pytorch模型定义之:模型定义三种方式以及U-Net模块搭建笔记
Pytorch学习第三部分:pytorch的模型定义
- Let's go !
- 一、pytorch模型定义
-
- 1.1 Sequential方式
-
- 1.1.1 Sequential: Direct list
- 1.1.2 Sequential: Ordered Dict
- 1.1.3 浅测一下吧
- 1.2 ModuleList方式
-
- 1.2.1 直接实例化ModuleList报错
- 1.2.2 解决方法:自定义forward
- 1.3 ModuleDict方式
-
- 1.3.1 直接实例化ModuleDict报错
- 1.3.2 解决方法:自定义forward
- 1.4 优缺点比较
- 二、搭建U-Net模块
-
- 2.1 U-Net模块介绍
- 2.2 搭建过程
-
- 2.2.1 搭建两次卷积模块
- 2.2.2 搭建下采样模块
- 2.2.3 搭建上采样模块
- 2.2.4 搭建输出模块
- 2.2.5 各模块组装
- 三、模块修改
-
- 3.1 修改特定层
- 3.2 添加额外输入
- 3.3 添加额外输出
- 四、模型保存与读取
-
- 4.1 CPU或单卡:保存&读取整个模型
- 4.2 CPU或单卡:保存&读取模型权重
- 4.3 多卡:保存&读取整个模型(不推荐)
- 4.4 多卡:保存&读取模型权重(推荐)
- 4.5 其他
Let’s go !
这部分知识主要包括了进行模型定义的三种方式、U-Net模块的搭建过程、模型修改以及模型保存和读取的相关知识,让我们一起学起来吧!
一、pytorch模型定义
Module 类是 torch.nn 模块里提供的一个模型构造类 (nn.Module),是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。
PyTorch模型定义应包括两个主要部分:各个部分的初始化(init);数据流向定义(forward)
基于nn.Module,我们可以通过以下三种方式自定义pytorch模型:
- Sequential,
- ModuleList
- ModuleDict
下面开始三种方式的具体介绍:
1.1 Sequential方式
Sequential方式有两种定义模块的方式分别是列表式和字典式
首先是列表形式的Sequential: Direct list 直接列到里面就可以
1.1.1 Sequential: Direct list
这里是做了一个两层的神经网络,中间的激活函数用的Relu。
需要注意的是,
输入层假设长度是784,相当于手写数字拉长了之后的长度(28*28=784)
隐藏节点数是256
输出层节点数是10
代码如下:
## Sequential: Direct list 直接列到里面就可以
import torch.nn as nn
net1 = nn.Sequential(#做了一个两层的神经网络,中间的激活函数用的Relu
nn.Linear(784, 256),#输入层假设长度是784--手写数字拉长了之后的长度(28*28=784),隐藏节点数是256
nn.ReLU(),
nn.Linear(256, 10), #输出节点数是10
)
print(net1)
结果展示:

然后是字典式的Sequential: Ordered Dict 带顺序的字典,python中的字典是不强调顺序的,但神经网络中曾层与层之间有顺序
1.1.2 Sequential: Ordered Dict
前面[ ’ ’ ]的是标号也就是字典里的key键值,fc是指的父类collection,使用Ordered Dict主要是可以实现我们层名称(标号)的命名。
代码如下:
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),#前面的是标号,fc是指的父类collection,使用Ordered Dict主要是可以实现我们层名称(标号)的命名
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)
结果展示:

1.1.3 浅测一下吧
随机生成一个batch=4,维数784的张量a,分别用列表和字典的方式进行实例化。
代码如下:
# 试一下
a = torch.rand(4,784)#4代表的是batch(批数),784是维数
#print(a)
out1 = net1(a)
out2 = net2(a)
print(out1 == out2)
print(out1.shape==out2.shape, out1.shape)
结果展示:
我们可以看到out1与out2的生成的最终形状是一样的,均是我们期望的[4, 10],但是由于两种方式的参数生成存在一定的差异所以两个里的内容其实是不一样的。
1.2 ModuleList方式
ModuleList也是一种类似列表的模块,同时具有列表的一些操作比如append添加列表元素。
这就带给我们了一些与上面Sequential不同的地方,modulelist可以自行添加我们需要的层,而sequential只能依次定义。
代码如下:
## ModuleList
# ModuleList因为是列表所以也可以使用列表的append方法添加元素
net3 = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])#这是手动实现
# net3 = nn.ModuleList([nn.Linear(x,x) for i in range(5)])表示复制5遍
net3.append(nn.Linear(256, 10)) # # 类似List的append操作,给他又加了一层。
print(net3[-1]) # 类似List的索引访问
print(net3)
同时modulelist还有一个很便利的操作是复用,代码如下:
表示前面的那一个层复制5遍。
代码如下:
net3 = nn.ModuleList([nn.Linear(x,x) for i in range(5)])
结果展示:
1.2.1 直接实例化ModuleList报错
代码如下:
# 注意ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。此处应报错
out3 = net3(a)
#也就是没有进行forward的分析,模型不知道ModuleList里层的顺序是什么样的。
当我们直接实例化时报错:表示没有有效的模型层输出

1.2.2 解决方法:自定义forward
但是如果想实例化模块的话那么与Sequential不同的是,ModuleList需要自己定义前向传播的输出,即自己定义forward,因为ModuleList方式构建的模块并不知道层之间的顺序,而Sequential由于是依次顺序列出来的所以不需要自己定义forward。
代码如下:
#解决方法就是把ModuleList的定义放到初始化函数里,然后定义forward来指定他的层的先后顺序(即、数据怎么从前一层传到后一层)
class Net3(nn.Module):
def __init__(self):
super().__init__()
self.modulelist = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
self.modulelist.append(nn.Linear(256, 10))
def forward(self, x):
for layer in self.modulelist:
x = layer(x)
return x
net3_ = Net3()
out3_ = net3_(a)
print(out3_.shape)
由于MoudleList类似列表的形式所以我们在forward中使用循环依次输出层即可。
结果展示;
![]()
1.3 ModuleDict方式
ModuleDict方式类似Sequential中的第二种字典形式,也是通过自定义键值来作为层标识的对应。
代码如下:
## ModuleDict 类似Sequential: Ordered Dict ,也可以自己指定标号名称,但是ModuleDict也和上面一样没有定义网络,需要自己forward
net4 = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net4['output'] = nn.Linear(256, 10) # 添加
print(net4)
print(net4['linear']) # 访问
print(net4.output)
结果展示:

1.3.1 直接实例化ModuleDict报错
代码如下:
# 同样地,ModuleDict并没有定义一个网络,它只是将不同的模块储存在一起。此处应报错。
# 正确使用方式同上
out4 = net4(a)
结果展示:

与上面ModuleList一样由于没有定义出层之间的顺序所以报错。
1.3.2 解决方法:自定义forward
由于ModuleDict不是列表类型所以forward不能用循环进行逐个输出,一般可以通过自己定义键值的方式输出,但是非常复杂。
代码如下:
#解决方法就是把ModuleDict的定义放到初始化函数里,然后定义forward来指定他的层的先后顺序(即、数据怎么从前一层传到后一层)
class Net4(nn.Module):
def __init__(self):
super().__init__()
self.moduledict = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
self.moduledict['output'] = nn.Linear(256, 10)
def forward(self, x):#这个地方的forward不像modulelist那样好用for便利,所以需要一层一层用['key']写明要forward的层是哪一个
#x = self.moduledict['linear'](x)
#x = self.moduledict['act'](x)
#x = self.moduledict['output'](x) #这是我自己写的能输出但不知道对不对
#return x
return x
net4_ = Net4()
print(net4['output'])
print(net4_)
out4_ = net4_(a)
print(out4_.shape)
结果展示:

1.4 优缺点比较
Sequential的方式不需要自己写forward,但是需要自己逐层的定义。
ModuleList的方式可以使用List的方式对重复性大的模型快速复用进行定义,但是缺点就是需要自己写forward。
尤其是当ModuleList不只是一个单一模型的时候,比如和其他层叠在一起的时候非常好用。
二、搭建U-Net模块
下面我们开始探索如何利用模型块,快速构建U-Net网络
2.1 U-Net模块介绍
首先我们看一下U-Net模块的具体流程,从左边最开始输入数据后先进行二次卷积,然后逐渐下采样降低尺寸,下采样到一定程度后进行上采样,上采样的时候需要进行模型修改,将下采样中的输出拼接到上采样升高尺寸后的结果上,最后再进行二次卷积最终得到满足条件的输出。
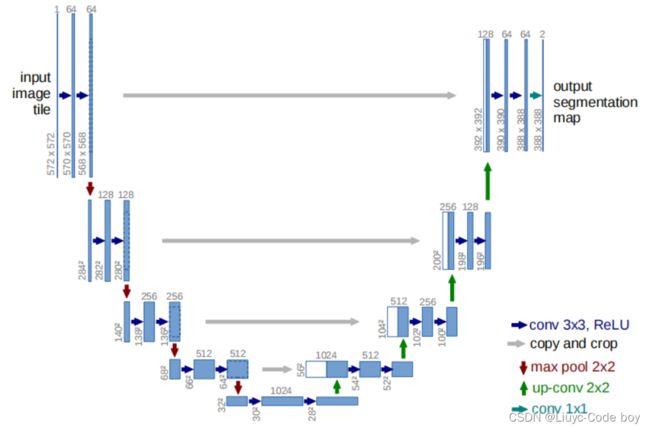
组成U-Net的模型块主要有如下几个部分:
1)每个子块内部的两次卷积(Double Convolution)
2)左侧模型块之间的下采样连接,即最大池化(Max pooling)
3)右侧模型块之间的上采样连接(Up sampling)
4)输出层的处理
除模型块外,还有模型块之间的横向连接,输入和U-Net底部的连接等计算,这些单独的操作可以通过forward函数来实现。
(参考:https://github.com/milesial/Pytorch-UNet )
2.2 搭建过程
首先导入一些必要的pytorch包
import os
import numpy as np
import collections
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
2.2.1 搭建两次卷积模块
两次卷积模块的初始化函数中我们使用Sequential的类型来定义模型,设置的因为是两次卷积所以在输入通道数,输出通道数直接还要有一个中间通道数(第一次卷积输出=第二次卷积输入)
具体执行:
第一次卷积从输入通道到中间通道,执行一次BatchNorm2d和激活,然后第二次卷积从中间通道到输出通道,再执行一次BatchNorm2d和激活。
因为是Sequention的定义方式所以forward直接把sequention给他forward就好了
代码如下:
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""##双次卷积
def __init__(self, in_channels, out_channels, mid_channels=None):#因为是两次卷积所以在输入通道数,输出通道数直接还要有一个中间通道数(第一次卷积输出=第二次卷积输入)
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),#第一次卷积从输入通道到中间通道
nn.BatchNorm2d(mid_channels),# 执行一次BatchNorm2d和激活
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),#第二次卷积从中间通道到输出通道
nn.BatchNorm2d(out_channels),# 再执行一次BatchNorm2d和激活
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)#因为是Sequention的定义方式所以forward直接把sequention给他forward就好了
2.2.2 搭建下采样模块
下采样模块的主要目地就是降低尺寸,并且我们使用了刚刚二次卷积层的复用来定义模块。
代码入下:
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""#下采样模块
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),#先把尺寸降低
DoubleConv(in_channels, out_channels)#再做一次DoubleConv(复用),还是得到一个sequention的模块
)
def forward(self, x):
return self.maxpool_conv(x)
2.2.3 搭建上采样模块
上采样模块与下采样模块相对应主要是进行升高尺寸,主要的亮点是在torch.cat(x2, x1),将x2和x1叠加在一起,这也是后面模型修改的方法之一。
代码如下:
class Up(nn.Module):
"""Upscaling then double conv"""#上采样模块
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:#因为上采样需要差值,bilinear就是一个差值方式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#Upsample是pytorch内置的一个函数进行上采样操作
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)#上采样之后在进行一次卷积
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)#精髓点,将x2和x1叠加在一起
return self.conv(x)
2.2.4 搭建输出模块
输出模块的主要目的是将我们的结果进行处理最终得到我们目标想要的通道数,如果是二分类问题channel可能是1,多分类可能是5,6,7…
代码如下:
class OutConv(nn.Module):# 输出的时候再进行一次卷积,这个卷积目的是使得channel数达到最后的channel数量,如果是二分类问题channel可能是1,多分类可能是5,6,7...
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
2.2.5 各模块组装
将上述的各个模块进行组装最终得到我们的U-Net模块。
代码如下:
## 组装
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)# 参数都是连续的64...128...256...512
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1#,factor取决于差值的选取方式,如果是linear的话factor就是2
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)#上采样的时候是通道数是逐渐减少的
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):#用forward连接起来,是一个很优美的数据流
x1 = self.inc(x)#数据输进来,先过inc进行第一次DoubleConv
x2 = self.down1(x1)#下采样的时候其实也有DoubleConv操作,但是直接down就好了,因为Down函数里面有复用的DouleConv
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)#上采样有两个输入因为up是接收了另一个输入的
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)#最后把x4得到的结果输出到output得到的logits,logitis其实就是做sigmoid之前的一个数。
return logits
定义输入时3通道的RGB,期望输出是单通道的二分类黑白图
代码如下:
unet = UNet(3,1)#只需要定义两个输入,定义输入的channel是几个,假设是RGB的就是3个输入,十几个class就输出几个class,这里我们假定输出的是黑白的二分类的问题也就是1个维度
unet
运行结果展示:

三、模块修改
这里我们假设最后的分割是多类别的(即mask不止0和1,还有2,3,4等值代表其他目标),需要对模型特定层进行修改。
此外还有两种情况的模型修改方式,这里也做演示:
- 添加额外输入
- 添加额外输出
首先我们可以查看一下当前模型我们选择的层的样子
## 修改特定层
import copy#内置的copy块
unet1 = copy.deepcopy(unet)#复制unet的结构
unet1.outc#.outc可以用来检测层的样子
结果展示:
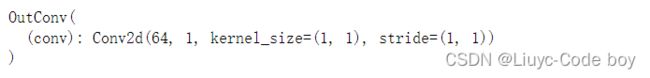
也可以查看模型全貌
unet1#查看全貌
结果展示:

3.1 修改特定层
假定有一个随机生成的噪声图片,batch是1,channel是3,大小是224*224,由于我们之前定义的U-Net模型最后的output层是将通道数转换成1,所以结果不论输入的是几个channel最后使用UNet模型输出都是1个channel。
b = torch.rand(1,3,224,224)#假定有一个随机生成的噪声图片,batch是1,channel是3,大小是224*224
out_unet1 = unet1(b)
print(out_unet1.shape)#结果不论输入的是几个channel最后使用UNet模型输出都是1个channel
结果展示:
![]()
修改特定层:我们想输出5个channel,分别表示这个像素属于我们想要的五种类别的概率
代码如下:
#我们想输出5个channel,分别表示这个像素属于我们想要的五种类别的概率
unet1.outc = OutConv(64, 5)
#unet1.outc这个outc是创建的UNet模型里输出层的key值,我们使用unet1.outc可以获取这个层,然后重新实例化就可以修改
#类似的我们也可以去修改其他层,比如mid层...等等
unet1.outc
结果展示:

再次输入刚刚的噪声图片b查看现在的最终输出结果
out_unet1 = unet1(b)#仍然拿刚刚定义的噪声图片输出,发现和刚刚相比只有channel数发生了变化
print(out_unet1.shape)
结果展示:
![]()
发现通道数已经变为了我们修改的5
3.2 添加额外输入
添加额外输入主要是在两个地方进行修改:
- 在forward中,修改点,假设add_variable是一个常数,那么我们可以给每个x加上这一点(这个修改的例子没什么实际意义),这个修改可以放在任意位置,但是注意可能需要对上面的模型块进行修改。
- 在上面定义的下采样模块或者上采样模块处要进行对应匹配,即在下面forward流修改了之后这里的模型块的定义也要相应的修改,比如down1的输出变成128+1=129,那么down2的输入也应该是129而不是原来的128。
- 最后注意:因为forward里定义了添加一个add_variable,所以这里输入(b,c)多了一个c作为输入。这个例子最后结果与原来的一样,因为虽然多了一个数但是实际我写的没有任何意义,但是实际使用的时候可以自己添加一些有意义的额外输入
代码如下:
## 添加额外输入
class UNet2(nn.Module):#定义一个新模型,和刚刚一样也是把这些层堆叠起来
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet2, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)#注意在下面forward流修改了之后这里的模型块的定义也要相应的修改,比如down1的输出变成128+1=129,那么down2的输入也应该是129
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x, add_variable):#在forward里添加了一个add_variable,下面的内容里就要把add_variable用起来
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = x + add_variable #修改点,假设add_variable是一个常数,那么我们可以给每个x加上这一点(这个修改的例子没什么实际意义),这个修改可以放在任意位置,但是注意可能需要对上面的模型块进行修改。
logits = self.outc(x)
return logits
unet2 = UNet2(3,1)
c = torch.rand(1,1,224,224)#这是一个自己定义的噪声
out_unet2 = unet2(b, c)#因为forward里定义了添加一个add_variable,所以这里输入(b,c),这个例子里的多数出一个是没有任何意义的,但是实际使用的时候可以自己添加一些有意义的额外输入
print(out_unet2.shape)
结果展示:
![]()
由于我们代码其实没什么实质性的修改所以不会产生结果的区别,,但是实际使用的时候可以自己添加一些有意义的额外输入。
3.3 添加额外输出
添加额外输出比较简单,只需要在forward最后的return返回的时候加上我们想要额外输出的内容,同时在实例化接收的时候多定义一个变量接收输出内容即可。
代码如下:
## 添加额外输出
class UNet3(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet3, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits, x5 # 修改点,只需要在return输出即可
unet3 = UNet3(3,1)
c = torch.rand(1,1,224,224)
out_unet3, mid_out = unet3(b)#只需要额外添加一个变量接收额外的输出即可
print(out_unet3.shape, mid_out.shape)
结果展示:
![]()
四、模型保存与读取
这里相应考虑单卡和多卡情况下的模型存取情况。
模式一共有三种:pt、pth、pkl
注意:我们保存后可以回到jupyter的文件目录下,看保存的结果。
还是先把我们最开始的U-Net模块数据打印出来一部分:
unet # 还是最开始定义的原始的unet模型输入3输出1
结果展示:

然后我们将数据转换成字典格式:
unet.state_dict() # 用字典的方式存下来
结果展示一部分:
4.1 CPU或单卡:保存&读取整个模型
## CPU或单卡:保存&读取整个模型
torch.save(unet, "./unet_example.pth")#保存
loaded_unet = torch.load("./unet_example.pth")#输出
loaded_unet.state_dict()
结果展示:

发现与我们上面转化成字典的数据是一致的。
后续存储内容只是方法不同结果与上面一直我就不展示结果了。
4.2 CPU或单卡:保存&读取模型权重
## CPU或单卡:保存&读取模型权重
torch.save(unet.state_dict(), "./unet_weight_example.pth")
loaded_unet_weights = torch.load("./unet_weight_example.pth")#先load到一个缓存变量里
unet.load_state_dict(loaded_unet_weights)#用定义好的模型结构去.load_state_dict把预存的变量加载进去
unet.state_dict()
4.3 多卡:保存&读取整个模型(不推荐)
## 多卡:保存&读取整个模型。注意模型层名称前多了module
## 不建议,因为保存模型的GPU_id等信息和读取后训练环境可能不同,尤其是要把保存的模型交给另一用户使用的情况
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'#与cpu或者单卡不同,cpu是在cpu,单卡是在cuda0,多卡如果存的卡和加载的卡不一样的话就很难匹配。
unet_mul = copy.deepcopy(unet)
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul
torch.save(unet_mul, "./unet_mul_example.pth")
loaded_unet_mul = torch.load("./unet_mul_example.pth")
loaded_unet_mul
4.4 多卡:保存&读取模型权重(推荐)
## 多卡:保存&读取模型权重。--推荐
torch.save(unet_mul.state_dict(), "./unet_weight_mul_example.pth")
loaded_unet_weights_mul = torch.load("./unet_weight_mul_example.pth")
unet_mul.load_state_dict(loaded_unet_weights_mul)
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()
4.5 其他
# 另外,如果保存的是整个模型,也建议采用提取权重的方式构建新的模型:
unet_mul.state_dict = loaded_unet_mul.state_dict
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()