语音处理/语音识别基础(六)- 语音的端点检测(EPD/VAD)
端点检测(End-point Detection,简称 EPD)的目标,是要找到音频信号(音讯)的开始和结束的位置,所以又可以称为 Speech Detection 或是 VAD (Voice Activity Detection)。端点检测在语音处理与识别中,扮演重要的角色,可以基于时域,或者基于频域来做 EPD。
本文尝试解答如下问题:
1).为什么使用基于频域的方法来做音频的分析?
2).什么是语谱图,语谱图有什么作用?
3).语谱图中,如何区分出来清音、噪音和浊音?
4).如何衡量数据的多样性?
5).音频帧的熵值如何计算?
读完此文以及前面的系列文章,你应当可以解答这些问题。
常见的端点检测方法与相关的特征参数,可以分成两大类:
时域(Time Domain)的方法:
计算量比较小,因此比较容易移植到计算能力较差的计算机平台。
1).音量:只使用音量来进行端点侦测,是最简单的方法,但是会对气音造成误判。不同的音量计算方式也会造成端点侦测结果的不同,至于是哪一种计算方式比较好,并无定论,需要靠大量的资料来测试得知。
2).音量和过零率:以音量为主,过零率为辅,可以对气音进行较精密的检测。
频域(Frequency Domain)的方法:
计算量比较大,因此比较难移植到计算能力较差的计算机平台。
频谱的 Variance(spectral variances):浊音的频谱变化较规律,Variance 较低,可作为判断端点的基准。
频谱的Entropy:浊音的规则的频谱幅度会产生低的熵值,因此我们可以使用使用 Entropy 来做为 EPD 检测的一个条件。
简单地说,若只是对声音波形做一些较简单的运算,就是属于时域的方法。另一方面,凡是要用到傅立叶转换(Fourier Transform)来产生声音的频谱,就是属于频谱的方法。这种分法常被用来对音讯处的方法进行分类,但有时候有一些模糊地带。
频域的分析有效果,对于声音信号,实际上是因为人对于频域的敏感性远超时域特征的敏感度。 可以认为人耳就是一个频谱分析仪,还是一台非常准确的频谱分析仪(只能说是准确,不能说精确,因为单纯人耳不能精确地量化声音信号)。
一、基于时域(Time Domain) 的 EPD 检测
1).基于音量的端点检测
第一种方法,是直接使用音量来进行端点侦测的方法。
这是一种最简单的方法,只要音量小于某个门槛值,我们就认定是静音或是杂讯,至于这个门槛值如何决定,除了靠人的直觉外,比较客观的方法,还是靠大量的测试资料来决定最佳值。
在计算音量时,请务必记得要先经过零点校正(参考前面一篇 声音的音量,过零率,音高的计算 中的“零调整”)。否则噪音的影响非常大。
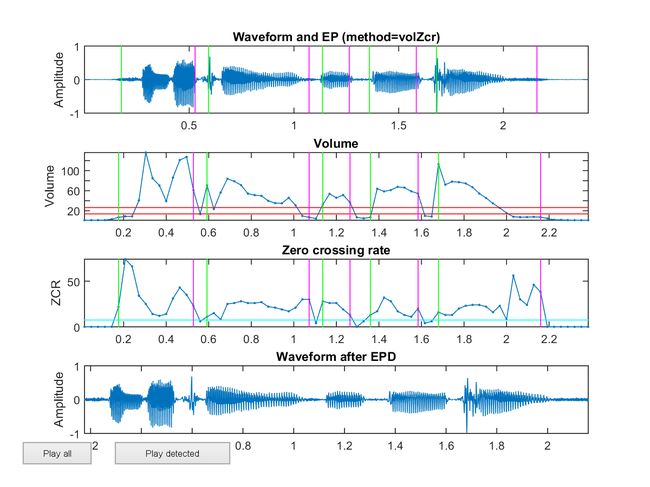
选择一个 Vth 作为静音的音量标记,一帧的音量小于 Vth 认为是静音,大于 Vth 是有声音的片段。如图绿线的标记为声音的开头,紫色线是结尾,图中共有 5 段声音。

