端侧模型性能优化——Flops与访存量的坑
故事背景:笔者开发了一个端侧的模型,是在mobilnetV3-small-0.75(Flops:52M)的基础上魔改出来的,其Flops比mbv3-large-1.0(Flops:58M)是低的,但是其在端侧手机GPU上面的初始化时间却高很多,推理时间甚至是后者的两倍,带着这个问题,以及需要优化模型性能的目标,分析并调研了以下的内容。
一、当下比较流行的轻量级模型以及其优化策略
在学术界中,往往使用Flops来评估模型算力,其优化也是针对这一方面来优化的
- MobileNet:将传统conv替换为DWconv与PWconv,降低Flops,DW+PW = 传统conv,但是所需要的Flops更低,在论文中,V3Flops低于V2,且效果更好一些;
- octConv: 将传统conv替换为octConv,可以进一步降低Flops,其原理为卷积得到的特征中,存在高频特征与低频特征,而低频特征在卷积时可以降低分辨率,在论文中,ocv-mobilenet其Flops更低,且效果略好一些;
- GhostNet:将传统conv替换为ghost module,可以降低Flops,其原理特征映射之间的相关性与冗余性,即部分特征可以直接通过对其他特征进行简单的线性变换得到,而不用进行卷积;
- SkipNet:顾名思义,即认为多层的cnn,是为了解决部分cornercase而设计的,一部分case并不需要走完网络全程,所以可以通过“跳跃”的形式来提高性能;
- MobileVit:针对Mobile优化的VIT,其为transformer,并非传统cnn,故这里并没有多研究;
- TineNet: 其主要阐述了一个观点,即在轻量级网络上面,对于模型效果影响最多的因素,主要为分辨率>网络深度>网络宽度。
所以,理论上如果我们对于当前的模型,如果设计为skip-ghost-oct-mobilnet-sod的形式(融合怪哈哈哈),其Flops可以进一步降低;
但是此时笔者想到了另外两个问题:
1、之前兄弟团队基于NAS优化mbv3-large-1.0,其搜索出来的模型Flops优化了50%,性能优化却只有8%~20%之间,功耗优化只有1~2mA(测试平台为三星9815、sm8350,功耗不排除测试误差);
2、学术界mbv3性能和效果都优于mbv2,但是工业界却普遍反馈并非如此,为了验证,我们在一个回归任务上,使用训练集训练mbv2和mbv3(两个都经过imagenet预训练),v2误差比v3低2%,同时v2的性能确实比v3要高。
据此分析,Flops和性能功耗成正相关,但是并不是严格正比的关系;
二、实测不同模型的性能
基于高通8450平台,批跑一批图片,测试结果如下:
mobilnet 模型大小,Flops,op种类,层数等对于初始化以及推理性能的影响
| 模型类别 |
当前模型 |
mbv3-small-1.0 |
mbv2-1.0 |
mbv2-0.5 |
mbv3-large-1.0 |
|---|---|---|---|---|---|
| Flops | 52M | 58M | 314M | 103M | 224M |
| 模型大小(float 32,output1~35之间) | 4.85M | 5.93M | 8.46M | 2.62M | 16M |
| 初始化(无缓存) | 1.66s | 1.02s | 0.656s | 0.645s | 1.16s |
| 初始化(有缓存) | 170~210ms | 110~160ms | 100~140ms | 108~146ms | 110~170ms |
| 推理时间 | 24~28ms | 8~11ms | 7~8ms | 6~8ms | 10~12ms |
| params | 1.14M | 1.55M | 2.22M | 0.69M | 4.25M |
可以观察到以下几个现象:
- mbv2-1.0 VS mbv3-large-1.0, Flops更高,但是初始化时间和推理时间都更低;
- mbv2-1.0 VS mbv2-0.5, 后者Flops更低,但是初始化时间和推理时间都接近;
- 当前模型 VS mbv3-small-1.0, 两者Flops接近,但是前者初始化时间和推理时间都高很多;
经过查询资料以及与负责端侧算法框架的同事沟通后,了解到:
- 模型在各个平台上的初始化时间,和op种类以及网络层数有关;
- 模型在各个平台上的推理时间,和Flops和访存量有关;
- 目前在推理时,op内部可以并行计算,而各个op之间仍然是串行的;
带着这三个观点,结合下面的模型结构图,再看一下上面的现象:(最左边为当前模型)
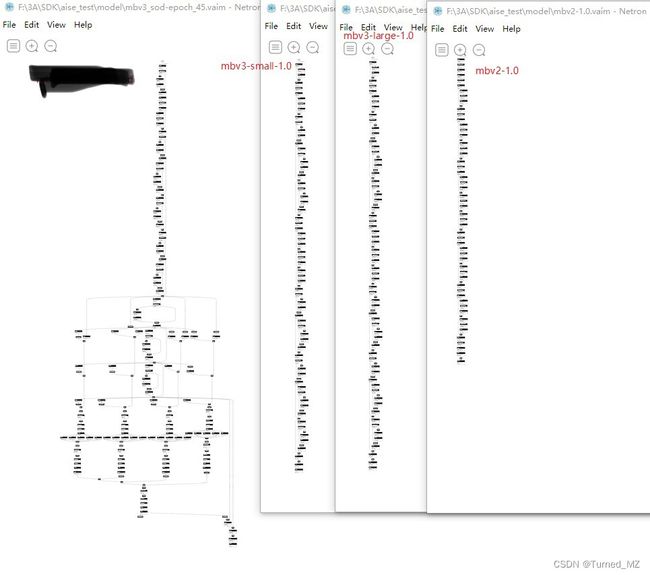
1、当前模型, 其深度、op种类,都高于mbv3-small-1.0或者mbv3-large-1.0,所以其初始化时间最长;
2、mbv2-1.0, 其深度,op种类都低于mbv3-small-1.0,所以其初始化时间最短;
初始化的时间差异,到这里就明白了。
那么为什么mbv3-small-1.0相对于mbv2-1.0 Flops更低,但是推理时间却更长了呢,Flops和访存量是怎么影响推理时间的呢?
三、决定模型性能的因素有哪些?
推荐这一篇文章,讲的很详细(下面内容是对这篇文章中一些重点的摘抄):深度学习模型大小与模型推理速度的探讨 – POLARAI.CN https://polarai.cn/540.html
https://polarai.cn/540.html
先解释几个概念:
- 计算量:计算量是模型所需的计算次数,即Flops(Floating Point Operations),即浮点计算次数。
- 参数量:参数量是模型中的参数的总和,参数量往往是被算作访存量的一部分,因此参数量不直接影响模型推理性能。但是参数量一方面会影响内存占用,另一方面也会影响程序初始化的时间。
- 访存量:访存量是指模型计算时所需访问存储单元的字节大小,反映了模型对存储单元带宽的需求。访存量一般用 Bytes(或者 KB/MB/GB)来表示,即模型计算到底需要存/取多少 Bytes 的数据。
- 模型的计算密度 :由计算量除以访存量就可以得到模型的计算强度,它表示此模型在计算过程中,每
Byte内存交换到底用于进行多少次浮点运算。单位是FLOPs/Byte。 - 内存占用:内存占用是指模型运行时,所占用的内存/显存大小。内存占用 ≠ 访存量。主要原因是其大小除了受模型本身影响外,还受软件实现的影响,和参数量一样,内存占用不会直接影响推理速度,往往算作访存量的一部分。
- 算力:也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是
FLOPS。 带宽:也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。- 计算强度上限 :两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是
FLOPs/Byte。
1. 计算密度与 RoofLine 模型
RoofLine 模型是一个用于评估程序在硬件上能达到的性能上界的模型,可用下图表示:

