【刘二大人 - PyTorch深度学习实践】学习随手记(二)
目录
10. Basic CNN
回顾:全连接神经网络
本节:处理图像时常用的二维卷积神经网络
图像
卷积(Convolution)
卷积层(Convolutional Layer)
Padding(填充)
Stride(步长)
最大池化层(Max Pooling Layer)
一个简单的卷积神经网络
如何使用GPU?
Exercise
11. Advanced CNN
GoogLeNet
Inception Module
1×1 卷积
Inception Module 的实现
ResNet
Deep Residual Learning
Residual Network
简单利用残差块的网络
Exercise
接下来的路怎么走
10. Basic CNN
CNN(Convolutional Neural Network):卷积神经网络
回顾:全连接神经网络
- 定义:网络中用的都是线性层,且为串型连接
- 输入和每一个输出,任意两个节点间都存在权重,即每一个输入节点都要参与下一层每一个输出节点的计算上
- 丧失了一些原有的空间信息(两个点在图像中原本为相邻点,但展平之后可能距离很远)

import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()--------------------------------------------------------------------------------------------------------------------------------
本节:处理图像时常用的二维卷积神经网络
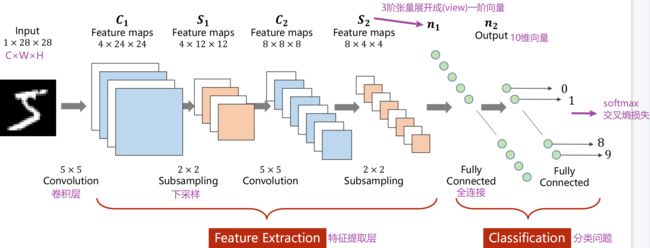
- 卷积层:保留图像的空间特征,把图像按照原始空间结构进行保存
- 下采样:通道数不变,图像的宽度和高度会发生改变(目的:减少数据量,降低运算需求)
两者合称为特征提取层:通过卷积运算找到某种特征
经过特征提取后,变为一个向量,再经过全连接网络去做分类(分类器)
--------------------------------------------------------------------------------------------------------------------------------
图像
图像的表示方法:
- 栅格图像:RGB 图像即为一个一个格子,每个格子里都有颜色值
- 矢量图像

卷积:
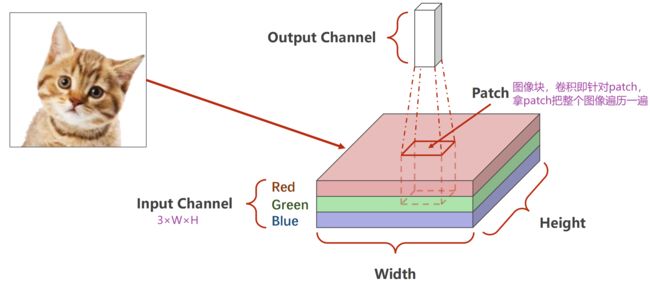 最后输出的通道数取决于卷积核的个数
最后输出的通道数取决于卷积核的个数
---------------------------------------------------------------------------------------------------------------------------------
卷积(Convolution)
(1)单通道(Single Input Channel)
- Input:1×5×5
- Kernel:3×3
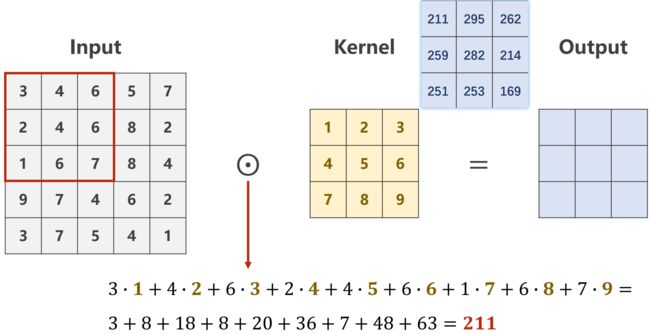 数乘:对应元素相乘
数乘:对应元素相乘
(2)多通道(3 Input Channels)