如何确定门槛值 Vth, 简单的方法, 可以使用如下三个音量中的一个作为门槛值,来进行端点侦测:
A.音量最大值的 0.1:此方法在音量忽大忽小时或杂讯太强时,会发生错误。
B.音量最小值的 5 倍:此方法在杂讯太强时,会发生错误。
C.第一个音帧的音量的 4 倍:此方法假设一开始是静音,但若一开始就有声音,或是录音器材一开始有偏移,此做法就很容易发生错误。
D.也可以使用加权平均的方法来找一个合适的参数:
volTh=(volMax-volMin)*epdPrm.volRatio+volMin;
volTh=(volMax-volMin)*epdPrm.volRatio+volMin;
where epdPrm.volRatio is 0.1, and volMin and volMax are 3% and 97% percentiles of the volumes in an utterance, respectively.
前面几种方法的具体代码略过。 可以参考:
http://mirlab.org/jang/books/audiosignalprocessing/example/epdByVolTh01.m
若是声音很干净,噪音不大,那么使用音量来侦测端点可得到不错的效果。但是如果碰到下列问题,这个简单的方法就行不通:
1).噪音比较强
2).清音比较多
3).同一句话的音量变化太大
此时单一音量门槛值的选取就比较不容易,端点侦测的正确率也会下降。
另外,对一般端点侦测而言,若希望求得高准确度的端点,我们可以让音框和音框之间的重叠部分加大,但是相对而言,计算量也会跟着变大。
第二种常用的方法,则是用到了音量和过零率
简述如下:
1).以高音量门槛值(tu)为标准,决定端点,作为初始短点(如下图 tu 与能量曲线的交点)。
2).将端点前后延伸到低音量门槛值(tl)处(如下图 N1, N2 点)。
3).再将端点前后延伸到过零率门槛(tzc)处,以包含语音中的清音部分。
此方法用到三个参数(tu、tl、tzc),若电脑计算能力够强,可用各种搜索法来调整这三个参数,否则,就只有靠观察法及经验值。 结合音量/能量(Volume/Energy)和过零率(ZCR)来做端点检测的过程图示:
图中 tl 的范围是完全包含了 tu 的范围。为什么还需要第一步,因为仅仅用第2步的话,噪音的部分会被计算进来,有噪音的时候,tl 的范围中, 会有一部分完全在 tu 的范围之外(跟 tu 没有连接的交集)。所以从 tl 的范围开始扩展、延伸信号的帧长。
端点检测是一个检测SUV 的过程。 声音的每一帧被分为 SUV 三个类别。
回顾一下过零率的定义: 一帧音频信号中,采样值穿过0点的次数。
结合过零率找到 SUV 来做端点检测,基于如下的特征:
浊音 ZCR < 静音 ZCR < 清音 ZCR,SUV 三种帧的过零率排序:Voiced < Silence < Unvoiced
对于清音过零率是最高的。下面的图中可以看到, 标注为 u 的是清音,过零率高,同时信号幅度(能量)小,Singapore Is A Fine Place 这句话中有4段清音。
% 相关类库: http://mirlab.org/jang/books/audiosignalprocessing/example.rar
% 结合过零率的端点检测 epdByVolZcr01.m
waveFile='singaporeIsAFinePlace.wav';
au=myAudioRead(waveFile);
opt=endPointDetect('defaultOpt');
opt.method='volZcr';
showPlot=1;
endPoint=endPointDetect(au, opt, showPlot);代码运行得到下图(图中第二个图的2条红线,分别是使用 tu, tl 识别到的声音范围, 图3中的蓝线的起始点是用 ZCR 检测到的起始点,如图 Start/End 的标记)

第3种方法:结合音量的高阶差分(High Order Difference)
使用基于音量的端点检测,第3种常用的方法,是结合音量和高阶差分(High Order Difference) 来检测, 找到清音(Unvoiced Sound)的部分。
High Order Diffrence: 计算多次差分(diff)。差分就是用后一个信号减去前一个信号的值。
差分的计算方法, 对于 (-1 1 -1 1 -1 1 -1 1) 这一帧信号(这是一帧清音信号)来说,
一阶差分 diff(s) = (2 -2 2 -2 2 -2 2) ,
二阶差分 diff(diff(s)) = (-4 4 -4 4 -4 4)
三阶差分 diff(diff(diff(s))) = (8 -8 8 -8 8)
如下图的计算过程。 通过 Volume + SOD 来识别清音(U)的部分,使用高阶差分,计算出来清音的值很高。这样就能跟静音区分开来。
实现的 matlab 代码如下
% highOrderDiff01.m
waveFile='singaporeIsAFinePlace.wav';
au=myAudioRead(waveFile); y=au.signal; fs=au.fs;
frameSize = 256;
overlap = 128;
y=y-mean(y); % zero-mean substraction
frameMat=buffer2(y, frameSize, overlap); % frame blocking
frameNum=size(frameMat, 2); % no. of frames
volume=frame2volume(frameMat);
sumAbsDiff1=sum(abs(diff(frameMat)));
sumAbsDiff2=sum(abs(diff(diff(frameMat))));
sumAbsDiff3=sum(abs(diff(diff(diff(frameMat)))));
sumAbsDiff4=sum(abs(diff(diff(diff(diff(frameMat))))));
subplot(2,1,1);
time=(1:length(y))/fs;
plot(time, y); ylabel('Amplitude'); title('Waveform');
subplot(2,1,2);
frameTime=frame2sampleIndex(1:frameNum, frameSize, overlap)/fs;
plot(frameTime', [volume; sumAbsDiff1; sumAbsDiff2; sumAbsDiff3; sumAbsDiff4]', '.-');
legend('Volume', 'Order-1 diff', 'Order-2 diff', 'Order-3 diff', 'Order-4 diff');
xlabel('Time (sec)');
显示图如下 (图中红色的清音信号 通过 HOD 被大幅加强,跟静音完全区分开来了)

