李宏毅【機器學習2021】笔记
只有一半左右,因为主要目标是nlp,剩下的就随缘看了,要杀nlp一个回马枪了!
文章目录
- 預測本頻道觀看人數 (上) - 機器學習基本概念簡介
-
- 什么是机器学习
- 不同类型的函数
- How to find a function? A Case Study
-
- 写一个新的函数,使得预测函数更加复杂更加符合实际(一周为周期)
- 預測本頻道觀看人數 (下) - 深度學習基本概念簡介
-
- 线性model太简单了
- Sigmoid Function
- 重新定义一些符号。。。
- 至此我们改进了前面提到的机器学习框架的第一步:Function with unknown
- Loss
- Batch
- ReLU
- 实战效果
- 多层神经网络
-
- 实战效果
- 此即深度学习
- 为什么不将网络变胖而是把它变深, 留待讲解,插眼。
- Overfitting
- 機器學習任務攻略
-
- Framework of ML
- General Guide
- Model bias
- Optimization Issue
- 如何判断是model Bias 还是Optimization Issue的原因?
- Overfitting
-
- 解决方案
- Cross Validation
- N-fold Cross Validation
- Mismatch
- 類神經網路訓練不起來怎麼辦 (一): 局部最小值 (local minima) 與鞍點 (saddle point)
-
- 当 gradient 接近零,学习速度也就接近0,其原因有可能为:
- 如何确定到底是哪个原因?
-
- Tayler Series Approximation
- Saddle Point v.s. Local Minima
- 類神經網路訓練不起來怎麼辦 (二): 批次 (batch) 與動量 (momentum)
-
- Review
- Small Batch vs Large Batch
- 考虑到GPU平行运算的问题更大的batch不一定就比小的batch花的时间多
- 更新参数所拥有的数据越多,更新越精准,batch越多,更新一次batch的数据越少,噪音越大,然而效果反而更好。
- 即使train data效果差不多,在test data里小的batch size也会得到更好的效果。
- 总结
- Momentum
- 類神經網路訓練不起來怎麼辦 (三):自動調整學習速率 (Learning Rate)
-
- 训练卡住了,loss不再下降,并不意味着到了local minima 或者鞍点之类的
- But training can be difficult even without critical points
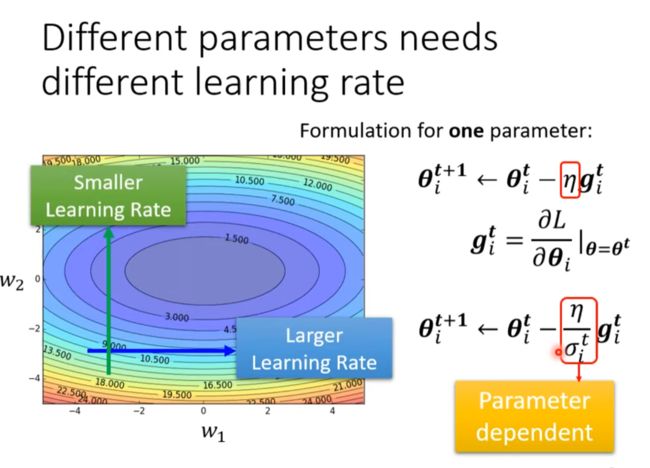
- Different Parameters needs different learning rate
- RMSProp
- Adam
- Learning Rate Scheduling
- Residual Network
- Summary of Optimization
- Next Time
- 類神經網路訓練不起來怎麼辦 (四):損失函數 (Loss) 也可能有影響
-
- To learn more
- Classification as Regression?
- Loss of Classification
- 为什么相较于MSE Cross-entropy更常被用到
- 類神經網路訓練不起來怎麼辦 (五): 批次標準化 (Batch Normalization) 簡介
-
- Changing Landscape
- Feature Normalization
- Considering Deep Learning
- Batch Normalization[插眼,没看太懂]
-
- BN in Test
- Internal Covariate Shift?
- 卷積神經網路 (Convolutional Neural Networks, CNN)
-
- Image Classification
- Observation 1 //引出receptive field
- Simplification 1
-
- receptive field
- Typical Setting
- Observation 2 //引出filter
- Simplification 2
-
- Typical Setting
- Benefit of Convolutional Layer
- Convolutional layer //另一种说法
- Comparison of Two Stories
- Observation 3 //引出pooling
- The Whole CNN
-
- Flatten 把所有数值拉直变成向量
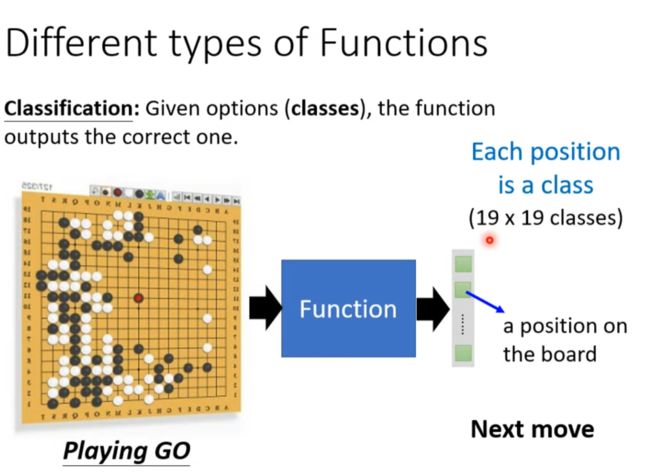
- Application: Playing Go
- Why CNN for GO playing
- More Applications
- To learn more
- 自注意力機制 (Self-attention) (上)
-
- Vector as Input
- What is the output?
-
- 输入数量与输出数量一致
- 输入输出数量不一致
- Sequence Labeling
- Self-attention
- Part of attention network
- 自注意力機制 (Self-attention) (下)
-
- Multi-head self-attention
- Positional Encoding
- Application
-
- Speech
- Image
- Self-attention for Graph
-
- To Learn more about GNN
- Self-attention v.s. CNN
- Self-attention vs RNN
-
- To learn more about RNN
- To Learn More
- Transformer(上) Encoder
-
- Sequence-to-sequence's application
-
- Seq2seq for Chatbot
- Seq2seq for Syntactic parsing
- seq2seq for multi-label classification
- Seq2Seq for Object Detection
- Seq2seq
-
- Encoder
- To learn more
- Transformer (下) Decoder
-
- Autoregressive(Speech Recognition as example)(AT)
- Decoder
-
- Masked multi-head attention
- Stop Token: We don't know the correct output length
- Non-autoregressive(NAT)
-
- To learn more about nat
- Encode-Decoder
-
- Cross Attention
- train
- Teacher Forcing
- tips about train seq2seq
-
- Copy Mechanism
-
- To learn more
- Summarization
- Guided Attention
- Beam Search
- Optimizing Evaluation Metrics?
- 训练和测试不一致(Exposure bias)
-
- Scheduled Sampling
- 生成式對抗網路 (Generative Adversarial Network, GAN) (一) – 基本概念介紹
-
- Network as Generator
- 为什么要输出一个分布?
- GAN
-
- Anime Face Generation
- Discriminator
- Basic Idea of GAN
- Algorithm
- Progressive GAN
