihl 分别表示原始图片和被遮挡图片所产生的的特征,然后测量所有图片对(i, j)的误差向量 epsilon 的一致性:
![]()
其中,H 是 Hamming distance, Δ l Δ_l Δl 值越小,对应操作对狗狗分类的影响越一致,就表明这些不同图片上被遮挡的部件越存在紧密联系。表1 中对比了遮挡左眼,右眼,鼻子的 Δ 比随机遮挡的 Δ 更低,说明眼睛图片和鼻子图片内部存在相关性。第5层鼻子和眼睛的得分差异明显,说明第5层卷积网对部件级(鼻子,眼睛等等)的相关性更为关注;第7层各个部分得分差异不大,说明第7层卷积网络开始关注更高层的信息(狗狗的品种等等)。
5 实验
5.1 ImageNet 2012
该图像库共包含了(130万/5万/10万)张(训练/验证/测试)样例,种类数超过 1000。表2显示了本文模型的测试结果。
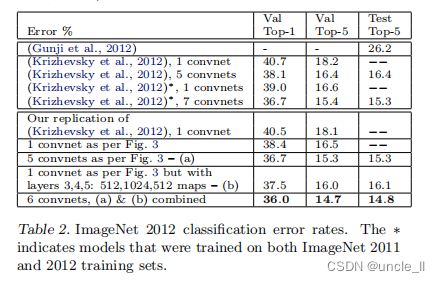
首先,本文重构了(Krizhevsky et al 2012)的模型,模型在验证集上的错误率与作者给出的错误率十分一致,误差在 0.1%以内,将其作为参考标准。
之后,本文将第1层的卷积核大小调整为 7*7,将第1层和第2层卷积运算的步长改为2,模型结构如图3所示,获得了相当不错的结果,与(Krizhevsky et al 2012)相比,错误率为 14.8%,比(Krizhevsky et al 2012)的 15.3% 提升了0.5 个百分点。注意到,这个误差几乎是ImageNet2012分类挑战中非卷积算法(26.2%的误差)的一半。
改变ImageNet模型大小:在表3中,首先通过调整层的大小或完全删除它们来探索(Krizhevestetal.,2012)的体系结构。在每种情况下,模型都是通过修改后的体系结构从头开始进行训练的。移除全连接的层(6,7)只会略微增加误差,这是令人惊讶的,因为它包含了大多数的模型参数。去除两个中间的卷积层也会使错误率的差异相对较小。然而,同时去掉中间的卷积层和全连接的层,就会得到一个只有4个层的模型,其性能明显更差。这将表明,模型的整体深度对于获得良好的性能是很重要的。在表3中,修改了模型,如图3所示。改变全连接层的大小对性能影响不大(模型相同(Krizhevestetal.,2012))。然而,增加中间卷积层的大小会给性能提供有用的好处。但是增加这些层,同时也扩大完全连接的层会导致过拟合。

5.2 特征泛化
上面的实验显示了我们的 ImageNet 模型的卷积部分在获得sota的重要性。由图2 的可视化支持,它显示了卷积层中的复杂不变性。现在探索这些特征提取层的能力,以推广到其他数据集,即 Caltech-100(Feifei 等人, 2006),Caltech-256(Grifffi等人, 2006)和 PASCAL VOC 2012。为此,我们将 在ImageNet 数据上训练的模型的第1~7层固定并使用新数据集的训练图像在最上面训练一个新的 Softmax 分类器(使用适当的类别数)。由于Softmax包含的参数相对较少,因此可以从相对较小的示例中快速训练。
我们的模型所使用的分类器(softmax)和其他方法(通常是线性SVM)具有相似的复杂性,因此实验将我们从ImageNet学习到的特征表示与其他方法使用的手工制作的特征进行了比较。值得注意的是,我们的特征表示和手工制作的特征都是使用Caltech和 PASCAL训练集之外的图像来设计的。例如,HOG描述符中的超参数是通过在行人数据集上的系统实验来确定的(Dalal&Triggs,2005)。我们还尝试了第二种策略,即从头开始训练一个模型,即将第1-7层重置为随机值,并对数据集的训练图像进行训练,以及softmax。
一个复杂的问题是,Caltech的一些数据集有一些图像也在ImageNet的训练数据中。使用归一化相关性,识别到了这些少数“重叠”图像,并将它们从我们的训练集中删除,然后重新训练图像模型,以避免训练/测试污染的可能性。
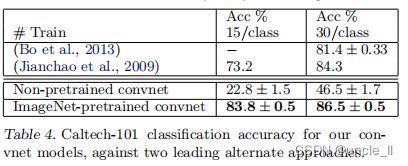
Caltech-101:遵循(Fei-fei等 ,2006)的程序,每类随机选择15或30幅图像进行训练,每类测试50幅图像,表4中报告了每类准确度的平均值,使用 5次训练/测试折叠。训练 30张图像/类的数据用时 17分钟。预先训练的模型在 30幅图像/类上的结果比(Bo et al 2013)的成绩提高 2.2%,然而,从零开始训练的 Convnet 模型非常糟糕,只能达到 46.5%。说明基于 ImageNet 学习到的特征更有效。
