apollo6.0激光雷达感知学习笔记
apollo6.0激光雷达的感知技术解析
讲解员:陈嘉豪 百度高级研发工程师
算法库有更新,激光雷达用了新的模型。


光学传感器就是自动驾驶车辆的眼睛。lidar是光学遥感技术。
非常精确的探测精度。高精度高分辨率的传感器。非常的可靠。
apollo支持多款雷达。

和赛,国产品牌。不间断的旋转,得到1帧完整的点云数据。

图中不同高度的颜色不同。
相机可能会出现过曝。
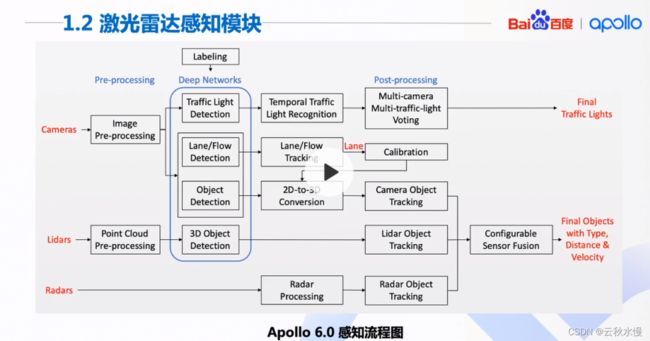
红绿灯时camera感知和高精度地图,
障碍物检测以lidar为主,camera为辅的。
车道线仅camera能做。车道线给标定做辅助。得到2D到3D。
lidar的流程很简单,预处理-目标检测-目标跟踪。但效果很好。
其精度高不高,实时性好不好,直接决定了apollo的感知的效果。

预处理:去除一些异常点,截取一定范围内的点云。
全新算法pointpillars模型;感知速度快实时性高。
感知是10hz输出。
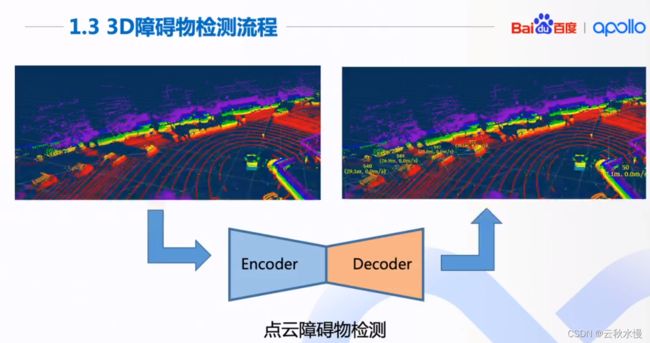
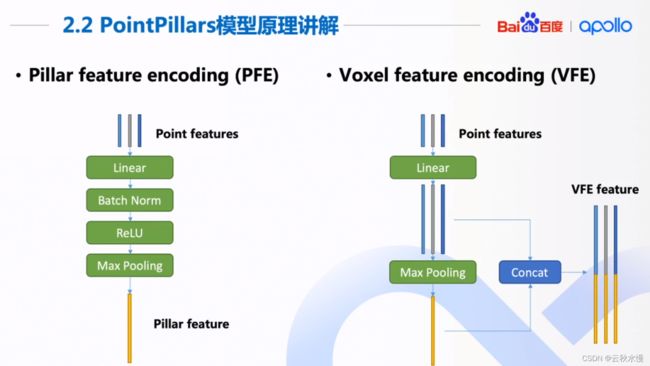
3维物体检测。算法概况为编码解码的结构。
编码得到算法更能理解的抽象的特征,然后解码成物体的3维框。

只用点云数据,不用其他传感器数据作为输入。
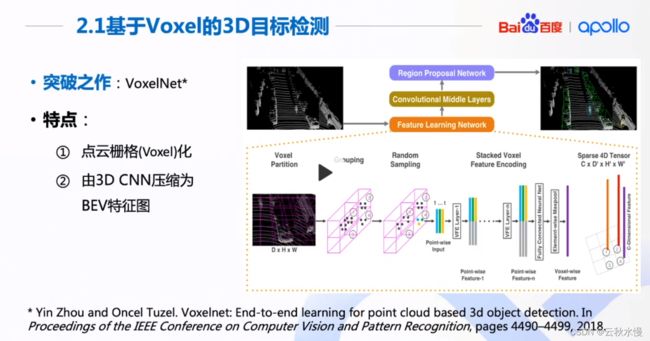
voxelnet突破之作。
传统的得到BEV的方法都是有损的压缩,必须加入图像等传感器的信息,才能得到好的检测效果。
原理是把点云做栅格化处理。大小相同的栅格,先提取每个栅格里的特征,再使用3维卷积。再用RPN网络得到检测框。
缺点是3维卷积非常的耗时。

pointpillars针对耗时的问题,提出的新的模型。
在voxel基础上做了改进,只用2维卷积。精度反而更好,速度更快。没有用3维卷积。
如何做的呢?
最大的特点是,点云转化成BEV的过程和VOXEL的不同。它不是得到网格,而是在x,y平面上得到柱子(pillars).转化成特征向量。
没有Z的信息,做2维卷积,速度更快。


