ICCV 2021 Oral|涨点神器!RS Loss:目标检测和实例分割的新损失函数
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:极市平台 作者丨小马
导读
本文作者提出了一种用于目标检测和实例分割任务的Rank & Sort Los),能够简化原来模型训练的复杂性,并能使得模型达到更好的performance。
写在前面
目标检测和实例分割往往是一个multi-task的任务,其中包含了诸如classification,box regression和mask prediction等多个子任务,因此对于这类任务的损失函数往往是多个子任务的损失函数来加权求和,如下所示:

其中, 是在第k个stage中第t个任务的损失函数(对于Faster R-CNN这类二阶段的目标检测器, 就等于2), 是一个用来决定每个stage中每个任务权重的超参数。
由于子任务和stage的多样性以及每个任务重要性的不平衡,在这类任务中,超参数的数量往往就会比较多。虽然加入这些超参数来平衡不同任务的重要性能够让模型获得更好的性能,但由于调参是非常耗时耗资源的,并且次优的超参数会导致模型次优的性能。
因此,在本文中,作者提出了一种用于目标检测和实例分割任务的Rank & Sort Loss(RSLoss),能够简化原来模型训练的复杂性,并能使得模型达到更好的performance。实验中,作者在7个模型中验证了RSLoss的有效性。
1. 论文和代码地址

Rank & Sort Loss for Object Detection and Instance Segmentation
论文地址:https://arxiv.org/abs/2107.11669
代码地址:https://github.com/kemaloksuz/RankSortLoss
2. Motivation
上面提到了,目标检测和实例分割这类multi-task任务,需要在每个子任务的损失函数之前加上一个超参数来调节他们的重要性,但是调参这个过程是非常耗时耗资源的,并且次优的超参数会导致模型次优的性能。
因此,最近也有工作提出了一些方法来避免这个问题,比如ranking-based的损失函数(代表有Average Precision (AP) Loss[1],average Localisation Recall Precision (aLRP) Loss[2]),相比于传统的损失函数,主要有两个优点:
1)它们直接优化performance的指标(比如AP),从而使训练和评估目标保持一致。另一方面,这也减少了超参数的数量,因为performance的指标通常不会有超参数的约束。
2)由于ranking-based的损失函数对错误的定义与传统的损失函数不同,因此这类损失函数往往对于“类别不平衡”的问题(比如说长尾问题)更加鲁棒。
虽然这些方法能够提升模型的性能,但是他们往往需要更长的训练时间 。
总的来说,ranking-based的损失函数更加关注于正样本,而不是负样本;并且也没有显式的建模正样本和正样本之间的关系。使用一个辅助head根据定位的质量(比如说用IoU等指标来衡量)来对正样本之间优先级的排序,对于提升性能也是非常重要的。除此之外,也有文献提出,直接用IoU对分类器进行监督,就能够直接移除辅助head并提升performance。

基于上面的思想,作者提出了Rank & Sort (RS) Loss来训练视觉检测器(VD,这里的VD可用于目标检测和实例分割)。RS Loss其实由两部分组成,一部分是Rank,还有一部分是Sort。Rank指的是根据Classification Lofits区分出正负的样本,Sort指的是根据IoU来对正样本进行排序。
这样的方式能够带来几个好处:
1)因为正样本根据IoU进行Sort,不同的正样本在训练的时候就会有不同的优先级,所以用RS Loss训练的检测器就不再需要额外的辅助head 了。
2)由于RS Loss根据Classification Lofits区分出正负的样本,因此用RS Loss训练的检测器就能够处理比较极端的不平衡数据分布 ,而不需要采用启发式的采样。
3)此外,除了学习率,RS Loss不需要任何超参数调优 ,因为在RS Loss中没有需要调优的任务平衡系数。
作者将RS Loss在多个multi-stage, one-stage, anchor-based, anchor-free的目标检测和实例分割方法上进行了实验,证明了RS Loss的性能相比于Baseline能够有很大的提升。
3. 方法
3.1. Identity Update for Ranking-based Losses
使用ranking-based的损失函数能够使得模型达到一个更好的性能,但是由于rank是不可微的,所以在训练的时候也会存在一些问题。在本节中,我们先介绍一些现有的解决办法,然后在介绍本文提出的方法

3.1.1. 以前的方法
损失函数定义
Rank-based损失函数可以表示为:
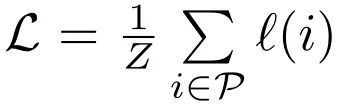
其中 是正样本的集合, 是在正样本上计算的误差项。
损失函数计算(Forward)
给定一组logits ,损失函数 的计算可以分为三步(如上图绿色剪头所示 ):
第一步: 计算 和 的差异值:

第二步: 基于上面得到的 ,每一对样本得到的差异项,可以被表示成可以一个基础项

其中 表示概率质量函数, 为rank-based损失函数。可以看出 需要i和j输出的pairwise-binary-ranking关系,这个关系由一个不可微的函数 决定(当x≥0时,H(x)=1;当x<0时,H(x)=0)。
第三步: 最后L就可以被归一化求和,得到最后的损失函数值 :

损失函数优化(Backward)
这一步的目的就是找到 ,然后通过反向传播更新模型的参数(如上图的橘色箭头所示 )。步骤1和步骤3是可微的,而基础项 不是可微函数。
根据链式法则用 来更新 , 就可以被表示为:

在AP Loss[1]和aLRP Loss[2]中都采用error-driven update,用 代表 ,其中 为目标基础项。
3.1.2. 本文的方法:Identity Update
上面的方法首先存在两个缺点:
1)D1 :产生的损失函数( )没有考虑 ,因此 时,这个函数的可解释性就不太好;
2)D2 :从上面的公式(2)中,我们可以看到,只有i为正样本,j为负样本的时候, 才是非0的,这就忽略了类内的损失。这部分损失在连续的标签中就显得尤为重要了。
损失函数定义
作者将损失函数定义为:

这样定义损失函数主要有两个好处:
1) 直接衡量了目标和期望误差之间的差异,产生一个可解释的损失值,解决了D1的问题;
2)不需要限制i是数据集中的正样本,这样的定义更加完整。
损失函数计算(Forward)
损失函数 的计算可以表示如下:
这样的处理方式,所得所有pair都是一个非零的损失,就避免了D2的问题。
损失函数优化(Backward)
这样的损失函数定义, 可以直接被计算,如下所示:
3.2. Rank & Sort Loss
为了能够用定位的质量来监督视觉检测器中的分类器,RS Loss将这个问题拆分成了两个任务:
1)Ranking task,它的目标是让每一个正样本的排名高于所有负样本的排名。
2)Sorting task,它的目的是能够根据连续的Ground Truth标签,让logits按降序排列。
3.2.1. 定义
给定logits和连续的Ground Truth标签(比如IoU),RS Loss为所有正样本上当前 和目标 的RS error的平均值:
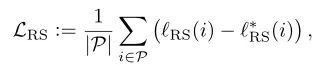
是当前rank error和当前sort error的总和:

3.2.2. 计算
相比于以前的方法, 多了一步正样本和正样本之间的计算,来增加类内的优先级差异性:


3.2.3. 优化
为了获得 ,作者根据Identity Update的原则,直接用 代替了 ,因此所有正样本的 为:

由于sort error 存在, 还包括了所有正样本的promotion和demotion排序的更新信号:

3.3. Analysis and Tuning-Free Design Choices
在原始的检测任务中,损失函数通常由三部分组成:
其中 为 Focal Loss, 为 GIoU Loss , 为 Cross-entropy Loss。
在本文中作者首先砍掉了centerness head,然后 RS Loss代替了 ,得到:
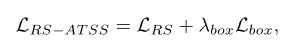

3.4. Training Different Architectures

在上图中,(a)是一个以前的Visual Detector的流程,包括可能来自多个阶段的多个子任务的head;(b)是使用RS Loss进行训练的Visual Detector;(c)展示了如何通过loss的值来平衡每个任务的权重,从而避免了调参。
4.实验
4.1. 目标检测
4.1.1.Multi-stage Object Detectors

在多阶段的目标检测器上,RS Loss在标准的Faster R-CNN上达到39.6 AP,并且超过了FPN 3.4AP,aLRP 2.2AP,Dynamic R-CNN 0.7AP。
4.1.2. One-stage Object Detectors