在上图中,随着我们对 frameMat 的一再差分,清的音量就会越来越明显,因此可用来侦测清音的存在。
一个可能的组合计算音量 volume 和 HOD 来做端点检测的方法如下:
1).计算音量 (VOL)和 n阶差分(HOD) 的绝对值和。
2).在 [0, 1] 内选择一个加权因子 w 以计算新曲线 VH = w*VOL + (1-w)*HOD。
3).找到一个比率 r 来计算 VH 的阈值 t 以确定端点。 阈值等于 VHmin+(VHmax-VHmin)*r。
上述方法涉及三个待确定的参数:n、w、r。 这些参数的典型值为 n = 1、w = 0.76 和 r = 0.012。 但是,这些值因数据集而异。 始终建议使用目标数据集来调整这些值以获得更稳健的结果。
使用音量和 HOD 的更完整的 EPD 检测版本是 SAP 工具箱中的 epdByVolHod.m。
http://mirlab.org/jang/matlab/toolbox/sap.zip
epdByVolHod.m 使用音量和 HOD 来进行端点侦测,参考下例。
% epdByVolHod.m
waveFile='singaporeIsAFinePlace.wav';
au=myAudioRead(waveFile);
opt=endPointDetect('defaultOpt');
opt.method='volHod';
showPlot=1;
endPoint=endPointDetect(au, opt, showPlot);检测出来的声音起点,终点:
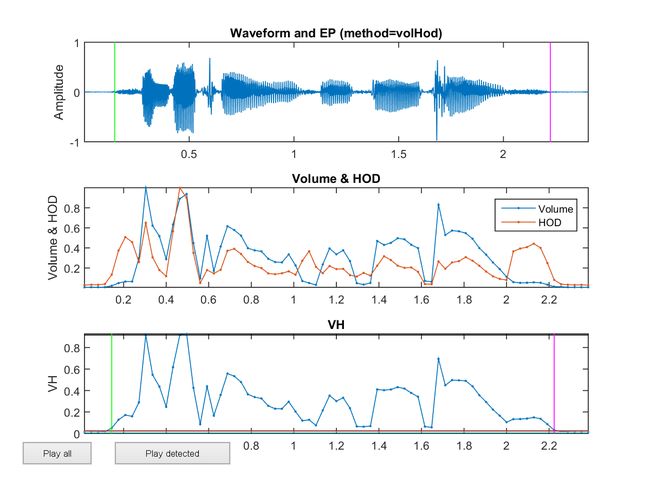
当有噪音的时候, HOD 也不管用了。 噪音的 HOD 也很高,跟清音区分不开来。这个时候需要用到频域的信号分析。
二、基于频域(Frequency Domain) 的 EPD 检测
为什么要使用基于频域做 EPD 检测。 因为以下几个原因:
1.如上面的计算和验证过程, 使用时域的信号,不能有效地处理各种情况,特别是噪音的场景。
2.声音在频域里面,特征更加明显。
3.人耳实际上是一个频谱分析仪,对于频域信号的感知强烈。
有声的语音信号在频谱上会有重复的谐波结构(harmonic structures),因此我们也可以使用频谱的 Variance 或是 Entropy 来进行端点侦测。此外,能量分布将主要偏向低频段。 因此,我们可以在 EPD 的光谱上应用简单的数学函数。 对于能量的含义,参考前面的分享文章。
什么是频谱图: 以时间为横轴, 频率为纵轴,同时用不能颜色标记能量值的语音信号图。 如下图示例,颜色中,红色表示高能量的部分,蓝色是低能量的部分。
FFT 变换之后,可以显示频谱图。
对于清音,高频的能量高于低频的能量。 基于这个特性可以区分出清音的部分。
频谱的展示
% epdShowSpec01.m
waveFile='SingaporeIsAFinePlace.wav';
au=myAudioRead(waveFile);
time=(1:length(au.signal))/au.fs;
subplot(211);
plot(time, au.signal); axis([min(time), max(time), -1, 1]);
ylabel('Amplitude'); title(waveFile);
subplot(212);
frameSize=256;
overlap=frameSize/2;
[S,F,T]=spectrogram(au.signal, frameSize, overlap, 4*frameSize, au.fs);
magSpec=abs(S);
specgram=log(magSpec);
imagesc(T, F, specgram); axis xy
xlabel('Time (sec)'); ylabel('Freq (Hz)');
audioPlayButton(au);
colormap jet;幅度图和频谱图 展示图如下 ,

