Pytorch学习笔记(三)
目录
nn_loss.py
nn_loss_network.py
nn_optimizer.py
nn_loss.py
#损失函数和反向传播
#计算实际输出与目标之间的差距;为我们更新输出提供一定的依据(反向传播)
import torch
from torch.nn import L1Loss, CrossEntropyLoss
from torch.nn import MSELoss
inputs=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,2,5],dtype=torch.float32)
#RuntimeError: mean(): could not infer output dtype. Input dtype must be either a floating point or complex dtype. Got: Long
#reshape是为了添加维度,原来的tensor是二维的,只有行和列的信息
#reshape后添加batch_size、channels信息
inputs=torch.reshape(inputs,(1,1,1,3))
targets=torch.reshape(targets,(1,1,1,3))
# 平均绝对误差MAE 一般用于回归
#Creates a criterion that measures the mean absolute error (MAE) between each element in the input x and target y.
#torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
# reduction表示L1Loss的两种计算方式mean/sum,默认为‘mean’
#reduction='mean'
loss_mae_mean=L1Loss()
result_mae_mean=loss_mae_mean(inputs,targets)
print("loss_mae_mean:",result_mae_mean) # loss_mae_mean: tensor(0.6667)
#reduction='sum'
loss_mae_sum=L1Loss(reduction='sum')
result_mae_sum=loss_mae_sum(inputs,targets)
print("loss_mae_sum:",result_mae_sum) #loss_mae_sum: tensor(2.)
# 均方误差MSE 一般用于回归
loss_mse=MSELoss()
result_mse=loss_mse(inputs,targets)
print("loss_mse:",result_mse)#loss_mse: tensor(1.3333)
# 交叉熵CrossEntropyloss 一般用于分类
#loss(x,class)=-log(exp(x[class])/∑exp(x[j]))=-x[class]+log(∑exp(x[j])
#其中x是指每个类别的预测输出值output,其是一个数组形式 eg:output:[0.1,0.2,0.3] class是指真实target值0/1/2
# 可以从最大似然的角度理解交叉熵
# 对于二分类问题
# 根据逻辑斯谛回归模型:P(Y=1|x)=exp(w.x)/(1+exp(w.x)) P(Y=0|x)=1/1+exp(w.x)
# 设P(Y=1|x)=exp(w.x)/(1+exp(w.x))=π(x),P(Y=0|x)=1/1+exp(w.x)=1-π(x) 即预测概率含参数
# 似然函数为∏[π(xi)yi[1-π(xi)]1-yi 其中yi 1-yi为指数
# 当target yi=0时,该式剩下1-π(xi),即预测yi=0的概率(output值);当target yi=1时,该式剩下π(xi),即预测出yi=1的概率(output值)
# 所以似然函数可以理解为正确分类的概率 似然函数值越大表示模型预测值越接近真实值
# 对数似然函数即对似然函数取对数得到 其值同样与正确分类的概率成正比
# 所以损失函数可以取对数似然函数的相反数 对其求极小值,得到参数的估计值(当损失函数越小时 正确分类的概率就越大)
# Loss=-∑[yilogπ(xi)+(1-yi)log(1-π(xi))]=-∑[yi(w.xi)-log(1+(w.xi))] Note:yi是真实标签target w.xi是网络预测值output
#交叉熵内置函数是现将x经过softmax函数处理之后再计算误差的,所以输入的x不是概率形式也是可以的
x=torch.tensor([0.1,0.2,0.3]) #三个class分别对应的output score
y=torch.tensor([1]) #给定target=1
x=torch.reshape(x,(1,3)) #Input shape:(N,C) batchsize=1,class=3
loss_cross=CrossEntropyLoss()
result_loss_cross=loss_cross(x,y)
print("loss_cross:",result_loss_cross)#loss_cross: tensor(1.1019)nn_loss_network.py
# 使用nn_seq.py中搭建好的神经网络
# 代码流程:
# 加载数据集 搭建网络 定义loss计算方式 输入数据 计算损失函数 反向传播
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
#加载数据集
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=1)
#搭建神经网络
class myModel(nn.Module):
#model结构:conv1-maxpool1-conv2-maxpool2-conv3-maxpool3-flatten-linear1-linear2
