论文学习笔记:使用知识库嵌入改进知识图谱上的多跳问答
公众号 系统之神与我同在
https://www.aclweb.org/anthology/2020.acl-main.412.pdfwww.aclweb.org/anthology/2020.acl-main.412.pdf
摘要
知识图(KG)是由实体作为节点,实体之间的关系作为类型化边组成的多关系图。 KG
问答(KGQA)任务的目的是回答对 KG 提出的自然语言查询。 多跳 KGQA 要求在 KG 的多个
边缘进行推理,以得出正确的答案。 KG 通常缺少许多链接,这给 KGQA 尤其是多跳 KGQA
带来了额外的挑战。 最近对多跳 KGQA 的研究已尝试使用相关的外部文本(即边缺失,使
用额外信息进行补充)来处理 KG 稀疏性,但这种方式并非一帆风顺。 在另一项研究中,
提出了 KG 嵌入方法,以通过执行丢失的链接预测来减少 KG 稀疏性。 此类 KG 嵌入方法尽
管非常相关,但迄今为止尚未针对多跳 KGQA 进行探索。 我们在本文中填补了这一空白,
并提出了 EmbedKGQA。 EmbedKGQA 在执行稀疏 KG 上的多跳 KGQA 方面特别有效(但是
当知识图谱不稀疏时,也应该能够超过基线)。 EmbedKGQA 还放宽了从预先指定的邻域
中选择答案的要求,这是先前的多跳 KGQA 方法实施的次优约束。 通过在多个基准数据集
上进行的广泛实验,我们证明了 EmbedKGQA 在其他最新基准上的有效性。(这里的多跳问
答很类似基于多路径的知识嵌入??不是的,并没有采用 PTransE 思想)
1 简介
知识图(KG)是由数百万个实体(例如,加利福尼亚州圣何塞等)及其之间的关系(例如,San Jose-cityInState-California)组成的多关系图。 一些大型 KG 的示例包括 Wikidata(谷歌,2013),DBPedia(Lehmann 等,2015),Yago(Suchanek 等,2007)和 NELL(Mitchell
等,2018)。 过去几年来,知识图问题解答(KGQA)已经成为重要的研究领域(Zhang 等
人,2018; Sun 等人,2019a)。 在 KGQA 系统中,给定自然语言(NL)问题和 KG,则根据
在 KG 上下文中对该问题的分析得出正确答案。

图 1:稀疏和不完整 KG 中知识图谱(KGQA)上的多跳 QA 面临的挑战:不完整 KG 中边缘
的类型具有流派(Gangster No. 1,犯罪),这使得回答输入 NL 更加困难 问题,因为 KGQA
模型可能需要在 KG 上的更长路径上进行推理(以粗体标记)。 现有的多跳 KGQA 方法还施
加了启发式邻域限制(图中阴影区域),(即本来就信息缺失,不足,再限制搜索范围,问
题更难解决,但是不限制范围,搜索复杂度太大,也不行)这常常使真实答案(在本例中为
犯罪)难以企及。 我们提出的方法 EmbedKGQA 通过在多跳 KGQA 期间利用输入 KG 的嵌入
来克服这些限制(1 即使用训练好的,语义丰富的知识图谱嵌入,用于表示稀疏知识图谱上
的节点,进行多跳推理??不就这样的。是直接面向目标 KG 进行表示学习。2 在训练知识
图谱时,学习的嵌入的数据集时稀疏的知识图谱(即目标),还是稠密的质量高的知识图谱?
