MyDLNote-Transformer : Pyramid Vision Transformer 一个无卷积的密集预测通用Backbone
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions

- paper https://arxiv.org/pdf/2102.12122.pdf
- Code is available at https://github.com/whai362/PVT
- Note: Improved Pyramid Vision Transformer, PVTv2: Improved Baselines with Pyramid Vision Transformer, can be found Here.
目录
Abstract
Introduction
Method
Applied to Downstream Tasks
Experiments

Abstract
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer (PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks.
PVT has several merits compared to prior arts.
(1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense prediction, but also using a progressive shrinking pyramid to reduce computations of large feature maps.
(2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones.
(3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g. object detection, semantic and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches.
1. 动机和核心研究内容:
虽然使用卷积神经网络 (CNNs) 作为 backbones 在计算机视觉中取得了巨大的成功,但这项工作研究了一个简单的 backbones 网络,用于许多没有卷积的密集预测任务。与最近提出的专门用于图像分类的 Transformer 模型 (例如,ViT) 不同,本文提出了 Pyramid Vision Transformer (PVT),它克服了将 Transformer 移植到各种密集预测任务中的困难。
2. PVT介绍:
(1)PVT 不仅可以对图像的密集分区进行训练以获得高输出分辨率(这对密集预测很重要),还可以使用渐进收缩金字塔来减少大型特征图的计算量。
(2)PVT 继承了 CNN 和 Transformer 的优点,通过简单地替换 CNN backbones,使其在各种视觉任务中成为统一的 backbones,无需卷积。
(3)通过大量的实验验证了 PVT 算法的有效性,结果表明,该算法提高了许多下游任务的性能,如目标检测、语义和实例分割。
Introduction
Introduction 的逻辑:作者开门见山,直接告诉本文要实现的目标是什么(第一段)。接着,告诉读者实现这个目标采用的基本工具是什么(第二段)。但直接使用这个工具存在什么问题(第三段)。于是乎,作者介绍了本文解决这些问题的方法(第四段)。最后,作者综述了本文方法的优点(第五段)。
Convolution Neural Network (CNN) achieves remarkable successes in computer vision, and becomes a versatile and dominating method in almost all tasks of computer vision. Nevertheless, this work is trying to explore new versatile backbone network without convolutions. We investigate an alternative model beyond CNN for the tasks of dense predictions such as object detection, semantic and instance segmentation, other than image classification.
第一段,本文的核心研究范畴:这项工作尝试探索新的无卷积的多功能 backbone 网络。本文研究了一个超越 CNN 的替代模型,用于密集预测任务,如目标检测,语义和实例分割,而不是图像分类。
Inspired by the success of Transformer [51] in natural language processing (NLP), many researchers are trying to explore applications of Transformer in computer vision. For example, some works model the vision task as a dictionary lookup problem with learnable queries, and use the Transformer decoder as a task-specific head on the top of the CNN backbone, such as VGG [41] and ResNet [15]. While some prior arts have incorporated the attention modules [53, 35, 61] into CNNs, as far as we know, exploring a clean and convolution-free Transformer backbone to address dense prediction tasks in computer vision is rarely studied.
第二段,采用的基本工具,即 Transformer,来实现第一段提出的研究范畴和目标;同时本文的独到性,即探索一个无卷积的 Transformer 主干来解决计算机视觉中的密集预测任务很少被研究。

Recently, Dosovitskiy et al. [10] employs Transformer for image classification. This is an interesting and meaningful attempt to replace the CNN backbone by a convolutionfree model. As shown in Figure 1 (b), ViT has a columnar structure with coarse image patches (i.e., dividing image with a large patch size) as input1 . Although ViT is applicable to image classification, it is challenging to be directly adapted to pixel-level dense predictions, e.g., object detection and segmentation, because (1) its output feature map has only a single scale with low resolution and (2) its computations and memory cost are relatively high even for common input image size (e.g., shorter edge of 800 pixels in COCO detection benchmark).
第三段,本文研究的难点和意义:直接用 ViT 适应像素级密集预测具有挑战性,表现在 (1)其输出地形图只有单一的比例尺,分辨率较低;(2)计算和存储成本相对较高。
To compensate the above limitations, this work proposes a convolution-free backbone network using Transformer model, termed Pyramid Vision Transformer (PVT), which can serve as a versatile backbone in many downstream tasks, including image-level prediction as well as pixel-level dense predictions. Specifically, as illustrated in Figure 1 (c), different from ViT, PVT overcomes the difficulties of conventional Transformer by (1) taking fine-grained image patches (i.e., 4 × 4 per patch) as input to learn high-resolution representation, which is essential for dense prediction tasks, (2) introducing a progressive shrinking pyramid to reduce the sequence length of Transformer when the depth of network is increased, significantly reducing the computational consumption, and (3) adopting a spatial-reduction attention (SRA) layer to further reduce the resource cost to learn high-resolution feature maps.