- 生成式對抗網路 (Generative Adversarial Network, GAN) (二) – 理論介紹與WGAN
-
- Our Objective
- How to solve the problem of divergency(sample and discriminator)
-
- Discriminator
- can we use other divergence?
- Tips of gan
-
- JS divergence is not suitable
- Wasserstein distance
- WGAN
- 生成式對抗網路 (Generative Adversarial Network, GAN) (三) – 生成器效能評估與條件式生成
-
- GAN is still challenging
- GAN for Sequence Generation
-
- For more
- 为什么用GAN
- Possible Solution
- Quality of Image
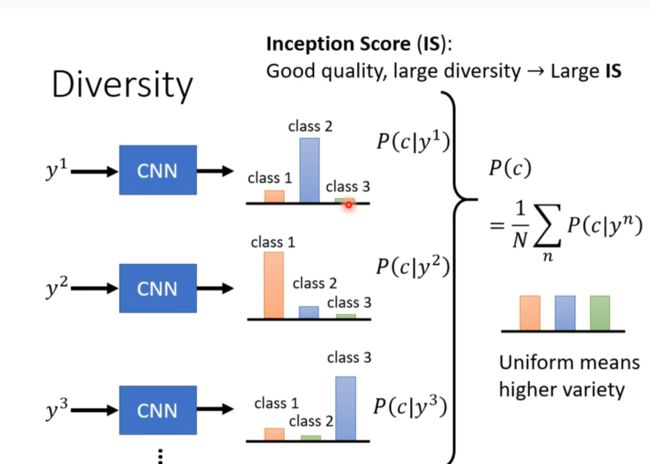
- Diversity - Mode Collapse
- Diversity - Mode Dropping
- Frechet inception Distance(FID)(插眼)
- We don't want memory GAN
- Conditional Generation
-
- Text to image
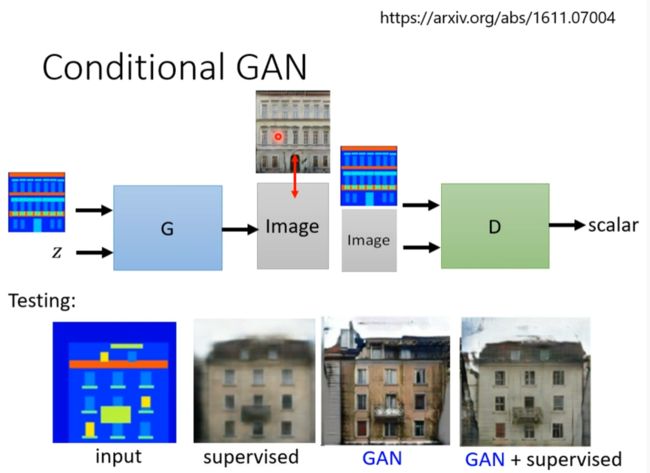
- Application
- 生成式對抗網路 (Generative Adversarial Network, GAN) (四) – Cycle GAN
-
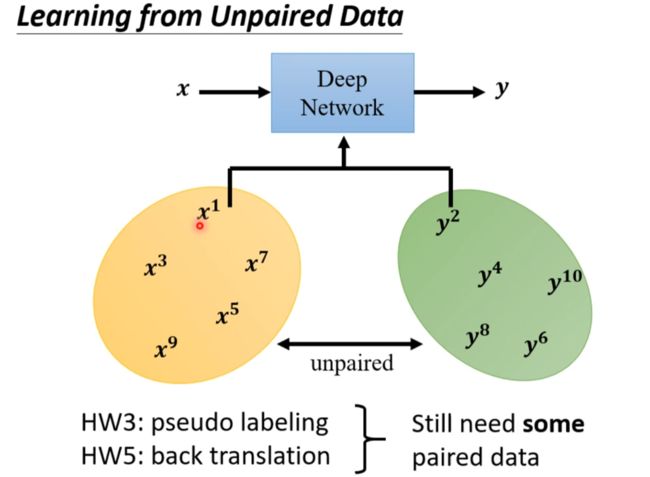
- Learning from Unpaired Data(无监督)
- more
- SELFIE2ANIME
- Text Style Transfer
- 自督導式學習 (Self-supervised Learning) (一) – 芝麻街與進擊的巨人
- 自督導式學習 (Self-supervised Learning) (二) – BERT簡介
-
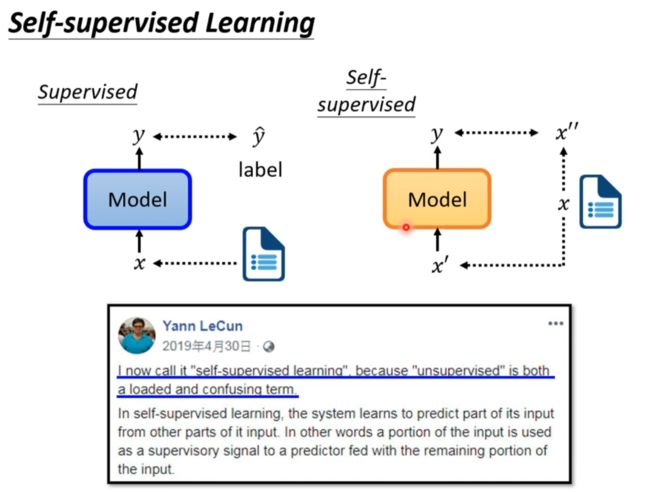
- Self-supervised Learning
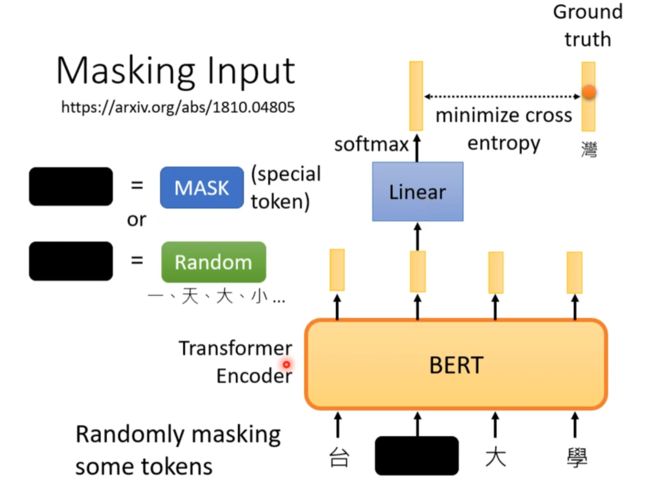
- Masking Input
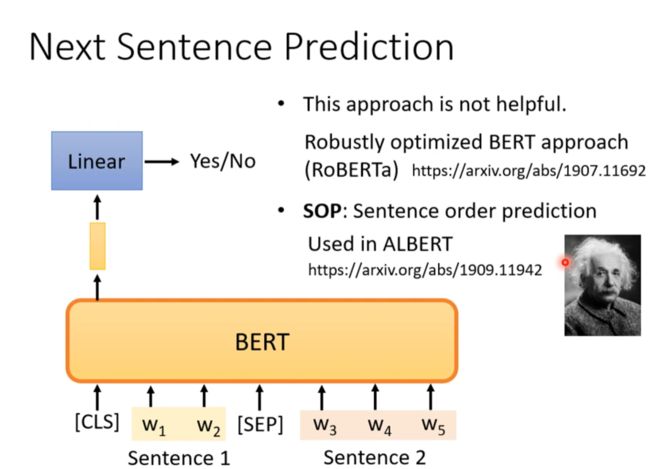
- Next Sentence Prediction
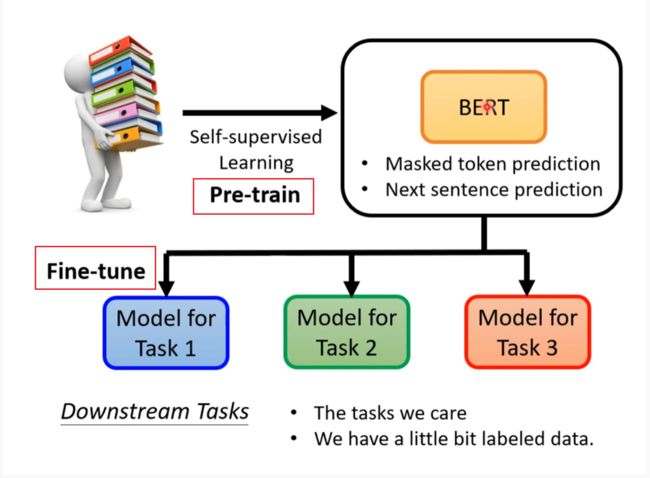
- Downstream Tasks 将前面的训练结果用在其他训练上
- GLUE
- How to use BERT
-
- Case 1 input asq output class
- Case 2 input seq output same as seq
- Case 3 input two seq output class
- Case 4 input document and query output answer
- Training BERT is challenging
- BERT Embryology(胚胎学)
- Pre-training a seq2seq model
- 自督導式學習 (Self-supervised Learning) (三) – BERT的奇聞軼事
-
- Why does BERT work
- Applying BERT to protein,DNA,music classification
- Multi-lingual BERT
-
- Cross-lingual Alignment(一种解释)
- 自督導式學習 (Self-supervised Learning) (四) – GPT的野望
-
- How to use GPT
- Few-shot learning (no gradient descent) "In-context" Learning
- Beyond Text
-
- Image
- Speech
- Application of self supervised
- 自編碼器 (Auto-encoder) (上) – 基本概念
-
- Outline
- review of self-supervised learning frame work
- auto-encoder in image
-
- Dimension reduction
- for more
- Why auto-encoder?
- Auto-encoder is not a new idea
- De-noising Auto-encoder
- 自編碼器 (Auto-encoder) (下) – 領結變聲器與更多應用
-
- Feature Disentangle
-
- Representation includes information of different aspects
- Application: voice conversion
- discrete representation
- Text as representation
- Tree as Embedding
- Generator
- Compression
- Anomaly Detection
- For More
- 來自人類的惡意攻擊 (Adversarial Attack) (上) – 基本概念
-
- Motivation
- How to arrack
-
- Example of attack
- 含恶意的噪音
- Non-perceivable
- Attack Approach
- 來自人類的惡意攻擊 (Adversarial Attack) (下) – 類神經網路能否躲過人類深不見底的惡意?
-
- White Box vs Black Box
- Black Box
- One pixel attack
- Universal Adversarial Attack
- Beyond Images
- Attack in the Physical World
- Backdoor in Model
- Solution
- 機器學習模型的可解釋性 (Explainable ML) (上) – 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢?
-
- Why we need Explainable ML?
- Interpretable vs powerful
- Goal of Explainable ML
- Explainable ML
-
- Local Exception
- A test
- SmoothGrad
- Gradient Saturation
- How a net work process the input data
-
- 为了观察过程压缩中间向量的维度
- 很多问题尚待研究。。
- 用探针处理中间向量
- example
- 機器學習模型的可解釋性 (Explainable ML) (下) –機器心中的貓長什麼樣子?
-
- What does a filter detect?(插眼,他在说什么)
- Outlook
- 概述領域自適應 (Domain Adaptation)
-
- Domain shift
- Basic idea
- Domain Adversarial Training
- Limitation(插眼)
- Outlook
- More condition in domain Adaptation
-
- little unlabel
- Know nothing
-
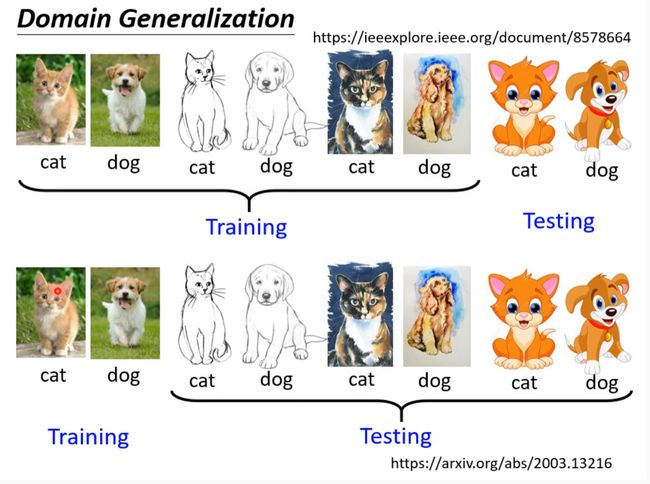
- Domain Generation
https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.php
預測本頻道觀看人數 (上) - 機器學習基本概念簡介
什么是机器学习
机器学习就是让机器具备找一个函数的能力。
例子:
- 语音识别
- 图像识别
- α GO

