PaddlePaddle(3)——深度学习模型训练和关键参数调优详解
转载请注明作者和出处:https://blog.csdn.net/qq_28810395
运行平台: Windows 10
AIstudio官网:https://aistudio.baidu.com/ --飞桨领航团AI达人创造营

前言
1.什么是人工智能

人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
人工智能是一门极富挑战性的科学,从事这项工作的人必须懂得计算机知识,心理学和哲学。人工智能是包括十分广泛的科学,它由不同的领域组成,如机器学习,计算机视觉等等,总的说来,人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。但不同的时代、不同的人对这种“复杂工作”的理解是不同的。 [1] 2017年12月,人工智能入选“2017年度中国媒体十大流行语”。 [2]
2.我们所追求的智能

3.目前我们所实现的“智能”
- 老旧照片修复
- 图像分割(人物抠图,医学图像处理,车辆分割)

- 人物识别

- 图像提取(标签提取)
- AI写诗

一、模型选择
根据目前完成工程目标与任务类型出发,选择最合适的模型。
1.回归任务——以人脸关键点检测为例

- 人脸关键点检测

- 1-17:人脸的下轮廓
- 18-27:眉毛
- 28-36: 鼻子
- 37-48:眼睛
- 49-68:嘴巴
人脸关键点检测任务中,输出为人脸关键点的数量x2,即每个人脸关键点的横坐标与纵坐标。
- 目标要求(既要准确又要速度)
在模型组网时,主要使用2个模块,分别是Inception模块和空间注意力模块。增加空间注意力模块是为了提高模型效果。
-
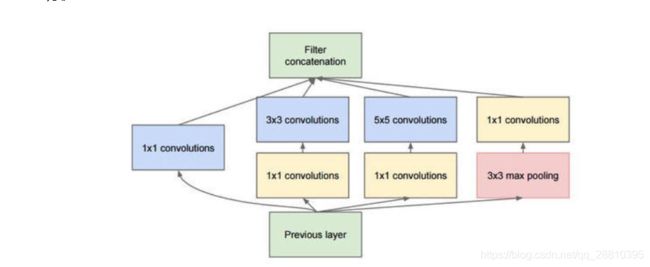
Inception模块:
GoogLeNet是由Inception模块进行组成的,GoogLeNet采用了模块化的结构,因此修改网络结构时非常简单方便。以增加网络深度和宽度的同时减少参数。
-
空间注意力模块
空间注意力聚焦在“哪里”是最具信息量的部分,比如,图像中的某一个图像区域,随着任务的变化,注意力区域往往会发生变化。计算空间注意力的方法是沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符。

2.分类任务
CIFAR-10数据集也是分类任务中一个非常经典的数据集,在科研中,常常使用CIFAR数据集评估算法的性能。
在MLP中,最核心的部分就是空间选通单元(Spatial Gating Unit, SGU),它的结构如下图所示:
3.场景任务
-
目标检测
基于PaddleX的YOLOv3模型快速实现昆虫检测。

-
人像分割
基于PaddleX核心分割模型 Deeplabv3+Xcetion65 & HRNet_w18_small_v1 实现人像分割,PaddleX提供了人像分割的预训练模型,可直接使用,当然也可以根据自己的数据做微调。

-
文字识别
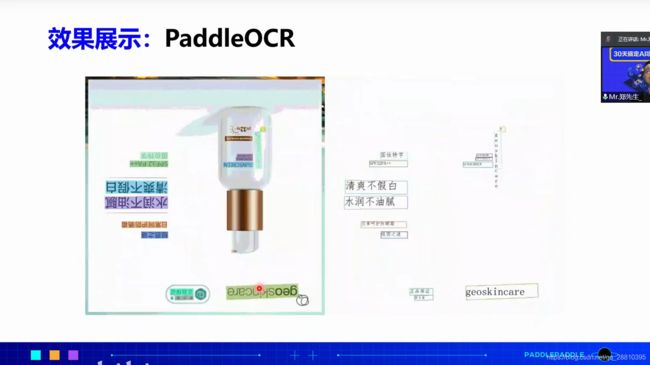
基于chinese_ocr_db_crnn_mobile实现文字识别,识别图片当中的汉字,该Module是一个超轻量级中文OCR模型,支持直接预测。