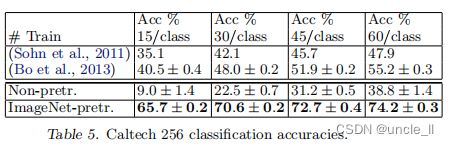
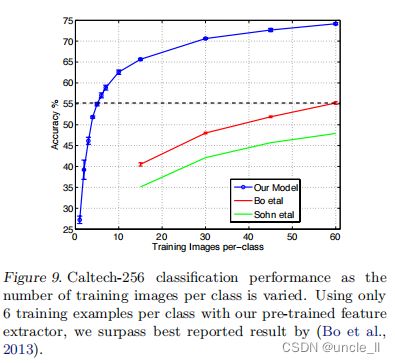
Caltech-256:遵循(Griffin et al 2006)的测试方法进行测试,为每个类选择15, 30, 45,或 60 个训练图片,结果如表5所示,基于ImageNet预先学习的模型在每类 60 训练图像上以准确率高出 19% (74.2% VS 55.2%)的巨大优势击败历史最好的成绩。图9从另一个角度(一次性学习)描述了基于 ImageNet 预训练模型的成功,只需要6张 Caltech-256训练图像即可击败使用10倍图像训练的先进方法,这显示了ImageNet特征提取器的强大功能。
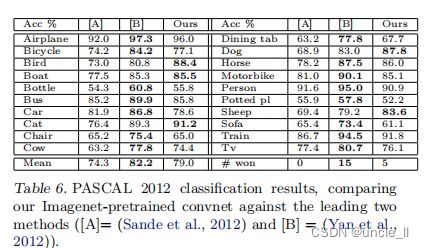
PASCAL 2012:使用标准的训练和验证图像在ImageNet预训练的网络顶部训练20类Softmax。这并不理想,因为 PASCAL 图像可以包含多个对象,而模型仅为每个图像提供一个单独的预测。表6显示了测试集的结果。PASCAL 和 ImageNet 的图像本质上是完全不同的,前者是完整的场景而后者不是。这可能解释我们的平均表现比领先(Yan et al 2012)的结果低 3.2%,但是在 5类的结果上击败了他们,有时甚至大幅度上涨。
5.3 特征分析
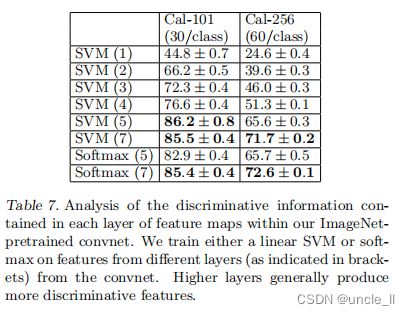
我们研究了 ImageNet 预训练模型在每一层如何区分特征的,通过改变 ImageNet模型中的层数来完整这一工作,并将线性SVM 或者 Softmax 分类器置于顶层。表7显示了 Caltech-101 和 Caltech-256 的结果。对于这两个数据集,当我们提升模型时,可以看到一个稳定的改进,通过使用所有的层都可以得到最好的结果。该结果证明了:当深度增加时,网络可学到更好的特征。
6 讨论
我们以多种方式探索了大型神经网络模型,并对图像分类进行了训练。首先,提出了一种新颖的方式来可视化模型中的活动。这揭示了这些特征不是随机的,不可解释的模式。相反,提升模型时,他们显示出许多直观上令人满意的属性,例如组合性,增强不变性和类别区别等。此外,还展示了如何使用这些可视化来调试模型的问题以获得更好的结果,例如改进(Krizhevsky et al 2012)令人印象深刻的 ImageNet 2012 结果。然后,通过一系列遮挡实验证明,**该模型虽然训练了分类,但是对图像局部结构高度敏感,并不仅仅使用广阔的场景环境。**对该模型的进一步研究表明,对网络而言,具有最小的深度而不是单独的部分对模型的性能至关重要。
最后展示了 imageNet 训练模型如何很好地推广到其他数据集。对于Caltech-101 和 Clatech-256,数据集足够相似,以至于我们可以击败最好的结果,在后一种情况下,结果有一个显著的提高。迁移学习带来了对具有小(数量级1000)训练集的基准效用的问题。我们的卷积模型对 PASCAL 数据的推广程度较差,这可能源于数据集偏差(Torrarba & Efors, 2011),虽然它仍处理报告的最佳结果的 3.2%之内。例如,如果允许对每个图像的多个对象的使用不同的损失函数,我们的性能可能会提高。这自然也能使网络能够很好地处理对象检测。
参考
[1] Bengio, Y., Lamblin, P., Popovici, D., and Larochelle, H. Greedy layer-wise training of deep networks. In NIPS, pp. 153–160, 2007.
[2] Berkes, P. and Wiskott, L. On the analysis and in terpretation of inhomogeneous quadratic forms as receptive fifields. Neural Computation, 2006.
[3] Bo, L., Ren, X., and Fox, D. Multipath sparse coding using hierarchical matching pursuit. In CVPR, 2013.