不同类型的函数
- Regression: The function outputs a scalar.
- Classification: Given options(classes),the function outputs the correct one,
- Structured Learning, create something with structure(image,document)

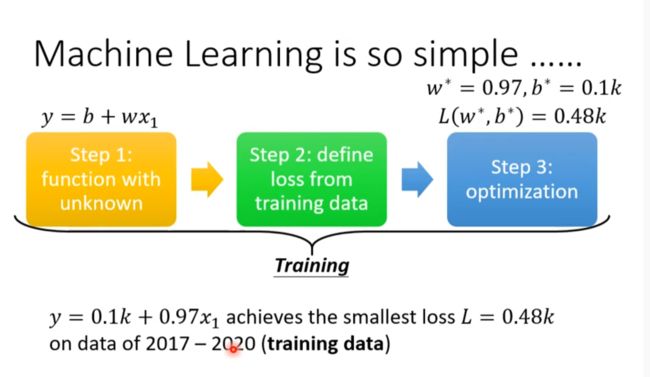
How to find a function? A Case Study
输入Youtube历史资料输出是第二天的浏览人数
- Function with Unknown Parameters
- Define Loss from Training Data
- Optimization
 i
i


这个图是error surface

步伐取决于斜率和learningrate
Hyperparameters 超参数
Gradient descent并不是总能停在global minima 而是停在了local minima.
该问题可以被解决,并不是gradient descent真正的通点(插眼,我猜是计算量太大,引出随机梯度下降)

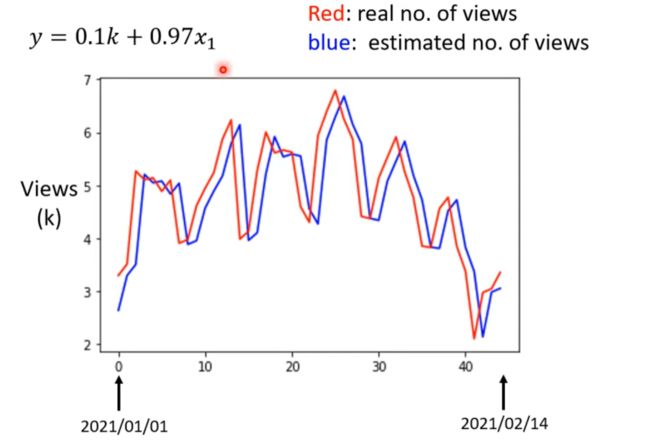
写一个新的函数,使得预测函数更加复杂更加符合实际(一周为周期)
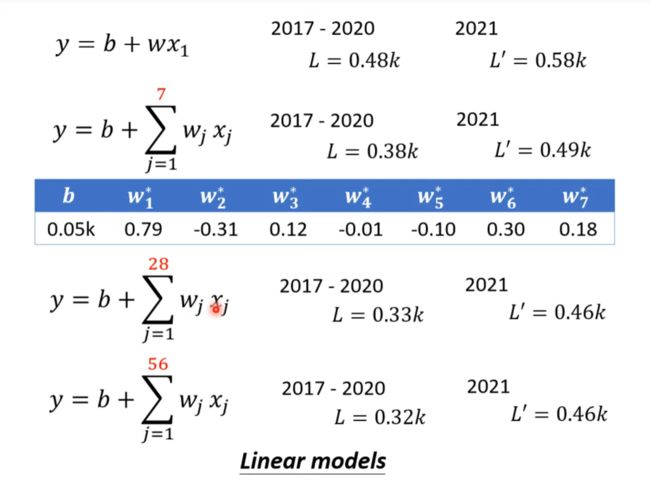
似乎观看人数的循环规律止于7之28天之间
預測本頻道觀看人數 (下) - 深度學習基本概念簡介
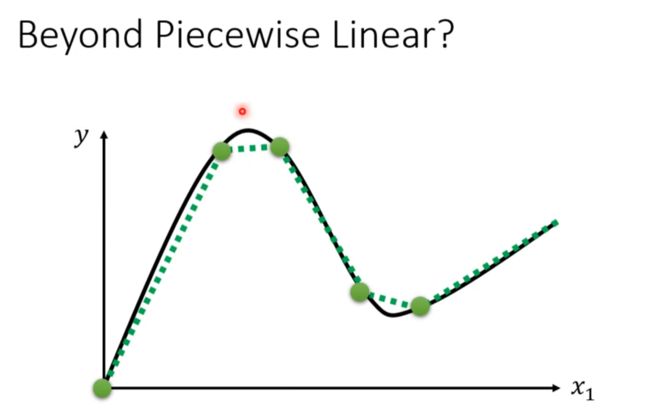
线性model太简单了
这种情况叫做Model Bias

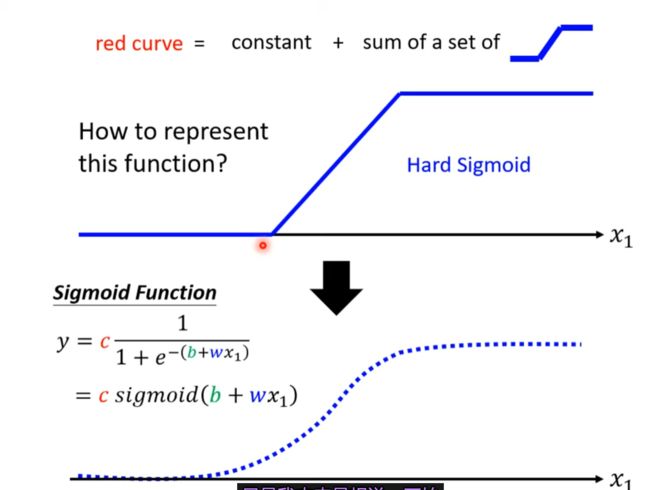
Sigmoid Function

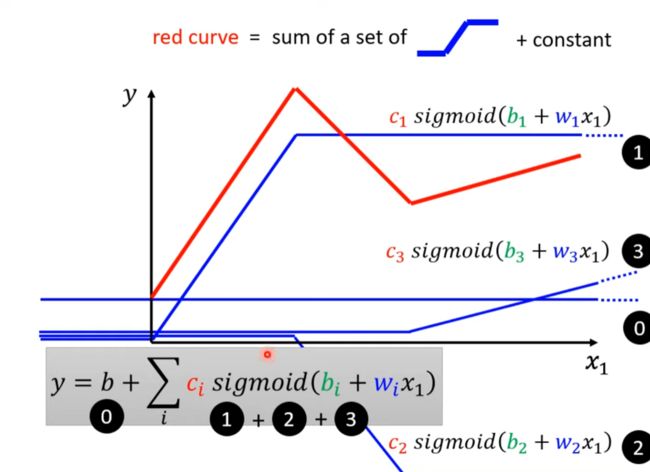
用多个feature加到一起去近似

引入离散数学:
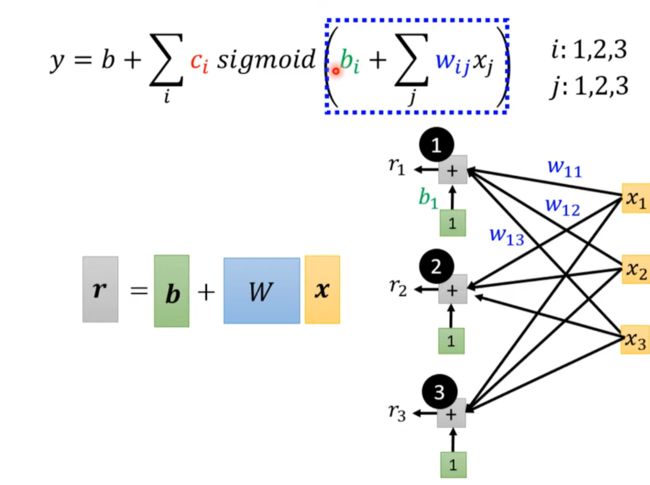
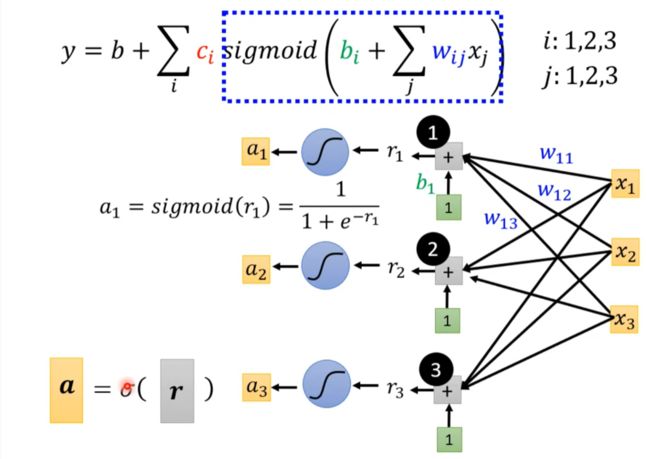
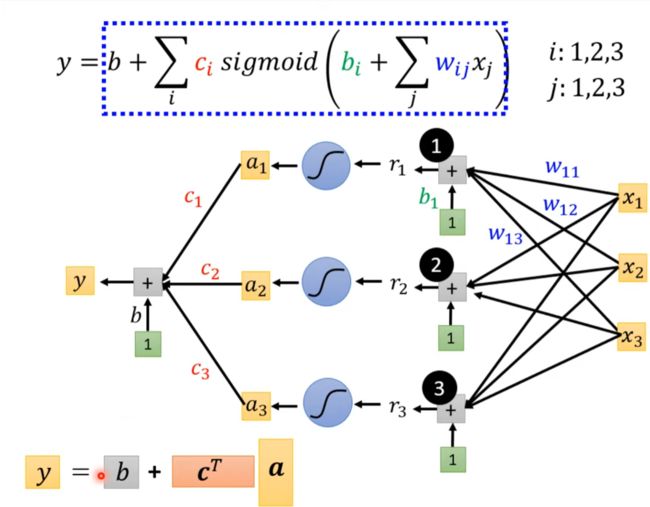
最终得到
重新定义一些符号。。。

至此我们改进了前面提到的机器学习框架的第一步:Function with unknown
课外知识:Hard Sigmoid
Loss
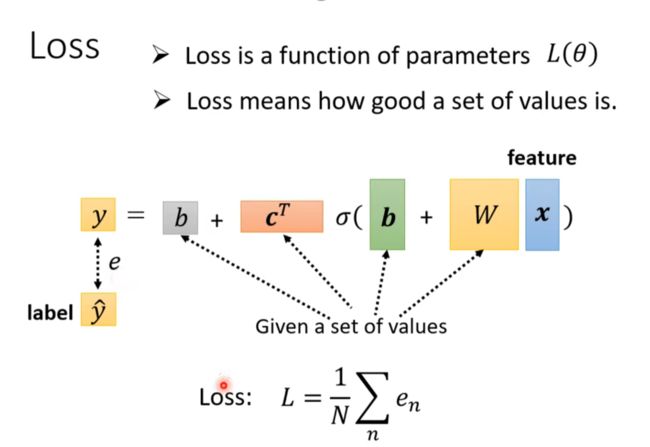
先随机找一组θ初始值,以后可以有更好的方法,而不是随机的。之后根据梯度不断更新。