图像里的一个patch = 3×3×3的张量
输入的通道数 = 卷积核的数量

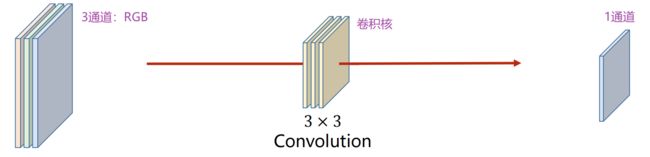 (3)多通道(N Input Channels)
(3)多通道(N Input Channels)
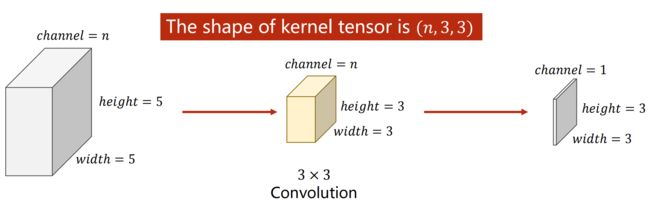
(4)多通道(N Input Channels and M Output Channels)
若有m个卷积核,最后输出的通道数为m
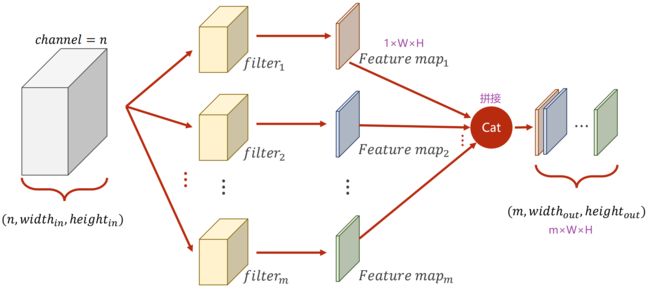
总结:
- 每一个卷积核的通道数 = 输入通道数
- 卷积核的总数 = 输出通道数
- 卷积核大小自己定,与图像大小无关
- 对每一个图像块做运算时,用的都是相同的卷积核(共享权重机制)

--------------------------------------------------------------------------------------------------------------------------------
卷积层(Convolutional Layer)
import torch
in_channels ,out_channels = 5,10 # 输入通道数n=5,输出通道数m=10
width , height = 100,100 # 图像大小
kernel_size = 3 # 卷积核大小,若为常数3,即3×3;若为元组(5,3),即5×3
batch_size = 1
input = torch.randn(batch_size,in_channels,width,height) # randn为正态分布采样随机数
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)卷积层对输入图像的宽度和高度没有要求,对输入通道数有要求
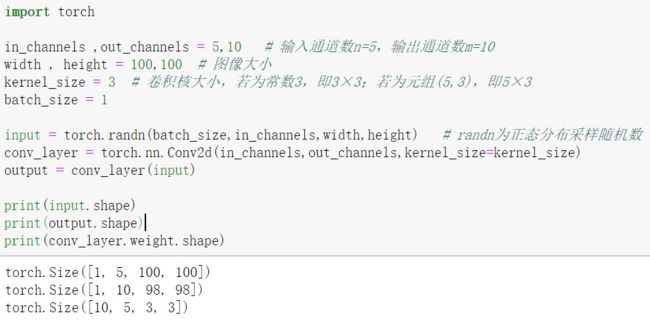
卷积核大小为 3×3 时,图像大小(宽和高)都会减小 2 个单位
--------------------------------------------------------------------------------------------------------------------------------
Padding(填充)
若希望 Output 大小不变(与 Input 保持一致),可以采用填充(padding)的方式
- 若卷积核为3×3,3整除2为1,则 padding=1
- 若卷积核为5×5,5整除2为2,则 padding=2
- 以此类推

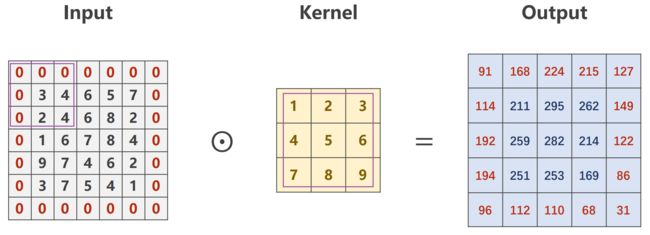 填充0
填充0
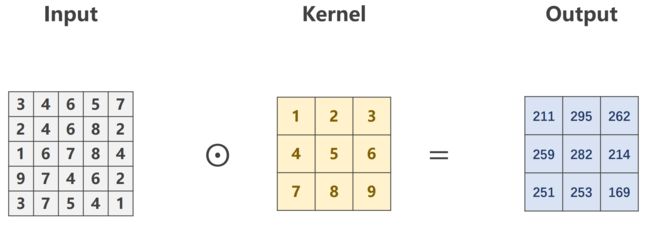
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5) # B,C,W,H 其中batch_size=1意味着一次送入一张照片
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,padding=1,bias=False) # bias:进行完卷积后对通道加上偏置量
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3) # out_channels, in_channels, kernel_width, kernel_height
conv_layer.weight.data = kernel.data # 初始化卷积层权重;kernel为张量,所以要用.data
output = conv_layer(input)
print(output)
Stride(步长)
有效降低图像的宽、高度