[4] Ciresan, D. C., Meier, J., and Schmidhuber, J. Multi column deep neural networks for image classifification. In CVPR, 2012.
[5] Dalal, N. and Triggs, B. Histograms of oriented gradients for pedestrian detection. In CVPR, 2005.
[6] Donahue, J., Jia, Y., Vinyals, O., Hoffffman, J., Zhang, N., Tzeng, E., and Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In arXiv:1310.1531, 2013.
[7] Erhan, D., Bengio, Y., Courville, A., and Vincent, P.Visualizing higher-layer features of a deep network. In Technical report, University of Montreal, 2009.
[8] Fei-fei, L., Fergus, R., and Perona, P. One-shot learning of object categories. IEEE Trans. PAMI, 2006.
[9] Griffiffiffin, G., Holub, A., and Perona, P. The caltech 256. In Caltech Technical Report, 2006.
[10] Gunji, N., Higuchi, T., Yasumoto, K., Muraoka, H., Ushiku, Y., Harada, T., and Kuniyoshi, Y. Classifification entry. In Imagenet Competition, 2012.
[11] Hinton, G. E., Osindero, S., and The, Y. A fast learning algorithm for deep belief nets. *Neural Computation, 18:1527–1554, 2006.
[12] Hinton, G.E., Srivastave, N., Krizhevsky, A.,Sutskever, I., and Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv:1207.0580, 2012.
[13] Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y. What is the best multi-stage architecture for object recognition? In ICCV, 2009.
[14] Jianchao, Y., Kai, Y., Yihong, G., and Thomas, H.Linear spatial pyramid matching using sparse coding for image classifification. In CVPR, 2009.
[15] Krizhevsky, A., Sutskever, I., and Hinton, G.E. Imagenet classifification with deep convolutional neural networks. In NIPS, 2012.
[16] Le, Q. V., Ngiam, J., Chen, Z., Chia, D., Koh, P., andNg, A. Y. Tiled convolutional neural networks. In NIPS, 2010.
[17] LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D.
Backpropagation applied to handwritten zip code recognition. Neural Comput., 1(4):541–551, 1989.
