Spark SQL实验:鸢尾花、影评数据集分析存储
一、实验描述
鸢尾花数据集分析
数据集信息如下:
iris.csv 的各特征列为花萼长度(sepal_length)、花萼宽度(sepal_width)、花瓣长度(petal_length)、花瓣宽度(petal_width)、鸢尾花种类(iris_type),每种鸢尾花都对应50个数据记录, 共含150个数据记录。
导入鸢尾花数据集到Mysql之后,进行如下查询:
(1) 所有鸢尾花的花萼与花瓣的长度、宽度的均值
(2) 不同种类的鸢尾花的花萼与花瓣的长度、宽度的均值
(3) 不同种类的鸢尾花的花萼与花瓣的长度、宽度的标准差
其中,(2)、(3)的查询结果存到Mysql当中
影评数据集分析
数据集信息如下:
1、users.dat 数据格式为: 2::M::56::16::70072,共有6040条数据
对应字段为:UserID,Gender,Age, Occupation,Zipcode
对应字段中文解释:用户id,性别,年龄,职业,邮政编码
2、movies.dat 数据格式为: 2::Jumanji (1995)::Adventure|Children’s|Fantasy,共有3883条数据
对应字段为:MovieID, Title, Genres
对应字段中文解释:电影ID,电影名字,电影类型
3、ratings.dat 数据格式为: 1::1193::5::978300760,共有1000209条数据
对应字段为:UserID, MovieID, Rating, Timestamped
对应字段中文解释:用户ID,电影ID,评分,评分时间戳
查询分析目标:
(1) 被评分次数最多的10部电影
(2) 求 movie_id = 2116 这部电影各年龄段的平均影评(年龄段,影评分)
(3) 好片(评分>=4.0)最多的那个年份的最好看的10部电影
(4) 1997年上映的电影中评分最高的10部Comedy类电影
(5) 每个地区最高评分的电影名
二、实验代码
1. Iris
(1) IrisRequirementRealization.scala
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SparkSession, functions}
class IrisRequirementRealization {
def getIris(sparkSession: SparkSession): DataFrame = {
val iris = sparkSession.read.format("jdbc").option(
"url","jdbc:mysql://master:3306/iris"
).option(
"driver","com.mysql.jdbc.Driver"
).option(
"user", "root"
).option(
"password", "Hive@2020"
).option(
"dbtable","iris"
).load()
iris
}
def requirementA(sparkSession: SparkSession): Unit ={
val iris = getIris(sparkSession)
iris.createOrReplaceTempView("iris_temp")
val df = sparkSession.sql("SELECT AVG(sepal_length) as sepal_length_avg, AVG(sepal_width) sepal_width_avg, AVG(petal_length) petal_length_avg, AVG(petal_width) petal_width_avg FROM iris_temp")
df.show()
}
def requirementB(sparkSession: SparkSession): Unit ={
val iris = getIris(sparkSession)
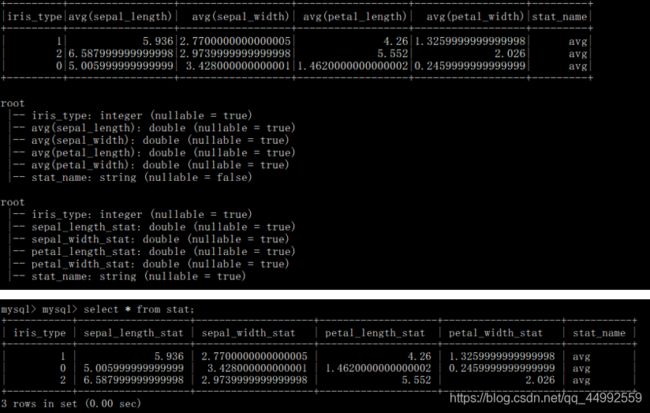
var df = iris.groupBy("iris_type").avg("sepal_length","sepal_width","petal_length","petal_width")
df = df.withColumn("stat_name", functions.lit("avg"))
df.show()
df.printSchema()
val schema = StructType(
List(
StructField("iris_type", IntegerType, nullable = true),
StructField("sepal_length_stat", DoubleType, nullable = true),
StructField("sepal_width_stat", DoubleType, nullable = true),
StructField("petal_length_stat", DoubleType, nullable = true),
StructField("petal_width_stat", DoubleType, nullable = true),
StructField("stat_name", StringType, nullable = true),
)
)
df = sparkSession.createDataFrame(df.rdd, schema)
df.printSchema()
writeToMysql(df)
}
def requirementC(sparkSession: SparkSession): Unit ={
val iris = getIris(sparkSession)
iris.createOrReplaceTempView("temp_iris")
val df = sparkSession.sql("SELECT iris_type, STD(sepal_length) as sepal_length_stat, STD(sepal_width) as sepal_width_stat, STD(petal_length) as petal_length_stat, STD(petal_width) petal_width_stat, \"std\" as stat_name FROM temp_iris GROUP BY iris_type")