import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5)
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,stride=2,bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
---------------------------------------------------------------------------------------------------------------------------------
最大池化层(Max Pooling Layer)
为下采样的一种,最大池化的特点是:无权重,通道数不变,用 2×2 的 maxpooling,图像的大小会变为之前的一半

import torch
input = [3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6]
input = torch.Tensor(input).view(1,1,4,4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2) # kernel_size=2 默认 stride=2
output = maxpooling_layer(input)
print(output)
---------------------------------------------------------------------------------------------------------------------------------
一个简单的卷积神经网络
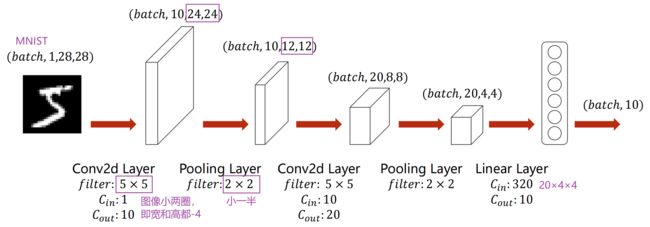
卷积和池化不在乎输入图像的大小,但最后的分类器在乎:对每一个样本来说元素个数
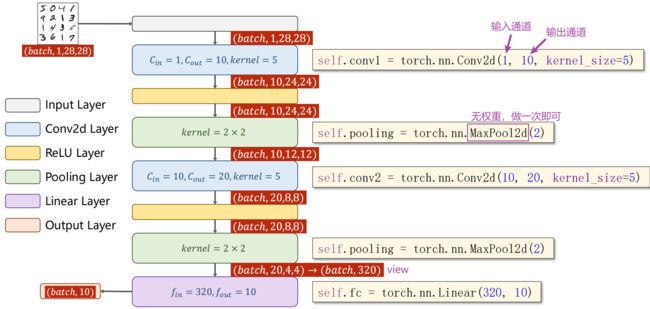
import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2) # 无权重,做一次就行
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
# Flatten data from (n,1,28,28) to (n,784)
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = x.view(batch_size,-1) # Flatten,采用view()变为全连接网络需要的输入
x= self.fc(x)
return x # 最后一层不做激活,因为要算交叉熵损失
model = Net()如何使用GPU?
1、Move Model to GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0 表示第一块显卡,取决于显卡的数量
model.to(device)
2、Move Tensors to GPU


完整代码:
# 0.导包
import torch
from torchvision import transforms # 对图像进行原始处理的工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 为了使用函数 relu()
import torch.optim as optim # 为了构建优化器
# 1.准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), # PIL Image 转换为 Tensor
transforms.Normalize((0.1307, ),(0.3081, ))]) # 归一化到0-1分布,其中mean=0.1307,std=0.3081
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
# 2.设计模型
import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2) # 无权重,做一次就行
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
# Flatten data from (n,1,28,28) to (n,784)
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = x.view(batch_size,-1) # Flatten,采用view()变为全连接网络需要的输入
x= self.fc(x)
return x # 最后一层不做激活,因为要算交叉熵损失
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0 表示第一块显卡,取决于显卡的数量
model.to(device)
# 2.设计模型
import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2) # 无权重,做一次就行
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
# Flatten data from (n,1,28,28) to (n,784)
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = x.view(batch_size,-1) # Flatten,采用view()变为全连接网络需要的输入
x= self.fc(x)
return x # 最后一层不做激活,因为要算交叉熵损失
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0 表示第一块显卡,取决于显卡的数量
model.to(device)
# 3.构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# 4.训练
def train(epoch): # 把一轮循环封装到函数里
running_loss = 0
for batch_idx, data in enumerate(train_loader,0):
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
optimizer.zero_grad()
# 前馈 反馈 更新
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # 每300批量输出一次
print('[%d,%5d]loss: %.3f' % (epoch+1,batch_idx+1,running_loss/2000))
running_loss = 0
# 5.测试
epoch_list = []
accuracy_list = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
outputs = model(inputs)
_,predicted = torch.max(outputs.data,dim=1) # 求每一行里max的下标,对应着分类,其中dim=1为行,dim=0为列
total += target.size(0) # (N,1),取N
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' %(100*correct/total,correct,total))
accuracy_list.append(correct/total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
epoch_list.append(epoch)
画图:
import matplotlib.pyplot as plt
plt.plot(epoch_list,accuracy_list)
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.show()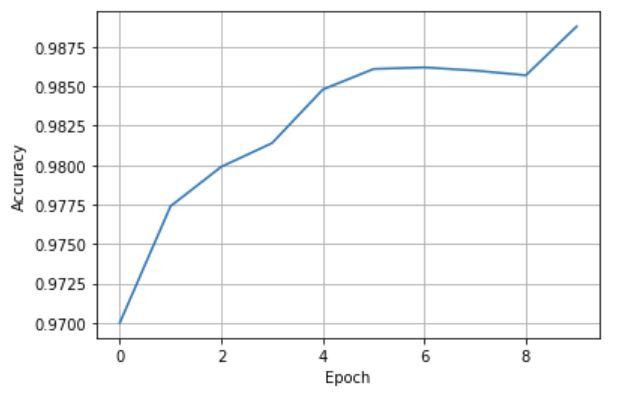
---------------------------------------------------------------------------------------------------------------------------------
Exercise

