Pytorch(1) 学习笔记-多分类网络的搭建
接触机器学习和深度学习已经有一段时间了,一直想做个记录,方便自己以后的查阅。
一开始我搭建神经网络时所使用的框架是Tensorflow,虽然功能强大但是不同版本代码的兼容性有些差强人意。
以下的内容所创建的环境是Anaconda中的虚拟环境,采用的python版本是3.8,cuda和cudnn都是对应的版本。
搭建和训练神经网络分为以下几个步骤:1.数据集的准备 2.神经网络的搭建 3.反向传播调整参数降低loss值
只是一个记录。
一. 数据集的准备
搭建完一个神经网络之后必不可少的步骤是对其进行训练,不断降低其loss值,修改参数。在此之前介绍一下与数据集息息相关的两个函数Datasets和DataLoader.
首先来说说Datasets,Datasets是torch下工具包的一个primitive,中文翻译为基元
Datasets
import torchvision
Dataset提供了很多已经收集好标记好的数据集,如Image Datasets,Text Datasets,Audio Datasets.我们可以通过以下方式来下载数据集。
dataset=torchvision.datasets.CIFAR10(root="./dataset",
train=True,
tansform=torchvision.transforms.ToTensor(),
download=True)此时我们下载的是CIFAR10数据集,该数据集提供了10个class的图片,分为planes,cars,truck等,所以该数据集适合多分类网络的入门。
root代表我们下载数据集所存储的位置,一般是直接放在项目列表下;train指定训练或测试数据集,如果设置为True则设置为训练集,如果为False则为测试集;download设置为True的话是如果我们的根目录里没有检测到该数据集,则从网上进行下载。
我们都知道神经网络需要的input是tensor数据类型,也就是张量,所以我们在加载图片之前需要将图片数据转换为tensor数据类型。torchvision提供了ToTensor的方法来进行转变,我们在下载数据集时可以直接进行转换。
DataLoader
当下载完数据集后,我们需要装载数据集,就像打牌时发完牌我们需要用手去抓取,一次抓四张还是一次抓五张由我们自己决定。
dataloader=DataLoader(dataset=dataset,
batch_size=32,
shuffle=True)dataset:要使用的数据集
batch_size:每个batch有多少个样本,就和我们一次抓多少张牌
shuff:在每个epoch开始的时候对数据进行重新排序
二.神经网络的搭建
这里我们主要使用的是torch.nn,它为我们封装好了现成的函数
class Net(nn.Module):#继承nn.Module
def __init__(self):
super(Net,self).__init__()#初始化
self.module=nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,input):
output=self.module(input)
return output这里搭建module使用的是nn.Sequential,如果一步一步来搭建网络,在forward时我们还得重新写一遍。
以上仅仅使用了卷积层、最大池化层和线性层,激活层并未使用。
三.读取数据并进行反向传播
接下来我们要把数据加载进神经网络并进行反向传播。
net=Net()#实例化网络
loss=nn.CrossEntryLoss()
optim=torch.optim.SGD(net.parameters(),lr=0.01)
for epoch in range(100):
for data in dataloader:
imgs,targets=data
outputs=net(imgs)
loss_result=loss(outputs,targets)
optim.zero_grad()#梯度清零
loss.backward()#进行反向传播计算梯度
optim.step()#进行参数优化
print(loss_result)
这里我们设置了50个epoch。在第一个epoch时loss值为2.3左右
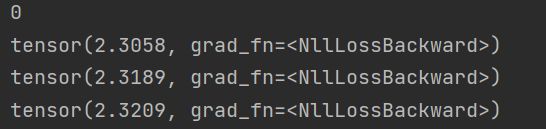
在第40个epoch时loss值已经下降到0.4左右
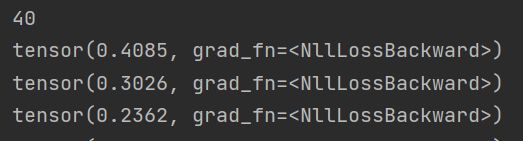
在第100个epoch时已经下降到0.001左右了

下面我把全部的代码贴出来,做个备份。
# -*- codeing = utf-8 -*-
# @Time : 2021/7/21 14:45
# @Author : ZY
# @File : caculate_loss.py
# Software : PyCharm
# Goal:Caculate the loss of CIFAR10 dataset using CrossEntryloss
import torchvision
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("pytorch代码/data",
train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
#build the net
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
net=Net()
loss=nn.CrossEntropyLoss()
optim=torch.optim.SGD(net.parameters(),lr=0.01)
for epoch in range(100):
print(epoch)
for data in dataloader:
imgs, targrts=data
outputs=net(imgs)
# print(outputs)
result_loss=loss(outputs,targrts)
optim.zero_grad()
result_loss.backward()
optim.step()
print(result_loss)