Batch
将data随机分为多个batch,每次学习一个batch

每更新一次参数(学习一个batch)叫一次update,每更新完一轮data(学习了多个batch)叫一个epoch。
ReLU



实战效果

多层神经网络
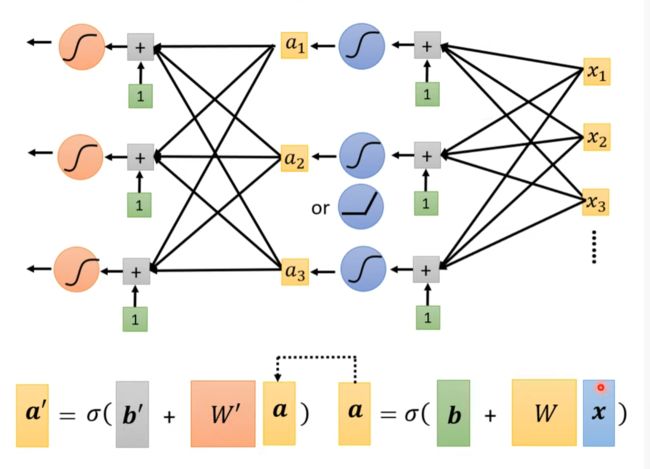
实战效果

此即深度学习
Deep = Many hidden layers
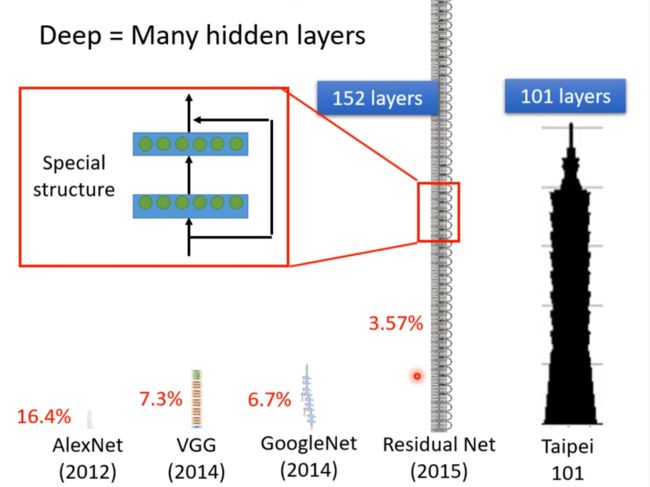
为什么不将网络变胖而是把它变深, 留待讲解,插眼。
Overfitting
训练数据loss减少,测试数据loss增大
機器學習任務攻略
Framework of ML

General Guide

Model bias
函数弹性不够大

Optimization Issue

如何判断是model Bias 还是Optimization Issue的原因?
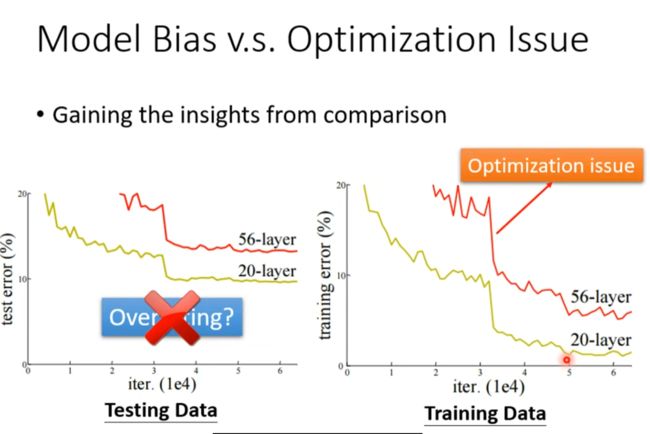
注意training data上的效果, 多出来的层数不进行操作都可以达到20层的效果,弹性应该比他大得多, 说明优化有问题
test data上出现这种情况可能是由于过拟合,但一定要在training data上验证了才可以确定

Overfitting

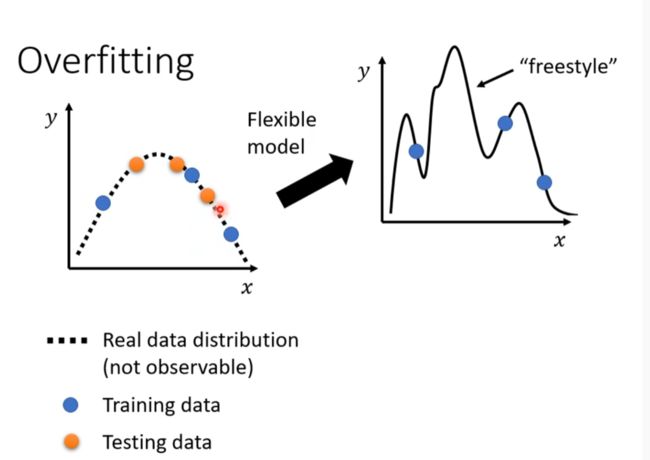
测试数据过少,模型预测函数的自由度太大(由于弹性太大)。
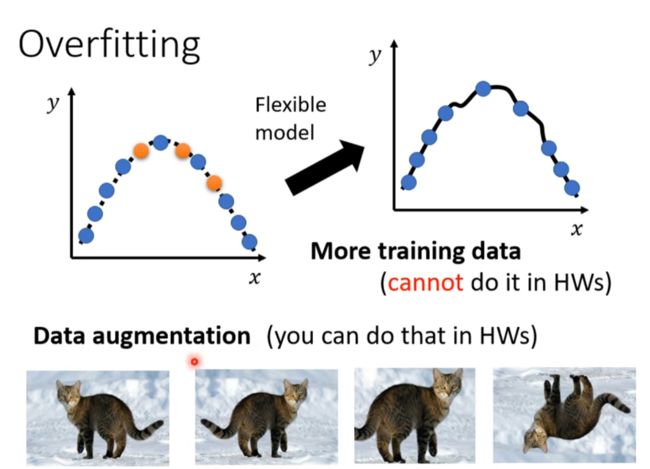
解决方案
- 增加训练资料
- Data augmentation
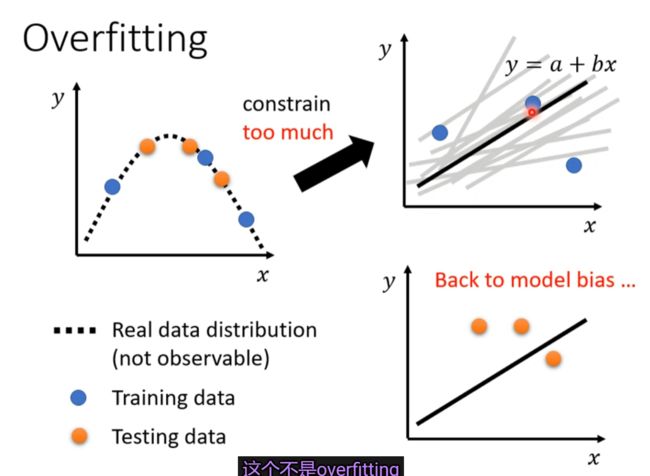
- Constrained model(根据实际情况降低model的弹性),限制要适量,过度的话就拟合不出来了。



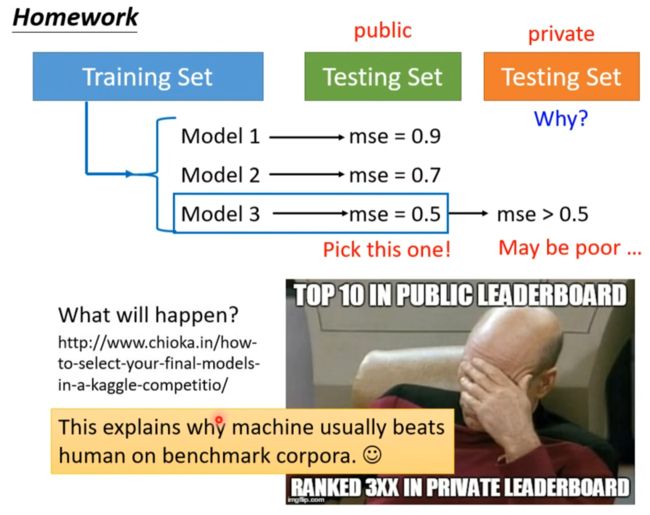
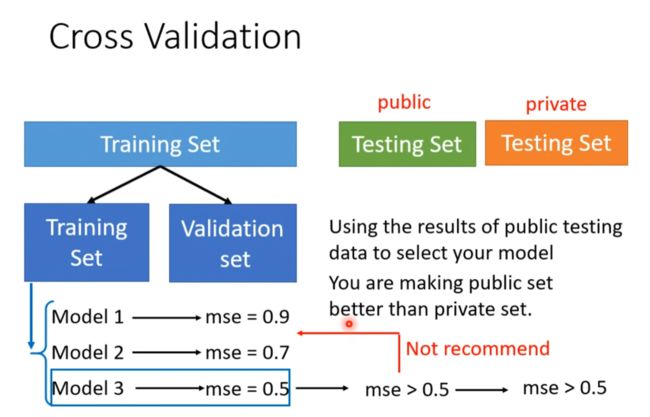
选mse最低的不一定就是最好的model
Cross Validation
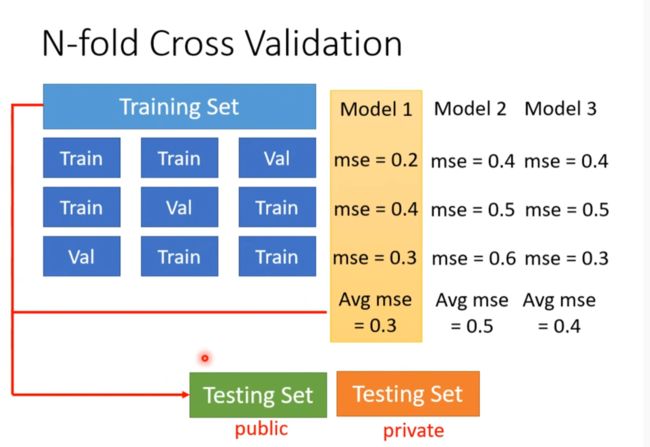
N-fold Cross Validation
Mismatch
由于没有将一些情况考虑进去,比如春节,data中不包含春节的经验,所以模型在考虑结果时当然不会考虑到春节的影响。

類神經網路訓練不起來怎麼辦 (一): 局部最小值 (local minima) 與鞍點 (saddle point)
Optimization Fails because…
当 gradient 接近零,学习速度也就接近0,其原因有可能为:
- local minima
- saddle point
- critical point