-
总结
根据自己任务场景需求选择相应模型,对应文档进行微调与配置。PaddleX文档链接
PaddleX简介:PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程,并提供简明易懂的Python API,方便用户根据实际生产需求进行直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践。
二、 模型训练
基础:神经网络梯度下降
1. 基于高层API训练模型
通过Model.prepare接口来对训练进行提前的配置准备工作,包括设置模型优化器,Loss计算方法,精度计算方法等。
import paddle
# 使用paddle.Model完成模型的封装
model = paddle.Model(Net)
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 调用fit()接口来启动训练过程
model.fit(train_dataset,
epochs=1,
batch_size=64,
verbose=1)
- 加载数据集
论文里将gMLP应用到ImageNet上的图像分类任务中,而不使用额外的数据,从而在视觉领域检查gMLP。但是ImageNet数据集较大,为了节省时间,这里使用Cifar10进行验证。
mport paddle.vision as vision
import paddle
import paddle.vision.transforms as transforms
from paddle.vision.transforms import Normalize
normalize = transforms.Normalize(
[0.4914*255, 0.4822*255, 0.4465*255], [0.2023*255, 0.1994*255, 0.2010*255])
trainTransforms = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.Transpose(),
normalize
])
testTransforms = transforms.Compose([
transforms.Transpose(),
normalize
])
trainset = vision.datasets.Cifar10(mode='train', transform=trainTransforms)
trainloader = paddle.io.DataLoader(trainset, batch_size=128, num_workers=0, shuffle=True)
testset = vision.datasets.Cifar10(mode='test', transform=testTransforms)
testloader = paddle.io.DataLoader(testset, batch_size=128, num_workers=0, shuffle=True)
- 模型封装
以使用paddle.Model完成模型的封装,将网络结构组合成一个可快速使用高层API进行训练和预测的对象。代码如下:
model = paddle.Model(gmlp_vision)
- 训练参数配置
用paddle.Model完成模型的封装后,在训练前,需要对模型进行配置,通过Model.prepare接口来对训练进行提前的配置准备工作,包括设置模型优化器,Loss计算方法,精度计算方法等。
# 调用飞桨框架的VisualDL模块,保存信息到目录中。
callback = paddle.callbacks.VisualDL(log_dir='gMLP_log_dir')
def create_optim(parameters):
step_each_epoch = len(trainloader) // 128
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=0.25,
T_max=step_each_epoch * 120)
return paddle.optimizer.Adam(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(3e-4))
model.prepare(create_optim(model.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, 5))) # 评估指标
- 模型训练
做好模型训练的前期准备工作后,调用fit()接口来启动训练过程,需要指定至少3个关键参数:训练数据集,训练轮次和单次训练数据批次大小。
model.fit(trainloader,
testloader,
epochs=120,
eval_freq=2,
shuffle=True,
save_dir='gMLP_case1_chk_points/',
save_freq=20,
batch_size=128,
callbacks=callback,
verbose=1)
2.使用PaddleX训练模型
YOLOv3模型的训练接口示例,函数内置了piecewise学习率衰减策略和momentum优化器。
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.000125,