第四段,本文提出的方法: Pyramid Vision Transformer (PVT),包括三个技术:
(1)以细粒度图像 patch (即每个 patch 4 × 4) 作为输入,学习高分辨率表示,这对于密集预测任务来说是必不可少的;
(2)当网络深度增加时,引入一个渐进收缩的金字塔来减少 Transformer 的序列长度,显著降低了计算消耗;
(3)采用 SRA (spatial-reduction attention) 层,进一步降低学习高分辨率地物图的资源成本。
Overall, the proposed PVT possesses the following merits. Firstly, compared to the conventional CNN backbones (see Figure 1 (a)) where the receptive field increases when the depth increases, PVT always produces a global receptive field (by attentions among all small patches), which is more suitable for detection and segmentation than CNNs’ local receptive field. Secondly, compared to ViT (see Figure 1 (b)), due to the advance of the pyramid structure, our method is easier to be plugged into many representative dense prediction pipelines, e.g., RetinaNet [27] and Mask R-CNN. Thirdly, with PVT, we can build a convolutionfree pipeline by combining PVT with other Transformer decoders designed for different tasks, such as PVT+DETR [4] for object detection. For example, to the best of our knowledge, our experiments present the first end-to-end object detection pipeline, PVT+DETR, which is entirely convolution-free. It achieves 34.7 on the COCO val2017, outperforming the original DETR based on ResNet50.
第五段,本文方法的特点:
(1)与 CNN 相比,PVT 总是产生一个全局的感受野 (通过对所有小 patches 的关注),比 CNN 的局部感受场更适合于检测和分割;
(2)与 ViT 相比,由于金字塔结构的改进,本文的方法更容易插入到许多具有代表性的密集预测pipeline 中,如 RetinaNet 和 Mask R-CNN;
(3)可以通过将 PVT 与其他针对不同任务设计的 Transformer 解码器 (如用于目标检测的 PVT+DETR) 相结合来构建一个无卷积的 pipeline。例如,实验展示了第一个端到端对象检测pipeline,PVT+DETR,这是完全无卷积的。
Method
Overall Architecture
Our goal is to introduce the pyramid structure into Transformer, so that it can generate multi-scale feature maps for dense prediction tasks (e.g., object detection and semantic segmentation). An overview of PVT is depicted in Figure 3. Similar to CNN backbones [15], our method has four stages that generate feature maps of different scales. All stages share a similar architecture, which consists of a patch embedding layer and
Transformer encoder layers.
本文的目标是在 Transformer 中引入金字塔结构,使其能够为密集的预测任务 (例如,目标检测和语义分割)生成多尺度特征映射。图 3 描述了 PVT 的概述。与 CNN backbones 相似,本文的方法分为四个阶段,生成不同尺度的特征图。所有阶段都有一个相似的体系结构,包括一个 patch embedding 层和 Transformer 编码器层。

In the first stage, given an input image with the size of H ×W ×3, we first divide it into HW/4^2 patches (same as ResNet, we keep the highest resolution of our output feature map at 4-stride), and the size of each patch is 4×4×3. Then, we feed the flattened patches to a linear projection and get embedded patches with size of HW/4^2 ×C_1. After that, the embedded patches along with position embedding pass through a Transformer encoder with L_1 layer, and the output is reshaped to a feature map F_1, and its size is H/4 × W/4 × C_1. In the same way, using the feature map from the prior stage as input, we obtain the following feature maps F_2, F_3, and F_4, whose strides are 8, 16, and 32 pixels with respect to the input image. With the feature pyramid {F_1, F_2, F_3, F_4}, our method can be easily applied to most downstream tasks, including image classification, object detection, and semantic segmentation.
在第一阶段,给定一幅大小为 H × W ×3 的输入图像,我们首先将其划分为 HW/4^2 patches(与ResNet 相同,本文的输出 feature map 的最高分辨率为 4 stride),每个 patch 的大小为 4×4×3。然后,本文将平坦的 patches 注入到一个线性投影中,得到大小为 HW/4^2 C_1 的 patches embedding。然后,将 embedded patch 连同 position embedding 一起经过 L_1 层的 Transformer编码器,输出被重塑为 feature map F_1,其大小为 H/4 × W/4 × C_1。同样,使用前一阶段的特征映射作为输入,得到以下特征映射 F_2、F_3 和 F_4,它们相对于输入图像的 stride 分别为8, 16, 32 像素。通过特征金字塔 {F_1, F_2, F_3, F_4},本文的方法可以很容易地应用于大多数下游任务,包括图像分类,目标检测和语义分割。
总之,就是将每层都做 ViT,且每层都做预测输出。
Feature Pyramid for Transformer
Unlike CNN backbone networks [15] that use convolution stride to obtain multi-scale feature maps, our PVT use progressive shrinking strategy to control the scale of feature maps by patch embedding layers.