focal loss为了缓解分类任务正负样本不均匀的问题。
weighted softmax loss泛化性更好。不同的类别加一些不同的权重。
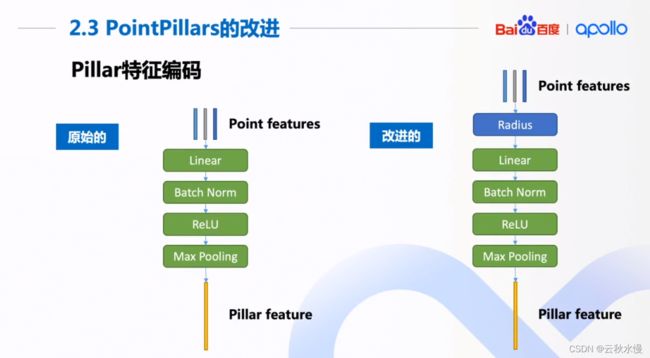
拿到点特征后,用x,y替换为radius。
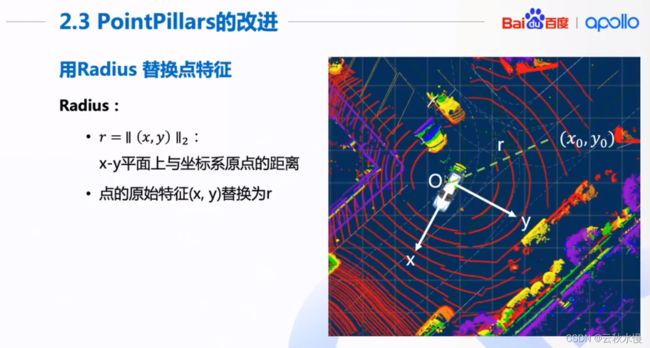
x,y的二范数。
用来输出最后的框和类别。
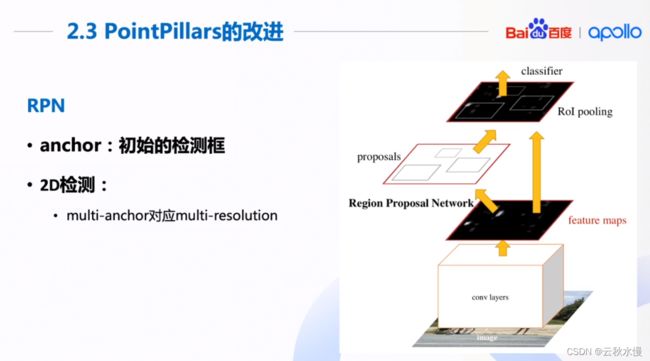
最初是针对2维检测。
设定初始的检测框,对应到特征图,然后后续处理,得到候选框。然后从候选框中选择模型要输出的目标。候选框一开始叫做anchor。
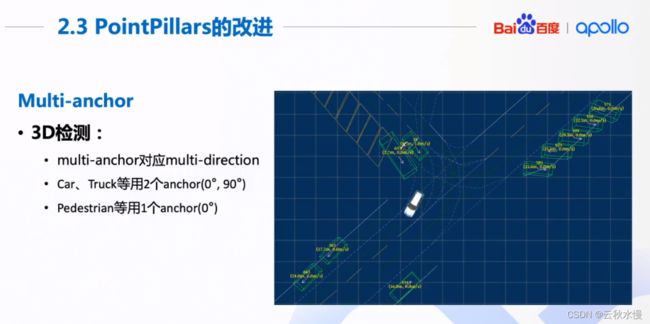
同一类物体的框大小相似,在鸟瞰图上只需要考虑朝向即可。但行人锥桶不需要考虑锥桶。
多设置一个45度角的anchor反而没有更好,时间反而增加了。



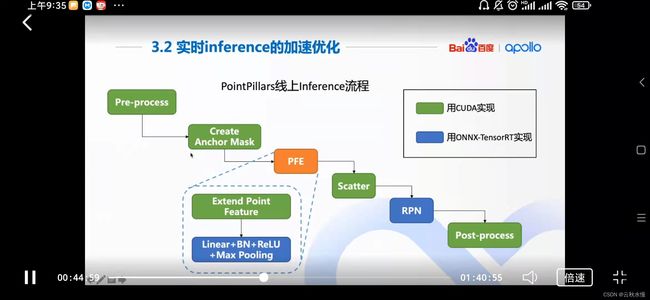
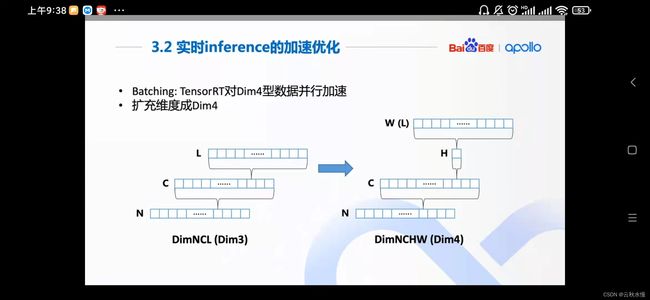