lr_decay_epochs=[210, 240],
save_dir='output/yolov3_darknet53',
use_vdl=True)
- 配置数据集
from paddlex.det import transforms
import paddlex as pdx
# 下载和解压昆虫检测数据集
insect_dataset = 'https://bj.bcebos.com/paddlex/datasets/insect_det.tar.gz'
pdx.utils.download_and_decompress(insect_dataset, path='./')
# 定义训练和验证时的transforms
# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/det_transforms.html
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250), transforms.RandomDistort(),
transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize(
target_size=608, interp='RANDOM'), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.Resize(
target_size=608, interp='CUBIC'), transforms.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-vocdetection
train_dataset = pdx.datasets.VOCDetection(
data_dir='insect_det',
file_list='insect_det/train_list.txt',
label_list='insect_det/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='insect_det',
file_list='insect_det/val_list.txt',
label_list='insect_det/labels.txt',
transforms=eval_transforms)
- 初始化模型
# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.html
num_classes = len(train_dataset.labels)
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#paddlex-det-yolov3
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
- 模型训练
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#id1
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.000125,
lr_decay_epochs=[210, 240],
save_dir='output/yolov3_darknet53',
use_vdl=True)
3.模型训练通用配置基本原则
- 每个输入数据的维度要保持一致,且一定要和模型输入保持一致。
- 配置学习率衰减策略时,训练的上限轮数一定要计算正确。
- BatchSize不宜过大,太大容易内存溢出,且一般为2次幂。
四、超参优化
1. 超参优化的基本概念概述:
在介绍HPO之前,先对超参和HPO的概念做一个简要介绍,其定义如下:
超参数:超参通常指在算法或模型开始之前必须确定,无法在计算过程中更新的参数。如在深度学习中的优化器、迭代次数、激活函数、学习率等;在运筹优化算法中的编码方式、迭代次数、目标权重、用户偏好等,另外算法类型可作为更高层面的一种超参。
超参优化:超参数优化是指不是依赖人工调参,而是通过一定算法找出优化算法/机器学习/深度学习中最优/次优超参数的一类方法。HPO的本质是生成多组超参数,一次次地去训练,根据获取到的评价指标等调节再生成超参数组再训练。
平时在各个系统中我们通常接触参数较多,从上面的定义中可以看出,超参这个概念是相对参数提出来的。在某些领域其参数也满足上述的超参定义,广义上讲也可以纳入超参的定义中,如遗传算法(Genetic Algorithm, GA)中的种群数量,控制器的控制参数等。
而HPO是在超参空间中的搜索算法,优化的结果是模型/算法的一组超参,这组超参在我们的数据集上取得了最优的效果。值得一提的是HPO通常是一种黑盒优化。
2.手动调整超参数的四大方法
使用某一网络时,最好在已经出现的论文中证明过,然后在此基础上,调参,优化。但存在领域不同,所表现的效果不好,所以需要随之改变。
注意:目前不存在⼀种通用的关于正确策略的共同认知,这也是超参数调节的"玄学"之处
- 使用提前停止来确定训练的迭代次数
方法:做一个判断,满足条件时退出循环,终止训练:
重点:for epoch in range(MAX_EPOCH): // 训练代码 print('{}[TRAIN]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy())) if (): break model.train()
