Deep learning for Computer Vision with Python笔记(4)构建KNN图像分类器
上文链接:
Deep learning for Computer Vision with Python(1)从零开始入门计算机视觉
Deep learning for Computer Vision with Python 笔记(2)图像基础_冰淇淋2333的博客-CSDN博客
Deep learning for Computer Vision with Python笔记(3)图像数据集介绍_冰淇淋2333的博客-CSDN博客
第六章 配置环境介绍
由于每个环境的版本都在更新,所以他们的兼容性非常复杂,尽管它们的更新会带来新的优化和训练神经网络的能力。
用到的库介绍
1. keras:同时支持TensorFlow和Theano
2. Mxnet:分布式多机器学习的深度学习库,在海量数据集上训练深度神经网络架构时,跨多个GPU、多设备并行训练的能力是非常重要的。
3. OpenCV:主要目的是实时图像处理,将图像表示为Numpy数组。它使用c++写的,但是支持python的接口。
4. scikit-image和scikit-learn:用于图像处理的算法,实现创建训练测试和验证的功能。
第七章 第一个图像分类器
这一张主要讨论最近邻K-NN分类器来构建模型进行图像分类。
在处理图像数据时,需要考虑的问题是:数据集是否非常大,能够放到机器的RAM中?对于较大的图像分类器,需要考虑一些方法来处理加载的图像。
step 1. 创建如图所示的项目结构。
datasets目录主要实现SimpleDatasetLoader类,用来加载小型数据集并返回图片内容和图片标签。在读取出图片后,我们将图片处理成固定的尺寸。
一些机器学习算法,类似K-NN,SVM,以及卷积神经网络都要求输入数据集的图片为统一的尺寸。实现大小调整有很多方式,我们使用基础的忽略纵横比,将宽度和高度压缩到所需尺寸。
step2. 写图像处理器类(preprocessor):
import cv2
class SimplePreprocessor:
def __init__(self, width, height, inter=cv2.INTER_AREA):
# 存储目标图像的长宽和插值
self.width = width
self.height = height
self.inter = inter
def preprocess(self, image):
# 缩放图像
return cv2.resize(image,(self.width, self.height),interpolation = self.inter)
step3. 写图像加载器类(datasetLoader):
import numpy as np
import cv2
import os
class SimpleDatasetLoader:
def __init__(self, preprocessors = None):
self.preprocessors = preprocessors
if self.preprocessors is None:
self.preprocessors = []
def load(self, imgPaths, verbose = -1):
data = []
labels = []
for(i, imgPath) in enumerate(imgPaths): #在遍历图片的同时保存i
image = cv2.imread(imgPath)
# 路径格式: /dataset_name/class/image.jpg
label = imgPath.split(os.path.sep)[-2] # 路径分隔符,用图片的父类路径作为图片标签
if self.preprocessors is not None:
for p in self.preprocessors:
image = p.preprocess(image)
data.append(image)
labels.append(label)
# 处理过程打印,verbose是限制最大的图片数
if verbose > 0 and i > 0 and (i+1) % verbose == 0:
print("[INFO] processed {}/{}".format(i+1,len(imagePaths)))
return (np.array(data), np.array(labels))这个加载器虽然简单,但能保证只要数据集的大小不超过电脑的内存,都可以进行加载和保存。如果图像数据集过大,则需要考虑更高级的加载器。
用类的方式实现加载,虽然分开成多个文件,但是这样的文件结构和类的设计有助于后面的拓展,所有图片的处理都可以用Prepocess,图片路径也可以任意选择。
step4. 使用K-NN构建模型
k近邻分类器器是一个简单地图像分类算法,主要依赖于图像特征向量之间的距离。对于一个未知的数据点,我们通过计算离他最近的k个点的标签,通过投票的方式选出它的标签。对于图像分类来说,这个算法有用的前提是,在n维空间内图像数据靠得近的,具有相似的内容。