是直接面向目标知识图谱的。3 是不是像词向量一样,先通过词向量预训练学习词嵌入,然
后在应用下游任务时,通过查表寻找相应的词向嵌入的??不是的。4 如果是这样的,问题
来了知识图谱的节点和关系非常多,可以说是无穷,不像词嵌入一样,单字或者常用的词语
是有限的,是可以做到的。)。 有关更多详细信息,请参见图 2 和第 4 节。
在多跳 KGQA 中,系统需要对 KG 的多个边缘执行推理以推断出正确的答案。 KG 通常
不完整,这给 KGQA 系统带来了额外的挑战,尤其是在多跳 KGQA 的情况下。 最近的方法
已经使用外部文本语料库来处理 KG 稀疏性(Sun 等人,2019a,2018)。 例如,(Sun 等
人,2019a)中提出的方法从 KG 构造了一个特定于问题的子图,然后用支持的文本文档对
其进行了扩充。
然后,在此扩展子图上应用图 CNN(Kipf 和 Welling,2016),以得出最终答案。 不幸
的是,相关文本语料的可用性和识别本身就是一个挑战,这限制了这种方法的广泛应用。 而
且,这些方法还强加了预先确定的启发式邻域大小限制,需要从中选择真实答案。 这常常
使真正的答案超出了模型的选择范围。
为了说明这些观点,请考虑图 1 所示的示例。在此示例中,Louis Mellis 是输入 NL 问题
中的主要实体,而 Crime 是我们希望模型选择的真实答案。 如果边缘具有类型(帮派编号
1,犯罪)存在于 KG 中,那么可以很容易地回答这个问题。 但是,由于 KG 缺少这种优势
(与不完整和稀疏的 KG 相似),KGQA 模型可能需要在 KG 上更长的路径上进行推理(由图
中的粗体边缘标记)。 此外,KGQA 模型将邻域大小设置为 3 跳,这使真正的答案“犯罪”
触手可及。
在另一项研究中,已有大量工作利用 KG 嵌入来预测 KG 中的缺失链接,从而降低 KG 稀
疏度(Bordes 等人,2013; Trouillon 等人,2016; Yang 等人。 ,2014a; Nickel 等,2011)。
KG 嵌入方法学习 KG 中实体和关系的高维嵌入,然后将其用于链接预测。 尽管具有很高的
相关性,但对于多跳 KGQA 仍未使用 KG 嵌入方法–我们在本文中填补了这一空白。 特别是,
我们提出了 EmbedKGQA,这是一种利用 KG 嵌入执行多跳 KGQA 的新颖系统。 我们在本文
中做出以下贡献:
1.我们提出了 EmbedKGQA,这是一种用于多跳 KGQA 任务的新方法。 据我们所知,
EmbedKGQA 是将 KG 嵌入用于此任务的第一种方法。(但是关于多跳(或者)多路径知识
图谱嵌入老早就有研究了,问题就在于在研究多路径的知识图谱嵌入的时候,结构信息要能
够保证,即邻居节点信息聚合,不能只是关注路径问题(深度搜索),还要兼顾邻居节点的
结构信息(广度搜索)) EmbedKGQA 在执行稀疏 KG 上的多跳 KGQA 方面特别有效。
2. EmbedKGQA 放宽了从预先指定的本地邻域进行选择的要求(即放宽搜索范围,这是必
然的,因为进行多跳推理,邻居范围的扩大是需要的),这是以前的方法对该任务施加的不
希望的约束。
3.通过在多个真实数据集上进行的广泛实验,我们证明了 Embed KGQA 在最新基准上的
有效性。(多路径嵌入无论是是有用于下游任务,都是增强知识图谱推理以及更大范围信息
的必要方法,可以直接拿来用于知识图谱表示)
我们已经使 EmbedKGQA 的源代码能够促进可重复性。

图 2:EmbedKGQA 概述,这是我们提出的基于知识图的多跳 QA 方法(KGQA)。EmbedKGQA
具有三个模块:(1)KG 嵌入模块(第 4.2 节)学习输入 KG 中所有实体的嵌入,(2)问题嵌入模块(第 4.3 节)学习问题的嵌入,以及(3) 选择模块(第 4.4 节)通过合并问题和
关系相似性得分来选择最终答案。 EmbedKGQA 对嵌入的使用使它在处理 KG 稀疏性方面
