机器学习笔记 - 基于Torch Hub的深度估计模型MiDaS
1、MiDaS
图像的深度估计从 2D 图像本身预测对象的顺序(如果图像以 3D 格式扩展)。这无疑是一项艰巨的任务,因为获取专门用于该领域的注释数据和数据集本身就是一项艰巨的任务。深度估计的使用范围很广,最明显的是在自动驾驶汽车领域,其中估计汽车周围物体的距离有助于导航。

MiDaS 是一种机器学习模型,可以根据任意输入图像估计深度。 下面是论文地址。
https://arxiv.org/pdf/1907.01341.pdf https://arxiv.org/pdf/1907.01341.pdf MiDaS 背后的研究人员以非常简单的方式解释了他们的动机。他们认为在处理包含现实生活问题时,在单个数据集上的训练模型不会很健壮。当创建实时使用的模型时,它们应该足够强大以处理尽可能多的情况和异常值。
https://arxiv.org/pdf/1907.01341.pdf MiDaS 背后的研究人员以非常简单的方式解释了他们的动机。他们认为在处理包含现实生活问题时,在单个数据集上的训练模型不会很健壮。当创建实时使用的模型时,它们应该足够强大以处理尽可能多的情况和异常值。
下面是MiDaS的实现地址,有兴趣可以参阅,这里不进行详细展开。
https://github.com/isl-org/MiDaShttps://github.com/isl-org/MiDaS
MiDaS 的创建者决定在多个数据集上训练他们的模型。这包括具有不同类型标签和目标函数的数据集。为了实现这一点,他们设计了一种在与所有真实表示兼容的适当输出空间中执行计算的方法。
这个想法非常巧妙,但作者必须仔细设计损失函数并考虑选择使用多个数据集所带来的挑战。由于这些数据集在不同程度上具有不同的深度估计表示,因此出现了固有的尺度模糊性和移位模糊性,正如该论文的作者所指出的那样。
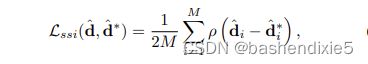
其中 ![]() 和
和 ![]() 是预测和基本事实的缩放和移位版本,
是预测和基本事实的缩放和移位版本, 定义了损失函数的特定类型。
定义了损失函数的特定类型。
现在,由于数据集很可能会遵循彼此不同的分布。因此,这些问题几乎是意料之中的。然而,作者为每个挑战提出了解决方案。最终产品是一个强大的深度估计器,它既高效又准确。在下图中,我们看到了论文中显示的一些结果。
 我们展示了如何利用来自多个互补来源的训练数据进行单视图深度估计,尽管深度范围和尺度不同且未知。 我们的方法可以实现跨数据集的强泛化。 顶部:输入图像。 中间:通过所提出的方法预测的逆深度图。 底部:或从新视点渲染的相应点云。 通过 Open3D 渲染的点云。
我们展示了如何利用来自多个互补来源的训练数据进行单视图深度估计,尽管深度范围和尺度不同且未知。 我们的方法可以实现跨数据集的强泛化。 顶部:输入图像。 中间:通过所提出的方法预测的逆深度图。 底部:或从新视点渲染的相应点云。 通过 Open3D 渲染的点云。
下面看看如何使用 MiDaS 模型找到自定义图像的逆深度。
2、创建配置文件
创建名为config.py的配置文件。
import torch
import os
# 定义根目录,后跟测试数据集路径
BASE_PATH = "dataset"
TEST_PATH = os.path.join(BASE_PATH, "test_set")
# 指定图像大小和批量大小
IMAGE_SIZE = 384
PRED_BATCH_SIZE = 4
# 确定设备类型
DEVICE = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# 定义保存输出的路径
OUTPUT_PATH = "output"
MIDAS_OUTPUT = os.path.join(OUTPUT_PATH, "midas_output")3、创建数据加载器
创建名为data_utils.py的配置文件。
# import the necessary packages
from torch.utils.data import DataLoader
def get_dataloader(dataset, batchSize, shuffle=True):
# create a dataloader and return it
dataLoader= DataLoader(dataset, batch_size=batchSize,
shuffle=shuffle)
return dataLoader4、使用 MiDaS 找到逆深度估计
这里还是使用猫狗大战的数据集进行简单测试。
环境运行需要安装timm模块,另外这个模型的Torch Hub的地址变了,所以运行的时候,需要临时修改下环境目录下Lib\site-packages\torch\hub.py文件,可以在124行临时插入repo_owner = 'isl-org',之后再删掉。另外就是预训练模型1.3G,很慢,所以下载之后上传到了云盘。
链接:https://pan.baidu.com/s/1pDK_QMcg5jaGlJjF7LRyZQ
提取码:d4ji创建midas_inference.py文件。
from data_utils import get_dataloader
import config
from torchvision.transforms import Compose, ToTensor, Resize
from torchvision.datasets import ImageFolder
import matplotlib.pyplot as plt
import torch
import os
# 使用测试转换管道创建测试数据集并初始化测试数据加载器
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), ToTensor()])
testDataset = ImageFolder(config.TEST_PATH, testTransform)
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
# 使用 torch hub 初始化 midas 模型
modelType = "DPT_Large"
midas = torch.hub.load("intel-isl/MiDaS", modelType)
# 将模型刷入设备并将其设置为评估模式
midas.to(config.DEVICE)
midas.eval()
# 初始化可迭代变量
sweeper = iter(testLoader)
# 抓取一批测试数据将图像发送到设备
print("[INFO] getting the test data...")
batch = next(sweeper)
(images, _) = (batch[0], batch[1])
images = images.to(config.DEVICE)
# 关闭自动毕业
with torch.no_grad():
# 从输入中获取预测
prediction = midas(images)
# 批量解压预测
prediction = torch.nn.functional.interpolate(
prediction.unsqueeze(1), size=[384, 384], mode="bicubic",
align_corners=False).squeeze()
# 将预测存储在一个 numpy 数组中
output = prediction.cpu().numpy()
# 定义行和列变量
rows = config.PRED_BATCH_SIZE
cols = 2
# 为子图定义轴
axes = []
fig=plt.figure(figsize=(10, 20))
# l遍历行和列
for totalRange in range(rows*cols):
axes.append(fig.add_subplot(rows, cols, totalRange+1))
# 为并排绘制基本事实和预测设置条件
if totalRange % 2 == 0:
plt.imshow(images[totalRange//2]
.permute((1, 2, 0)).cpu().detach().numpy())
else :
plt.imshow(output[totalRange//2])
fig.tight_layout()
# 构建 midas 输出目录(如果尚未存在)
if not os.path.exists(config.MIDAS_OUTPUT):
os.makedirs(config.MIDAS_OUTPUT)
# 将绘图保存到输出目录
print("[INFO] saving the inference...")
outputFileName = os.path.join(config.MIDAS_OUTPUT, "output.png")
plt.savefig(outputFileName)5、推理结果
猫狗大战数据集中的大多数图像都会在最前面放一只猫或狗。可能没有足够的背景图像,但 MiDaS 模型应该为我们提供一个输出,该输出决定性地描绘了前景中的猫或狗。这正是我们希望的推理图像中发生的情况。