计算机视觉方向简介 | 半全局匹配SGM
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前言
目标读者:对密集匹配,三维重建等有基本概念并感兴趣的人群。
文章及代码资源:
网盘中包含有论文以及代码,论文包括经典文章《Stereo Processing by Semi-Global Matching and Mutual Information》,以及两篇个人认为比较有意思的相关论文,一篇提出了物方的SGM,另一篇则将SGM与深度学习相结合,代码是笔者从网上找的开源代码,供读者参考。
链接:
https://pan.baidu.com/s/1CmWd4EQE9VtXbLRnVSvb3w
提取码:ypda
导读:
相信了解过密集匹配/立体匹配的读者对“SGM”不会感到陌生,SGM全名为semi-global matching,即半全局匹配,顾名思义,即为一种介于局部匹配与全局匹配之间的匹配算法,其较好的中和了局部匹配和全局匹配的优缺点,在精度和效率上有较好的平衡,现在已经较为广泛的应用于许多商业软件中,尤其在航空遥感影像上有许多应用。
SGM源于经典文章《Stereo Processing by Semi-Global Matching and Mutual Information》,谷歌学术上显示被引率已高达2536次,若读者希望对该算法有较为深刻的理解,该文章几乎是不可不读。opencv也有基于该算法的开源实现,名为sgbm。
就Heiko Hirschmuller的经典文章而言,其核心为分层互信息的代价计算,多方向一维近似二维的代价聚集,以及其他的一些精化的后处理部分,比如左右一致性处理,亚像素求精等等。但实际上在代价计算步骤中,分层互信息的应用并没有想象中的那么广泛,比如opencv开源的sgbm所用的代价函数就不是分层互信息,而是效率更高的BT,个人认为,或许根据影像情况自行选择测度会是一个更好的选择,比如就遥感影像而言,将相关系数作为测度的选择就非常多。
同时,SGM依赖惩罚参数来适应视差连续与断裂等情况,故而惩罚参数的设置较为重要,并且需要预先给定视差范围,在opencv中的sgbm实现中还需要给定许多其他优化参数,如果希望获取较好的匹配效果,合理设置参数非常重要。
以下将基于个人理解,分别从SGM的核心公式,代价计算步骤,代价聚集,视差计算及精化进行介绍,文章重点将落在代价聚集部分。由于笔者学识所限,如有错漏或者理解错误的地方,敬请批评。
1. 核心公式
SGM虽然名字上称为半全局匹配,但实际上还是采用的全局匹配算法中最优化能量函数的思想,即寻找每个像素的最优视差来使得整张影像的全局能量函数最小,下式为SGM所采用的能量函数:

上式中能量函数的最优化是一个NP问题,故而SGM提出了一个思路,即将像素所有视差下的匹配代价进行像素周围所有路径(比如8或者16)上的一维代价聚合,然后再将所有的一维代价聚合值相加,以近似二维的最优,这不仅可以取得和全局算法相媲美的结果,还大大的增加了效率。
下式为某像素p沿着某一条路径r的路径代价计算公式:

第一项还是数据项,第二项是平滑项,取r方向上视差不变,变化为1,变化大于1三种情况下代价最小的值,第三项则保证
Lr不超过数值上限,具体理解可见下文中的代价聚合步骤。
在代码中,可以用一个结构体来表示路径,通过变化rowDiff,colDiff来表明路径的方向。
struct path {
short rowDiff;
short colDiff;
short index;
};
实际上读者可以将所谓的路径理解为像素P(x,y)领域中的某一个特定位置的像素点。比如下图中的path1可设为(rowDiff = 0,colDiff = -1,index = 1),path2可设为(rowDiff = -1,colDiff = 0, index = 2)等。
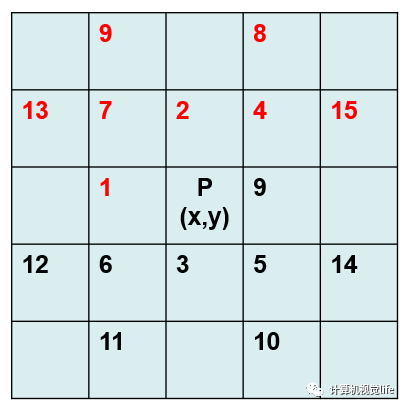
本文提供的开源代码分两次进行代价聚合的扫描,第一次为上图中红色的路径,第二次为图中黑色的路径。
2. 代价计算
在视差计算之前,首先需要定义大小为W×H×D(W为影像宽度,H为影像高度,D则为事先给定的视差范围)的三维矩阵C来存储每个像素在视差范围内每个视差下的匹配代价值。矩阵C通常称为DSI(Disparity Space Image),这个长方块也是我们常说的视差空间。下图为DSI的示意图:

C(x, y, d)代表像素(x,y)在视差为d时的匹配代价,匹配代价越小说明相似度越高。代价函数或者说测度的选择有很多,比如说Heiko Hirschmuller文章中的互信息,分层互信息,还有opencv中sgbm所选择的BT,以及相关系数等。匹配测度各自有各自的优势,建议根据具体数据的特性来选择合适的匹配测度。
3. 代价聚合
感性上来讲,SGM能够扬名的一个很重要的点就是它将一个NP的全局优化问题简化成了一个多方向的代价问题,即用多个一维路径代价聚合的方式来近似二维的最优。虽然还是在全局的框架下,但是整体的计算效率已相较于全局算法有了很大提升。
上一步代价计算步骤中所计算出来的代价仅仅是能量函数中的数据项,在经过聚合步骤后的代价才会被用来计算最优视差。所谓的代价聚合实质上是对上一步的代价矩阵进行全局优化,得到一个存有聚集后代价的新的矩阵,用三维矩阵S来表示。
就路径聚合,以下将简要介绍三个示意图。
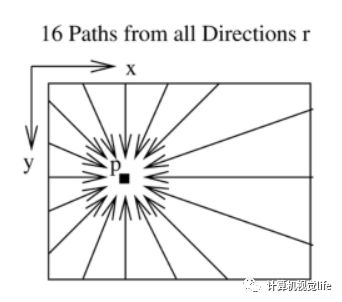
第一个示意图,也即原论文中路径聚合的示意图如下图所示,做出了一个感性的十六方向代价聚合示意。
第二个示意图为许多介绍SGM博客中所用到的示意图,如下图所示,红色箭头方向代表四路径聚集,红色和黑色箭头方向共同代表八路径聚集,白色聚合方向则代表十六方向路径聚集,路径数越多时间开销则会愈多,但相对而言效果也会更好,路径数自行权衡即可。