图中3段清音的部分, 如下图左图的标记, 对于清音部分高频的能量远高于低频区域的能量。
以下是对于有背景噪音的一段音频的分析
% epdShowSpec02.m
waveFile='noisy4epd.wav';
au=myAudioRead(waveFile);
time=(1:length(au.signal))/au.fs;
subplot(211);
plot(time, au.signal); axis([min(time), max(time), -1, 1]);
ylabel('Amplitude'); title(waveFile);
subplot(212);
frameSize=256;
overlap=frameSize/2;
[S,F,T]=spectrogram(au.signal, frameSize, overlap, 4*frameSize, au.fs);
magSpec=abs(S);
specgram=log(magSpec);
imagesc(T, F, specgram); axis xy
xlabel('Time (sec)'); ylabel('Freq (Hz)');
audioPlayButton(au);
colormap jet;包含噪音语音的幅度图、频谱图,展示如下
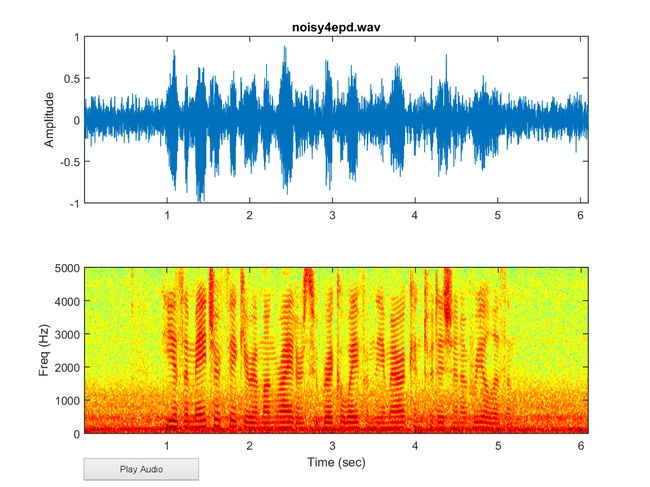
图中因为有噪音, 看得到在低频的部分,始终有能量。 因此需要找到更好的特征来区分噪音的部分。
如何聚合频谱,得到一个单一的特征,使得频谱的能量分布分散时值更大?可以使用如下两种方法:
1). 熵函数
2). 几何平均/算术平均

熵函数的定义 (下图中的 p 是在 i 点的概率分布,总共 n 个点,整体的熵函数如下)

一帧频谱的熵值计算
图中 s(fi) 表示 i 点的频率上的信号值。p 是一个概率分布。同时为了更好的效果,做一个规范化,对于 fi < 250 Hz, fi > 6000 Hz 的情况,都把 s(fi) 当做 0 处理。 同时当 pi 过大或者过小时也当做0 来处理。
 对于语音的每一帧,做熵值的计算,计算出来的值会呈现如下的规律:
对于语音的每一帧,做熵值的计算,计算出来的值会呈现如下的规律:
清音的熵值大(可以理解成混乱度高,熵值越大有序性阅读),静音、浊音的分散度小。
原因是因为清音的频率能量分散度大,P 的分散大,而静音,浊音的分散度小。(参考前面的图)
几何平均与算术平均的计算:

熵值,几何均值/算法均值,都可以用来衡量多样化,从而可以用来区分清音和浊音/静音。