[18] Sande, K., Uijlings, J., Snoek, C., and Smeulders, A. Hybrid coding for selective search. In PASCAL VOC Classifification Challenge 2012, 2012.
[19] Sohn, K., Jung, D., Lee, H., and Hero III, A. Effiffifficient learning of sparse, distributed, convolutional feature representations for object recognition. In ICCV, 2011
[20] Torralba, A. and Efros, A. A. Unbiased look at dataset bias. In CVPR, 2011.
[21] Vincent, P., Larochelle, H., Bengio, Y., and Manzagol, P. A. Extracting and composing robust features with denoising autoencoders. In ICML, pp. 1096–1103, 2008.
[22] Yan, S., Dong, J., Chen, Q., Song, Z., Pan, Y., Xia, W., Huang, Z., Hua, Y., and Shen, S. Generalized hierarchical matching for sub-category aware object classifification. In PASCAL VOC Classifification Challenge 2012, 2012.
[23] Zeiler, M., Taylor, G., and Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In ICCV, 2011.
实践
基于pytorch1.14 , vgg16预训练模型进行可视化,cpu版本,参考上述的git项目
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import models
from torchvision import transforms, utils
import numpy as np
import scipy.misc
import matplotlib.pyplot as plt
from PIL import Image
import json
# 转灰度图
def to_grayscale(image):
"""
input is (d,w,h)
converts 3D image tensor to grayscale images corresponding to each channel
"""
image = torch.sum(image, dim=0)
image = torch.div(image, image.shape[0])
return image
def normalize(image):
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
image = Variable(preprocess(image).unsqueeze(0))
return image
def predict(image):
_, index = vgg(image).data[0].max(0)
return str(index.item()), labels[str(index.item())][1]
def deprocess(image):
return image * torch.Tensor([0.229, 0.224, 0.225]).cpu() + torch.Tensor([0.485, 0.456, 0.406]).cpu()
def load_image(path):
image = Image.open(path)
plt.imshow(image)
plt.title("Image loaded successfully")
return image
kitten_1 = load_image("./images/kitten_1.jpg")
vgg = models.vgg16(pretrained=True).cpu()
print(vgg)
labels = json.load(open('labels/imagenet_class_index.json'))
kitten_2 = normalize(kitten_1)
print(predict(kitten_2))
modulelist = list(vgg.features.modules())
print(modulelist)
# Output of various layers
def layer_outputs(image):
outputs = []
names = []
for layer in modulelist[1:]:
image = layer(image)
outputs.append(image)
names.append(str(layer))
output_im = []
for i in outputs:
i = i.squeeze(0)
temp = to_grayscale(i)
output_im.append(temp.data.cpu().numpy())
fig = plt.figure()
plt.rcParams["figure.figsize"] = (300, 500)
for i in range(len(output_im)):
a = fig.add_subplot(8,4,i+1)
imgplot = plt.imshow(output_im[i])
plt.axis('off')
a.set_title(names[i].partition('(')[0], fontsize=30)
plt.savefig('layer_outputs.jpg', bbox_inches='tight')
layer_outputs(kitten_2)
# Output of each filter separately at given layer
def filter_outputs(image, layer_to_visualize):
if layer_to_visualize < 0:
layer_to_visualize += 31 # reverse
output = None
name = None
for count, layer in enumerate(modulelist[1:]):
image = layer(image)
if count == layer_to_visualize:
output = image
name = str(layer)
filters = []
output = output.data.squeeze()
for i in range(output.shape[0]):
filters.append(output[i,:,:])
fig = plt.figure()
plt.rcParams["figure.figsize"] = (30, 30)
for i in range(int(np.sqrt(len(filters))) * int(np.sqrt(len(filters)))):
fig.add_subplot(int(np.sqrt(len(filters))), int(np.sqrt(len(filters))), i+1)
imgplot = plt.imshow(filters[i])
plt.axis('off')
print(len(filters))
print(filters[0].shape)
print(output.shape)
filter_outputs(kitten_2, 0)
filter_outputs(kitten_2, -1)
# Visualize weights
def visualize_weights(image, layer):