更加有效。 此外,由于 EmbedKGQA 会将所有实体视为候选答案(但是搜索范围是不是有
点大??在下文会介绍范围缩减的方法),因此,它不会受到现有的多跳 KGQA 方法所带来
的局限性的邻里不可达问题的困扰。 请参阅第 4 节,了解 EmbedKGQA 的详细说明。()
2 相关工作
KGQA:在先前的工作中(Li 等人,2018),TransE(Bordes 等人,2013)已使用嵌入来回
答基于事实的问题。 但是,这需要为每个问题加上地面真相关系标签,并且不适用于多跳
问题回答。 在另一项工作中(Yih 等人,2015)和(Bao 等人,2016),建议提取一个局部
子图来回答这个问题。 在(Bordes et al。,2014a)中提出的方法中,为头部实体生成的子
图被投影在高维空间中以进行问题回答。 内存网络也已被用来学习 KG 中存在的事实的高
维嵌入来执行 QA(Bordes 等人,2015)。 类似的方法(Bordes 等,2014b)在训练过程中
学习问题和相应三元组之间的相似性功能,并在测试时对所有候选三元组进行评分。(Yang
等,2014b)和(Yang 等,2015)利用基于嵌入的方法将自然语言问题映射为逻辑形式。 诸
如(Dai 等人,2016; Dong 等人,2015; Hao 等人,2017; Lukovnikov 等人,2017; Yin 等人,
2016)之类的方法利用神经网络学习评分功能来对候选人进行排名 一阵 sw。 诸如
Mohammed 等人,2017; Ture 和 Jojic,2016)的一些作品认为每个关系都是通俗易懂的,而
将质量检查模型作为分类问题。
将这些方法扩展为多跳问题解答并非易事。
最近,有一些工作将文本语料库作为 KG 的补充知识来回答有关 KG 的复杂问题(Sun et
al。,2018,2019a)。 在 KG 不完整的情况下,此类方法很有用。 但是,这会导致质量检
查系统的复杂性提高到另一个水平,并且文本语料库可能并不总是可用。
KG 完成方法:使用 KG 嵌入的知识图谱中的链接预测已成为近年来研究的热门领域。
通用框架是为 KG 中的一组三元组(h,r,t)定义得分函数,并以这样的方式约束它们:
正确三元组的得分高于错误三元组的得分。
RESCAL(Nickel 等人,2011)和 DistMult(Yang 等人,2015)学习一种分数函数,该函
数包含头部实体和尾部实体向量之间的双线性乘积以及一个关系矩阵。 ComplEx(Trouillon
et al。,2016)表示复杂空间中的实体向量和关系矩阵。 SimplE(Kazemi 和 Poole,2018)
和 TuckER(Balazevi ˇ c´et al。,2019)分别基于规范化的 Polyadic(CP)分解(Hitchcock,
1927)和 Tucker de composition(Tucker,1966)。
TransE(Bordes 等人,2013)将实体嵌入到高维真实空间中,并在头和尾实体之间进行
翻译。 另一方面,RotatE(Sun 等人,2019b)投影复杂空间中的实体,并且关系表示为复
杂平面中的旋转。
ConvE(Dettmers et al。,2018)利用卷积神经网络来学习头部实体,尾部实体和关系之
间的评分功能。
InteractE(Vashishth et al。,2019)通过增加功能交互来改善 ConvE。
3 背景
知识在本节中,我们正式定义一个知识图(KG),然后描述不完整 KG 上的链接预测任
务。 然后,我们描述 KG 嵌入并解释 ComplEx 嵌入模型。3.1 知识图谱
给定一组实体 E 和关系 R,知识图谱 G 是一组三元组 K,使得 K⊆E×R×E。 一个三元组表示
为(h,r,t),其中 h,t∈E 分别表示对象和对象实体,r∈R 是它们之间的关系。
3.2 链接预测