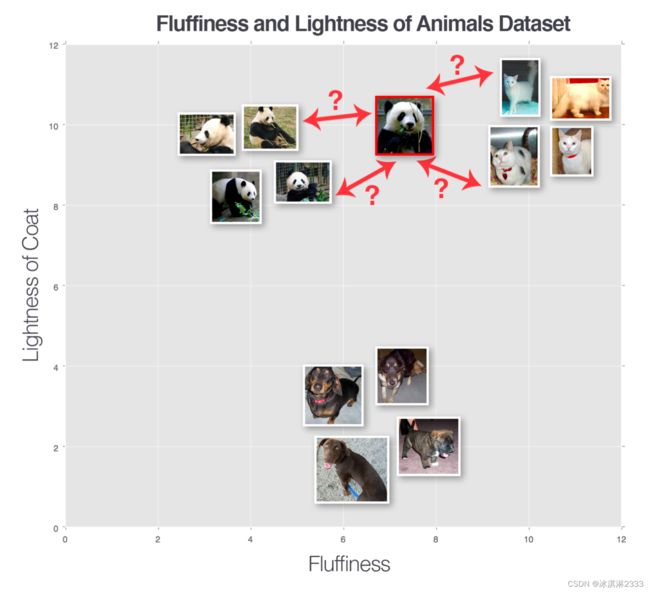
超参数的选择
首先我们要考虑,在计算距离时选择的距离度量函数。常见的距离度量函数有:
1. 欧几里得距离(L2距离),平方和计算距离
2. 曼哈顿距离(L1距离),差的绝对值之和
我们选择欧几里得距离来构建分类器。
第二个考虑的点是,k的取值对于结果的影响。需要根据具体的数据来进行尝试k的取值。k越小,效率越高,但是精度会下降,并受到噪声点和异常数据的影响。如果k越大,运行效率会变慢,并且k太大时,可能过度平滑分类结果,增加结果的偏差。
具体步骤
1. 把数据集的图片调整到32×32×3像素;
2. 将数据集分割成训练和测试集(这里不考虑超参数调优的过程,所以不涉及验证集)
3. 训练分类器
4. 在测试集上评估性能
创建knn.py文件。
首先,根据超参数编写接口:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from pyimagesearch.preprocessing import SimplePreprocessor
from pyimagesearch.datasets import SimpleDatasetLoader
from imutils import paths
import argparse
# 编写API
ap = argparse.ArgumentParser()
# 数据集路径,必填
ap.add_argument("-d","--dataset",required=True, help="path to input dataset")
# k值,默认为1,可选
ap.add_argument("-k","--neighbors",type=int, default=1, help="# of nearest neighbors for classification")
# 计算距离时的并发数,可选,默认用机器所有可用内核
ap.add_argument("-j","--jobs",type=int, default=-1, help = "# of jobs for k-NN distance ( -1 uses all available cores )")
args = vars(ap.parse_args())根据数据路径获取图像列表:
# 获取图片列表
print("[INFO] loading images...")
imagePaths = list(paths.list_iamges(args["datasets"]))调用之前写的simplepreprocessor处理图片:
# 处理图片
sp = SimplePreprocessor(32,32)
sdl = SimpleDatasetLoader(preprocessors = [sp])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.reshape((data.shape[0],3072))
print("[INFO] features matrix: {:.1f}MB".format(
data.nbytes / (1024 * 1000.0)
))分割数据集并构建模型:
# 分割数据集
le = LabelEncoder()
labels = le.fit_transform(labels)
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)
# 建立模型
print("[INFO] evaluating k-NN classifier...")
model = KNeighborsClassifier(n_neighbors=args["neighbors"], n_jobs=args["jobs"])
model.fit(trainX, trainY)
print(classification_report(testY, model.predict(testX), target_names=le.classes_))这样就写好了knn.py文件。通过:
$ python knn.py --dataset ../datasets/animals调用接口,开始训练。使用的数据集为动物数据集,下载地址:Dogs vs. Cats | Kaggle

从结果分析可以看出,对于500多张图片,他保存的特征向量仅有1.7MB,这说明k近邻模型的特征矩阵较小,易保存。准确率为0.66,这是因为猫和狗的特征较为相似,预测难度较大。
k-NN算法在图像分类问题上 的优缺点
K-NN仅保存数据点并计算距离,不需要训练,效率较高。但是,对于大型数据集来说,计算每个数据点和比较的耗时就会变得很大。并且,它在预测时同样需要耗费较大的时间,这不同于一般的机器学习:在训练中耗时,在测试时能非常快的获得结果。
K-NN非常适合用于低纬度特征的数据,而并非类似图像数据,因为高维数据的距离是非直观的。