如何确定到底是哪个原因?
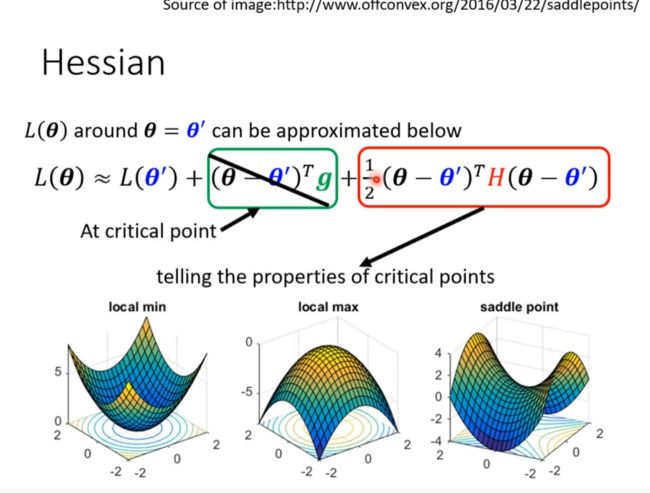
Tayler Series Approximation

可以根据二阶导数来判断:[ToL]
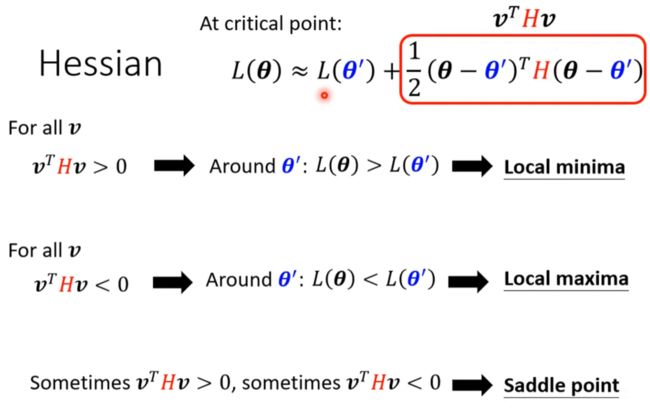



实际上用到的机会少,因为随着模型规模的增大,二阶倒数太难算了
Saddle Point v.s. Local Minima
低维的local minima很有可能是高维的saddle point

Eigen value 为负的话还是有路可以降低loss
類神經網路訓練不起來怎麼辦 (二): 批次 (batch) 與動量 (momentum)
Review
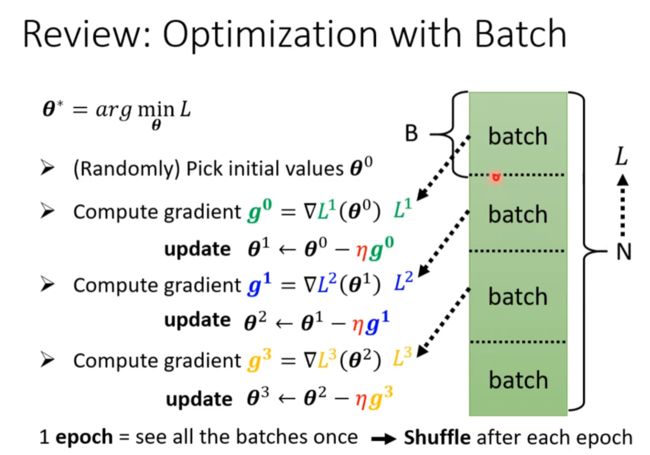
每次epoch重新分batch,每次这样的操作叫一次epoch
Small Batch vs Large Batch

考虑到GPU平行运算的问题更大的batch不一定就比小的batch花的时间多

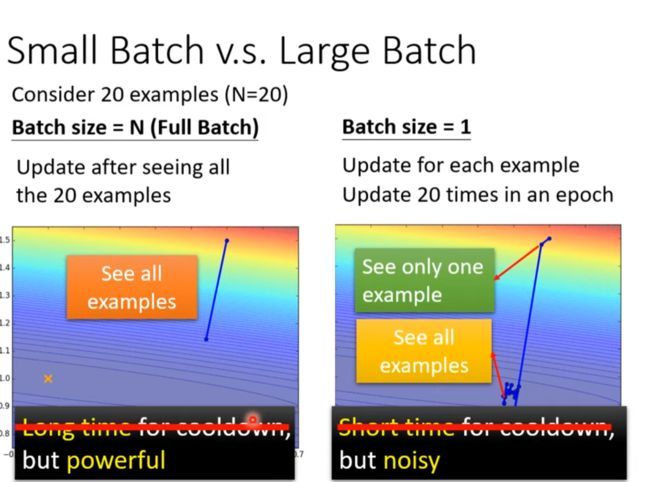
更新参数所拥有的数据越多,更新越精准,batch越多,更新一次batch的数据越少,噪音越大,然而效果反而更好。
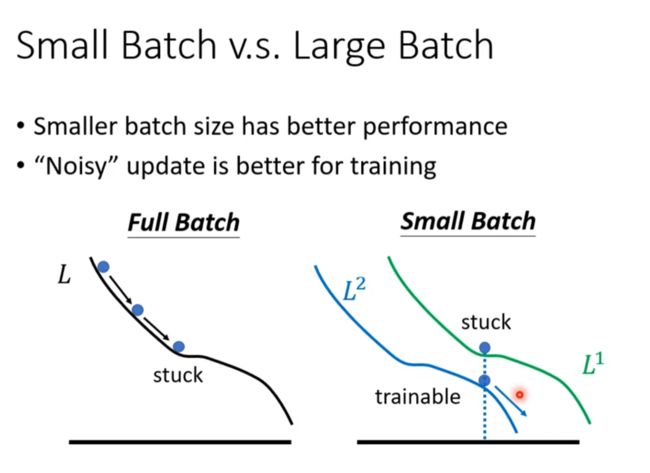
即使train data效果差不多,在test data里小的batch size也会得到更好的效果。

总结


Momentum
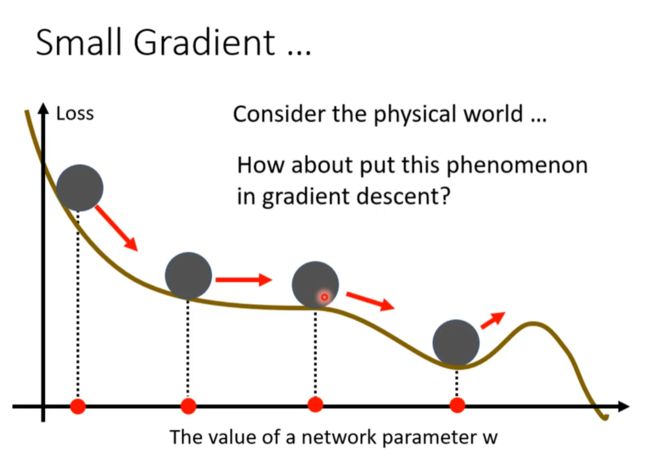
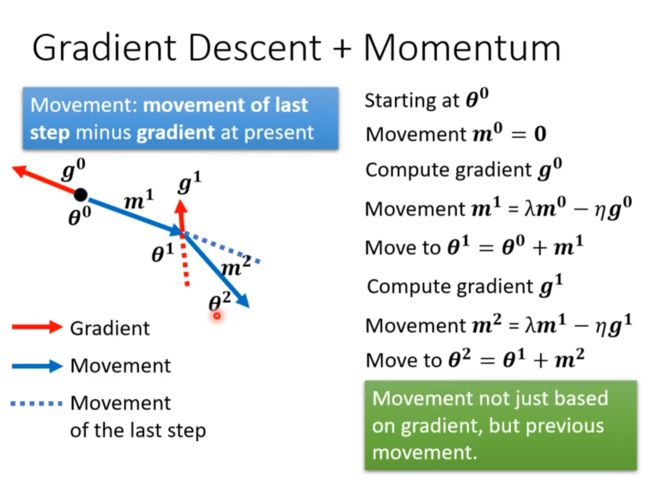
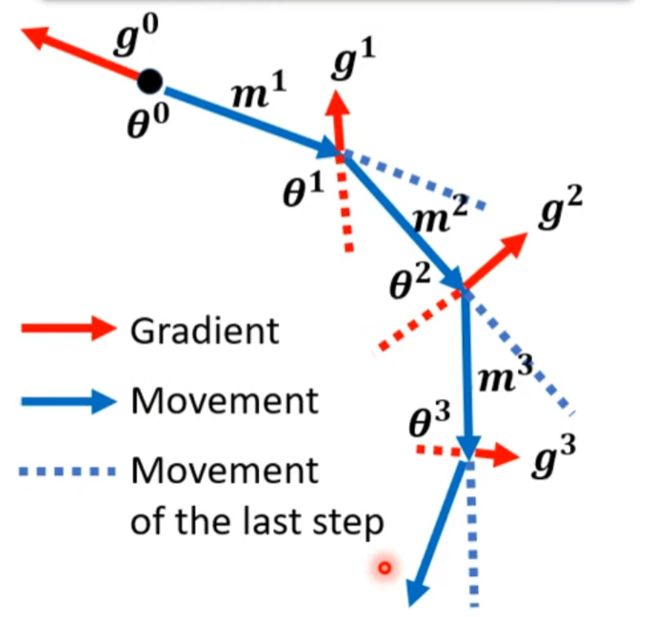