在链接预测中,如果知识图不完整,则任务是预测哪些未知链接有效。(难道不应该是
通过推理补全吗?我们的目的不是通过推理对知识图谱补全,而是利用推理在连接缺失的情
况在,进行尾实体预测。不过,连接预测与知识图谱补全,方法类似) KG 嵌入模型通过
计分函数φ来实现此目的,该函数分配分数 s =φ(h,r,t)∈R,该分数指示三元组是否为
真,目的是能够正确地对所有缺失的三元组进行计分。(成了三元组真假分类问题了吗?是
的,对三元组尾实体的预测,成了二元分类问题)
3.3 知识图嵌入
对于每个 e∈E 和 r∈R,知识图嵌入(KGE)模型会生成 ee∈Rde 和 er∈Rdr,其中 ee
和 er 分别是维向量和 dr 维向量。 每种嵌入方法还具有评分函数φ:E×R×E→R 以为可能的
三元组(h,r,t),h,t∈E 和 r 分配一些分数φ(h,r,t)。 ∈R
以如下方式训练模
型:对于每个正确的三元组(h,r,t)∈K 和不正确的三元组(h0,r0,t0)6∈K,模型分
配分数,使得φ(h,r,t)> 0 并且φ(h0,r0,t0)<0。评分函数通常是(eh,er,et)的
函数。


3.3.1 ComplEx 嵌入
ComplEx(Trouillon 等,2016)是一种张量因子化方法,将关系和实体嵌入复杂空间。 给
定 h,t∈E 和 r∈R,ComplEx 生成 eh,er,et∈Cd 并定义一个评分函数:

4 EmbedKGQA:建议的方法
在本节中,我们首先定义 KGQA 的问题,然后描述我们的模型。4.1 问题陈述
让 E 和 R 分别是 KG G 中所有实体和关系的集合,而 K⊆E×R×E 是所有可用 KG 事实的集
合。 KGQA 中的问题涉及给定自然语言问题 q 和问题中存在的主题实体 eh∈E,任务是提
取正确回答问题 q 的实体 et∈E。
4.1.1 EmbedKGQA
概述我们在这样的环境中工作:数据集中没有细粒度的注释,例如问题类型或确切的逻
辑推理步骤。 例如,合作演员是已加星标 1 和已加星标关系的组合,但是我们的模型不需
要此注释。
EmbedKGQA 使用知识图嵌入来回答多跳自然语言问题。 首先,它学习嵌入空间中 KG
的表示。 然后给定一个问题,它学习问题嵌入。 最后,它将这些嵌入结合起来以预测答案。
在以下各节中,我们介绍 Em bedKGQA 模型。 它由 3 个模块组成:
(1) KG 嵌入模块为 KG 中的所有实体创建嵌入。
(2)问题嵌入模块可以找到问题的嵌入。
(3)答案选择模块可以减少求职者的人数。
4.2 KG 嵌入模块
针对 KG 中的所有 h,t∈E 和所有 r∈R 训练 ComplEx 嵌入,以使 eh,er 等。 实体嵌入
用于学习头部实体,问题和答案实体之间的三重评分功能。 根据 QA 训练集中 KG 实体的覆
盖范围,可以将在此处学习的实体嵌入保持冻结状态,或者在后续步骤中对其进行微调。
4.3 问题嵌入
模块该模块将自然语言问题 q 嵌入到固定维矢量 eq∈Cd。 这是使用前馈神经网络完成
的,该网络首先使用 RoBERTa(Liu 等人,2019)将问题 q 嵌入到 768 维向量中。 然后将其
通过具有 ReLU 激活的 4 个完全连接的线性层,最后投影到复杂空间 Cd 上。
给定问题 q,主题实体 h∈E 和答案实体 A⊆E 的集合,它学习问题的嵌入方式为:

对于每个问题,将使用所有候选答案实体 a0∈E 计算分数φ(.)。通过最小化分数的 S 形与目标标签之间的二进制交叉熵损失来学习模型,其中目标标签为 1 为正确答案,否则为 0。
当实体总数很大时,将进行标签平滑。
4.4 答案选择模块
推断时,模型针对所有可能的答案 a0∈E 对(头部,问题)对进行评分。对于相对较小
的 KG(如 MetaQA),我们仅选择得分最高的实体。
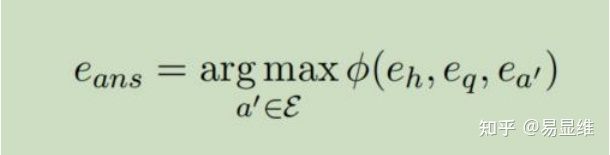
