【基于时间特征交互和引导细化的遥感变化检测 】2022TGRS
变化检测TGRS2022《Remote Sensing Change Detection via Temporal Feature Interaction and Guided Refinement》
ABSTRACT
遥感变化检测(RSCD)从注册的一对遥感图像中识别变化和不变的像素,最近取得了显著的成功。然而,在RSCD中,定位具有精细结构细节的变化对象仍然是一个具有挑战性的问题。在本文中,我们提出了一种新的基于时间特征交互和引导求精的RSCD网络(TFI-GR)来解决这个问题。具体来说,与以往的方法不同,这些方法只使用一个单一的级联或减法操作来进行双时间特征融合,我们设计了一个时间特征交互模块(TFIM)来增强双时间特征之间的交互,并在不同的特征级别捕获时间差异信息。然后,重复执行一个引导细化模块(GRM),该模块聚合低级和高级时间差分表示,以抛光高级特征的位置信息并过滤低级特征的背景杂波。最后,对多层次时间差分特征进行逐步融合,生成用于变化检测的变化图。为了证明所提出的TFIGR的有效性,在三个高空间分辨率RSCD数据集上进行了综合实验。实验结果表明,该方法优于其他最先进的变化检测方法。
网络框架

网络分为三个阶段,分别是特征提取(Conv-1到Res-5),时间融合(TFIM),特征变化推理(GRM)。
从创新上来说,网络分为三个模块。分别是时间特征提取模块(TFIM),引导精炼模块(GRM),变化信息提取模块(CIEM)。其中GRM包含了CIEM。
网络流程
首先双时相图像T1,T2送入到基于resnet18的暹罗网络中进行特征提取,得到4对不同阶段的特征图。之后分别送入TFIM阶段用来关注差异特征。之后送入GRM用来探索补充信息。之后得到不同层次的特征用于特征聚合,从而在浅层到深层的融合过程中生成变化图。
时间特征提取模块(TFIM)
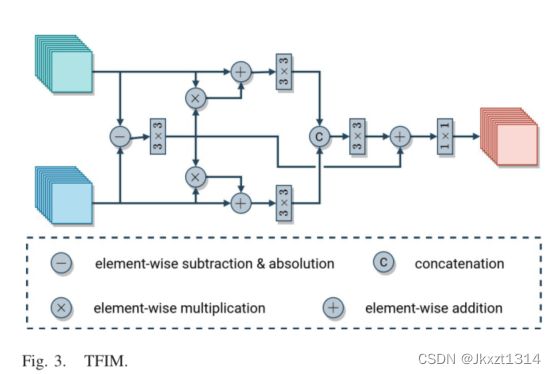
首先将得到的t1和t2时刻的特征图进行做差,得到差异图。之后将差异图送入3x3的卷积,之后分别与T1和T2的特征进行相乘,之后再与T1和T2进行相加,两个分支分别再经过一个3x3卷积,之后进行拼接进行通道变化,之后在与差异特征进行相加。之后经过1x1的卷积来减少通道维度,最后得到输出特征。
引导精炼模块(GRM)
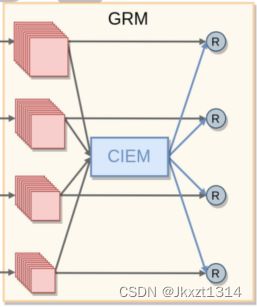
GRM模块主要包含了CIEM和四个网络分支,采用多级输入和输出的方法对特征进行提取。
变化信息提取模块(CIEM)

CIEM模块首先对输入的不同层次的特征图进行上采样,大小相同之后进行特征拼接,之后将拼接后的特征送入通道注意力模块,之后与自身相乘。然后通过3x3的卷积进行特征学习,之后将特征划分为相应层次,并使用自适应平均池化来进行特征复原,之后将不同层次特征与原始特征进行相加,最后将不容层次特征进行融合得到最终的变化图。
损失函数
论文采用BCE和DICE联合损失作为损失函数。
对于变化检测任务,在大多数情况下,变化区域的比率远远小于不变区域的比率,从而导致类不平衡问题。为了缓解这个问题并引导网络从复杂场景中学习,我们采用了一种混合损失,包括二进制交叉熵损失Lbce和骰子损失Ldice。
消融实验

从消融实验中可以看出,两层GRM可以达到最好的效果,过多的GRM模块可能会导致过拟合。
对比实验

可以看出该方法再sysu数据集上达到了较好的效果,其iou为72.40。sysu应该是目前最高的结果。
论文代码 pytorch 网络结构
import torch
import torch.nn as nn
import torch.nn.functional as F
from .resnet import resnet18
class TemporalFeatureInteractionModule(nn.Module):
def __init__(self, in_d, out_d):
super(TemporalFeatureInteractionModule, self).__init__()
self.in_d = in_d
self.out_d = out_d
self.conv_sub = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_diff_enh1 = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_diff_enh2 = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_cat = nn.Sequential(
nn.Conv2d(self.in_d * 2, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_dr = nn.Sequential(
nn.Conv2d(self.in_d, self.out_d, kernel_size=1, bias=True),
nn.BatchNorm2d(self.out_d),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
# difference enhance
x_sub = self.conv_sub(torch.abs(x1 - x2))
x1 = self.conv_diff_enh1(x1.mul(x_sub) + x1)
x2 = self.conv_diff_enh2(x2.mul(x_sub) + x2)
# fusion
x_f = torch.cat([x1, x2], dim=1)
x_f = self.conv_cat(x_f)
x = x_sub + x_f
x = self.conv_dr(x)
return x