11. Advanced CNN
- 卷积神经网络、多层感知机、全连接网络 —— 串型结构(输出是下一层的输入)
如下图的例子,用了2个卷积层、2个池化层、2个全连接层,近似LeNet5
- 高级CNN —— 可能会有分支等结构
--------------------------------------------------------------------------------------------------------------------------------
GoogLeNet
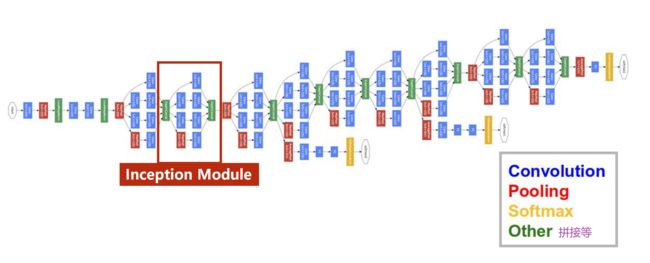
- Inception Module(块):蓝蓝红+四个蓝,封装为一个类
- 减少代码冗余,减少重复:使用函数(如C语言),或构造自己的类(如面向对象方法)
Inception Module
构造神经网络时,有的超参数是比较难选的,如卷积核大小。GoogLeNet 的出发点是:在一个块里把几种卷积都用一下,将来好用的那一种卷积核权重就会变得比较大,其他路线的权重会相对变小,即提供了几种候选的卷积神经网络的配置,通过训练自动找到卷积最优的组合
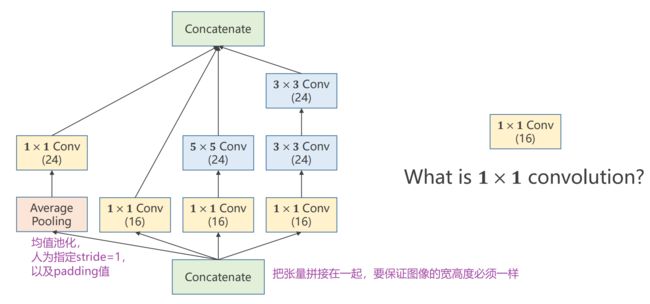
四条路径,四个张量要拼接在一起,必须要保证它们的宽高度一致
(batch,channel,width,height)走不同路径,channel 可以不同,width 和 height 必须保持一致
- 后3条,padding 即可
- 第1条,均值池化时为了保证W和H不变,人为指定 stride=1,padding=某个值(如3×3做均值,padding=1)
最大池化会导致图像变为原来的一半
1×1 卷积
卷积个数取决于输入张量的通道
作用:改变通道数量
- C×W×H 通过 1×1 卷积,变为 1×W×H
- 若希望输出的通道数为m,则使用m个 3个1×1卷积 叠加在一起的卷积
输出中的每一个元素,都包含了输入通道所有相同位置的信息(信息融合)
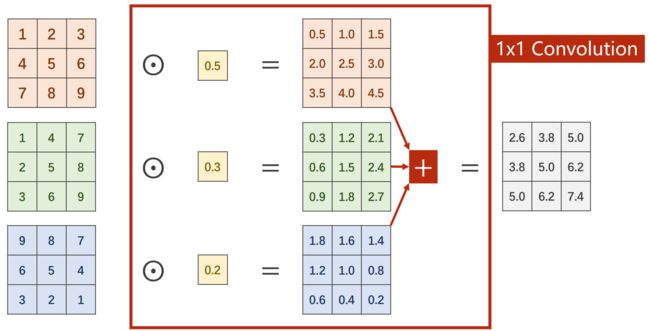
Why 1×1 Convolution
1×1 卷积又叫 Network in Network
- 运算量降低:如图,运算量只有以前的十分之一
- 改变通道数量