但是,如果知识图很大,则修剪候选实体可以显着提高 EmbedKGQA 的性能。 下一节将介
绍修剪策略。
4.4.1 关系匹配
与 PullNet(Sun et al。,2019a)类似,我们学习了得分函数 S(r,q),该函数对给定
问题 q 的每个关系 r∈R 进行排名。 令 hr 是关系 r 的嵌入,q0 =(,w1,..,w | q |,
s>)是输入到 RoBERTa 的有问题的单词序列 q。
评分函数定义为 RoBERTa 的最后一个隐藏层的最终输出(hq)和关系 r(hr)的嵌入的点
积的 S 型。
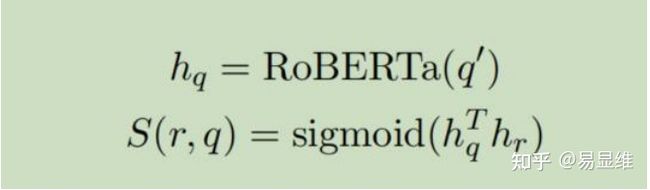
我们使用关系得分和 ComplEx 得分的线性组合来找到答案实体。

5 实验细节
在本节中,我们首先描述评估方法的数据集,然后说明实验设置和结果。

5.1 数据集
1. MetaQA(Zhang 等人,2018)数据集是大型多跳 KGQA 数据集,在电影中主要有超过 40
万个问题。 它具有 1 跳,2 跳和 3 跳问题。 在我们的实验中,我们使用了“香草”版本的问
题。 除了 QA 数据外,MetaQA 还为 KG 提供了 135k 个三元组,43k 个实体和 9 个关系(这
里的关系有那么少吗?这里的关系是三元组中的关系 R 吗?)。
2. WebQuestionsSP(tau Yih 等人,2016)是一个较小的 QA 数据集,包含 4,737 个问题。 此
数据集中的问题是 1 跳和 2 跳问题,可通过 Free base KG 回答。 为了便于实验,我们将 KB
严格限制为 Freebase 的子集,其中包含与 We bQuestionsSP 问题中提到的任何实体相距 2 跳
以内的所有事实。 我们进一步修剪它只包含数据集中提到的那些关系。 这个较小的 KB 具
有 180 万个实体和 570 万个三元组。
5.2 基线
我们将模型与 WebQuestionsSP 数据集的键值内存网络(Miller 等人,2016),GraftNet
(Sun 等人,2018)和 Pullnet(Sun 等人,2019a)进行了比较。 对于 MetaQA 数据集,我
们还与 VRN 进行了比较(Zhang 等人,2018)。
这些方法实现了多跳 KGQA,并且除了 VRN 之外,还使用其他文本语料库来减轻 KG 稀疏
性问题。
•VRN(Zhang 等人,2018)使用变分学习算法在 KG 上执行多跳 QA。
•键值存储网络(KVMem)(Miller 等人,2016)是尝试通过对不完整 KB 进行文本扩充
来进行质量检查的首批模型之一。 它维护一个存储表,该表存储 KB 事实和编码为键值对
的文本,并将其用于检索。•GraftNet(Sun 等,2018)使用启发式方法创建包含文本语料库中的 KG 事实,实体和句
子的特定于问题的子图,然后使用 CNN 图的变体(Kipf 和 Welling,2016)对其进行推理。 。
•PullNet(Sun 等人,2019a)还创建了特定于问题的子图,但不是使用启发式方法,而
是从数据中“提取”事实和语句以创建更相关的子图。 它还使用图 CNN 方法执行推理。
完整的 KG 设置是质量检查最简单的设置,因为创建数据集的方式是答案始终存在于 KG
中,并且路径中没有丢失的链接。 但是,这不是一个现实的设置,并且质量检查模型也应
该能够在不完整的 KG 上工作。 因此,我们通过随机删除 KB 中的三元组的一半来模拟不完
整的 KB(我们随机删除一个概率为 0.5 的事实)。 在本文中,我们将此设置称为 KG-50,
而将完整 KG 设置称为 KG-Full。
在下一节中,我们将回答以下问题:Q1。知识图嵌入可以用于执行多跳 KGQA 吗? (第
5.3 节)Q2。 当标头实体和答案实体之间没有直接路径时,可以使用 EmbedKGQA 回答问题
吗?
