卷积神经网络学习笔记-基础知识
1、卷积神经网络结构
卷积神经网络结构包括:全连接层,卷积层,下采样层。

全连接层是许许多多得神经元相互链接得到,输入xi×权重w求和加偏置,经过激活函数得到输出y。将神经元列与列排列,列于列之间全连接,就得到了bp(back propagation)神经网络,算法包括前向传播和误差的反向传播。
激活函数一般使用Sigmoid或是ReLu函数。引入非线性因素,让其有解决非线性的能力。

卷积是一个卷积核在图像上滑动并计算,由于卷积核权值不变,卷积具有权值共享的特性和局部感知的特性。目的是对图像的特征进行提取。


对于一个特征矩阵,卷积核channel同其一样,输出的特征矩阵则于卷积核个数相同。W为原矩阵尺寸,F为卷积核的尺寸,P为填充像素数,S为步距。

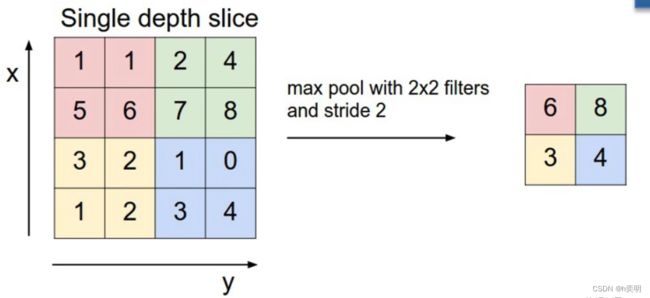
下采样层,不改变特征矩阵的Channel,图为最大下采样,作用是为了稀疏处理,降低计算量。
2、误差的计算
对于输出这里使用Softmax函数,将输出转换为和为一的概率问题。

通过交叉熵损失函数,求得输出o1、o2得损失。loss=-(O1*In(O1)+O2*In(O2)),得到损失后进行反向传播。

gradient=损失函数对权值进行求导,再对新权值更行,w(new)=w(old)-learning*gradient。
但由于实际情况不能将整个数据集一次性载入,是一个batch一个batch载入。为了使得网络更快收敛,引入优化器,对权值进行更新。

3、Lenet的构建

import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()#多继承
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
4、参考资料
霹雳吧啦Wz的个人空间_哔哩哔哩_Bilibili