Deep Learning with Pytorch_002
chapter03_深入研究神经网络的构建块_2
机器学习问题的解决方案框架
机器学习项目的工作流程包括问题陈述、评估、特征工程和避免过拟合
问题定义和数据集创建
要定义问题,包括两件重要的事情:输入数据和问题的类型。
输入数据和目标标签将是什么?例如,通过客户的评论,根据他们的特色菜品对餐馆进行分类,比如意大利、墨西哥、中国和印度的食物。要开始处理这种问题,需要手动手动将训练数据标注为可能的类别之一,然后才能在其上训练算法。在这个阶段,数据可用性通常是一个具有挑战性的因素。
识别问题的类型将有助于确定它是否为二进制分类、多分类、标量回归(房屋定价)或向量回归(边界框)。有时,可能还会需要使用一些无监督的技术,如聚类和降维。一旦确定了问题类型,就更容易确定应该使用哪种体系结构、损失函数和优化器。
对模型的评估
一个模型的好坏是由业务目标直接决定的。例如,当试图预测下一次机器故障将发生在风车中时,我们会更感兴趣地了解该模型能够预测故障的次数。使用简单的精度可能是错误的度量,因为大多数情况下,模型将正确地预测机器何时不会发生故障,因为这是最常见的输出。假设我们的准确率为98%,而且模型每次在预测故障率时都是错误的–但是这些模型在现实世界中可能没有任何用处。选择正确的成功度量对于业务问题至关重要。通常,这类问题有不平衡的数据集。
对于平衡分类问题,如果所有类都具有可能的精度,ROC和曲线下的面积(AUC)是常见的度量。对于不平衡的数据集,我们可以使用精确和回忆。对于排序问题,我们可以使用平均精度。
split函数及 rename函数
import re
text = '你好!吃早饭了吗?再见。
print('split1:')
print(text.split('!'))
# [64]: ['你好', '吃早饭了吗?再见。']
print('split2:')
print(text.split(',|?')) #python内建的split()函数只能使用单个分隔符,若有多个,则不划分
# [65]: ['你好!吃早饭了吗?再见。']
Re = re.split('。|!|?', text) # re可以实现多个分隔符的划分
# import re模块的split()函数可以使用多个分隔符对句子进行分割,其中不同的分隔符要用 “|” 隔开。
print('Re:')
print(Re)
# [67]: ['你好', '吃早饭了吗', '再见', '']
# # os.path.split():按照路径将文件名和路径分割开
# # split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割 后的字符串列表(list)
# # 1、split()函数, #python内建的split()函数只能使用单个分隔符,若有多个,则不划分
# # 语法:str.split(str="",num=string.count(str))[n]
# #
# # 参数说明:
# # str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
# # num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
# # [n]:表示选取第n个分片,当n= -1时,返回的是分割后的最后一个分片
# #
# # 注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
# # 2、os.path.split()函数
# # 语法:os.path.split('PATH')
# #
# # 参数说明:
# #
# # 1.PATH指一个文件的全路径作为参数:
# #
# # 2.如果给出的是一个目录和文件名,则输出路径和文件名
# #
# # 3.如果给出的是一个目录名,则输出路径和为空文件名
# # os.rename() 方法用于命名文件或目录,从 src 到 dst,如果dst是一个存在的目录, 将抛出OSError。
rename函数的使用技巧
for i in shuffle[:500]:
folder = files[i].split('/')[-1].split('.')[0]
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join(path,'valid',folder,image))
for i in shuffle[500:1400]:
folder = files[i].split('/')[-1].split('.')[0]
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join(path,'train',folder,image))
通过上述代码可以很方便的对数据进行预处理,将valid和train数据按照类别进行划分,分别把valid和train中的cat照片和dog照片分类放入cat和dog文件夹下;一次完成了文件夹的创建及照片的分类。
图片分类
提取shuffle里的前2000个元素,分别放入train的cat及dog里,2000以后的元素,分别放入valid的cat及dog里
# Copy a small subset of images into the validation folder and train 提取 shuffle里的前2000个元素,分别放入train的cat及dog里,valid的cat及dog里, 已经放好
for i in shuffle[:2000]:
folder = files[i].split('\\')[-1].split('.')[0]
# print('folder:')
# print(folder)
if folder == 'dog':
shutil.copyfile(files[i], 'F:\inner\kaggle\\valid\dog\dog.'+str(i)+'.jpg')
else:
shutil.copyfile(files[i],'F:\inner\kaggle\\valid\cat\cat.'+str(i)+'.jpg')
for i in shuffle[2000:]:
folder = files[i].split('\\')[-1].split('.')[0]
if folder == 'dog':
shutil.copyfile(files[i],'F:\inner\kaggle\\train\dog\dog.'+str(i)+'.jpg')
else:
shutil.copyfile(files[i],'F:\inner\kaggle\\train\cat\cat.'+str(i)+'.jpg')
关于transform1及transform2