(第 5.4 节)Q3。 答案选择模块对我们模型的最终性能有多大帮助?
(第 5.5 节)
5.3 KGQA 结果
在本节中,我们将模型与 MetaQA 和 WebQuestionsSP 数据集上的基线模型进行了比较。
5.3.1 对 MetaQA 的分析
MetaQA 对 1 跳,
2 跳和 3 跳问题的数据集具有不同的分区。在完整的 KG 设置(MetaQA
KG-Full)中,我们的模型与 2 跳问题的最新技术比较,并为 3 跳问题建立了最新技术。
EmbedKGQA 的执行情况与预期为 1 跳问题的情况类似,这是因为答案节点直接连接到头
节点,并且能够从问题中学习嵌入的对应关系。 另一方面,在 2 跳和 3 跳问题上的表现表
明 EmbedKGQA 能够从相邻边缘推断出正确的关系,因为 KG 嵌入可以建模关系的组成。
Pullnet 和 GraftNet 的表现也很相似,因为答案实体通常位于问题子图中。
如上一节所述,我们还在非完整 KG 设置下测试了我们的方法。 在这里,我们发现,
与整个 KG 设置相比,所有基线的准确性均显着降低,而 EmbedKGQA 则可实现最先进的性
能。 这是因为 MetaQA KG 相当稀疏,对于 43k 个实体只有 135k 个三元组。 因此,当删除
50%的三元组时(如 MetaQA KG-50 中所做的那样),该图将变得非常稀疏,每个实体节点
平均只有 1.66 个链接。
这导致许多问题的首部实体节点到其答案节点的路径更长(> 3)。 因此,需要特定问
题的子图构造的模型(GraftNet,PullNet)无法在其生成的子图中调用答案实体,因此效果
较差。 但是,只有在包含其他文本语料库之后,它们的性能才会提高。 另一方面,Em
bedKGQA 并不将自身限制为子图,并且利用 KG em 床品的链接预测属性,EmbedKGQA 能够
推断出缺失链接上的关系。
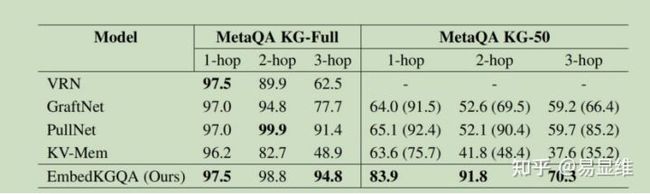
表 2:MetaQA 数据集的结果。 所有基线结果均取自 Sun 等。 (2019a)。 我们已经考虑了全 KG(MetaQA KG 满)和 50%KG(MetaQA KG-50)的设置。 该表中报告的数字为 hits @
1。 括号中的数字对应于使用文本来增加不完整 KG(MetaQA KG-50)的设置。 有关更多详
细信息,请参阅第 5.3.1 节。
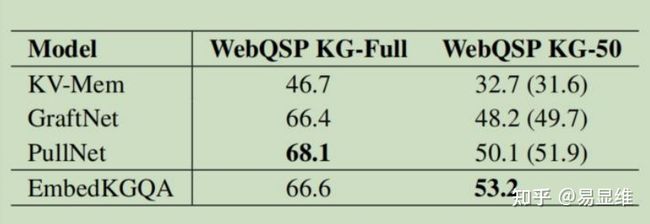
表 3:WebQuestionsSP 数据集的性能。 所有基线结果均取自 Sun 等。 (2019a)。 报告
的值为 hits @ 1。 括号中的数字对应于使用文本来增加不完整 KG(WebQSP KG-50)的设置。
有关更多详细信息,请参见第 5.3.2 节。
5.3.2 在 WebQuestionsSP 上进行分析 WebQuestionsSP 的培训示例相对较少,但使用较大的
KG(Freebase)作为背景知识。 这使多跳 KGQA 变得更加困难。 由于 KG 的所有实体均未
包含在训练集中,因此有必要在 KG 嵌入学习阶段(第 4.2 节)学习它们之后冻结实体嵌入。