onnx随时切换训练的网络。
训练和推理的解耦。
问答环节:
问题1: 点云检测中,如何处理120米以外点云的检测分类?
即使是128线的激光雷达,有效距离也是仅一百米。120米已经非常稀疏,点很远,物体很容易受影响。所以apollo没有对120米外物体做检测。
问题2: 为什么复现模型的精度非常的低?
推荐github second (pointpillars)。
问题3:apollo采用了哪些方法进行了模型的加速?
2点。充分利用tensorrt加速极致,降低精度fp16,int8,尽量用cuda语言。
问题4:新人如何入门激光雷达感知?
问对了地方。最好的方式是使用Apollo的代码。理论基础,《apollo自动驾驶丛书》。
阅读论文,论文里给出的是最原始的知识。
问题5:基于gridmap的方式,pointoillars的优势?
前者是有损压缩,转化成鸟瞰图,pointpillars精度更高。
问题6:pointpillars的高频率检测方式,对10hz的点云意义不大?
检测的速度越快越好。就可以添加其他的处理方法,如预处理、后处理(目标框的筛检)的弥补。
问题7:3D点云处理算力是瓶颈吗?很吃资源。
获取pillars是最耗资源的。3万个pillars。速度确实会受影响。利用更高的显存来提升速度,更多的并行性操作。
问题8:频率是10hz,它的更新速度会影响感知效果吗?激光雷达期望的更新频率是多少呢?
1). apollo里以lidar为主,
2).够用了。如果高速场景40hz会更好。
问题9:pointpillars对没有训练过的物体进行识别?
取决于它的数据。如果没有训练过的物体,是不能够识别的。
利用后处理中,利用传统的三维视觉的方法来识别出来,如大石头等。来绕过它。
问题10:PPT点云的颜色怎么区分?
不同颜色代表了不同的高度。
问题11:毫米波雷达起到的作用,lidar已经很强大了?
与本次的课程是没有太多的关系。
问题12:tracking id是根据什么编号的?
是根据跟踪的结果。有时候编号达到了几百。是因为行驶过程中,会一直遇到新的目标。
问题13:激光雷达只扫到物体的一个面,可以通过聚类识别到物体吗?
pointlillars不是通过聚类得到的物体。很大的卡车停在前面,确实只看到1个面。这个取决于数据集。理论上比多个面的物体识别更难。如果面上有物体的形状信息,也可以识别到。
问题14:ppt里的图像看起来有点过曝,相机性能不好吗?
问题15:激光雷达能检测人行道等?
如果白粉很厚,很突出,才能检测得到。一般是检测不到。
只有突出轮廓的才能检测的比较好。车道线也是一样的。
问题16:vexel的运算速度如何?
问题17:点云需要有序吗?
vexel pillars里都不需要有序。
问题18:编码方式也属于有损压缩,pointnet才是无损压缩吧。
pointpillars用的即是pointnet的东西。max pooling。
问题19:鸟瞰图的优势
因为现有的模型不能直接处理三维的特征图,并且速度很快。三维卷积非常耗时非常的消耗算力。
主流的方法还是转化成鸟瞰图进行处理。自动驾驶都是在平面上行驶,所以可以看成1个平面,不需要很多的高度信息也可以。
也有一些新的方法。
问题20:pointpillars针对不同线束的点云,有哪些需要改进的地方?
可以针对不同线束的点云进行训练。最多取3万个pillars每个pillar最多60个点。对不同线束的点云的区别不大。
问题21:能否将改进效果直观些?
限于课程内容。
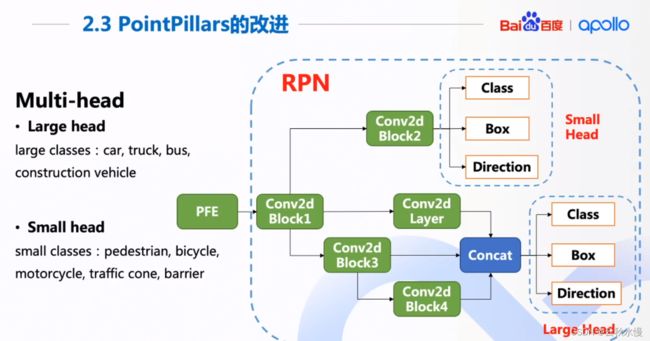
问题22:车辆和行人,apollo是使用了2个模型进行检测的吗?
用了统一的pillars的大小。用了1个模型。有9个类别输出。4个大目标、5个小目标。2个head来输出类别。
问题23:设置anchor的多少的依据是什么呢?
根据长宽比。大的设置2个,接近的设置1个。
问题24:pointpillars的改进版在kitti上测试过吗,精度怎么样呢?
测试过。结果比pointpillars的ap值高一些。
问题25:radius?
把x,y替换成了radius.因为x,y没有必要用2个。
问题26:二维卷积
大物体,需要global的信息。
小物体,只需要1阶段的卷积,不需要第三个阶段的更global的特征的。
问题27:传统的方法和深度学习结合的好的方法呢?
pointnet
问题28:kitti基准,如果只有点云数据,没有相机的数据、没有相机标定数据的话。怎么训练呢?