Inception Module 的实现
(1)4条分支
4个分支 (B,C,W,H) 只有C不一样,它们的通道数分别为:24、16、24、24
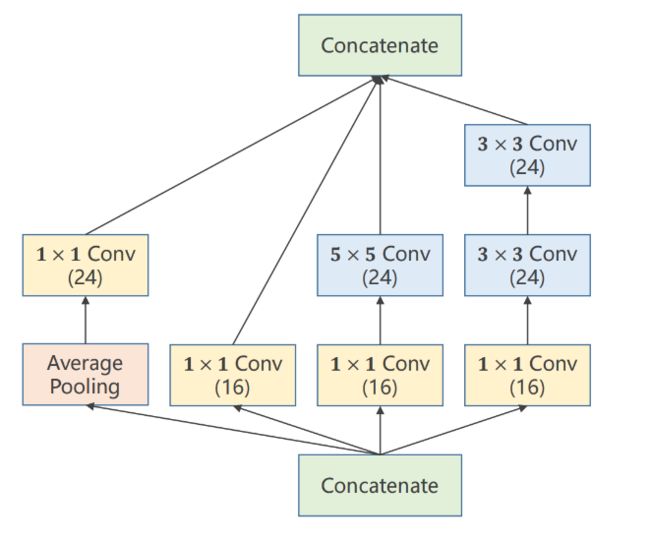 括号里的数字为 输出通道数
括号里的数字为 输出通道数 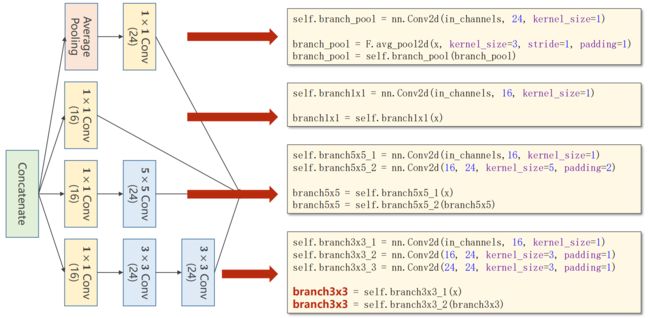 4条分支
4条分支
代码:
import torch
import torch.nn as nn
from torch.nn import Conv2d
# 第一条分支
# init
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
# forward
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1) # 平均池化,要保证Average后图像的宽度和高度不变,因为最后四条输出要拼接
branch_pool = self.branch_pool(branch_pool)
# 第二条分支
self.branch1x1 = nn.Conv2d(in_channels,16,kernel_size=1) # init
branch1x1 = self.branch1x1(x) # forward
# 第三条分支
# init
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1) # 输出16是下一个的输入
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2) # 为了保证图像的H和W不变,padding=2
# forward
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
# 第四条分支
# init
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1) # 注意输出通道与输入通道的匹配
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
# forward
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)(2)拼接 Concatenate
 4条分支的输出沿着通道维度拼接在一起
4条分支的输出沿着通道维度拼接在一起
代码:
outputs = [branch1x1,branch5x5,branch3x3,branch_pool] # 列表
return torch.cat(outputs,dim=1) # (b,c,w,h) dim=1表示c--------------------------------------------------------------------------------------------------------------------------------
重点代码:
(1)Inception
把 Inception 抽象为类,构建网络时就可以调用
import torch
import torch.nn as nn
from torch.nn import Conv2d
# Inception
class InceptionA(nn.Module):
# 初始输入通道并未写死,作为构造函数里初始化的参数,目的是为了实例化时可指明输入通道
def __init__(self,in_channels):
super(InceptionA,self).__init__()
# 分支1
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
# 分支2
self.branch1x1 = nn.Conv2d(in_channels,16,kernel_size=1)
# 分支3
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
# 分支4
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
def forward(self,x):
# 分支1
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool = self.branch_pool(branch_pool)
# 分支2
branch1x1 = self.branch1x1(x)
# 分支3
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
# 分支4
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)(2)用2个Inception模块
# 用2个Inception模块
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(88,20,kernel_size=5) # 88是由incep1来的
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2) # 经过MaxPooling后图像的宽高度一直在减小
self.fc = nn.Linear(1408,10) # fc 全连接
def forward(self,x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # 卷积—>池化—>relu
x = self.incep1(x) # 输入通道=10,输出通道=88(三个分支输出通道为24,一个为16,所以为24×3+16=88)
x = F.relu(self.mp(self.conv2(x))) # 输入88,输出20
x = self.incep2(x) # 输出88
x = x.view(in_size,-1) # 变为向量
x = self.fc(x) # 全连接做分类
return x- 1408怎么来的?
根据MNIST数据集28×28的宽度和高度,经过网络后,到fc层,inception2层的输出每张图像包含1408个元素 - 如何计算得到1408?
开发中实际不去计算(为了保证网络不出错),而是在定义模块时先去掉3行:
根据输入构造MNIST大小的随机张量输入,实例化后计算一下,看输出的size即可self.fc = nn.Linear(1408,10) x = x.view(in_size,-1) x = self.fc(x)
--------------------------------------------------------------------------------------------------------------------------------
完整代码:
# 0.导包
import torch