if __name__ == "__main__":
x = torch.randn(1, 64, 16, 16)
y = torch.randn(1, 64, 16, 16)
net1 = TemporalFeatureInteractionModule(64)
x1 = net1(x,y)
#print(x1)
print(x1.shape)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class ChangeInformationExtractionModule(nn.Module):
def __init__(self, in_d, out_d):
super(ChangeInformationExtractionModule, self).__init__()
self.in_d = in_d
self.out_d = out_d
self.ca = ChannelAttention(self.in_d * 4, ratio=16)
self.conv_dr = nn.Sequential(
nn.Conv2d(self.in_d * 4, self.in_d, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.pools_sizes = [2, 4, 8]
self.conv_pool1 = nn.Sequential(
nn.AvgPool2d(kernel_size=self.pools_sizes[0], stride=self.pools_sizes[0]),
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1, bias=False)
)
self.conv_pool2 = nn.Sequential(
nn.AvgPool2d(kernel_size=self.pools_sizes[1], stride=self.pools_sizes[1]),
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1, bias=False)
)
self.conv_pool3 = nn.Sequential(
nn.AvgPool2d(kernel_size=self.pools_sizes[2], stride=self.pools_sizes[2]),
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1, bias=False)
)
def forward(self, d5, d4, d3, d2):
# upsampling
d5 = F.interpolate(d5, d2.size()[2:], mode='bilinear', align_corners=True)
d4 = F.interpolate(d4, d2.size()[2:], mode='bilinear', align_corners=True)
d3 = F.interpolate(d3, d2.size()[2:], mode='bilinear', align_corners=True)
# fusion
x = torch.cat([d5, d4, d3, d2], dim=1)
x_ca = self.ca(x)
x = x * x_ca
x = self.conv_dr(x)
# feature = x[0:1, 0:64, 0:64, 0:64]
# vis.visulize_features(feature)
# pooling
d2 = x
d3 = self.conv_pool1(x)
d4 = self.conv_pool2(x)
d5 = self.conv_pool3(x)
return d5, d4, d3, d2
class GuidedRefinementModule(nn.Module):
def __init__(self, in_d, out_d):
super(GuidedRefinementModule, self).__init__()
self.in_d = in_d
self.out_d = out_d
self.conv_d5 = nn.Sequential(
nn.Conv2d(self.in_d, self.out_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.out_d),
nn.ReLU(inplace=True)
)
self.conv_d4 = nn.Sequential(
nn.Conv2d(self.in_d, self.out_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.out_d),
nn.ReLU(inplace=True)
)
self.conv_d3 = nn.Sequential(
nn.Conv2d(self.in_d, self.out_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.out_d),
nn.ReLU(inplace=True)
)
self.conv_d2 = nn.Sequential(
nn.Conv2d(self.in_d, self.out_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.out_d),
nn.ReLU(inplace=True)
)
def forward(self, d5, d4, d3, d2, d5_p, d4_p, d3_p, d2_p):
# feature refinement
d5 = self.conv_d5(d5_p + d5)