所以有种说法说惯性受过去所有运动的影响。

類神經網路訓練不起來怎麼辦 (三):自動調整學習速率 (Learning Rate)
训练卡住了,loss不再下降,并不意味着到了local minima 或者鞍点之类的
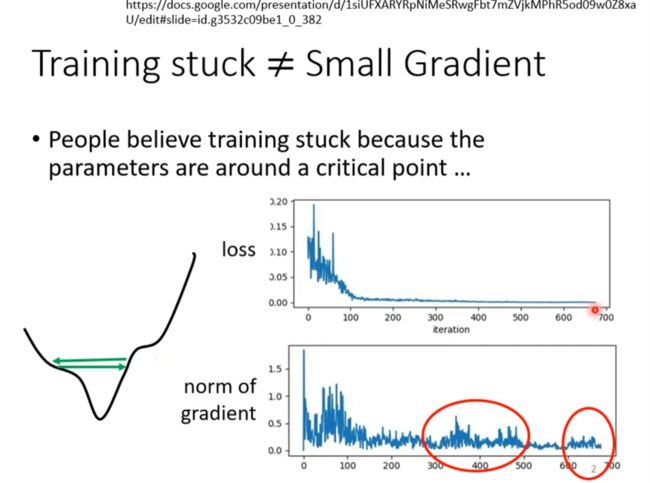
这样的点叫Critical point
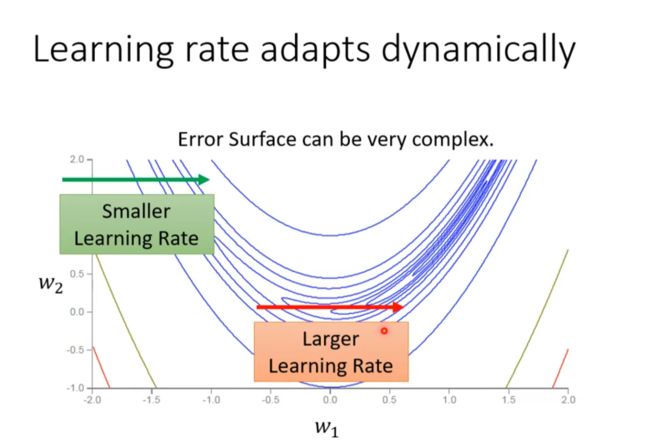
But training can be difficult even without critical points
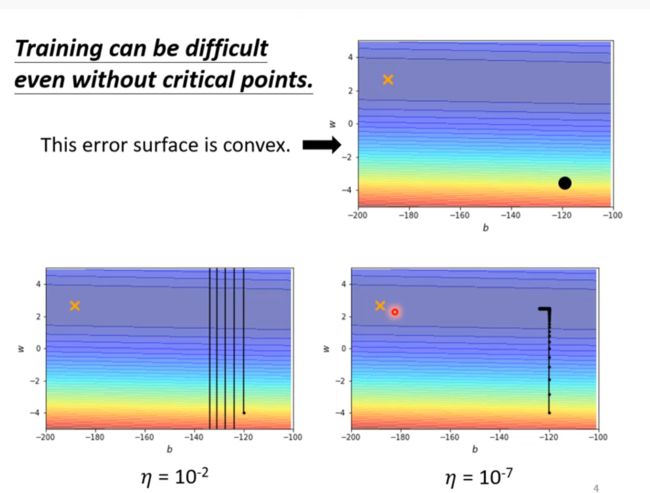
步伐(Learning rite)太大会在两边回荡,即critical point, 但是步伐太小又会使学习缓慢
Different Parameters needs different learning rate
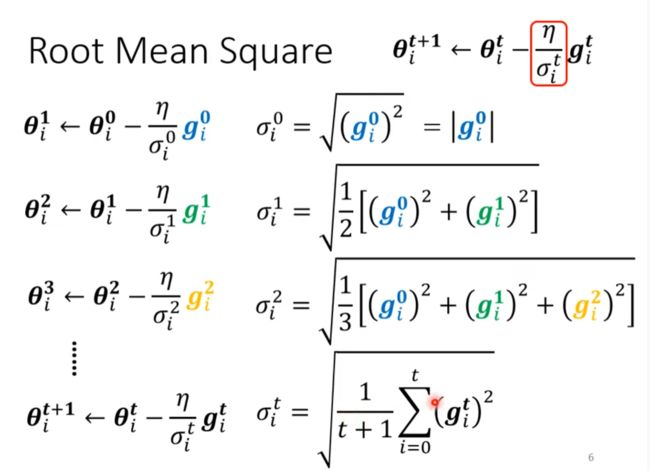

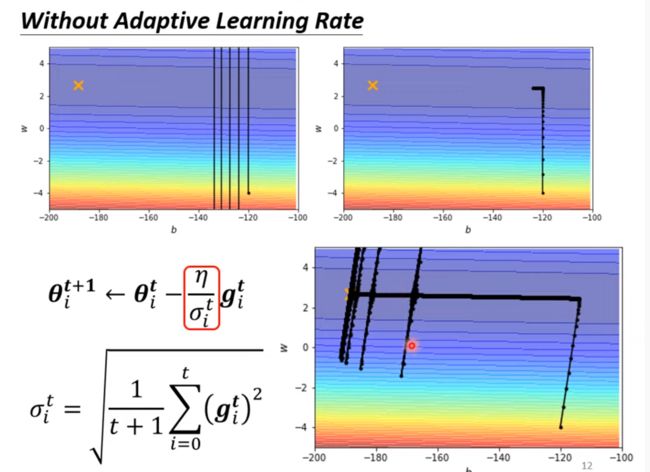
RMSProp

Adam

Learning Rate Scheduling
随着终点的临近让学习率下降(Learning rate decay)
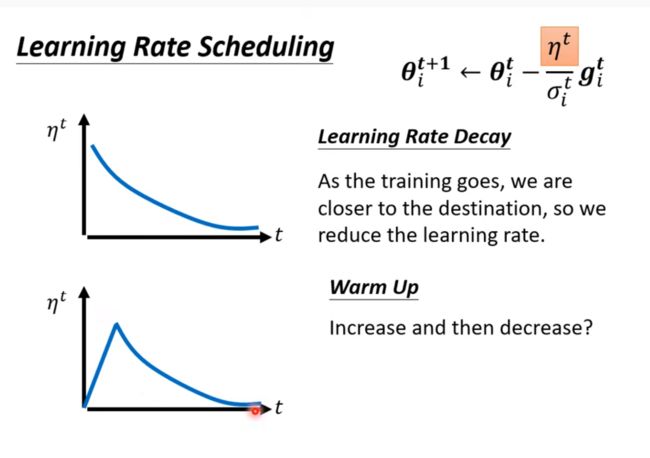
Residual Network
在transformer中引用了warm up的方法

Summary of Optimization

两个都考虑所有历史,但是一个更注重方向,一个只注重大小。
Next Time

類神經網路訓練不起來怎麼辦 (四):損失函數 (Loss) 也可能有影響
To learn more

Classification as Regression?

暗示12关系比较近,13比较远,所以不是很可行,所以选择one-hot编码。

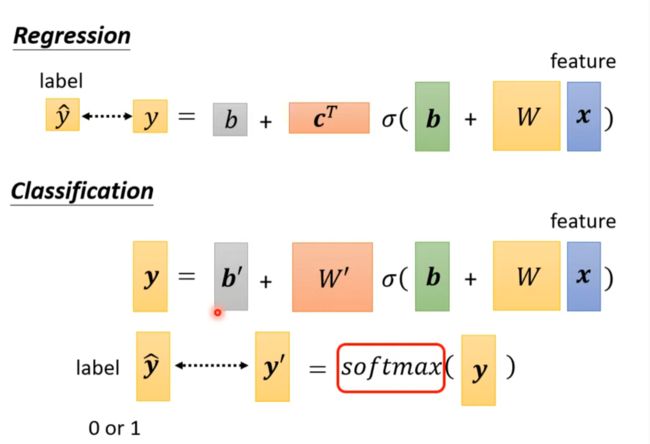
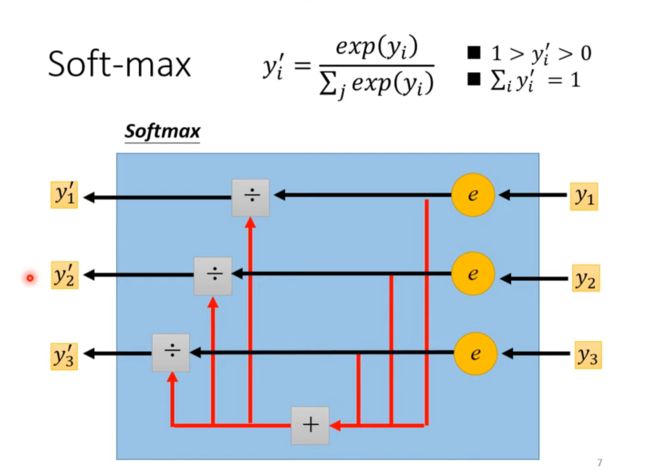
SoftMax 将可以为任何值的数值映射到0~1之间
当只有两类时softmax和sigmoid是相同的 (插眼,没太懂)
Loss of Classification
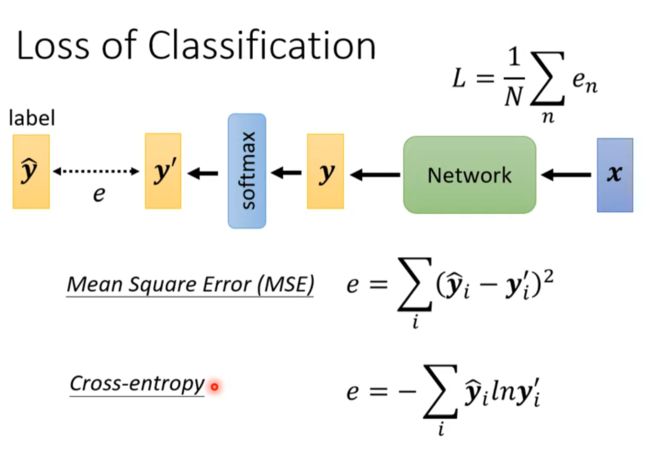
Minimizing cross-entropy is equivalent to maximizing likelihood.
Pytorch Cross-entropy 内含Softmax
为什么相较于MSE Cross-entropy更常被用到
MSE计算loss不容易从loss大的地方走下来,因为那里梯度太小了
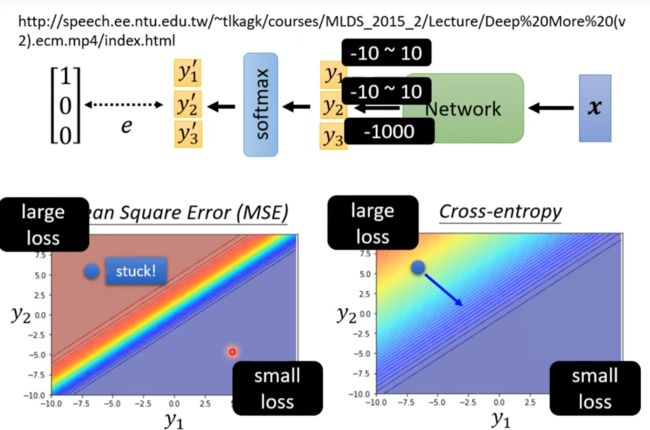
類神經網路訓練不起來怎麼辦 (五): 批次標準化 (Batch Normalization) 簡介
Changing Landscape
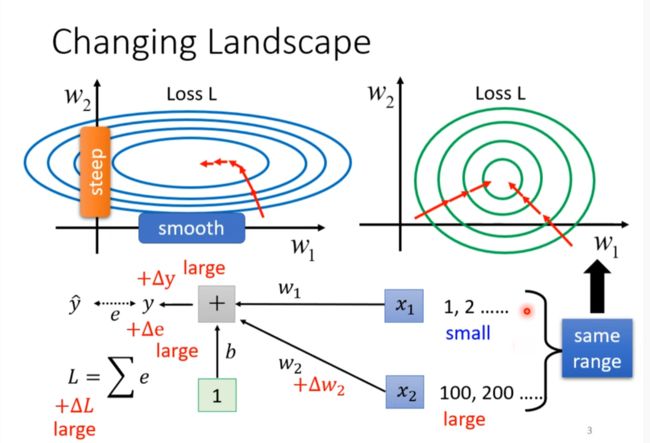
上图很6
Feature Normalization
Feature Normalization是上图的解决办法,以下是Feature Normalization的一种方法
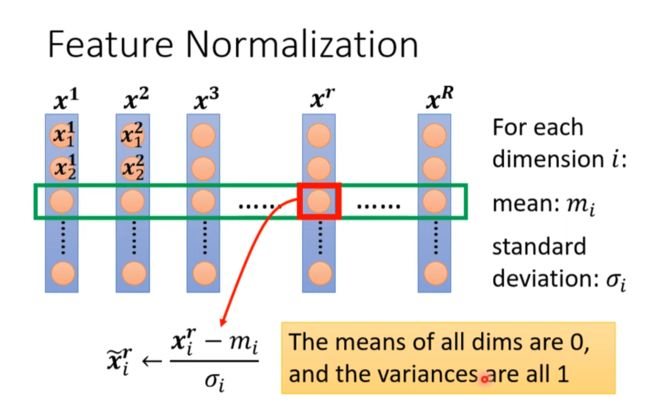
In general, feature normalization makes gradient scent converge faster.
Considering Deep Learning
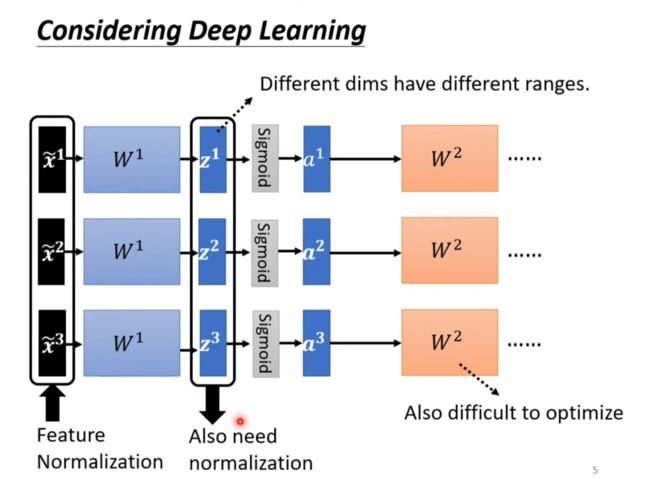