df.show()
df.printSchema()
writeToMysql(df)
}
def writeToMysql(df: DataFrame): Unit ={
val p = new Properties()
p.put("user","root")
p.put("password", "Hive@2020")
p.put("driver", "com.mysql.jdbc.Driver")
df.write.mode("append").jdbc(
"jdbc:mysql://master:3306/iris", "iris.stat", p
)
}
}
(2) IrisMain.scala
import org.apache.spark.sql.SparkSession
import scala.io.StdIn
import scala.util.control.Breaks
object IrisMain {
def main(args: Array[String]): Unit ={
val sparkSession = SparkSession.builder().appName("Iris").enableHiveSupport().getOrCreate()
val y = new IrisRequirementRealization()
Breaks.breakable{
while(true){
println("A. 所有鸢尾花的花萼与花瓣的长度、宽度的均值")
println("B. 不同种类的鸢尾花的花萼与花瓣的长度、宽度的均值")
println("C. 不同种类的鸢尾花的花萼与花瓣的长度、宽度的标准差")
println("------------------------------------")
println("Enter the requirement code to see the result(X to quit):")
val input = StdIn.readLine().trim
input match {
case "A" => y.requirementA(sparkSession)
case "B" => y.requirementB(sparkSession)
case "C" => y.requirementC(sparkSession)
case "X" => Breaks.break()
case _ => println("Invalid Input")
}
}
}
}
}
2. Movie
(1) MovieRequirementRealization.scala
import java.io.File
import org.apache.spark.sql.SparkSession
class MovieRequirementRealization {
def getProjectRootPath: String ={
val projectRoot: String = System.getProperty("user.dir")
projectRoot
}
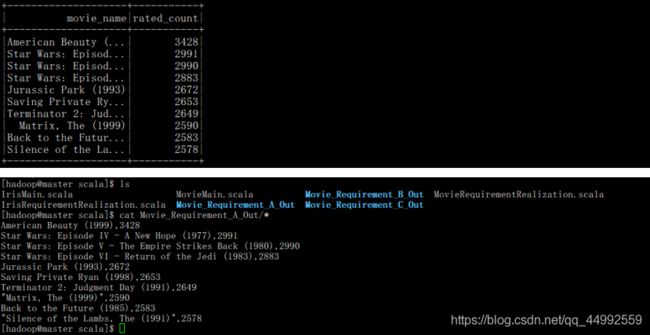
def requirementA(spark: SparkSession): Unit ={
val dfA = spark.sql(
"with movie_rated_count as (select rate.movie_id,count(*) as rated_count from rate group by movie_id) " +
"select movie.title as movie_name,movie_rated_count.rated_count as rated_count " +
"from movie_rated_count join movie on(movie_rated_count.movie_id=movie.movie_id) order by rated_count desc limit 10"
)
dfA.show()
val projectRoot = getProjectRootPath
val files: String = "file://" + projectRoot + "/src/main/scala/Movie_Requirement_A_Out"
dfA.write.csv(files)
}
def requirementB(spark: SparkSession): Unit ={
val dfB = spark.sql(
"select the_user.age,avg(rating) as avg_rating from the_user join rate on(the_user.user_id=rate.user_id) where rate.movie_id=2116 group by the_user.age"
)
dfB.show()
val projectRoot = getProjectRootPath
val files: String = "file://" + projectRoot + "/src/main/scala/Movie_Requirement_B_Out"
dfB.write.format("csv").save(files)
}
def requirementC(spark: SparkSession): Unit ={
val dfC = spark.sql(
"with " +
"x as (select movie.movie_id as movie_id,movie.title as title,substr(movie.title,-5,4) as movie_year," +
"avg(rate.rating) as avg_rating " +
"from rate join movie on(rate.movie_id=movie.movie_id) " +
"group by movie.movie_id,movie.title), " +
"y as (select x.movie_year as movie_year,count(*) as total " +
"from x where x.avg_rating>=4.0 " +
"group by movie_year " +
"order by total desc limit 1) " +