WebQuestionsSP 的结果(表 3)突显了一个事实,即使使用少量培训示例,EmbedKGQA 仍
可以学习良好的问题嵌入,从而可以推断出回答问题所需的多跳路径。
我们在 WebQSP KG-50 上采用的方法优于包括 PullNet 在内的所有基线,PullNet 使用了额
外的纺织品信息,并且是最新模型。
即使 WebQuestionsSP 的问题较少,EmbedKGQA 仍可以学习良好的问题嵌入,从而推断
KG 中的任务链接。 这可以归因于这样的事实,即相关的和必要的信息是通过 KG 嵌入隐式
捕获的。
5.4 缺少链接的 KG 上的 QA
最先进的 KGQA 模型(如 PullNet 和 GraftNet)要求在知识图谱中出现头部实体和答案
实体之间的路径以回答问题。 例如,在 PullNet 中,答案仅限于提取的问题子图中存在的实
体之一。(在缺失链接信息的情况下,子图查询方法很容易使得真实答案超出子图范围,难
以解决缺失连接的多跳问答问题)
对于仅存在原始三元组的 50%的不完全 KG 案例,PullNet(Sun 等人,2019a)报告称
MetaQA 1hop 数据集的召回率为 0.544。 这意味着,只有 54.4%的问题中,所有答案实体都
存在于提取的问题子图中,这对模型在这种情况下可以回答多少个问题进行了严格限制。
另一方面,EmbedKGQA 使用知识图嵌入而不是局部子图来回答问题。
它使用头嵌入和
问题嵌入,隐式捕获头节点周围所有观察到的和未观察到的链接的知识。
由于知识图嵌入
的链接预测属性,这是可能的。
因此,与其他 QA 系统不同,即使头部和答案实体之间没有路径,我们的模型也应该能够回答 KG 中是否有足够的信息来预测该路径(见图 1)。 我们设计了一个实验来测试我们
模型的这种能力。 对于 MetaQA 1-hop 数据集验证集合中的所有问题,我们从知识图中删除
了所有可直接用于回答问题的三元组。
例如,假设验证集中的问题是“ [PK]是什么语言”,我们从 KG 中删除了三元组(PK,用语
言,印地语)。
数据集还包含相同问题的解释,例如,“电影[PK]的语言是什么”和“电影[PK]的语言是什
么”。 我们还从训练数据集中删除了验证集问题的所有措辞,因为我们只想评估模型的 KG
完成属性,而不是语言通用化。
在这种情况下,我们希望仅依靠子图检索的模型就能实现 0 hits @ 1。
但是,在这种情况下,我们的模型提供了 29.9 hits @ 1 更好的命中率。 这表明我们的模
型可以捕获 ComplEx 嵌入的 KG 完成属性,并将其应用于回答否则无法实现的问题。
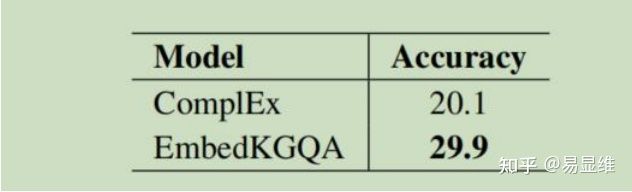
表 4:在 MetaQA 1-hop 上针对头实体与答案实体之间没有链接的实验的 QA 结果。 我们将
结果与已知问题黄金关系的 KG 完成方法进行了比较。
详情在 5.4 节中提供。
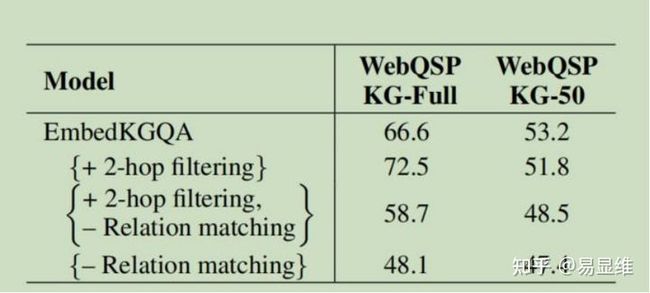
表 5:该表显示了关系匹配模块的重要性(第 4.4.1
节),以及基于邻居的过滤对 We
bQuestionsSP 数据集中的 EmbedKGQA 的影响。 EmbedKGQA 本身包含关系匹配模块。 在