from torchvision import transforms # 对图像进行原始处理的工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 为了使用函数 relu()
import torch.optim as optim # 为了构建优化器
# 1.准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), # PIL Image 转换为 Tensor
transforms.Normalize((0.1307, ),(0.3081, ))]) # 归一化到0-1分布,其中mean=0.1307,std=0.3081
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
import torch
import torch.nn as nn
from torch.nn import Conv2d
# Inception
class InceptionA(nn.Module):
# 初始输入通道并未写死,作为构造函数里初始化的参数,目的是为了实例化时可指明输入通道
def __init__(self,in_channels):
super(InceptionA,self).__init__()
# 分支1
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
# 分支2
self.branch1x1 = nn.Conv2d(in_channels,16,kernel_size=1)
# 分支3
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
# 分支4
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
def forward(self,x):
# 分支1
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool = self.branch_pool(branch_pool)
# 分支2
branch1x1 = self.branch1x1(x)
# 分支3
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
# 分支4
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)
# 2.设计模型,用2个Inception模块
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(88,20,kernel_size=5) # 88是由incep1来的
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2) # 经过MaxPooling后图像的宽高度一直在减小
self.fc = nn.Linear(1408,10) # fc 全连接
def forward(self,x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x))) # 卷积—>池化—>relu
x = self.incep1(x) # 输入通道=10,输出通道=88(三个分支输出通道为24,一个为16,所以为24×3+16=88)
x = F.relu(self.mp(self.conv2(x))) # 输入88,输出20
x = self.incep2(x) # 输出88
x = x.view(in_size,-1) # 变为向量
x = self.fc(x) # 全连接做分类
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0 表示第一块显卡,取决于显卡的数量
model.to(device)
# 3.构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# 4.训练
def train(epoch): # 把一轮循环封装到函数里
running_loss = 0
for batch_idx, data in enumerate(train_loader,0):
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
optimizer.zero_grad()
# 前馈 反馈 更新
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # 每300批量输出一次
print('[%d,%5d]loss: %.3f' % (epoch+1,batch_idx+1,running_loss/2000))
running_loss = 0
# 5.测试
epoch_list = []
accuracy_list = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
outputs = model(inputs)
_,predicted = torch.max(outputs.data,dim=1) # 求每一行里max的下标,对应着分类,其中dim=1为行,dim=0为列
total += target.size(0) # (N,1),取N
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' %(100*correct/total,correct,total))
accuracy_list.append(correct/total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
epoch_list.append(epoch) 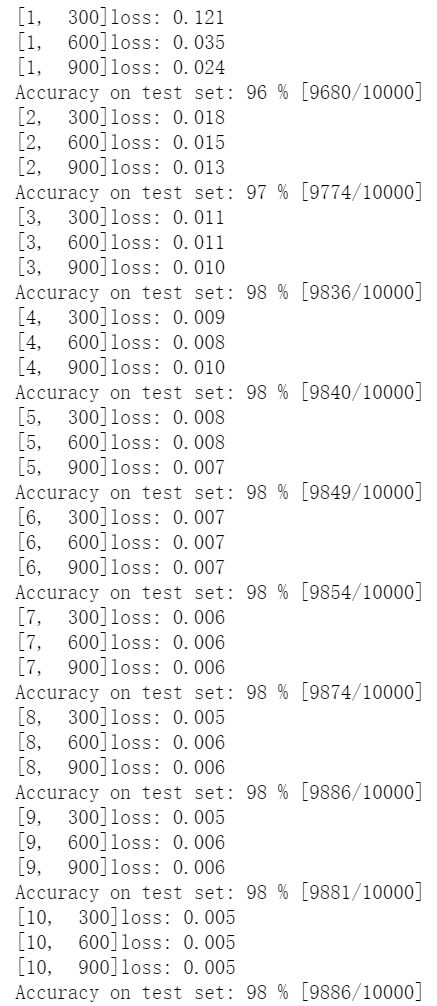
性能提高不多的主要原因:最后的全连接层层数较少,但是怎么改变卷积层来提高性能才是最主要的
import matplotlib.pyplot as plt
plt.plot(epoch_list,accuracy_list)
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.show() test 训练曲线
test 训练曲线
图中可以看出 Accuracy 最大值并不在最后一轮,所以:
- 训练神经网络时不是训练轮数越多越好,可能会过拟合,观察 test 决定网络训练多少轮合适
- 若某一次测试集准确率达峰值,将当前网络的参数做备份、存盘,这便是泛化性能最好的网络
---------------------------------------------------------------------------------------------------------------------------------
ResNet
把 3×3 卷积一直堆下去,性能会不会变好?