Here, we denote the patch size of the i-th stage as P_i . At the beginning of the stage i, we first evenly divide the input feature map
into
patches, and then each patch is flatten and projected to a C_i-dim embedding. After the linear projection, the shape of the embedded patches can be viewed as
, where the height and width are P_i times smaller than the input.
In this way, we can flexibly adjust the scale of the feature map in each stage, making it possible to construct a feature pyramid for Transformer.
本小节,主要介绍 金字塔模型中,embedding 的提取及其意义。
与 CNN backbone 网络使用卷积 stride 获得多尺度特征图不同,PVT 使用渐进收缩策略,通过 patch embedding layers 来控制 feature maps 的尺度。
这里,将第 i 阶段的 patch size 表示为 P_i。在第 i 阶段的开始,首先将输入特征映射 ![]() 均匀划分为
均匀划分为 ![]() patch,然后将每个 patch flatten 并投影到 C_i-dim embedding 中。线性投影后,embedded patches 的形状可以看作
patch,然后将每个 patch flatten 并投影到 C_i-dim embedding 中。线性投影后,embedded patches 的形状可以看作 ![]() ,其中高和宽比输入小,是输入的 P_i 倍。
,其中高和宽比输入小,是输入的 P_i 倍。
这样就可以灵活地调整 feature map 在各个阶段的比例尺,为 Transformer 构建 feature pyramid 提供了可能。
Transformer Encoder
For the Transformer encoder in the stage i, it has Li encoder layers, and each encoder layer is composed of an attention layer and a feed-forward layer [51]. Since our method needs to process high-resolution (e.g., 4-stride) feature maps, we propose a spatial-reduction attention (SRA) layer to replace the traditional multi-head attention (MHA) layer [51] in the encoder.
对于第 i 阶段的 Transformer 编码器,
1. 有 L_i 编码器层;
2. 每个编码器层由注意层和前馈层组成;
3. 由于需要处理高分辨率 (例如,4-stride) 特征图,本文提出了一个 SRA 层来取代传统的多头注意(MHA) 层。

Similar to MHA, our SRA also receives a query Q, a key K, and a value V as input, and outputs a refined feature. The difference is that our SRA will reduce the spatial scale of K and V before the attention operation as shown in Figure 4, which largely reduces the computation/memory overhead.
Details of SRA in the stage i can be formulated as follows:
where
, and
are parameters of linear projections. N_i is the head number of the Transformer encoder in the stage i. Therefore, the dimension of each head dhead is equal to
. SR(·) is the spatial-reduction operation, which is defined as:
Here, R_i denotes the reduction ratio of the attention layers in the stage i. Reshape(x, Ri) is the operation of reshaping the input
to the sequence with the size of
is a linear projection that reduces the dimension of input sequence to C_i . Norm(·) refers to layer normalization [1]. Same as Transformer [51], Attention(·) is the attention operation that is calculated as:
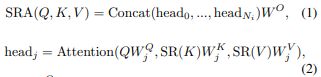
与 MHA 类似,SRA 也接收一个查询 Q、一个键 K 和一个值 V 作为输入,并输出一个细化的特性。不同的是,SRA 在进行如图 4 所示的注意操作之前,会缩小 K 和 V 的空间规模,这大大降低了计算/内存开销。第一阶段 SRA 的具体情况如公式(1)和(2)。
公式(1)表示每个 head 的输出 concat 起来,然后经过一个线性变换进行融合。
公式(2)表示输入的 Q,K,V 中,K 和 V 需要先经过 SR 操作(定义为公式(3)进行空间规模缩小,后面解释),然后 Q 和新的 K,V 再做基本的 self-attention 操作,公式(4)所示。
公式(3)表示输入的 embedding 首先经过 Reshape 操作,这个操作的目的是缩小输入的空间规模。缩小比例 R_i;缩小后再经过线性变换将维度进行缩小。最后,在经过 layer normalization 层。
公式(4)就是传统的 self-attention 操作了。
本文的 Attention(·) 运算的计算/存储成本是 MHA 的 R_i^2 倍,因此它可以在有限的资源下处理更大的输入特征映射/序列。
Model Details

Applied to Downstream Tasks
mage-Level Prediction
Image classification is the most representative task of image-level prediction. Following ViT [10] and DeiT [50], we append a learnable classification token to the input of the last stage, and then use a fully connected layer to make classification on the top of the classification token.