Batch Normalization[插眼,没看太懂]

BN in Test
在训练时先将测试时没有的参数算出来

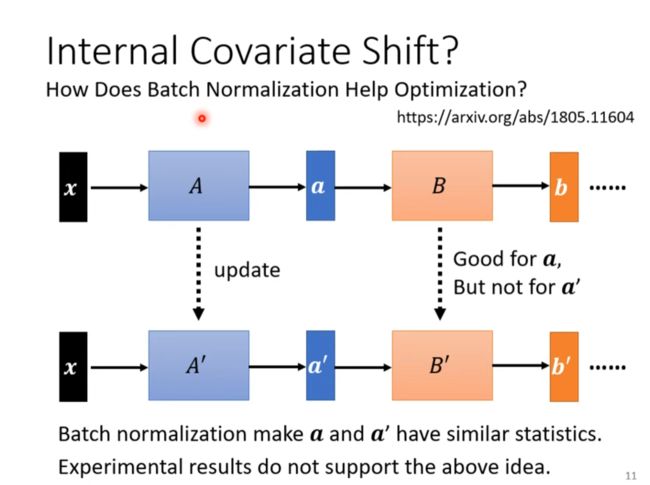
Internal Covariate Shift?
How Does Batch Normalization help Optimization

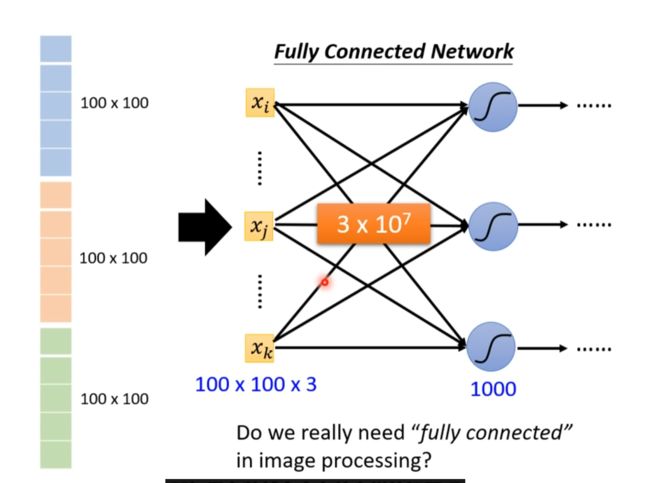
卷積神經網路 (Convolutional Neural Networks, CNN)
Image Classification

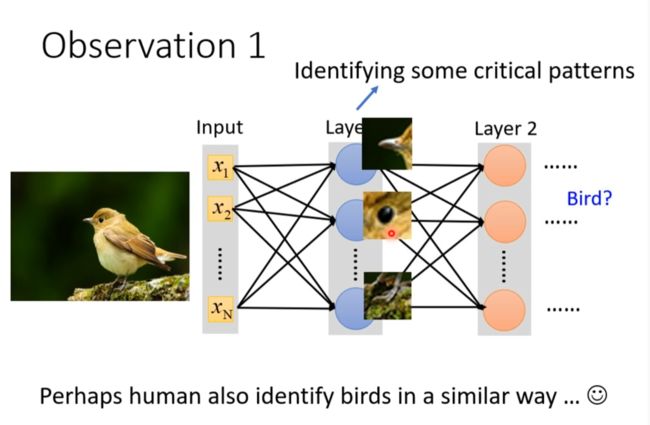
Observation 1 //引出receptive field
y隐藏层一个节点观测图片的一小部分
Simplification 1
receptive field

- Can different neurons have different sizes of receptive field?
- Cover only some channels.
- Not square receptive field?
Typical Setting
Kernel size
stride
overlap
padding

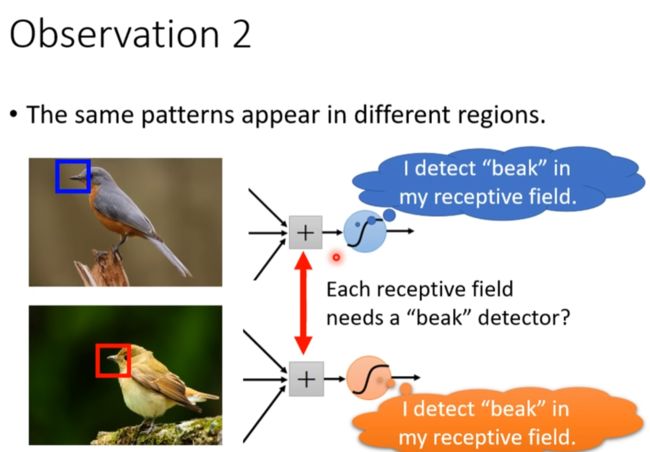
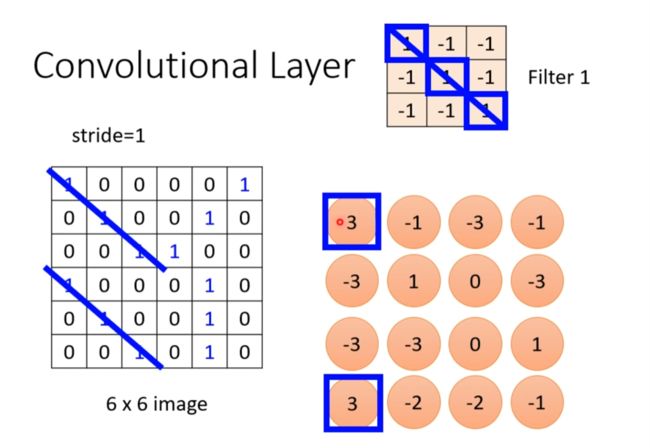
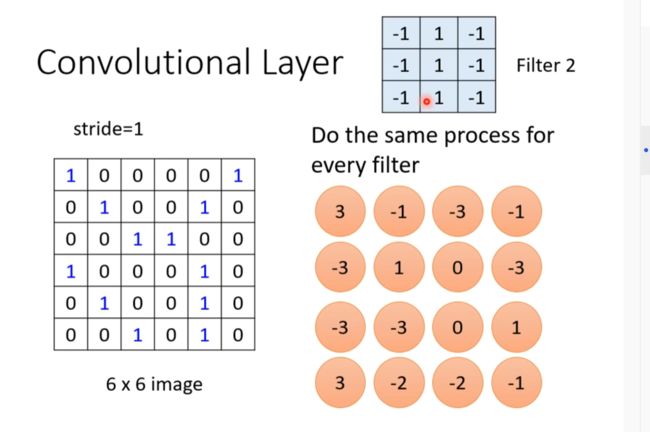
Observation 2 //引出filter
Simplification 2
两个节点照顾的位置不一样,但是参数是一样的