这里,我们尝试看到消除关系匹配模块并在答案选择期间添加 2 跳邻域过滤的效果。 有关
更多详细信息,请参阅第 5.5 节。(这里的 2 跳邻居过滤指的是什么呢?即在搜索答案时,
只关注 2 跳(阶)领域的实体节点(尾实体的候选范围))
此外,如果我们知道与每个问题相对应的关系,则一跳 KG QA 的问题与不完整知识图
中的 KG 完成相同。 使用与上述相同的训练 KG,并使用删除的三元组作为测试集,我们使
用 KG 嵌入进行尾部预测。 在这里,我们获得了 20.1 个匹配数@ 1。 得分较低的原因是
ComplEx 嵌入仅使用 KG,而我们的模型也使用了 QA 数据-它本身就代表了知识。 我们的模
型首先在 KG 上训练,然后使用这些嵌入来训练 QA 模型,因此它可以利用 KG 和 QA 数据中的知识。
5.5 答案选择模块的效果
我们通过消除关系匹配模块来分析答案选择模块(第 4.4 节)对 WebQues tionsSP 数据
集中的 EmbedKGQA 的影响。 此外,为了与将答案限制在 KG 中的邻居区的其他方法进行比
较(Sun 等人(2019a),Sun 等人
(2018)),我们尝试将答案实体的候选日期集限制
为仅头实体的 2 跳邻居。结果可以在表 5 中看到。如我们所见,在 WebQSP KG-full 和 WebQSP
KG-50 设置下,关系匹配对 EmbedKGQA 的性能都有重大影响。
而且,如前所述,WebQSP KG(自由子集)的实体比 MetaQA(1.8M 对 MetaQA 中的 134k)
具有更大的数量级,并且可能的答案数量很多。 因此,在 WebQSP KG-Full 的情况下,减少
对头部实体的 2 跳邻域的答案集可提高性能。但是,这导致 WebQSP KG-50 的性能下降。这
是因为将答案限制在不完整的 KG 上的 2 跳邻域中可能导致答案在候选者中不存在(请参见
图 1)。
总而言之,我们发现关系匹配是 EmbedKGQA 的重要组成部分。 此外,我们建议在答案
选择过程中的 n 跳过滤可能会包含在 EmbedKGQA 之上,以用于相当完整的 KG。
6 结论
在本文中,我们提出了 EmbedKGQA,这是一种用于多跳 KGQA 的新方法。 KG 通常完
整且稀疏,这给多跳 KGQA 方法带来了额外的挑战。 最近针对该问题的尝试已尝试通过使
用其他文本语料库来解决完整性问题。 但是,相关文本语料库的可用性通常受到限制,从
而降低了此类方法的广泛适用性。 在另一项研究中,提出了 KG 嵌入方法以通过执行丢失
的链接预测来减少 KG 稀疏性。 EmbedKGQA 利用 KG 嵌入的链接预测属性来缓解 KG 不完
整性问题,而无需使用任何其他数据。 它训练 KG 实体嵌入并使用它学习问题嵌入,在评
估过程中,它再次对所有实体(头部实体,问题)进行评分,并选择得分最高的实体作为答
案。
EmbedKGQA 还克服了现有多跳 KGQA 方法所施加的有限的邻域大小约束所带来的缺点。
嵌入式 KGQA 在多个 KGQA 设置中均实现了最先进的性能,这表明可以利用 KG 嵌入的链接
预测属性来缓解多跳 KGQA 中的 KG 不完整问题。