simple_transform = transforms.Compose([transforms.Scale((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
K-fold
KFold(n_split, shuffle, random_state)
参数:n_split:要划分的折数,n_split的值不能超过样例总数,不然会报错。
shuffle: 每次都进行shuffle,测试集中折数的总和就是训练集的个数
random_state:随机状态
def holdout():
import numpy as np
from sklearn.model_selection import KFold
X = ['a','b','c','d','e','f']
kf = KFold(n_splits = 4,shuffle = True,random_state = 3)
for train,test in kf.split(X): # 这里kf.split(X)返回的是X中进行分裂后train和test的索引值,令X中数据集的索引为0,1,2,3;第一次分裂,先选择test,索引为0和1的数据集为test,剩下索引为2和3的数据集为train;第二次分裂,先选择test,索引为2和3的数据集为test,剩下索引为0和1的数据集为train。
print('%s %s' % (train,test))
pass
ImageFolder
ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字。
ImageFolder(root,transform=None,target_transform=None,loader=
default_loader)
参数说明:
root : 在指定的root路径下面寻找图片
transform: 对PIL Image进行转换操作,transform 输入是loader读取图片返回的对象
target_transform :对label进行变换
loader: 指定加载图片的函数,默认操作是读取PIL image对象
猫狗大战训练代码及结果
1、数据预处理(创建并划分valid/(cat & dog)及train/(cat & dog))
# 所需导入的包
# 这部分代码可以另存一个python文件
import os
import torch
import numpy as np
from glob import glob
import matplotlib.pyplot as plt
from torch import nn
from torchvision import transforms, models
from torchvision.datasets import ImageFolder
# 数据预处理(创建并划分valid/(cat & dog)及train/(cat & dog))
# 这里运行的很慢,把数据集手动缩小了,缩小情况如下:
# (base) [@gpu08 cat]$ ls|wc -l
# 471
# (base) [@gpu08 cat]$ cd ..
# (base) [@gpu08 train]$ cd dog
# (base) [@gpu08 dog]$ ls|wc -l
# 429
# (base) [@gpu08 dog]$
#
# (base) [@gpu08 valid]$ cd cat
# (base) [@gpu08 cat]$ ls|wc -l
# 230
# (base) [@gpu08 cat]$ cd ..
# (base) [@gpu08 valid]$ cd dog
# (base) [@gpu08 dog]$ ls|wc -l
# 270
def split_validset(path):
# Read all the files inside our floder
files = glob(os.path.join(path, '*/*.jpg'))
print(f'Total no of images {len(files)}')
no_of_images = len(files)
# Create a shuffled index which can be used to create a validation data set
shuffle = np.random.permutation(no_of_images)
print('shffule:')
print(shuffle)
# print(shuffle.size()) TypeError: 'int' object is not callable
# 创建valid文件夹
if not os.path.exists(os.path.join(path, 'valid')):
os.mkdir(os.path.join(path, 'valid'))
# 在trian及valid文件夹下在创建dog和cat文件夹
for t in ['train', 'valid']:
for folder in ['dog/', 'cat/']:
if not os.path.exists(os.path.join(path, t, folder)):
os.mkdir(os.path.join(path, t, folder))
for i in shuffle[:500]:
folder = files[i].split('/')[-1].split('.')[0]
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join(path,'valid',folder,image))
for i in shuffle[500:1400]:
folder = files[i].split('/')[-1].split('.')[0]
image = files[i].split('/')[-1]
os.rename(files[i],os.path.join(path,'train',folder,image))
pass
2、训练
train_model函数接受一个模型,并通过运行多个周期和减少损失来优化算法的权重
# 训练
def train_model(model_ft, criterion, optimizer, scheduler, num_epochs=5):
model_cp = '/home/ZhangXueLiang/LiMiao/dataset/save_para' # 保存网络的参数的位置
since = time.time()
simple_transform = transforms.Compose([transforms.Scale((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