结果发现:20层卷积比56层卷积性能要好
可能原因:梯度消失
- 反向传播:链式法则把一连串的梯度乘起来
- 若梯度都小于1,连乘后梯度g趋于0
- 权重更新公式:w = w - αg,若g趋于0,则w得不到更新,离输入较近的块没法得到充分训练
解决梯度消失的方法:加锁、逐层训练。但由于深度学习里层数太多,难以用该方法训练。故有了ResNet 的提出
---------------------------------------------------------------------------------------------------------------------------------
Deep Residual Learning

Residual net
- 先和x相加(输出与x的输入的张量维度:C、H、W必须都一样,才能相加),再激活

- 解决梯度消失的问题,离输入近的那些层能得到充分的训练
Residual Network
残差网络的两种结构:
- 串型
- 跳连接(两个一组)
 颜色切换表明图像输入的宽高度发生了变化
颜色切换表明图像输入的宽高度发生了变化
x 经过最大池化层可以转化为同样大小
--------------------------------------------------------------------------------------------------------------------------------
简单利用残差块的网络

kernel_size为5时,经过卷积后,图像的宽高度各减小4个单位

Weight Layer:
- 第一个 Weight Layer:先卷积再激活
- 第二个 Weight Layer:先卷积,再加x,最后激活(卷积层输入、输出通道要与x保持一致)