与Focal Loss比较,当两个网络在没有辅助head的情况下训练时,RS Loss提供大约 1 AP的增益。
4.1.3. Comparison with SOTA
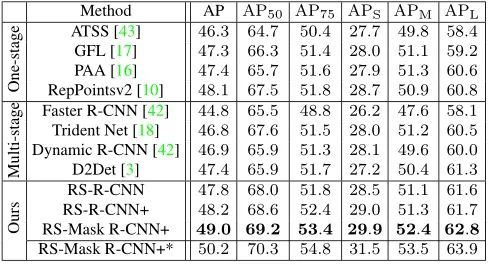
可以看出R-SR-CNN达到47.8 AP,比相似训练的Faster R-CNN和Dynamic R-CNN分别高出约3 AP和1 AP。
4.2. 实例分割
4.2.1. Multi-stage Instance Segmentation Methods
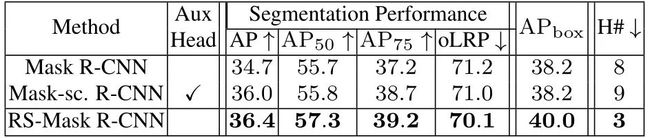
在COCO数据集上,基于Mask R-CNN模型,作为在检测和分割任务上都提升了大约2 AP。
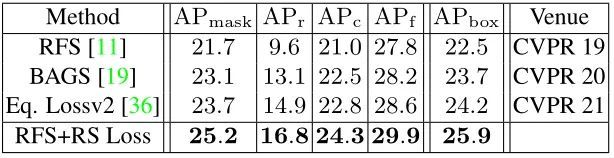
在长尾LVIS数据集上,通过将Mask R-CNN的 cross entropy loss换成RS Loss,提升了3.5 mask AP。
4.2.2. One-stage Instance Segmentation Methods

基于YOLACT,RS-YOLACT提升了1.5 mask AP和3.3box AP。

基于SOLOv2,RS-SOLOv2依旧能够在所有指标上都有所提升。
4.2.3. Comparison with SOTA
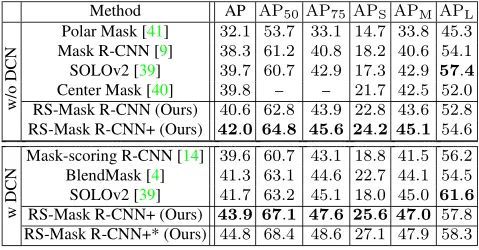
作者使用RS-Mask R-CNN(即带有RS Loss的Mask R-CNN)与SOTA方法进行比较。可以看出,使用ResNet101,RS-Mask R-CNN达到40.6 mask AP,将mask RCNN提高了2.3 mask AP,并显著优于所有SOTA方法(大约1 AP)。RS-Mask R-CNN+达到43.9 mask AP。
4.3. Ablation Experiments
4.3.1. Contribution of the components
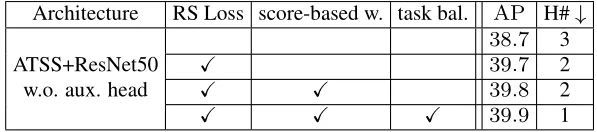
可以看出,用RS Loss代替Focal Loss显著提高了性能,基于score的加权作用较小,而基于value的任务平衡简化了调参。
4.3.2. Robustness to imbalance
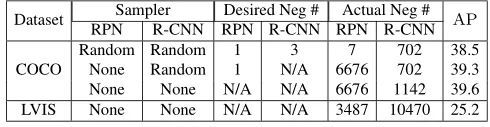
不需要调参,RS Loss能够成功训练具有不同程度imbalance的模型。
5. 总结
在本文中,作者提出了RS Loss,作为一个新的ranking-based的损失函数来训练目标检测和实例分割模型。不同于现有的ranking-based方法,RS Loss根据定位的质量对正样本进行了排序。基于RS Loss,作者采用了一种简单的、基于损失值的、无需调参的启发式算法来平衡visual detector中的所有head。最终,作者通过实验证明了RS Loss在一个检测和分割方法上的有效性。
参考文献
[1]. Chen, Kean, et al. "AP-loss for accurate one-stage object detection." IEEE Transactions on Pattern Analysis and Machine Intelligence (2020).
[2]. Oksuz, Kemal, et al. "A ranking-based, balanced loss function unifying classification and localisation in object detection." NeurIPS (2020).
本文亮点总结
1.Ranking-based的损失函数(代表有Average Precision (AP) Loss[1],average Localisation Recall Precision (aLRP) Loss[2]),相比于传统的损失函数,主要有两个优点:
1)它们直接优化performance的指标(比如AP),从而使训练和评估目标保持一致。另一方面,这也减少了超参数的数量,因为performance的指标通常不会有超参数的约束。
2)由于ranking-based的损失函数对错误的定义与传统的损失函数不同,因此这类损失函数往往对于“类别不平衡”的问题(比如说长尾问题)更加鲁棒。
2.RS Loss其实由两部分组成,一部分是Rank,还有一部分是Sort。Rank指的是根据Classification Lofits区分出正负的样本,Sort指的是根据IoU来对正样本进行排序。
论文PDF和代码下载
后台回复:RS Loss,即可下载上述论文PDF和代码
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看