train = ImageFolder('/home/ZhangXueLiang/LiMiao/dataset/dogsandcats/train/', simple_transform)
valid = ImageFolder('/home/ZhangXueLiang/LiMiao/dataset/dogsandcats/valid/', simple_transform)
# 按批次加载图像数据
train_data_gen = torch.utils.data.DataLoader(train, shuffle=True, batch_size=64, num_workers=3)
valid_data_gen = torch.utils.data.DataLoader(valid, batch_size=64, num_workers=3)
dataset_sizes = {'train': len(train_data_gen.dataset), 'valid': len(valid_data_gen.dataset)}
dataloaders = {'train': train_data_gen, 'valid': valid_data_gen}
best_model_wts = model_ft.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
scheduler.step()
model_ft.train(True) # Set model to training mode
else:
model_ft.train(False) # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for data in dataloaders[phase]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if torch.cuda.is_available():
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# 通过模型传递图像并计算损失。
# forward
outputs = model_ft(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
# 在训练阶段反向传播。对于验证/测试阶段,不调整权重。
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.data
running_corrects += torch.sum(preds == labels.data)
# print('running_corrects:')
# print(running_corrects)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
# print('running_loss:') # running_loss:
# print(running_loss) # tensor(0.8758)
# print('running_corrects:') # running_corrects:
# print(running_corrects) # tensor(482)
# print('dataset_sizes[phase]:')# dataset_sizes[phase]:
# print(dataset_sizes[phase]) # 500
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# 存储最佳模型及验证精度。
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model_ft.state_dict()
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model_ft.load_state_dict(best_model_wts)
torch.save(model_ft.state_dict(), '{0}/model.pth'.format(model_cp)) # 训练所有数据后,保存网络的参数
return model_ft
3、运行结果
在这段代码中,开始运行时,Acc的输出值总是为0,运行时发现,有如下情况:
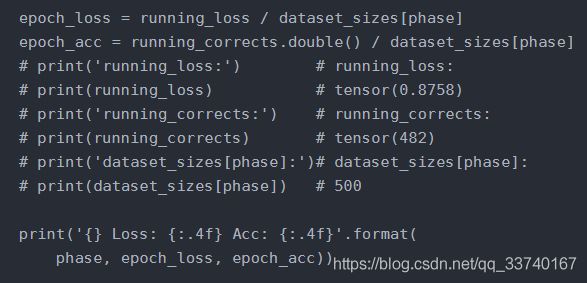
在注释掉的部分中,显示的是某一次的输出结果,可以看出输出的结果running_corrects为整形,但是dataset_sizes[phase]也是整形,而running_loss为浮点型,故Loss能得到非零值,而Acc结果总是为0(被舍入),故改变running_corrects —>running_corrects.double(),之后能得到结果。
改正后的运行结果:
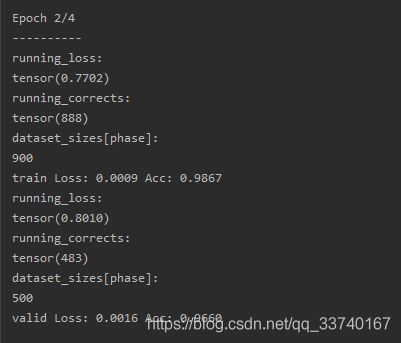
4、程序入口函数
# 所需的包
import time
from torch import nn, optim
from torch.optim import lr_scheduler
from torchvision import transforms, models
from torchvision.datasets import ImageFolder
import torch
from torch.autograd import Variable
# 程序入口函数
def main():
# loss and optimizer
learning_rate = 0.001
criterion = nn.CrossEntropyLoss() # 选择交叉熵损失函数
model_ft = models.resnet18(pretrained = True) # Resnet18网络模型
optimizer_ft = optim.SGD(model_ft.parameters(),lr = 0.001,momentum = 0.9) # 选择SGD优化器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft,step_size = 7,gamma = 0.1) # 动态地改变学习速度
# train_model(ResNet,criterion,optimizer_ft,exp_lr_scheduler,num_epochs=25)
train_model(model_ft,criterion,optimizer_ft,exp_lr_scheduler,num_epochs=5)
pass
if __name__ == '__main__':
main()