Towards Robust Visual Question Answering: Making the Most of BiasedSamples via Contrastive Learning
走向鲁棒的视觉问题回答: 通过对比学习,最大限度地利用有偏样本
提出问题:
视觉问答(VQA)模型通常依赖于虚假的相关性,即语言先验。使得其在分布外(OOD)测试数据面前表现不好。最近的方法通过减少偏倚样本对模型训练的影响,在克服这个问题方面取得了一些进展。但是,其在分布外(OOD)测试数据的改进严重牺牲了分布(ID)数据(由偏置样本主导)上的性能。
解决方法和创新点:
提出了一种新颖的对比学习方法,MMBS。它通过充分利用有偏样本来构建鲁棒的VQA模型。
具体来说,通过从原始训练样本中消除与语言先验相关的信息来构建用于对比学习的正样本,并探索出了几种策略来使用构建的正样本进行训练。这种方法没有破坏有偏样本在模型训练中的重要性,而是精确地利用有偏样本获得了有助于推理的无偏信息。
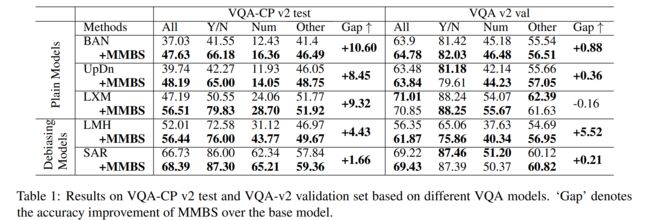
在分布外(OOD)测试数据集VQA- CP v2上的性能很有竞争力,同时在分布(ID)数据集VQA v2上保持了稳定的性能。
方法:

其中,问题类别词用黄色高亮显示。橙色圆圈和蓝色三角形表示原始样本和正样本的跨模态表示。同批次的其他样本为负样本,用灰色圆圈表示。
MMBS模型构造:(1)一个骨干VQA模型;
(2)一个正样本构建模块;
(3)一个无偏样本选择模块;
(4)对比学习目标。
1.骨干VQA模型
骨干VQA模型在MMBS中可以自由选择。大多数现有的VQA模型由四个部分组成:问题编码器eq(·)、图像编码器ev(·)、融合函数F(·)和分类器clf(·)。
训练目标:最小化多标签软损失Lvqa,可以形式化如下:

2.正样本构造
为了充分利用有偏样本中所包含的无偏信息,首先要构建排除有偏信息的正样本。
本文通过破坏每个输入问题(Qi)的问题类别信息来构建两种正问题(Q+i):
(1)洗牌:随机洗牌问题句中的单词,使问题类别单词与其他单词混合在一起。
这增加了建立问题类别和答案之间的相关性的难度。
