初学深度学习笔记(小土堆和霹雳吧啦)
model 文件(网络)
本人初学,用的是AlexNet。数据集是在kaggle上面下载的猫狗图片数据集,想要做一个猫狗识别的神经网络。
打开数据集可以发现猫狗图片的大小都在300*300以上但为了简便我们就直接利用霹雳吧啦写的网络,其代码如下
def __init__(self, num_classes=2, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 27 # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # 27 # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 13 # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # 13 # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # 13 # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # 13 # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
num_classes是分类的种类数,在这里设置为2。 步距stride,卷积核kernel_size,补0padding都没有变化,直接进行训练
后面记录如何更改自己想要的尺寸。 经过一系列的卷积、激活、最大池化下采样之后经过全连接层
self.classifier = nn.Sequential(
nn.Dropout(p=0.5), # 元素归0减少网络连接防止过拟合
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes)
然后遍历整个网络在遍历之前设置一下权重,在遍历网络时在卷积层与全连接层之间需要torch.flatten将其展成一维
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
之后初始化权重
# 网络权重初始化
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d): # 如果是卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # 用(何)kaiming_normal_法初始化权重
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): # 如果果是全连接层
nn.init.normal_(m.weight, 0) # 初始化偏重为0
到此处我们相当于只在AlexNet中改了一个参数num_classes=2
train 文件(数据的加载与训练)
自己下载的数据集并放在工程文件夹下重命名为dataset如图
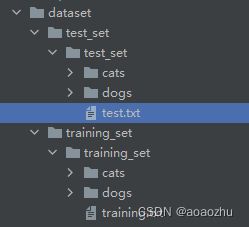
两个txt文件是自己创建的原本是没有的,小土堆的数据集是蜜蜂蚂蚁,此处用猫狗数据集,并且数据的读取也是用的小土堆的例程下面定义类
class MyData(Dataset):
def __init__(self, root_dir, names_file):
self.root_dir = root_dir
self.names_file = names_file
self.path = os.path.join(self.root_dir, self.names_file)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.names_file, img_name)
img = Image.open(img_item_path)
img = img.resize((224, 224)) # 图片尺寸不一样会报错
label = self.names_file
if label is "cats":
label = 0
else:
label = 1
img = torchvision.transforms.functional.to_tensor(img) # 将img中图片数据变成tensor数据类型
return img, label
def __len__(self):
return len(self.img_path)
这里不能照搬程序,root_dir给文件夹目录,names_file给猫狗文件夹名称,因为数据集已经分成了猫狗两个类别,并且也在文件名称上标注了,所以此处我们直接获取names_file在下面做出判断。为什么作此判断?之后在训练是会用到分成的类,在程序中我们用0到n个数与类别一一对应,有n个类就有n-1个数,如果不进行if判断将猫狗与1 0对应的话在训练的时候,与label对应的变量就得到字符串“cats”或”dogs“,组不成tensor类型的数据组所以在此加一个if判断将字符串变为int就能组成tensor了
接下来就是一系列的数据读取训练的操作了代码如下每一块都有注释的
img.resize更改图片大小,可以更改成想要的尺寸不过这里改过以后,在上面定义的类里面需要有所修改,修改的地方就是全连接层,需要计算对展开以后的点数,点数需要通过公式N = (W-F+2P)/S+1对每一层经过计算其尺寸最后得到输出通道数*N^2个点数。
# 训练集文件地址
root_dir = "../dataset/training_set/training_set"
cats_label_dir = "cats" # 文件夹名字
dogs_label_dir = "dogs"
cats_dataset = MyData(root_dir, cats_label_dir) # 利用MyData导入到变量dataset
dogs_dataset = MyData(root_dir, dogs_label_dir)
train_dataset = cats_dataset + dogs_dataset # 两种变量加和组成训练集dataset
# 测试集文件地址
root_dir = "../dataset/test_set/test_set"
cats_dataset = MyData(root_dir, cats_label_dir)
dogs_dataset = MyData(root_dir, dogs_label_dir)
test_dataset = cats_dataset + dogs_dataset # 两种变量加和组成测试集dataset
# print(train_dataset.__getitem__(dogs))
# 数据长度
test_data_size = len(test_dataset)
train_data_size = len(train_dataset)
print("训练数据集长度为{}".format(train_data_size))
print("测试数据集长度为{}".format(test_data_size))
# 数据读取 打包 打乱
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 引用网络模型
alex_net = AlexNet()
alex_net.train()
if torch.cuda.is_available():
alex_net = AlexNet.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(zxb_net.parameters(), lr=learning_rate, momentum=0.9)
# 设置训练网络的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练的轮数
epoch = 100
start_time = time.time()
for i in range(epoch):
print("*******第{}轮开始***********".format(i + 1))
# 训练步骤开始
for data in train_loader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = zxb_net(imgs)
loss = loss_fn(outputs, targets)
# 优化器调用
optimizer.zero_grad()
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print("训练100次花费时间{}".format(end_time - start_time))
print("训练次数{},loss{}".format(total_train_step, loss.item()))
# 测试步骤开始
total_test_loss = 0
with torch.no_grad():
for data in test_loader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = zxb_net(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
print("整体测试集的loss{}".format(total_test_loss))
torch.save(zxb_net, "zxb_net{}.pth".format(i))
print("模型已保存,训练结束")
最后把所有的程序都放在main()里面
def main():
if __name__ == '__main__':
main()
注意优化器里面的learning_rate是调节学习速率的就是吴恩达讲的机器学习里面的ɑ在训练的时候loss不会逐渐变小等训练十几轮就能显著降低loss了
predict 文件(预测判断文件)
device = torch.device("cuda:cats" if torch.cuda.is_available() else "cpu") # 是否有GPU否则在CPU运行
image_path = "../predicate_image/125.jpg"
image = Image.open(image_path)
image = image.convert('RGB') # 保留图片的RGB三通道,因为有的格式有四个通道如png多一个透明度
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((224, 224)),
torchvision.transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
image = transform(image)
assert os.path.exists(image_path), "file: '{}' dose not exist.".format(image_path) # 路径之中没有图片直接终止程序
# 加载网络模型
model = ZXBNet()
# 加载训练过的权重
weights_path = "../cat_vs_dog/zxb_net26.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
# 为网络加载参数模型
model=torch.load(weights_path)
image = torch.reshape(image, (1, 3, 224, 224))
model.eval()
with torch.no_grad():
output = torch.squeeze(model(image.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
output = model(image)
print(output)
print(output.argmax(1))
我的125.jpg图片如下
判断结果如下
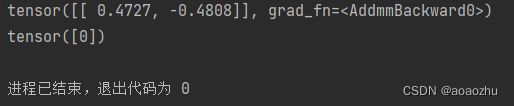
至此完成第一个神经网络的学习
我愿称之为究极缝合怪!