"select x.movie_id as movie_id,x.title as title,x.avg_rating as rating " +
"from x join y on(x.movie_year=y.movie_year) order by avg_rating desc limit 10"
)
dfC.show()
val projectRoot = getProjectRootPath
val files: String = "file://" + projectRoot + "/src/main/scala/Movie_Requirement_C_Out"
dfC.write.csv(files)
}
def requirementD(spark: SparkSession): Unit ={
val dfD = spark.sql(
"with x as (select movie.movie_id as movie_id,movie.title as title,substring(movie.title,-5,4) as movie_year,avg(rate.rating) as avg_rating " +
"from rate join movie on(rate.movie_id=movie.movie_id) group by movie.movie_id,movie.title) " +
"select x.movie_id,x.title,x.avg_rating from x join movie on(x.movie_id=movie.movie_id) " +
"where x.movie_year=1997 and array_contains(movie.genres,'Comedy') order by avg_rating desc limit 10"
)
dfD.show()
val projectRoot = getProjectRootPath
val files: String = "file://" + projectRoot + "/src/main/scala/Movie_Requirement_D_Out"
dfD.write.format("csv").save(files)
}
def requirementE(spark: SparkSession): Unit ={
val dfE = spark.sql(
"with " +
"x as (select the_user.zip_code as zipcode,movie.movie_id as movie_id,movie.title as movie_name,avg(rate.rating) as avgrating " +
"from the_user join rate on rate.user_id=the_user.user_id join movie on rate.movie_id=movie.movie_id group by the_user.zip_code,movie.movie_id,movie.title), " +
"y as (select x.zipcode as zipcode,x.movie_name as movie_name,x.avgrating as avgrating,row_number() over(distribute by x.zipcode sort by x.avgrating desc) as num from x) " +
"select y.zipcode,y.movie_name,y.avgrating from y where num=1"
)
dfE.show()
val projectRoot = getProjectRootPath
val files: String = "file://" + projectRoot + "/src/main/scala/Movie_Requirement_E_Out"
dfE.write.csv(files)
}
}
(2) MovieMain.scala
import org.apache.spark.sql.SparkSession
import scala.io.StdIn
import scala.util.control.Breaks
object MovieMain {
def main(args: Array[String]): Unit ={
val sparkSession = SparkSession.builder().appName("Movie").enableHiveSupport().getOrCreate()
val x = new MovieRequirementRealization()
Breaks.breakable{
while(true){
println("A. 被评分次数最多的10部电影")
println("B. 求 movie_id = 2116 这部电影各年龄段的平均影评(年龄段,影评分)")
println("C. 好片(评分>=4.0)最多的那个年份的最好看的10部电影")
println("D. 1997年上映的电影中评分最高的10部Comedy类电影")
println("E. 每个地区最高评分的电影名")
println("------------------------------------")
println("Enter the requirement number to see the result(X to quit):")
val input = StdIn.readLine().trim
input match {
case "A" => x.requirementA(sparkSession)
case "B" => x.requirementB(sparkSession)
case "C" => x.requirementC(sparkSession)
case "D" => x.requirementD(sparkSession)
case "E" => x.requirementE(sparkSession)
case "X" => Breaks.break()
case _ => println("Invalid Input")
}
}
}
}
}
三、运行结果
1. Iris

(1) A

(2) B

(3) C
2. Movie

(1) A
(2) B

(3) C

(4) D

(5) E