import torch
import torch.nn as nn
from torch.nn import Conv2d
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1) # padding=1是为了保证图像输出大小不变(因为卷积核为3,所以3整除2为1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y) # 即F(x)+x,注意是先求和再激活利用2个 residual block 实现简单的残差网络
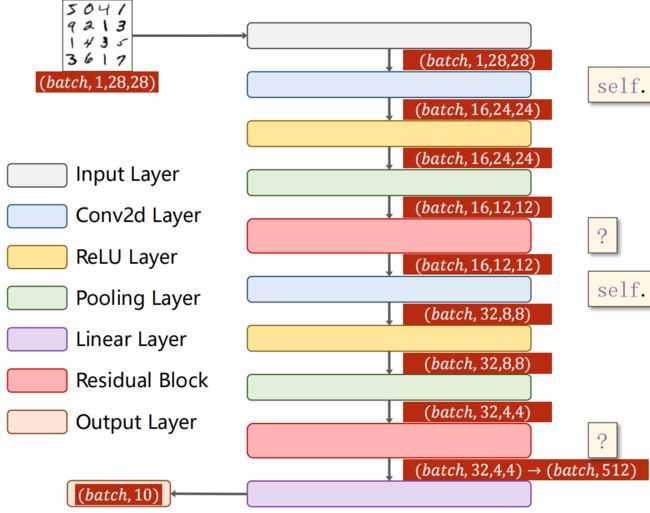
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,16,kernel_size=5)
self.conv2 = nn.Conv2d(16,32,kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16) # 括号里的数字是输入维度
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = view(in_size,-1)
x = self.fc(x)
return x注意事项:
- 网络结构非常复杂时,可以用新的类去封装它。若有不同的运行分支,可以分开计算,最后拼接到一起
- 构造网络时的超参数及网络里的 size 要算出来,但若想检验结果是否算的都对,可以创建完网络后,写一个简单的测试方法,先把其他行注释掉,看输出结果和预期的张量大小是否一致
- 逐步式渐增(增量式开发网络):渐渐增加网络的规模,保证每一步加上一个新的模块后,输出张量都是对的(保持每一层的结构符合预期)
完整代码:
# 0.导包
import torch
from torchvision import transforms # 对图像进行原始处理的工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 为了使用函数 relu()
import torch.optim as optim # 为了构建优化器
# 1.准备数据
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), # PIL Image 转换为 Tensor
transforms.Normalize((0.1307, ),(0.3081, ))]) # 归一化到0-1分布,其中mean=0.1307,std=0.3081
train_dataset = datasets.MNIST(root='../dataset/mnist',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
# Residual Block
import torch.nn as nn
from torch.nn import Conv2d
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)
# 2. 设计模型
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,16,kernel_size=5)
self.conv2 = nn.Conv2d(16,32,kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0 表示第一块显卡,取决于显卡的数量
model.to(device)
# 3.构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# 4.训练
def train(epoch): # 把一轮循环封装到函数里
running_loss = 0
for batch_idx, data in enumerate(train_loader,0):
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
optimizer.zero_grad()
# 前馈 反馈 更新
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # 每300批量输出一次
print('[%d,%5d]loss: %.3f' % (epoch+1,batch_idx+1,running_loss/2000))
running_loss = 0
# 5.测试
epoch_list = []
accuracy_list = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
outputs = model(inputs)
_,predicted = torch.max(outputs.data,dim=1) # 求每一行里max的下标,对应着分类,其中dim=1为行,dim=0为列
total += target.size(0) # (N,1),取N
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' %(100*correct/total,correct,total))
accuracy_list.append(correct/total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
epoch_list.append(epoch) 
import matplotlib.pyplot as plt
plt.plot(epoch_list,accuracy_list)
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.show()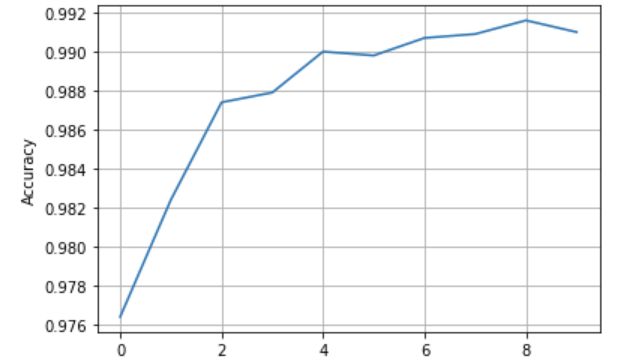
---------------------------------------------------------------------------------------------------------------------------------
Exercise
1、He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C]
- 有关 residual block 块的设计
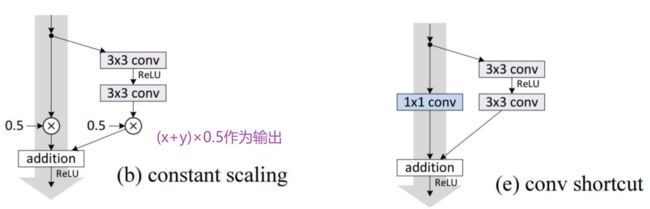
2、Huang G, Liu Z, Laurens V D M, et al. Densely Connected Convolutional Networks[J]. 2016:2261-2269.
- DenseNet

--------------------------------------------------------------------------------------------------------------------------------
接下来的路怎么走
- 理论角度深入理解,从数学和工程学角度,推荐《深度学习》花书
- 阅读 pytorch 文档(API Reference),通读一遍
- 复现经典工作,光下载代码并跑题只是会配置环境,完全不足够,需要循环读代码和写代码的过程(读代码需要读系统架构,包括训练架构、测试架构、数据读取、损失函数构建等等)
- 扩充视野,读相关领域论文,组装小模块