当程序的计算密度I较小时,程序访存多而计算少,性能受内存带宽限制,称为访存密集型程序,即图中橙色区域。在此区域的程序性能上界=计算密度×内存带宽,表现为图中的斜线,其中斜率为内存带宽的大小。计算密度越大,程序所能达到的速度上界越高,但使用的内存带宽始终为最大值。
反之如果计算密度I较大,程序性能受硬件最大计算峰值(下文简称为算力)限制,称为计算密集型程序,即图中蓝色区域。此时性能上界=硬件算力,表现为图中的横线。此时计算速度不受计算密度影响,但计算密度越大,所需内存带宽就越少。
在两条线的交点处,计算速度和内存带宽同时到达最大值。
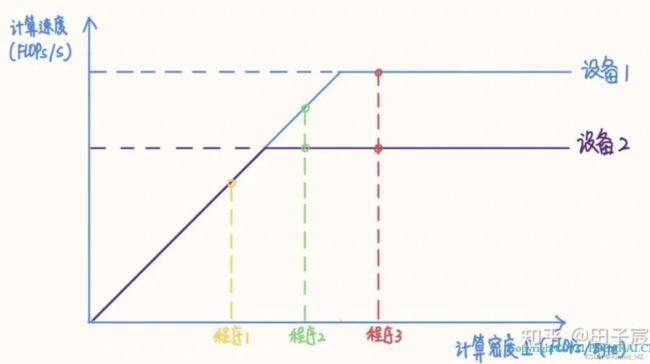
在不同设备上,同一个程序的性质可能发生变化。例如上图中的程序2,在算力稍弱的设备2上属于计算密集型程序,而在算力较强的设备1上就属于计算密集型程序了。如果想要充分发挥设备1的性能,应当适当加大程序的计算密度(比如到程序3的位置)。
2. 计算密集型算子与访存密集型算子
网络中的算子可以根据计算密度进行分类。一般来讲,Conv、FC、Deconv 算子属于计算密集型算子;ReLU、EltWise Add、Concat 等属于访存密集型算子。
同一个算子也会因参数的不同而导致计算密度变化,甚至改变性质,比如在其他参数不变的前提下,增大 Conv 的 group,或者减小 Conv 的 input channel 都会减小计算密度。
举个例子,对于不同参数的卷积,计算密度如下:

可以看到,不同参数下卷积算子的计算密度有很大的差异。第 4 个算子 Depthwise Conv 计算密度仅有 2.346,在当下的很多设备上都属于访存密集型算子。
算子的计算密度越大,越有可能提升硬件的计算效率,充分发挥硬件性能。我们以一个 Intel X86 服务器平台为例(10980 XE)。该平台 CPU 频率为 4.5 GHz,我们以 16 核为例,其理论 FP32 算力为 4.608 TFLOPs/s,内存带宽理论值为 96 GB/s。在此平台上的 RoofLine 模型为:
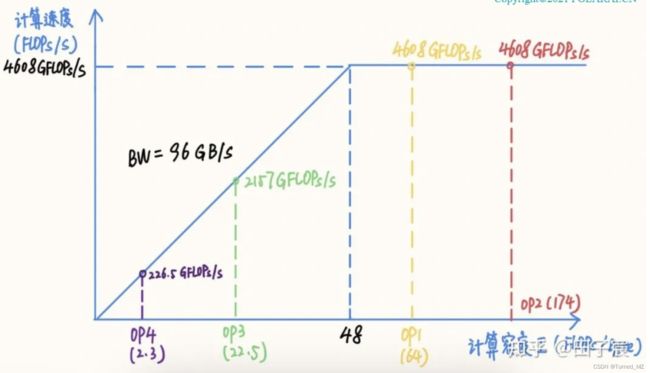
该平台“拐点”的计算密度为 48,计算较为密集的 OP1 和 OP2 处在计算密集区,能够达到平台的算力峰值;而 OP3 和 OP4 处在访存密集区,受内存带宽限制不能到达算力峰值,尤其是 OP4,由于计算访存比过低,计算效率仅有可怜的 4.9%,计算效率并不高。
3. 推理时间
这里涉及到一个 gap,很多部署的同学们更喜欢谈“计算效率”,而实际上算法同学真正关心的点是“推理时间”,导致两者在对接的时候经常会出现一些 misleading。因此我这里单独开一节来探讨一下“推理时间”的评估方法。
其实也很简单,按照 RoofLine 模型,我们很容易就能得到算子实际的执行时间:

这是一个分段函数,拆开来可得:
 一句话总结:对于访存密集型算子,推理时间跟访存量呈线性关系,而对于计算密集型算子,推理时间跟计算量呈线性关系。
一句话总结:对于访存密集型算子,推理时间跟访存量呈线性关系,而对于计算密集型算子,推理时间跟计算量呈线性关系。
按照 RoofLine 模型,在计算密集区,计算量越小,确实推理时间越小。但是在访存密集区,计算量与推理时间没关系,真正起作用的是访存量,访存量越小,推理的时间才越快。在全局上,计算量和推理时间并非具有线性关系。
OP4 虽然计算效率很低,但由于访存量也很低,因此其实推理速度还是快于其他几个 OP 的。但是我们可以观察到,其计算量虽然只有 OP1 的 1/130,但是推理时间仅降低到了 1/6,两者并非是线性关系(也是当年我把模型减到 1/10 计算量,但其实没快多少的原因)。