第三个示意图为解释本文提供的开源代码所画的示意图,如下图所示,红色数字为第一次扫描的路径index,黑色数字为第二次扫描的路径index。

以第一次扫描为例,代码如下:
for (int row = 0; row < rows; ++row)
{
for (int col = 0; col < cols; ++col)
{
for (unsigned int path = 0; path < firstScanPaths.size(); ++path)
{
for (int d = 0; d < disparityRange; ++d)
{
S[row][col][d] += aggregateCost(row, col, d, firstScanPaths[path], rows, cols, disparityRange, C, A[path]);
}
}
}
lastProgressPrinted = printProgress(row, rows - 1, lastProgressPrinted);
}
即对于每一个像素点,对其第一次扫描序列中的每一条路径,对其视差范围内的每一个视差,求取单路径聚集后的代价,再进行累加,存到S[rol][col][d]中,最后用于WTA视差计算。
此处关键的函数为aggregateCost(row, col, d, firstScanPaths[path], rows, cols, disparityRange, C, A[path])。输入的参数中(row,col,d)相当于确定了视差空间中三维点的位置,firstScanPaths[path]则确定了是哪条路径,或者可以更直观的理解为是像素领域内哪个相邻像素,(rows,cols,disparityRange)则确定了视差空间的范围,C为上一步代价计算得到的三维代价矩阵,最后的A[path]也是一个三维矩阵,用来存储对应方向的聚集代价,返回值则是A[row][col][d]。以下为该函数的实现:
unsigned short aggregateCost(int row, int col, int d, path &p, int rows, int cols, int disparityRange, unsigned short ***C, unsigned short ***A)
{
unsigned short aggregatedCost = 0;
aggregatedCost += C[row][col][d]; //像素匹配的 cost 值
// 1. 边界条件,直接为C
if (row + p.rowDiff < 0 || row + p.rowDiff >= rows || col + p.colDiff < 0 || col + p.colDiff >= cols)
{
A[row][col][d] += aggregatedCost;
return A[row][col][d];
}
// 2. 若未超出边界 ,则进行相应方向的代价聚合
unsigned short minPrev, minPrevOther, prev, prevPlus, prevMinus;
prev = minPrev = minPrevOther = prevPlus = prevMinus = MAX_SHORT;
//设置初始代价为最大值
//minPrev: 对应路径的视差代价最小值
// 对于该路径方向上,上一个像素,在其视差范围内进行循环
for (int disp = 0; disp < disparityRange; ++disp)
{
unsigned short tmp = A[row + p.rowDiff][col + p.colDiff][disp];
//找到这个路径下,前一个像素取不同视差值时最小的A,即为最后减去的那一项,minPrev
if(minPrev > tmp){minPrev = tmp;}
//前一个像素视差取值为d时,即和当前像素的视差相等时,最小的A.
if(disp == d)
{ prev = tmp;}
//前一个像素视差取值为d+1时,即和当前像素的视差相差1时,最小的A,最后将加惩罚系数P1.
else if(disp == d + 1)
{ prevPlus = tmp;}
//前一个像素视差取值为d-1时,即和当前像素的视差相差1时,最小的A,最后将加惩罚系数P1.
else if (disp == d - 1)
{ prevMinus = tmp;}
//前一个像素视差与当前像素的视差相差大于等于2时,最小的A,最后将加惩罚系数P2.
else
{ minPrevOther = tmp;}
}
/* 计算四种情况下的代价最小值 */
aggregatedCost += std::min(std::min((int)prevPlus + SMALL_PENALTY, (int)prevMinus + SMALL_PENALTY), std::min((int)prev, (int)minPrevOther + LARGE_PENALTY));
aggregatedCost -= minPrev; //避免值过大,减小内存
A[row][col][d] += aggregatedCost;
return A[row][col][d];
}
第二次扫描及其他代码细节具体见网盘资源。
4. 视差计算及精化
视差计算步骤其实非常简单,通常直接利用赢家通吃(WTA)算法,即选择某一个像素在所有视差值中最小的那一个即可,这也间接说明上一步,也即代价聚集步骤后所得到的视差空间中的代价值需要非常准确,那将直接决定算法的准确度。视差优化则是对计算得到的视差图进行进一步的优化,包括剔除粗差,亚像素插值,平滑等等。比如经常使用的左右一致性检查,可用来剔除遮挡点所产生的错误匹配,对视差图的改进比较大,有时候甚至可以成为许多算法的“遮羞布”。亚像素插值是对WTA得到的整像素进行精化,通常使用二次曲线拟合来获得子像素的视差。平滑则是使用一些平滑算子对视差图进行平滑处理。
结语
本文简要介绍了SGM的思想,并辅以部分代码以助于理解。近年来深度学习大热,SGM与深度学习的结合逐渐成为趋势,网盘中所提供的文章与开源代码可供读者参考,若有错漏,欢迎批评与不吝赐教。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