- 分类准确率不再提升
我们需要再明确⼀下什么叫做分类准确率不再提升,这样方可实现提前停止。
分类准确率在整体趋势下降的时候仍旧会抖动或者震荡。如果在准确度刚开始下降的时候就停止,那么肯定会错过更好的选择。
所以⼀种不错的解决方案是如果分类准确率在⼀段时间内不再提升的时候终止。当然这块用loss也是可以的,loss也是一个评判标准。 - loss降到一个想要的范围时
因为网络有时候会在很长时间内于⼀个特定的分类准确率附近形成平缓的局面,然后才会有提升。如果想获得相当好的性能,
第一种方案(分类准确率不再提升时)的规则可能就会太过激进了 —— 停止得太草率。
第二方案(loss降到一个想要的范围时)能很好地解决这一问题,但随之而来的问题就是不知不觉地又多了一个超参数,实际应用上,这个用于条件判断的loss值的选择也很困难。
- 让学习率从高逐渐降低
一般我们都将学习速率设置为常量。然而,如果采用采用可变的学习速率更加有效。
学习率设置中,学习率设置的过低,在训练的前期,训练速度会非常慢;而学习率设置地过高,在训练的后期,又会产生震荡,降低模型的精度:
 所以最好是在前期使用一个较大的学习速率让权重变化得更快。越往后,我们可以降低学习速率,这样可以作出更加精良的调整。
所以最好是在前期使用一个较大的学习速率让权重变化得更快。越往后,我们可以降低学习速率,这样可以作出更加精良的调整。
⼀种自然的观点是使用提前终止的想法。就是保持学习速率为⼀个常量直到验证准确率开始变差,然后按照某个量下降学习速率。我们重复此过程若干次,直到学习速率是初始值的 1/1024(或者1/1000),然后终止训练。 - 宽泛策略
宽泛策略可当作是一种对于网络的简单初始化和一种监控策略,这样可以更加快速地实验其他的超参数,或者甚至接近同步地进行不同参数的组合的评比。
下面的方法能给你带来某些不一样的启发:- 通过简化网络来加速实验进行更有意义的学习
- 通过更加频繁的监控验证准确率来获得反馈
五、效果展示
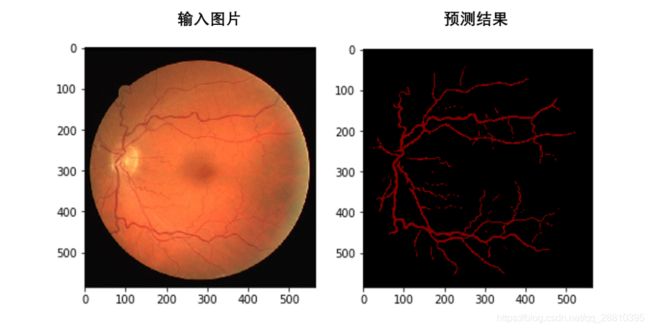
1.可视化输入与输出
直接可视化输入与输出是最直接的方法。将输入图片与预测输出图片进行可视化比对。
2.巧用VisualDL
VisualDL可视化流程
-
创建日志文件:
*为了快速找到最佳超参,训练9个不同组合的超参实验,创建方式均相同如下:writer = LogWriter("./log/lenet/run1") -
训练前记录每组实验的超参数名称和数值,且记录想要展示的模型指标名称
writer.add_hparams({'learning rate':0.0001, 'batch size':64, 'optimizer':'Adam'}, ['train/loss', 'train/acc'])注意:这里记录的想要展示的模型指标为’train/loss’和 ‘train/acc’,后续切记需要用add_scalar接口记录对应数值
-
训练过程中插入作图语句,记录accuracy和loss的变化趋势,同时将展示于Scalar和HyperParameters两个界面中:
writer.add_scalar(tag="train/loss", step=step, value=cost) writer.add_scalar(tag="train/acc", step=step, value=accuracy) -
记录每一批次中的第一张图片:
img = np.reshape(batch[0][0], [28, 28, 1]) * 255 writer.add_image(tag="train/input", step=step, img=img) -
记录训练过程中每一层网络权重(weight)、偏差(bias)的变化趋势:
writer.add_histogram(tag='train/{}'.format(param), step=step, values=values) -
记录分类效果–precision & recall曲线:
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i), labels=label_i, predictions=prediction_i, step=step, num_thresholds=20) writer.add_roc_curve(tag='train/class_{}_pr_curve'.format(i), labels=label_i, predictions=prediction_i, step=step, num_thresholds=20) -
保存模型结构:
fluid.io.save_inference_model(dirname='./model', feeded_var_names=['img'],target_vars=[predictions], executor=exe)
3.权重可视化
InterpretDL源码:https://github.com/PaddlePaddle/InterpretDL

六、 总结
本次课程对于参数调节博大而精深,需要慢慢回顾,实践尝试。
七、参考信息
- https://www.bilibili.com/video/BV1qq4y1X7uZ?p=3
- https://aistudio.baidu.com/aistudio/projectdetail/2247376
