PyTorch - Auto Encoder及其实战
目录
- AutoEncoder
-
- 经典AutoEncoder
-
- Loss Function的选择
- Denoising AutoEncoder
- Variational AutoEncoder
-
- Reparameterization Trick
- 实战部分
-
- AutoEncoder
-
- 网络的构建
- 数据集加载、训练和结果显示
-
- 导入包
- 数据集加载
- 训练以及结果显示
- 结果
- Variational AutoEncoder
-
- 网络的搭建
-
- 设置网络(\__init__())
- forward()
- 数据集加载、训练和结果显示
-
- 数据集加载
- 训练以及结果显示
- 结果
AutoEncoder
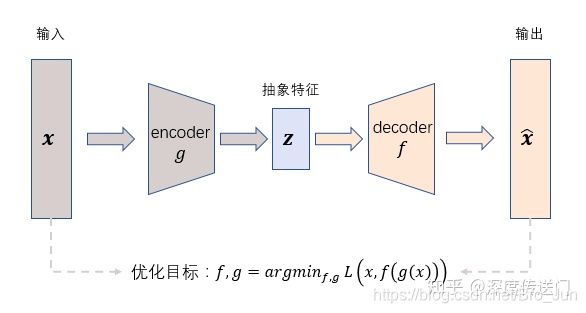
经典AutoEncoder
- 无监督学习
- 高维数据
- 进行高效的特征提取和特征表示
- 通过 encoder(g) 将输入样本x映射到特征空间 z,即编码过程
- 然后再通过 decoder(f) 将抽象特征 z 映射回原始空间得到重构样本x’,即解码过程
- 优化目标则是通过最小化重构误差来同时优化encoder和decoder,从而学习得到针对样本输入x的抽象特征表示z
Loss Function的选择

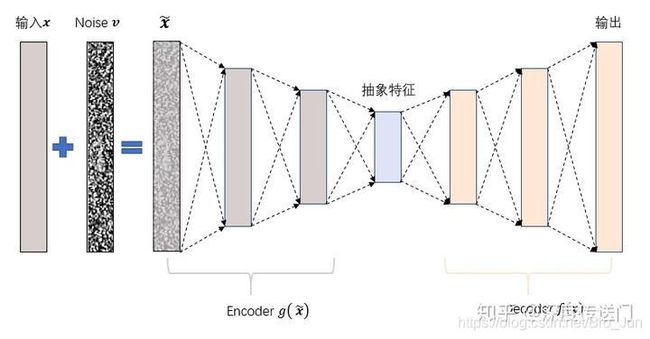
Denoising AutoEncoder
为了缓解经典AutoEncoder容易过拟合的问题,一个办法是在输入中加入随机噪声
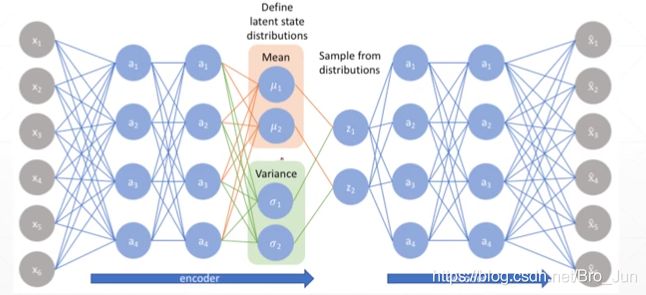
Variational AutoEncoder

Reparameterization Trick
由于Sample()是不可导的,所以为了训练我们将其变换成如下形式:

整个VAE神经网络如下所示:
实战部分
对MNIST数据集进行无监督学习AutoEncoder
AutoEncoder
网络的构建
思路:将图片打平,然后放到对称的全连接网络中,最后一个激活函数应为Sigmoid。
from torch import nn
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# [b, 784] => [b, 20]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b, 20] => [b ,784]
self.decoder = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x
数据集加载、训练和结果显示
导入包
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch import nn, optim
from ae import AE
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
数据集加载
- 先加载datasets中现成的数据集类
- 再用DataLoader加载
def main():
mnist_train = datasets.MNIST("mnist", True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST("mnist", False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True)
训练以及结果显示
# unsupervised learning => 不需要 label
x, _ = iter(mnist_train).next()
device = torch.device('cuda')
model = AE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
# 循环一次训练集,进行训练
for batchidx, (x, _) in enumerate(mnist_train):
x = x.to(device)
x_hat = model(x)
loss = criteon(x_hat, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss: ', loss.item())
# test
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
x_hat = model(x)
# 显示这一个epoch的结果
plt.figure()
for j in range(2):
for i in range(4):
if j == 0:
x_temp = x.cpu()
x_tmp = x_temp.numpy()
x_tmp = x_tmp[i, 0]
plt.subplot(2, 4, i+1)
plt.imshow(x_tmp)
if j == 1:
x_temp = x_hat.cpu()
x_tmp = x_temp.numpy()
x_tmp = x_tmp[i, 0]
plt.subplot(2, 4, i + 5)
plt.imshow(x_tmp)
plt.show()
if __name__ == '__main__':
main()
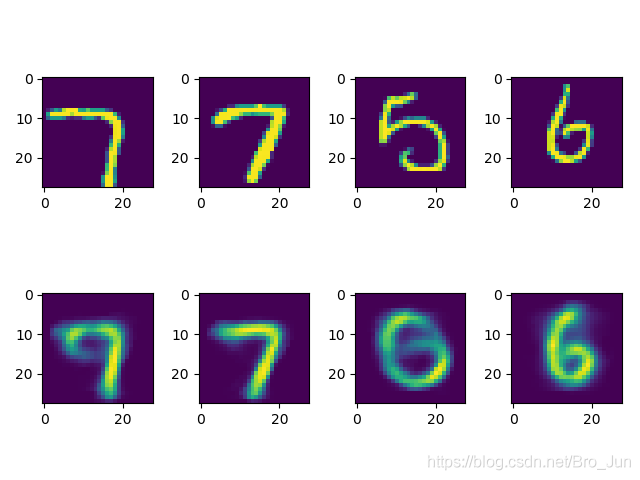
结果
对于MNIST数据集效果较好


Variational AutoEncoder
网络的搭建
设置网络(_init_())
这部分与AE只是在decoder部分的输入维度有所区别
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] => [b, 20]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# 向正态分布靠近
# u: [b, 10]
# sigma: [b, 10]
# [b, 10] => [b ,784]
self.decoder = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
forward()
在forward部分中要将正态化的过程表现出来以及将KL散度计算出来
文章《VAE模型》的最后给出了KL散度的公式
torch.chunk(input, num, dim=) 用法
注意:KL散度的计算中,要平均到每一个像素点上,否则在尺度上会与reconstruction的loss不平衡!
def forward(self, x):
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
h_ = self.encoder(x)
# [b, 20] => [b, 10] and [b, 10]
mu, sigma = h_.chunk(2, dim=1)
# reparameterization trick
h = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(h)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# KL Divergence (平均到每一个像素点)
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz * 28 * 28)
return x_hat, kld
数据集加载、训练和结果显示
数据集加载
与上一个代码没有区别
def main():
mnist_train = datasets.MNIST("mnist", True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST("mnist", False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True)
训练以及结果显示
与上边相比唯一变化是loss要加上KL散度
# unsupervised learning => 不需要 label
x, _ = iter(mnist_train).next()
print('x: ', x.shape)
device = torch.device('cuda')
model = VAE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
for batchidx, (x, _) in enumerate(mnist_train):
x = x.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
# loss是reconstruction部分加上KL散度
if kld is not None:
elbo = loss + 1.0 * kld
loss = elbo
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss: ', loss.item(), 'kld: ', kld.item())
# test
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
x_hat, kld_ = model(x)
plt.figure()
for j in range(2):
for i in range(4):
if j == 0:
x_temp = x.cpu()
x_tmp = x_temp.numpy()
x_tmp = x_tmp[i, 0]
plt.subplot(2, 4, i+1)
plt.imshow(x_tmp)
if j == 1:
x_temp = x_hat.cpu()
x_tmp = x_temp.numpy()
x_tmp = x_tmp[i, 0]
plt.subplot(2, 4, i + 5)
plt.imshow(x_tmp)
plt.show()
if __name__ == '__main__':
main()
结果
训练前期的效果不如AutoEncoder