(2)删除:从问题句中删除问题类型词。它完全消除了答案和问题类型词的共同出现。
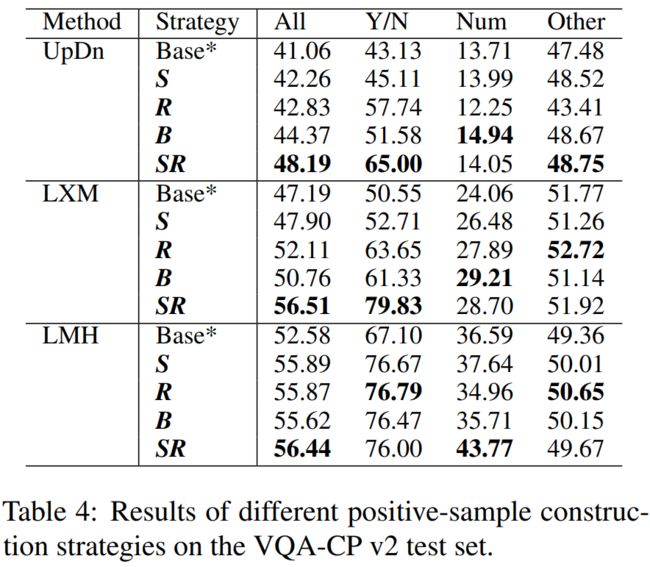
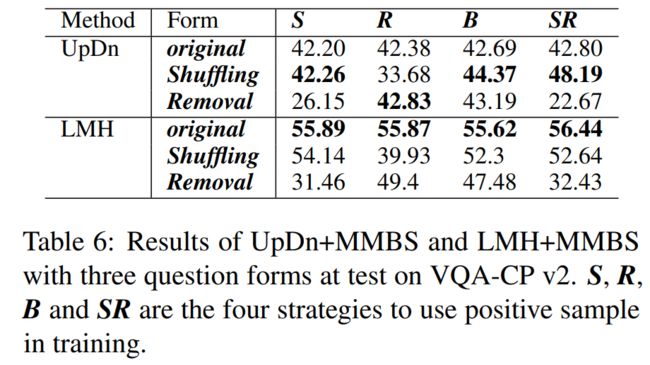
· 还提出了在训练中建构正问题的四种策略:
S:使用洗牌。
R:使用移除。
B:两个都用。
SR: 对于非yesno(如“Num”和“Other”)问题使用洗牌,对于yesno(如“Y/N”)问题使用移除。
采用上述任何一种策略,我们都可以得到输入样本 的正样本
的正样本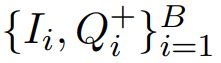 。负样本
。负样本 ,其中
,其中![]() ,是同批次的其他样本。B是训练的批量大小。
,是同批次的其他样本。B是训练的批量大小。
3.无偏样本选择
本文将无偏样本(或OOD)定义为训练集中每个问题类别的答案分布中的不频繁样本。
为了过滤出无偏样本,本文提出了一种新颖的算法,包括三个步骤:(i)计算答案频率;(ii)确定无偏答案比例;(iii)选择无偏样本。
答案频率:

其中,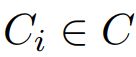 ,为第i个样本的问题类别;
,为第i个样本的问题类别;![]() 为 ground truth answer ;
为 ground truth answer ; 为软目标分数;
为软目标分数; 为类别为
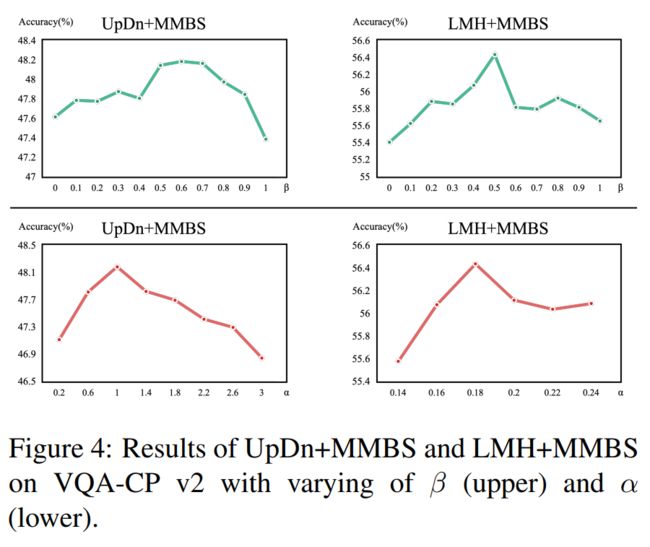
为类别为 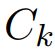 的所有样本的个数;引入一个超参数
的所有样本的个数;引入一个超参数 来控制无偏样本的比例。 如果一个样本有一个多标签答案
来控制无偏样本的比例。 如果一个样本有一个多标签答案 ,分别计算每个答案的得分。
,分别计算每个答案的得分。
基于熵的修正因子:
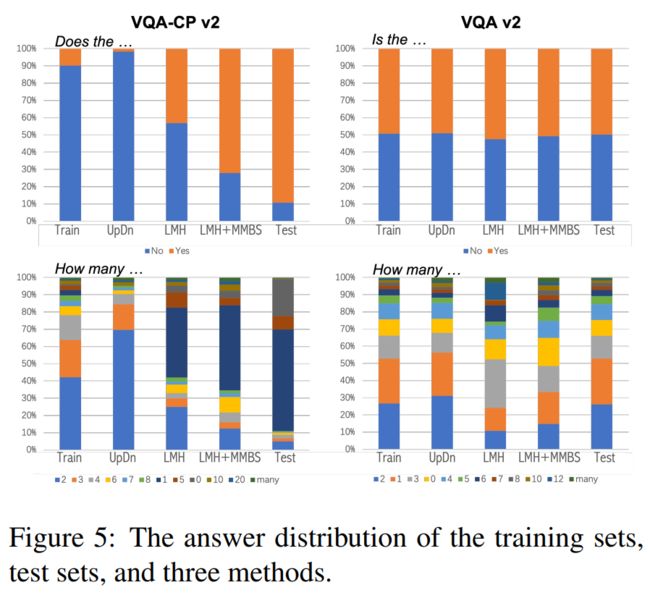
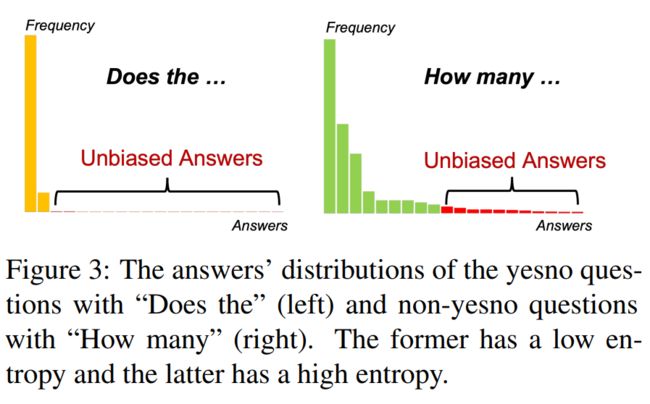
 问题类别的答案分布不同。从经验上看,当一个答案分布的熵较低时,更多的答案会与较少的样本相关联,因此无偏答案的比例应该较高,反之则相反。如图所示:
问题类别的答案分布不同。从经验上看,当一个答案分布的熵较低时,更多的答案会与较少的样本相关联,因此无偏答案的比例应该较高,反之则相反。如图所示:
因此,本文提出了一个基于熵的校正因子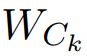 来动态调整每个类别
来动态调整每个类别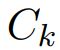 的β:
的β:
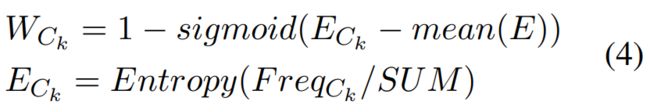
其中E代表 ,SUM表示
,SUM表示 的和 。熵较低时,
的和 。熵较低时, 更接近1,否则
更接近1,否则 更接近0。最后,我们得到无偏的答案比例
更接近0。最后,我们得到无偏的答案比例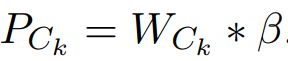 。
。
选取无偏样本:
对于每个问题类别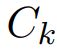 ,我们得到一个在
,我们得到一个在 中排名最末的
中排名最末的 的无偏答案列表。然后我们确定其真实答案(得分最高)属于此列表的样本为无偏样本。如果一个样本是有偏的,我们采用上一节提到的策略来构建其正样本。如果它是无偏的,我们使用原始样本作为它的正样本。
的无偏答案列表。然后我们确定其真实答案(得分最高)属于此列表的样本为无偏样本。如果一个样本是有偏的,我们采用上一节提到的策略来构建其正样本。如果它是无偏的,我们使用原始样本作为它的正样本。
4.对比学习目标
本文使用余弦相似度cos(·)作为评分函数。对比损失表示为:

其中,输入样本 、正样本
、正样本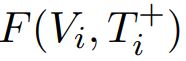 和负样本
和负样本 的跨模态融合分别表示为a,正 p 和负
的跨模态融合分别表示为a,正 p 和负 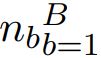 。
。
通过最小化它,模型可以专注于来自积极问题(positive question)的无偏信息。MMBS的总体损失表述为:L =  ,其中α为
,其中α为 的权重。
的权重。
实验结果: