图神经网络用于推荐系统问题(NGCF,LightGCN,UltraGCN)
何向南老师组的又两大必读论文,分别发在SIGIR19’和SIGIR20’。同时补一篇CIKM21’的优化。
Neural Graph Collaborative Filtering
协同过滤(collaborative filtering)的基本假设是相似的用户会对物品展现出相似的偏好,自从全面进入深度学习领域之后,一般主要是先在隐空间中学习关于user和item的embedding,然后重建两者的交互即interaction modeling,如MF做内积,NCF模拟高阶交互等。但是他们并没有把user和item的交互信息本身编码进 embedding 中,这就是NGCF想解决的点:显式建模User-Item 之间的高阶连接性来提升 embedding。
High-order Connectivity
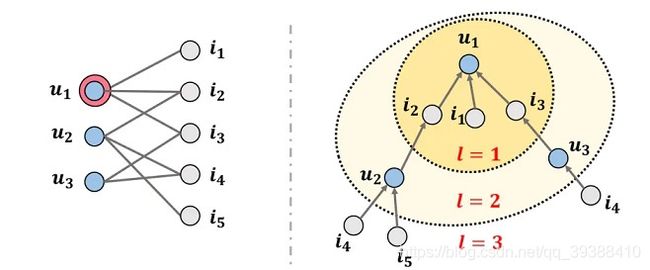
解释高阶连通性如上图,图1左边为一般CF中user-item交互的二部图,双圆圈表示此时需要预测的用户u1,对于u1我们可以把有关他的连接扩展成右图的树形结构,l是能到达的路径长度(或者可以叫跳数),l=1表明能一步到达u1的item,此时可以看到最外层的跳数相同的i4跟i5相比(l都为3),用户u1对i4的兴趣可能要比i5高,因为i4->u2->i2->u1、i4->u3->i3->u1有两条路径,而i5->u2->i2->u1只有一条,所以i4的相似性会更高。所以如果能扩展成这样的路径连通性来解释用户的兴趣,就是高阶连通性。
NGCF的完整模型如下图,可以分为三个部分来看:
- Embeddings:对user和item的嵌入向量,普通的用id来嵌入就可以了
- Embedding Propagation Layers:挖掘高阶连通性关系来捕捉交互以细化Embedding的多个嵌入传播层
- Prediction Layer:用更新之后带有交互信息的 user 和 item Embedding来进行预测
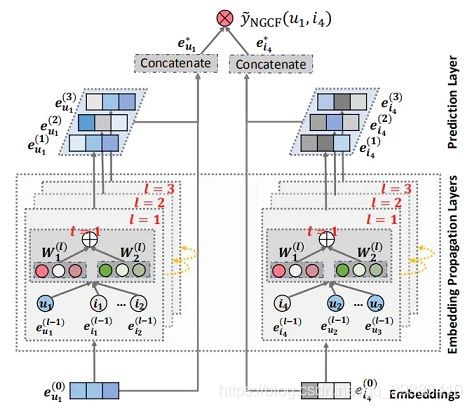
主要就是中间的交互信息捕捉怎么构建,主要思路是借助GNN的message passing消息传递机制: m u ← i = 1 ∣ N u ∣ ∣ N i ∣ ( W 1 e i + W 2 ( e i ⊙ e u ) ) m_{u\leftarrow i}=\frac{1}{\sqrt {|N_u||N_i|}}(W_1e_i+W_2(e_i\odot e_u)) mu←i=∣Nu∣∣Ni∣1(W1ei+W2(ei⊙eu))其中Mu←i是消息嵌入(即要传播的信息),使用embedding后的user,item的特征 e u , e i e_u,e_i eu,ei作为输入,然后两者计算内积相似度来控制邻域的信息,再加回到item上,用权重W控制权重,最后的N是u和i的度用来归一化系数,可以看做是折扣系数,随着传播路径长度的增大,信息慢慢衰减。