def __init__(self):
super(myModel, self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10),
)
#层与层之间用逗号分隔
def forward(self,x):
x=self.model1(x)
return x
#定义神经网络计算loss方式
#数据集用来解决分类问题 用交叉熵计算loss
loss=nn.CrossEntropyLoss()
#数据输入
model=myModel()
for data in dataloader:
imgs,targets=data
outputs=model(imgs)
# #看outputs\targets是什么样子,来决定用什么loss函数
# print("outputs:",outputs)
# print("targets:",targets)
# #选择其中一个来看
# #outputs: tensor([[-0.0268, -0.0497, -0.0931, 0.0797, 0.1244, -0.0817, 0.0271, 0.1708,-0.0522, 0.0187]], grad_fn=)
# #targets: tensor([6])
# #outputs为10个类别的得分 targets为数据集中每个imgs对应class的编号
# 计算loss
result_loss=loss(outputs,targets)
# print("result_loss:",result_loss)
# 反向传播backward
# Note:backward的对象是计算过的result_loss变量 不是loss
# outputs=model(imgs) result_loss=loss(outputs,targets) 所以可以得到result_loss是model中所含参数的一个函数
result_loss.backward() #计算出loss函数对每个参数的梯度
print("it's fine")
nn_optimizer.py
# 使用nn_seq.py中搭建好的神经网络
# 代码流程:
# 加载数据集 搭建网络 定义loss计算方式 设置优化器 输入数据 计算损失函数 反向传播
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
#加载数据集
dataset=torchvision.datasets.CIFAR10("../dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=1)
#搭建神经网络
class myModel(nn.Module):
#model结构:conv1-maxpool1-conv2-maxpool2-conv3-maxpool3-flatten-linear1-linear2
def __init__(self):
super(myModel, self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10),
)
#层与层之间用逗号分隔
def forward(self,x):
x=self.model1(x)
return x
#定义神经网络计算loss方式
#数据集用来解决分类问题 用交叉熵计算loss
loss=nn.CrossEntropyLoss()
model=myModel()
# 设置优化器
optim=torch.optim.SGD(model.parameters(),lr=0.001)
#外循环实现对整个数据集学习多轮
for epoch in range(20):
#内循环是对整个数据集学习一轮 #数据输入-计算输出-计算loss-backward计算梯度-优化参数
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=model(imgs)
# #看outputs\targets是什么样子,来决定用什么loss函数
# print("outputs:",outputs)
# print("targets:",targets)
# #选择其中一个来看
# #outputs: tensor([[-0.0268, -0.0497, -0.0931, 0.0797, 0.1244, -0.0817, 0.0271, 0.1708,-0.0522, 0.0187]], grad_fn=)
# #targets: tensor([6])
# #outputs为10个类别的得分 targets为数据集中每个imgs对应class的编号
# 计算loss
result_loss=loss(outputs,targets)
# print("result_loss:",result_loss)
optim.zero_grad() # 在进行参数优化的循环中 要把上一个循环中每个参数对应的梯度清零 若不清零,梯度会进行累加
result_loss.backward() # 反向传播,得到每个要更新参数对应的梯度
optim.step() # 每个参数会根据上一步得到的梯度进行优化
# Note:backward的对象是计算过的result_loss变量 不是loss
# outputs=model(imgs) result_loss=loss(outputs,targets) 所以可以得到result_loss是model中所含参数的一个函数
# print(result_loss)
running_loss=running_loss+result_loss #一轮学习中数据集中所有数据预测误差的总和
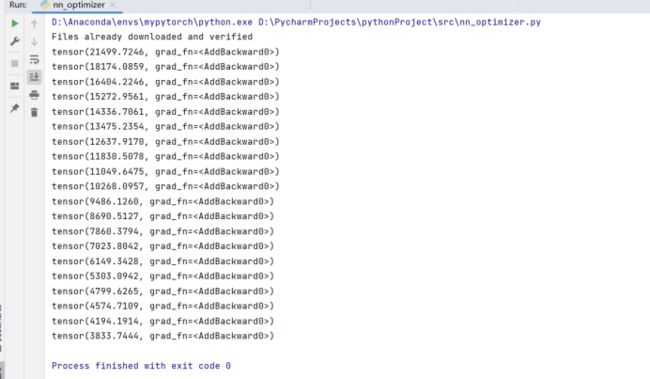
print(running_loss) Lr=0.01 陷入局部最优 反向优化
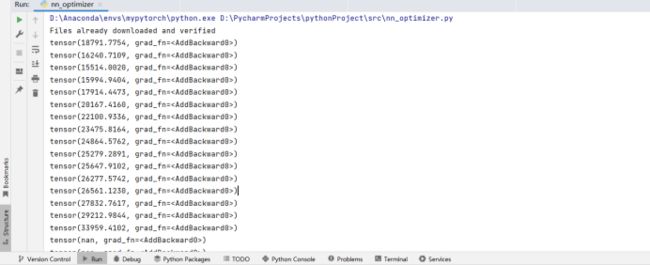
Lr=0.001 loss明显减小