再举两个例子强化一下,首先看这两个卷积,他们的计算量差不多,但是因为都在访存密集区,OP3 的访存量远低于 OP5,其推理也更快:
![]() 下面这个栗子更明显,OP5 和 OP6 的区别仅仅是一个是 DepthWise Conv,一个是普通 Conv,其他参数没有变化。按照我们之前的直观感受,Conv 换成 DepthWise Conv 应该会更快,但实际上两者的推理时间是差不多的
下面这个栗子更明显,OP5 和 OP6 的区别仅仅是一个是 DepthWise Conv,一个是普通 Conv,其他参数没有变化。按照我们之前的直观感受,Conv 换成 DepthWise Conv 应该会更快,但实际上两者的推理时间是差不多的
![]()
有了上面的认知,再结合我们实际项目中使用的平台,分析以下:
下图显示的是两个不同的平台的算力和带宽情况

这里的half就是fp16,float就是fp32,带个4的表示测试的是向量性能,否则是标量性能,GPU用的是宽度为4的向量,half4就是4个fp16数一起运算;
可以看到,现在的AI推理,算力往往不是瓶颈,很多时候被访存性能卡住的,移动端的访存带宽其实并不高,按照8450 GPU,3T的fp16算力,mobilnet才0.5G,计算部分0.16ms的事情,但实际要3-5ms;还有CPU和GPU之间的数据拷贝,那个性能更慢,10G/s附近,折算成ms,是10M/ms,在实际相机中,GPU通常会被各个模块占用,实际给模型能用的就更少了。
还有一个值得注意的地方是,OP的访存量也需要考虑到数据的复用次数,数据从DRAM 加载到CPU或者GPU的寄存器后,实际会复用多次(假设次数为N),而不用每次重复从DRAM中读取,另外还有Cache的影响。
N的次数会随着OP的不同而有所不同,比如Fully Connected和Conv1x1,N会相差很大,这个是由OP的特点和计算策略来决定的。
三、分析结论,以及对于我们优化的指导
分析结论:
- 计算量并不能单独用来评估模型的推理时间,还必须结合硬件特性(算力&带宽),以及访存量来进行综合评估。
- 除上述因素外,系统环境也会对性能产生影响,比如GPU或者NPU在某些条件下会降频。
- 软件实现上也会影响性能,即底层框架对于算子的优化力度,比如空洞卷积(dilated Conv)性能会弱于普通卷积的原因是前者对访存的利用不如后者高效。
- 功耗层面,当前并没有可以直接预估的方式,必须要实测。
- 性能上,可以基于上述分析结果指导优化,但是有条件的情况下最好还是实测。
对于优化的指导:
- 对于高算力平台(GPU、DSP 等),一味降低计算量来降低推理时间就并不可取了,往往更需要关注访存量。
- 单纯降低计算量,很容易导致网络落到硬件的访存密集区,导致推理时间与计算量不成线性关系,反而跟访存量呈强相关(而这类硬件往往内存弱于计算)。
- 相对于低计算密度网络而言,高计算密度网络有可能因为硬件效率更高,耗时不变乃至于更短。
- 面向推理性能设计网络结构时,尽量采用经典结构,大部分框架会对这类结构进行图优化,能够有效减少计算量与访存量。
- 例如 Conv->BN->ReLU 就会融合成一个算子,但 Conv->ReLU->BN 就无法直接融合 BN 层
- 算子的参数尽量使用常用配置,如 Conv 尽量使用 3x3_s1/s2、1×1_s1/s2 等,软件会对这些特殊参数做特殊优化。
- CNN 网络 channel 数尽量选择 4/8/16/32 的幂次,很多框架的很多算子实现在这样的 channel 数下效果更好
参考内容:
深度学习模型大小与模型推理速度的探讨 – POLARAI.CN