博主自己的理解是实际上做了一个小型的attention从领域的item整合信息,所以下一步就是用这些邻域信息更新user: e u ( 1 ) = L e a k y R e L U ( m u ← u + ∑ i ∈ N u m u ← i ) e^{(1)}_u=LeakyReLU(m_{u\leftarrow u}+\sum_{i\in N_u}m_{u\leftarrow i}) eu(1)=LeakyReLU(mu←u+i∈Nu∑mu←i)上标(1)表示一阶聚合,可以看到从领域的i中整合信息又考虑到了自身节点的信息,最后再激活一下。高阶传播实际就是将上述的一阶传播堆叠多层,这样经过 l 次聚合,每个节点都会融合其 l 阶邻居的信息,也就得到了节点的 l 阶表示,具体的传播如下图:
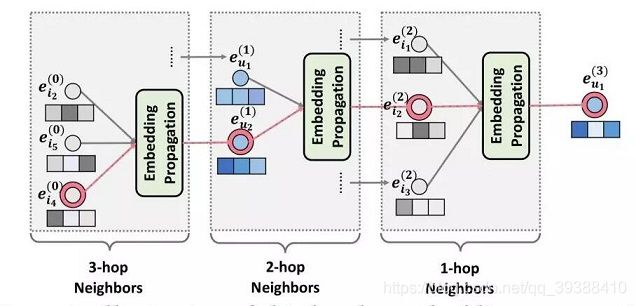 对应user u2来说,先由直接连接的i2,i4,i5开始是一阶,进行上述的聚合更新之后,聚合二阶邻居(此时u1也完成了更新),此时用u1和u2更新i2,同样的其他的item也会相应的更新,最后再由i1,i2,i3来更新u1,这样通过相互更新相互迭代,就完成了开篇那张图的树形结果。
对应user u2来说,先由直接连接的i2,i4,i5开始是一阶,进行上述的聚合更新之后,聚合二阶邻居(此时u1也完成了更新),此时用u1和u2更新i2,同样的其他的item也会相应的更新,最后再由i1,i2,i3来更新u1,这样通过相互更新相互迭代,就完成了开篇那张图的树形结果。
如果把上述的更新换成矩阵形式的话:
E ( l ) = σ ( ( L + I ) E ( l − 1 ) W 1 ( l ) + L E ( l − 1 ) ⊙ E ( l − 1 ) W 2 ( l ) ) E^{(l)}=\sigma((L+I)E^{(l-1)}W^{(l)}_1+LE^{(l-1)}\odot E^{(l-1)}W^{(l)}_2) E(l)=σ((L+I)E(l−1)W1(l)+LE(l−1)⊙E(l−1)W2(l))其中 L = D − 1 / 2 A D − 1 / 2 L=D^{-1/2}AD^{-1/2} L=D−1/2AD−1/2,这其实和GCN很像了。最后再将 L 阶的节点表示全部readout,分拼接起来作为最终的节点表示,再内积得到预测结果: y N G C F ′ ( u , i ) = e u ∗ T e i ∗ y'_{NGCF}(u,i)={e^*_u}^Te^*_i yNGCF′(u,i)=eu∗Tei∗损失函数就是常规的成对loss操作 L o s s = ∑ ( u , i , j ) ∈ O − l n σ ( y u i ′ − y u j ′ ) + λ ∣ ∣ Θ ∣ ∣ 2 Loss=\sum_{(u,i,j)\in O} -ln \sigma(y'_{ui}-y'_{uj})+\lambda||\Theta||^2 Loss=(u,i,j)∈O∑−lnσ(yui′−yuj′)+λ∣∣Θ∣∣2
最后再看看ngcf的关键代码:
def _create_ngcf_embed(self):
# Generate a set of adjacency sub-matrix.
# 使用矩阵的解法,所以先得到邻接矩阵
if self.node_dropout_flag:
# node dropout.
A_fold_hat = self._split_A_hat_node_dropout(self.norm_adj)
else:
A_fold_hat = self._split_A_hat(self.norm_adj)
#最初的嵌入形式
ego_embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = [ego_embeddings]
#执行k层的消息传播
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], ego_embeddings))
# u到u,聚合u所有邻居的消息
side_embeddings = tf.concat(temp_embed, 0)
# 特征变换矩阵
sum_embeddings = tf.nn.leaky_relu(
tf.matmul(side_embeddings, self.weights['W_gc_%d' % k]) + self.weights['b_gc_%d' % k])
# i到u,合并自嵌入,邻居的嵌入
bi_embeddings = tf.multiply(ego_embeddings, side_embeddings)
# 再次变换特征
bi_embeddings = tf.nn.leaky_relu(
tf.matmul(bi_embeddings, self.weights['W_bi_%d' % k]) + self.weights['b_bi_%d' % k])
#非线性激活函数,u到u和i到u的两部分
ego_embeddings = sum_embeddings + bi_embeddings
# message dropout.
ego_embeddings = tf.nn.dropout(ego_embeddings, 1 - self.mess_dropout[k])
#正则化
norm_embeddings = tf.math.l2_normalize(ego_embeddings, axis=1)
all_embeddings += [norm_embeddings]
all_embeddings = tf.concat(all_embeddings, 1)#拼一起
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
paper:https://arxiv.org/abs/1905.08108
code:https://github.com/xiangwang1223/neural_graph_collaborative_filtering
LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
前一篇的NGCF主要遵循标准GCN变形得到,包括使用非线性激活函数和特征变换矩阵w1和W2。然而作者认为实际上这两种操作对于CF并没什么大用,理由在于不管是user还是item,他们的输入都只是ID嵌入得到的,即根本没有具体的语义(一般在GCN的应用场景中每个节点会带有很多的其他属性),所以在这种情况下,执行多个非线性转换不会有助于学习更好的特性;更糟糕的是,它可能会增加训练的困难,降低推荐的结果。
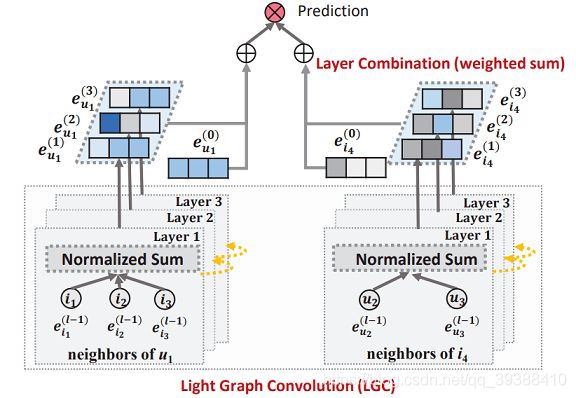
所以将非线性激活函数non-linear和特征变换矩阵feature transformation都去掉,只增加一组权重系数来邻域聚集weighted aggregate不同gcn层输出的嵌入为最终的嵌入,大大简化了模型。即在LightGCN中,只采用简单的加权和聚合器,放弃了特征变换和非线性激活的使用,所以公式变为(只剩下):
e u ( k + 1 ) = ∑ i ∈ N u 1 ∣ N u ∣ ∣ N i ∣ e i ( k ) e^{(k+1)}_u=\sum_{i\in N_u} \frac{1}{\sqrt{|N_u|}\sqrt{|N_i|}}e^{(k)}_i eu(k+1)=i∈Nu∑∣Nu∣∣Ni∣1ei(k) e i ( k + 1 ) = ∑ u ∈ N i 1 ∣ N i ∣ ∣ N u ∣ e u ( k ) e^{(k+1)}_i=\sum_{u\in N_i} \frac{1}{\sqrt{|N_i|}\sqrt{|N_u|}}e^{(k)}_u ei(k+1)=u∈Ni∑∣Ni∣∣Nu∣1eu(k)而且从上式可以看到它只聚合连接的邻居,连自连接都没有。最后的K层就直接组合在每个层上获得的嵌入,以形成用户(项)的最终表示: e u = ∑ k = 0 K α k e u ( k ) e_u=\sum^K_{k=0} \alpha_k e^{(k)}_u eu=k=0∑Kαkeu(k) e i = ∑ k = 0 K α k e i ( k ) e_i=\sum^K_{k=0} \alpha_k e^{(k)}_i ei=k=0∑Kαkei(k)其中αk设置为1/(K+1)时效果最好。其余的部分就和NGCF一模一样。
为什么要组合所有层?
- GCN随着层数的增加会过平滑,直接用最后一层不合理
- 不同层的嵌入捕获不同的语义,而且更高层能捕获更高阶的信息,结合起来更加全面
- 将不同层的嵌入与加权和结合起来,可以捕获具有自连接的图卷积的效果,这是GCNs中的一个重要技巧
同样看一下关键部分的代码,代码量真的要简洁许多:
def _create_lightgcn_embed(self):
if self.node_dropout_flag:
A_fold_hat = self._split_A_hat_node_dropout(self.norm_adj)
else:
A_fold_hat = self._split_A_hat(self.norm_adj)
ego_embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = [ego_embeddings]
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], ego_embeddings))
#归一化已经在A里面得到A_hat了,所以这里直接聚合就完了
side_embeddings = tf.concat(temp_embed, 0)
ego_embeddings = side_embeddings
all_embeddings += [ego_embeddings]
all_embeddings=tf.stack(all_embeddings,1)#然后拼一起
all_embeddings=tf.reduce_mean(all_embeddings,axis=1,keepdims=False)
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
paper:https://arxiv.org/abs/2002.02126
code:https://github.com/kuandeng/LightGCN
完整的关键代码中文注释可以参考:https://github.com/nakaizura/Source-Code-Notebook/
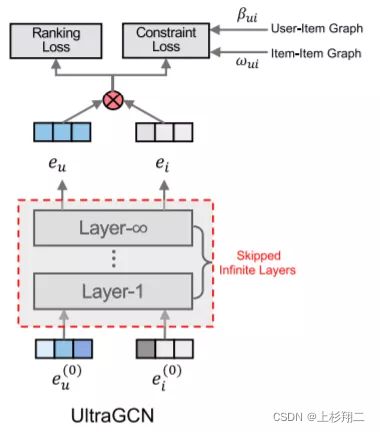
UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation
博主继续补文,来自CIKM21的UltraGCN。先上效果,就速度上,UltraGCN比LightGCN要快10倍。首先作者任务LightGCN的缺陷如下:
- 1。LightGCN对于给定的用户u,在更新node时item k和item i对应的权重不一样,即在聚合时的开方号不一致,这并不合理。
- 2。LightGCN多层堆叠进行消息传递,但未捕捉到重要性,可能会引入噪声。
- 3。实际上LightGCN只能堆叠2,3层就过平滑了,高阶信息很难捕捉。
因此,这种多层堆叠的显式消息传递是否必要?
作者提出的UltraGCN结构如上图,是一个多任务结构,重点就在于constrain loss的 β , w \beta, w β,w,其分别在User-Item Graph和Item-Item Graph上进行约束。
- User-Item Graph。针对问题1和3,提出了一种近似的高阶推导,以模拟在经过无限次传播后的收敛状态。
e u = ∑ β u , i e i , β u , i = 1 d u d u + 1 d i + 1 e_u=\sum \beta_{u,i}e_{i}, \ \beta_{u,i}=\frac{1}{d_u} \sqrt{\frac{d_u+1}{d_i+1}} eu=∑βu,iei, βu,i=du1di+1du+1详细过程可看原文的论证,通过无限次阶后使layer层数消失,从而通过除权重即 β \beta β来解决问题1,同时这种无限阶也能解决问题3。 - Item-Item Graph。针对问题2的边权重分配,即显示传播无法捕捉到不同类型关系的相对重要性。作者根据item的共现性构建item-item图G。 w i , j = G i , j g i − G i , i g i g j , g i = ∑ k G i , k w_{i,j}=\frac{G_{i,j}}{g_i-G_{i,i}}\sqrt{\frac{g_i}{g_j}}, \ g_i=\sum_k G_{i,k} wi,j=gi−Gi,iGi,jgjgi, gi=k∑Gi,k然后使用这个权重进行加权。
下一篇博文继续整理:
- 图神经网络用于推荐系统问题(IMP-GCN,LR-GCN)