weight_used = []
for w in vgg.features.children():
if isinstance(w, torch.nn.modules.conv.Conv2d):
weight_used.append(w.weight.data)
filters = []
for i in range(weight_used[layer].shape[0]):
filters.append(weight_used[layer][i,:,:,:].sum(dim=0))
filters[i].div(weight_used[layer].shape[1])
fig = plt.figure()
plt.rcParams["figure.figsize"] = (30, 30)
for i in range(int(np.sqrt(weight_used[layer].shape[0])) * int(np.sqrt(weight_used[layer].shape[0]))):
a = fig.add_subplot(int(np.sqrt(weight_used[layer].shape[0])), int(np.sqrt(weight_used[layer].shape[0])), i+1)
imgplot = plt.imshow(filters[i])
plt.axis('off')
# First conv layer filters
visualize_weights(kitten_2, 0)
# Last conv layer filters
visualize_weights(kitten_2, -1)
# CNN Heatmaps : Occlusion
def make_heatmap(image, true_class, k=8, stride=8):
"""
Input image is of size (1, c, w, h) typically (1, 3, 224, 224) for vgg16
true_class is a number corresponding to imagenet classes
k in the filter size (c, k, k)
"""
heatmap = torch.zeros(int(((image.shape[2]-k)/stride)+1), int(((image.shape[3]-k)/stride)+1))
image = image.data
i = 0
a = 0
while i<=image.shape[3]-k:
j = 0
b = 0
while j<=image.shape[2]-k:
h_filter = torch.ones(image.shape)
h_filter[:,:,j:j+k, i:i+k] = 0 # 8x8 occlusion
temp_image = Variable((image.cpu() * h_filter.cpu()).cpu())
temp_softmax = vgg(temp_image)
temp_softmax = torch.nn.functional.softmax(temp_softmax).data[0]
heatmap[a][b] = temp_softmax[true_class]
j += stride
b += 1
print(a)
i += stride
a += 1
image = image.squeeze()
true_image = image.transpose(0,1)
true_image = true_image.transpose(1,2)
# Un-Normalize image
true_image = true_image * torch.Tensor([0.229, 0.224, 0.225]).cpu() + torch.Tensor([0.485, 0.456, 0.406]).cpu()
# Plot both images
fig = plt.figure()
plt.rcParams["figure.figsize"] = (20, 20)
a = fig.add_subplot(1,2,1)
imgplot = plt.imshow(true_image)
plt.title('Original Image')
plt.axis('off')
# Normalize heatmap
heatmap = heatmap - heatmap.min()
# heatmap = heatmap/heatmap.max()
heatmap = np.uint8(255 * heatmap)
a = fig.add_subplot(1,2,2)
imgplot = plt.imshow(heatmap)
plt.title('Heatmap')
plt.axis('off')
return heatmap
my_img = load_image("images/goldfish.jpg")
my_img = normalize(my_img)
predict(my_img)
goldfish_heatmap = make_heatmap(my_img, 1, 16, 20) # Extremely slow
# Class Specific Saliency Maps
normalise = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalise
])
def make_saliency_map(input, label):
input = Variable(preprocess(input).unsqueeze(0).cpu(), requires_grad=True)
output = vgg.forward(input)
output[0][label].backward()
grads = input.grad.data.clamp(min=0)
grads.squeeze_()
grads.transpose_(0,1)
grads.transpose_(1,2)
grads = np.amax(grads.cpu().numpy(), axis=2)
true_image = input.data
true_image = true_image.squeeze()
true_image = true_image.transpose(0,1)
true_image = true_image.transpose(1,2)
true_image = deprocess(true_image)
fig = plt.figure()
plt.rcParams["figure.figsize"] = (20, 20)
a = fig.add_subplot(1,2,1)
imgplot = plt.imshow(true_image)
plt.title('Original Image')
plt.axis('off')
a = fig.add_subplot(1,2,2)
imgplot = plt.imshow(grads)
plt.axis('off')
plt.title('Saliency Map')
return grads
dog = load_image('images/retr.jpeg')
dog_sal = make_saliency_map(dog, 207)
flamingo = load_image('images/flamingo.jpg')
flamingo_sal = make_saliency_map(flamingo, 130)
goldfish = load_image('images/goldfish.jpg')
goldfish_sal = make_saliency_map(goldfish, 1)
# SmoothGrad
def smooth_grad(input, label, x=10, percent_noise=10):
"""
The apparent noise one sees in a sensitivity map may be due to
essentially meaningless local variations in partial derivatives.
