Motion Guided Attention for Video Salient Object Detection论文详读
abstract
视频显著目标检测的主要目的是检测出视频中视觉上最突出、最独特的目标,现有的方法没有获取和使用视频中的运动线索,或忽略了光流图像中的空间上下文。
本文的方法使用两个子网络分别实现两个子任务,一个子网络(appearance branches)在静态图像中对显著目标(salient object)进行检测,另一个子网络(motion branches)对光流图像中的运动的显著目标(salient object)进行检测。通过多个运动引导注意力模块(motion guided attention module),结合两个端到端训练的子网络,可以当前最好的检测效果。
introduce
视频显著目标(salient object)检测大致可以分为两类,一类主要用来预测视频中观察者的视角,可以从生物学角度了解人类视觉和认知系统的内部机制;第二类主要用来从混乱的背景中分割出重要的或显著的对象。
本文方法针对第二类问题进行解决,因为SOD(salient object detection)可以作为很多计算机视觉技术的前置步骤,如视觉跟踪、图像和视频压缩、人员识别等。
在视频显著目标(salient object)检测过程中如何把目标的运动考虑进去是非常重要的——第一,目标的显著性(saliency)不仅受其外观的影响,也受其连续帧运动的影响;第二,目标的运动提供了空间一致性的重要线索,具有相似位移的相邻图像很可能属于同一前景对象或背景区域;第三,利用运动线索可以使得视频图像目标分割变得简单,从而可以产生更高质量的saliency map。
当前的SOD算法还没有有效利用目标的运动信息。《Video saliency detection via spatialtemporal fusion and low-rank coherency diffusion》、《Consistent video saliency using local gradient flow optimization and global refinement》、《Saliency detection for unconstrained videos using superpixel-level graph and spatiotemporal propagation》尝试基于时空一致性合并外观和运动信息,但是因为手动标记的低维特征和缺乏训练数据挖掘而受到限制。因此这几个方法无法自适应的获取复杂场景中的运动模式和对象语义的准确特征。这些方法很难捕捉对象运动和高级语义的对比和唯一性。
基于FCN(全连接网络)的方法通过把当前帧和之前的帧或之前预测的saliency map简单的进行连接,形成CNN的输入,从而对时间一致性进行建模。这些基于CNN的方法没有利用显式的运动估计,如光流信息,并且受视频外观和混乱的背景的影响。
当前处理视频中显著目标效果最好的方法是基于RNN的方法,它们利用卷积记忆单元如ConvLSTM来聚合大范围的时空特征,部分算法利用flow warp使之前的特征与当前特征进行对齐,但是忽略了光流图像中的空间一致性和运行对比度。
本文提出一个多任务、运动引导的视频显著目标检测网络,其中包含两个部分,一部分是静态图像显著目标检测,另一部分是从光流图像中推断运动显著性。为了实现视频显著目标检测,需要把两个部分进行结合,为了实现完整的注意力机制,使用一系列运动引导注意力模块,集中了残差学习以及空间和通道注意力的优势。
本算法因为ConvLSTM的原因不在需要当前帧之前的大范围特征,仅需要之前帧小范围的上下文信息用于计算。
本文的contributions:
- 提出一个新颖的运动引导注意力模块,可以通过运动特征或运动显著性来增强特征;
- 提出一个新颖的视频显著目标检测网络,其中包含一个外观分支——静态图像显著目标检测模块,一个运动分支——光流图像运动显著性检测模块,和连接两部分的注意力模块;
- 大量的实验论证表明,本文的算法在广泛的数据集和指标上大大优于现有的最新算法。
模型
运动引导注意力机制 motion guided attention

为了利用运动信息,定义一个外观特征作为一个特征张量,该特征由一些隐藏层产生,如外观分支中的ReLU函数等。
运动信息可以分为两类,一类被定义为motion saliency map,由运动分支中最后一个层产生,这些motion saliency map可以被Sigmoid函数预测,它们的值被限定在[0,1];第二类是运动特征,由一些运动分支中的ReLU函数产生。
把motion saliency map定义为 P m P_m Pm,外观特征appearance feature定义为 f a f_a fa,前向计算得到的attended 外观特征:
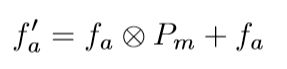
其中 f a ′ f^{'}_a fa′和 f a f_a fa的大小为 C × H × W C ×H ×W C×H×W, P m P_m Pm的大小为 H × W H × W H×W, ⨂ \bigotimes ⨂表示元素之间的乘法, P m P_m Pm与 f a f_a fa中每个通道进行元素相乘。这种乘法计算简单,但是具有局限性,因为运动分支通过motion saliency map训练检测任务的,而与背景具有相同位移的图像部分在 P m P_m Pm中最有可能被预测为0。
MGA-m