d4 = self.conv_d4(d4_p + d4)
d3 = self.conv_d3(d3_p + d3)
d2 = self.conv_d2(d2_p + d2)
return d5, d4, d3, d2
class Decoder(nn.Module):
def __init__(self, in_d, out_d):
super(Decoder, self).__init__()
self.in_d = in_d
self.out_d = out_d
self.conv_sum1 = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_sum2 = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.conv_sum3 = nn.Sequential(
nn.Conv2d(self.in_d, self.in_d, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(self.in_d),
nn.ReLU(inplace=True)
)
self.cls = nn.Conv2d(self.in_d, self.out_d, kernel_size=1, bias=False)
def forward(self, d5, d4, d3, d2):
d5 = F.interpolate(d5, d4.size()[2:], mode='bilinear', align_corners=True)
d4 = self.conv_sum1(d4 + d5)
d4 = F.interpolate(d4, d3.size()[2:], mode='bilinear', align_corners=True)
d3 = self.conv_sum1(d3 + d4)
d3 = F.interpolate(d3, d2.size()[2:], mode='bilinear', align_corners=True)
d2 = self.conv_sum1(d2 + d3)
mask = self.cls(d2)
return mask
class BaseNet(nn.Module):
def __init__(self, input_nc, output_nc):
super(BaseNet, self).__init__()
self.backbone = resnet18(pretrained=True)
self.mid_d = 64
self.TFIM5 = TemporalFeatureInteractionModule(512, self.mid_d)
self.TFIM4 = TemporalFeatureInteractionModule(256, self.mid_d)
self.TFIM3 = TemporalFeatureInteractionModule(128, self.mid_d)
self.TFIM2 = TemporalFeatureInteractionModule(64, self.mid_d)
self.CIEM1 = ChangeInformationExtractionModule(self.mid_d, output_nc)
self.GRM1 = GuidedRefinementModule(self.mid_d, self.mid_d)
self.CIEM2 = ChangeInformationExtractionModule(self.mid_d, output_nc)
self.GRM2 = GuidedRefinementModule(self.mid_d, self.mid_d)
self.decoder = Decoder(self.mid_d, output_nc)
def forward(self, x1, x2):
# forward backbone resnet
x1_1, x1_2, x1_3, x1_4, x1_5 = self.backbone.base_forward(x1)
x2_1, x2_2, x2_3, x2_4, x2_5 = self.backbone.base_forward(x2)
# feature difference
d5 = self.TFIM5(x1_5, x2_5) # 1/32
d4 = self.TFIM4(x1_4, x2_4) # 1/16
d3 = self.TFIM3(x1_3, x2_3) # 1/8
d2 = self.TFIM2(x1_2, x2_2) # 1/4
# change information guided refinement 1
d5_p, d4_p, d3_p, d2_p = self.CIEM1(d5, d4, d3, d2)
d5, d4, d3, d2 = self.GRM1(d5, d4, d3, d2, d5_p, d4_p, d3_p, d2_p)
# change information guided refinement 2
d5_p, d4_p, d3_p, d2_p = self.CIEM2(d5, d4, d3, d2)
d5, d4, d3, d2 = self.GRM2(d5, d4, d3, d2, d5_p, d4_p, d3_p, d2_p)
# decoder
mask = self.decoder(d5, d4, d3, d2)
mask = F.interpolate(mask, x1.size()[2:], mode='bilinear', align_corners=True)
mask = torch.sigmoid(mask)
return mask
论文地址
https://ieeexplore.ieee.org/document/9863802