After all, given typical training techniques there is no reason to expect derivatives to vary smoothly.
"""
tensor_input = torch.from_numpy(np.array(input)).type(torch.FloatTensor) # input is now of shape (w,h,c)
# x is the sample size
final_grad = torch.zeros((1,3,224,224)).cpu()
for i in range(x):
print('Sample:', i+1)
temp_input = tensor_input
# According to the paper, noise level corrresponds to stddev/(xmax-xmin). Hence stddev = noise_percentage * (max-min) /100
noise = torch.from_numpy(np.random.normal(loc=0, scale=(percent_noise/100) * (tensor_input.max() - tensor_input.min()), size=temp_input.shape)).type(torch.FloatTensor)
temp_input = (temp_input + noise).cpu().numpy()
temp_input = Image.fromarray(temp_input.astype(np.uint8))
temp_input = Variable(preprocess(temp_input).unsqueeze(0).cpu(), requires_grad=True)
output = vgg.forward(temp_input)
output[0][label].backward()
final_grad += temp_input.grad.data
grads = final_grad/x
grads = grads.clamp(min=0)
grads.squeeze_()
grads.transpose_(0,1)
grads.transpose_(1,2)
grads = np.amax(grads.cpu().numpy(), axis=2)
true_image = normalize(input)
true_image = true_image.squeeze()
true_image = true_image.transpose(0,1)
true_image = true_image.transpose(1,2)
true_image = deprocess(true_image.data)
fig = plt.figure()
plt.rcParams["figure.figsize"] = (20, 20)
a = fig.add_subplot(1,2,1)
imgplot = plt.imshow(true_image)
plt.title('Original Image')
plt.axis('off')
a = fig.add_subplot(1,2,2)
imgplot = plt.imshow(grads)
plt.axis('off')
plt.title('SmoothGrad, Noise: ' + str(percent_noise) + '%, ' + 'Samples: ' + str(x))
return grads
dog_sg = load_image('images/retr.jpeg')
dog_sal = make_saliency_map(dog_sg, 1)
dog_sg_sal = smooth_grad(dog, 207, 30, 10)
flamingo_sg = load_image('images/flamingo.jpg')
flamingo_sal = make_saliency_map(flamingo_sg, 130)
flamingo_sg_sal = smooth_grad(flamingo_sg, 130, 20, 20)
goldfish_sg = load_image('images/goldfish.jpg')
godlfish_sal = make_saliency_map(goldfish_sg, 1)
goldfish_sg_sal = smooth_grad(goldfish, 1, 30, 10)
# Class Models
def make_class_map(label, iterations=100, lr=250, reg=1):
cmap = np.zeros((224,224,3))
mean = np.array([0.485, 0.456, 0.406])
cmap += mean
# plt.imshow(map)
cmap = cmap.transpose(2,1,0)
cmap = Variable(torch.Tensor(cmap).unsqueeze(0).cpu(), requires_grad=True)
# cmap.data.shape
for i in range(iterations):
vgg.zero_grad()
output = vgg(cmap)
# print(i+1)
class_score = output[0][label]
reg_out = class_score + reg * cmap.norm()
reg_out.backward()
cmap.data = cmap.data + lr * cmap.grad.data
cmap = cmap.data.squeeze()
cmap.transpose_(0,1)
cmap.transpose_(1,2)
cmap = np.clip(np.array(deprocess(cmap).cpu()),0,255).astype('uint8')
plt.figure(figsize=(5,5))
plt.imshow(cmap)
plt.axis('off')
plt.title(labels[str(label)][1])
return cmap
flamingo_cmap = make_class_map(130, 1000, 300, 0.5)
参考
- https://www.cnblogs.com/wj-1314/p/13272191.html
- https://github.com/sar-gupta/convisualize_nb