图像分类是图像级预测中最具代表性的任务。在 ViT 和 DeiT 之后,本文在最后一个阶段的输入中添加一个可学习的分类 token,然后使用一个完全连接的层在分类 token 的顶部进行分类。
Pixel-Level Dense Prediction
- Object Detection
We apply our PVT models to two representative object detection methods, namely RetinaNet [27] and Mask R-CNN [14]. RetinaNet is a widelyused single-stage detector, and Mask R-CNN is one of the mainstream two-stage instance segmentation frameworks. The implementation details are listed as follows:
(1) Same as ResNet, we directly use the output feature pyramid {F1, F2, F3, F4} as the input of FPN [26], and then the refined feature maps are fed to the follow-up detection or in stance segmentation head.
(2) In object detection, the input can be an arbitrary shape, so the position embeddings pretrained on ImageNet may no longer be meaningful. Therefore, we perform bilinear interpolation on the pre-trained position embeddings according to the input image.
(3) During the training of the detection model, all layers in PVT will not be frozen.
本文将 PVT 模型应用于两种具有代表性的目标检测方法,即 RetinaNet[27] 和 Mask R-CNN[14]。RetinaNet 是一种广泛使用的单阶段检测器,而 Mask R-CNN 是主流的两阶段实例分割框架之一。实现细节如下:
(1) 与 ResNet 一样,本文直接使用输出特征金字塔 {F1, F2, F3, F4} 作为 FPN[26] 的输入,然后将精炼后的特征映射反馈到后续检测或姿态分割 head 中。
(2) 在目标检测中,输入可以是任意形状,因此在 ImageNet 上预训练的位置嵌入可能不再有意义。因此,根据输入图像对预处理后的 position embeddings 进行双线性插值。
(3) 在检测模型的训练过程中,PVT 中的所有层都不会被冻结。
- Semantic Segmentation
We choose Semantic FPN [21] as the baseline, which is a simple segmentation method without special operations (e.g., dilated convolution). Therefore, using it as the baseline can well examine the original effectiveness of backbones. Similar to the implementation in target detection, we feed the feature pyramid directly to the semantic FPN, and use bilinear interpolation to resize the pre-trained position embedding.
本文选择语义 FPN[21] 作为 baseline,这是一种简单的分割方法,不需要特殊的操作 (如扩张卷积)。因此,使用它作为 baseline 可以很好地检查 backbones 的原始有效性。与目标检测的实现类似,本文将特征金字塔直接输入语义 FPN,并使用双线性插值调整预先训练的 position embedding 的大小。
Experiments
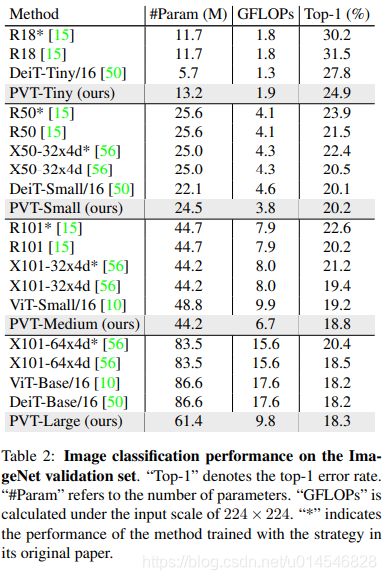
- Image Classification
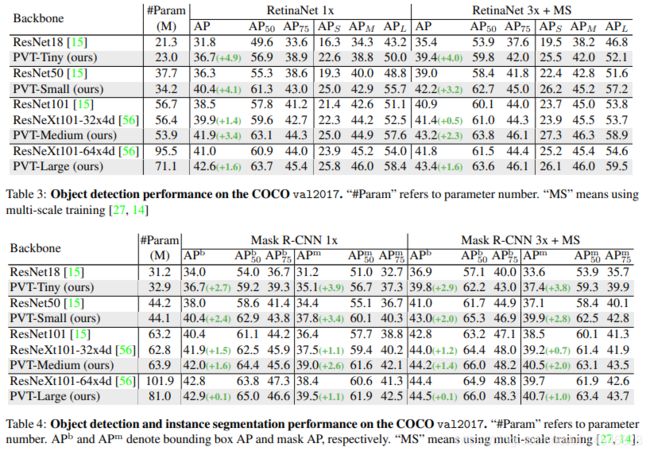
- Object Detection
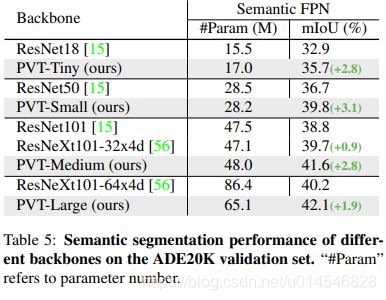
- Semantic Segmentation
我的 Conclusions:
感觉 PTV 整体算法还是比较简单的,一是每层都用 ViT;二是 Transformer 的输入做空间缩小。这两点都很简单。
本文可能更吸引的地方在于立意新,实验好。