上图可以看出,只有一部分显著目标在连续帧内移动,所以静止的部分在 P m P_m Pm中为0,所以得到的外观特征 f a ′ f^{'}_a fa′是被压缩的,因此不能保证显著目标的完整性。为了解决这个问题,提出一个获取 f a ′ f^{'}_a fa′的变形算法 f a ′ = f a ⨂ P m + f a f^{'}_a = f_a \bigotimes P_m + f_a fa′=fa⨂Pm+fa,只使得显著运动区域变得明显(其中的" + + +"表示元素间的相加), f a ⨂ P m f_a \bigotimes P_m fa⨂Pm被视为一个残差项,使用 + f a + f_a +fa的方式来完善 f a ⨂ P m f_a \bigotimes P_m fa⨂Pm导致的不正确的压缩。因此 f a ⨂ P m f_a \bigotimes P_m fa⨂Pm部分可以参与显著部分的计算,而静态但显著的区域不会被忽略。
把上述的模块称为MGA-m(motion guided attention,m表示该attention模块的输入是一个map)。
MGA-t
下面讨论如何利用运动张量 f m f_m fm——与MGA-m一致,提出一个新的运动注意力模块,

其中 f a f_a fa和 f m f_m fm的大小分别为 C × H × W C ×H ×W C×H×W和 C ′ × H × W C^{'} ×H ×W C′×H×W。 g ( ⋅ ) g(·) g(⋅)是一个1×1的卷积,作用是使运动特征和外观特征对齐。该模块被称为MGA-t,t表示来自运动分支的输入是一个特征张量feature tensor。
MGA-tm
受MGA-m模块的启发,该模块利用运动信息作为空间注意权重,我们设想了一种通过将运动特征预先转换为空间权重来与另一个张量同时出现的张量的变体。

其中h(·)是一个1×1的卷积且输出为单通道。Sigmoid(·)的输出是一个大小为 H × W H × W H×W的attention map。该模块被称为MGA-tm,tm表示输入的特征张量feature tensor在最开始就被转换为一个spatial map。
MGA-tm模块可以看作是在运动特征上应用空间注意力机制,而MGA-t模块空间和通道层面的注意力是依靠一个3维的注意力权重张量同时实现的。
MGA-tmc
在本文的算法中,运动分支只需要一个光流图像作为输入,用于向外观分支传递信息,且不了解外观信息。所以仅仅依靠运动特征来实现每个通道的注意力机制不现实,但是对于MGA-tm模块,它缺少对与视觉显著性对象或显著运动对象高度相关的通道的重要性进行强调的功能。
基于上述的原因,提出了新的MGA模块:

其中张量 f a f_a fa、 f a ′ f^{'}_a fa′和 f a ′ ′ f^{''}_a fa′′的大小为 C × H × W C ×H ×W C×H×W, f m f_m fm的大小为 C ′ × H × W C^{'} × H × W C′×H×W。 h ( ⋅ ) h(·) h(⋅)和 h ′ ( ⋅ ) h^{'}(·) h′(⋅)都是1×1的卷积,输出分别为单通道和C通道。 G A P ( ⋅ ) GAP(·) GAP(⋅)表示空间层面的全局平均池化操作。C的大小等于Softmax函数输出元素的数量。该模块被称为MGA-tmc,其中c表示是通道层面的注意力。
关于MGA-tmc的其他细节: f a ′ f^{'}_a fa′是一个外观特征,且早己被一个运动特征在空间上突出显示。 G A P ( f a ′ ) GAP(f^{'}_a) GAP(fa′)输入 f a ′ f^{'}_a fa′输出一个包含C个元素的向量, h ( ⋅ ) h(·) h(⋅)对每个通道分别预测出一个权重为C的向量。这些通道层面的注意力权重的主要作用是选择或增强一些基本属性,如边缘、边界、颜色、纹理、语义等。
S o f t m a x ( ⋅ ) ⋅ C Softmax(·) · C Softmax(⋅)⋅C正则 h ( ⋅ ) h(·) h(⋅)的输出,使其平均值等于1,为了简化,把这个过程记为"softmax",如上图(d)部分的"softmax"模块。
f a ′ ⨂ [ ⋅ ] f^{'}_a \bigotimes [·] fa′⨂[⋅]的作用是把 f a ′ f^{'}_a fa′中的每个空间位置处的特征列与正则化的注意力向量相乘。
总结来说,MGA-tmc模块首先通过显著运动突出空间位置,然后选择潜在的属性以根据运行展现的外观特征对显著性进行建模,最后添加输入向量作为补充。
网络结构 network architecture

上图可以看出,本文算法的结构包含一个外观分支appearance branches(蓝色)、一个运动分支motions branches(绿色)、一个预训练的流估计网络Flow-estimation network(灰色,基于Flownet 2.0: Evolution of optical flow estimation with deep networks实现的FlowNet 2.0网络)以及一系列运动引导注意力模块motion guided attention module(橙色)来连接外观分支和运动分支。
外观分支与运动分支相似又有所不同,因为光流图像不需要像RGB图像那样保持大量高维语义信息和细微的边缘细节。
外观分支和运动分支都包含三个部分——编码器encoder、多孔空间金字塔池化模块ASSP(atrous spatial pyramid pooling)、解码器decoder。
- 编码器的作用是从低维特征向高维提取可视化特征并减少特征图的分辨率,其中包含五层:一个卷积层(outputchannels=64,kernel=3,stride=2,然后紧跟着normalization函数和ReLu函数)和四个残差层(四层的stride分别为2,2,2,1;对于外观分支,四层的残差学习模块分别为3,4,23,3,outputchannels分别是256,512,1024,2048;对于运动分支四层的残差学习模块分别为3,4,6,3,outputchannels分别是64,128,256,512),所以编码器可以减少特征图的空间尺寸为原始输入的1/8;
- ASSP模块通过膨胀卷积在特征图中获取到大范围的依赖关系,并将其与局部、全局的representation进行集成,这样可以隐式的获取到大范围的比较,从而进行显著性建模。从上图的绿色部分可以看到ASSP的内部构造——一个1×1的卷积层,三个膨胀率分别为12,24,36的卷积层和一个全局平均池化层GAP。这5层的输出根据其深度维度进行链接,形成一个特征图;
- 解码器通过融合低维特征和高维特征,恢复特征图的空间大小,从而预测具有高分辨率的saliency map。从上图中可以看到,通过一个1×1的卷积层conv-1使得ASSP的输出缩小为256通道的特征,编码器encoder中的residual-1的低维输出通过一个1×1的卷积层conv-2缩小为48通道的特征。把上述的两个特征进行连接后,使用两个3×3的卷积层conv-3、conv-4进行处理,得到一个256通道的输出。最后通过一个1×1的卷积层conv-5和Sigmoid函数,预测得到最终的单通道saliency map。
- 关于运动引导注意力模块motion guided attention module,共有6个分别为MGA-i(i∈{0,1,2,3,4,5} ),其中MGA-0将两个子模块的head-conv的输出作为输入,并将输出传入外观分支的residual-1作为输入;其余的MGA-i 都是将对于的两个子模块中的residual-i 的输出作为,将其输出传入外观分支的residual-(i+1)作为输入。上图中可以看到,外观分支的编码器中的没有内部的链接,而都是把MGA的输出作为输入。MGA-5使用运动分支的最终输出和外观分支的解码器融合的特征作为输入,其输出作为外观分支解码器的conv-3的输入,因为MGA-5的输入是一个单通道的saliency map,所以它只能够被MGA-m实例化。而其他几个MGA-i可以选择MGA-t、MGA-tm或MGA-tmc进行实现。
多任务训练体系muti-task training scheme
多任务训练体系:
- 首先使用在ImageNet上预训练的ResNet-101初始化外观子网络appearance sub-network,然后使用静态图像显著目标检测数据集对外观分支进行fine-tune;
- 实现光流估计模块(前文中提到了,使用现成的FlowNet 2.0),然后使用其提供光流图像,这些光流图像计算后作为先前的帧传递到当前帧的forward flow;
- 首先使用在ImageNet上预训练的ResNet-34初始化运动子网络motion sub-network,然后在视频显著目标检测数据集上对这些合成的光流图像及其对应的saliency map进行训练;
- 最后使用MGA将两个分支链接起来,构成一个整体。
因为训练样本是静态图像或视频的第一帧,不具有一致的运动图像,所以假定在此之前的图像与当前图像相同,也就意味着这种样本中的对象不运动或不具有显著运动,因此遇到这种情况,只需要再MGA模块的运动输入中填充 0 即可。