Typical Setting

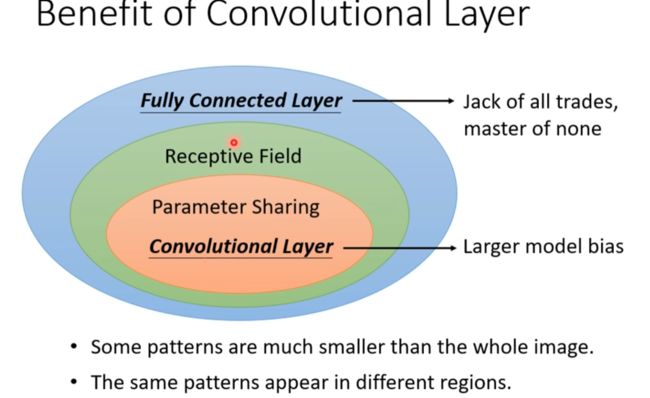
Benefit of Convolutional Layer
弹性逐渐减小
Convolutional layer //另一种说法
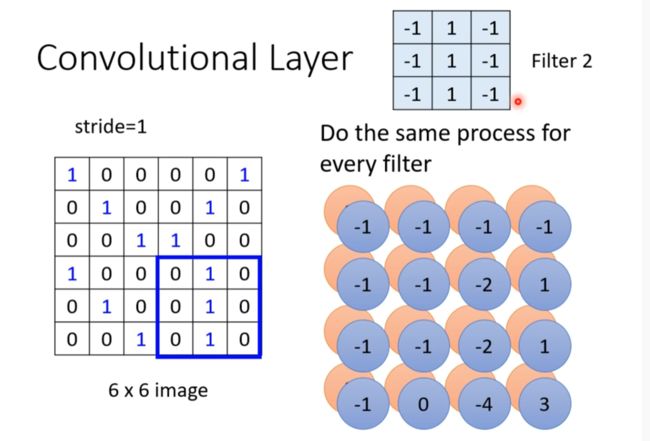

虽然只有3*3,但是后面的层的节点考虑到的会更大
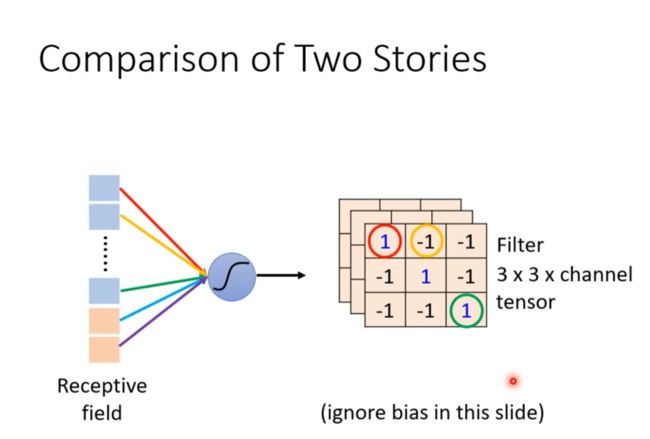
Comparison of Two Stories

Observation 3 //引出pooling

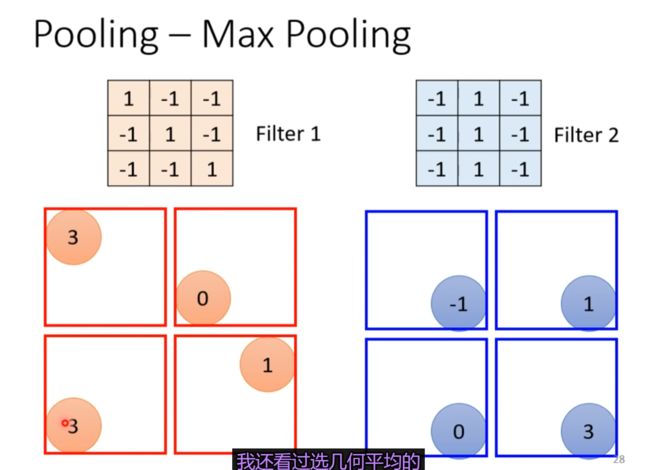
Pooling 把图片变小

最主要的理由是减少运算量
The Whole CNN
Flatten 把所有数值拉直变成向量

Application: Playing Go
下围棋是一个分类的问题
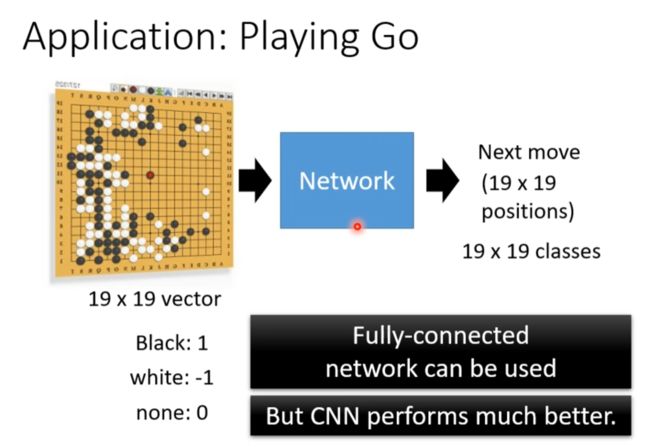

α Go每个棋盘上的位置都有48个属性
Why CNN for GO playing
上面讲的observation跟围棋有相似性。
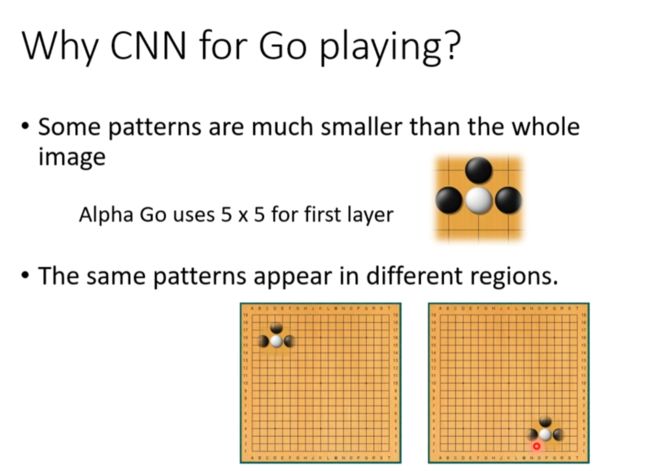
但要注意下围棋不适合用pooling
More Applications

To learn more

自注意力機制 (Self-attention) (上)
regression输出是一个数值 输入是一个向量
classification 输出是一个类别 输入是一个向量
如果更复杂?
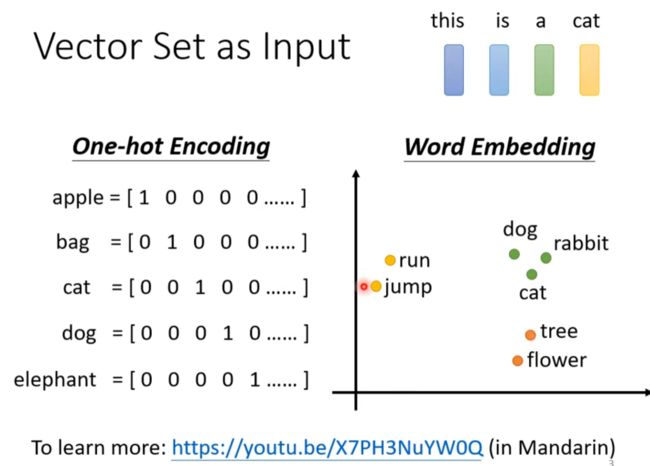
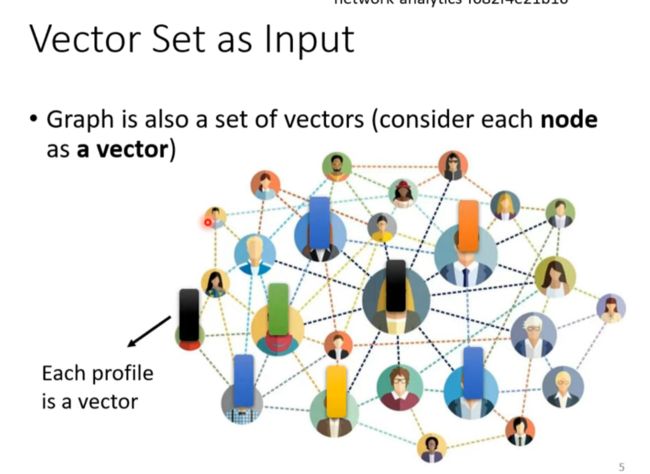
Vector as Input
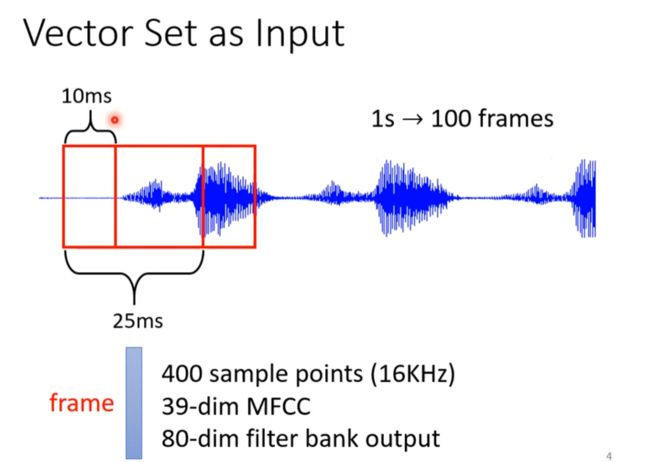
语音,社交网络,分子结构等可以转化为多个向量作为输入
What is the output?
输入数量与输出数量一致
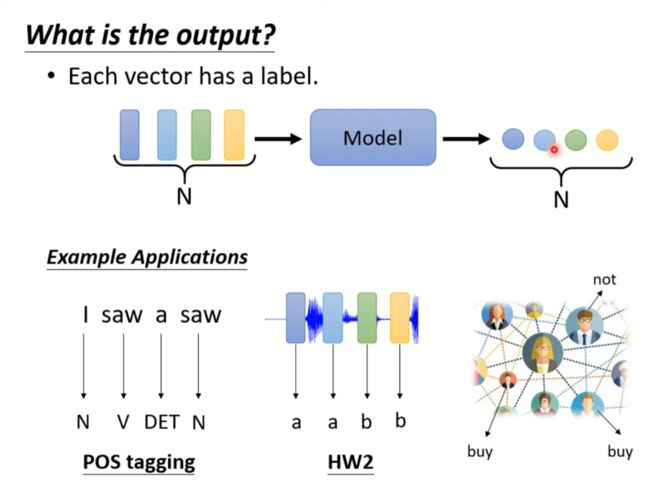
输入输出数量不一致

Sequence Labeling
输入与输出一样多

I saw a saw
不能用fully-connected network,因为同一个词汇出现两次对于fully-connected network 来说是一样的,所以要用窗口,
但是由于输入长度不一定,窗口也就不一定,由此引出self -attention
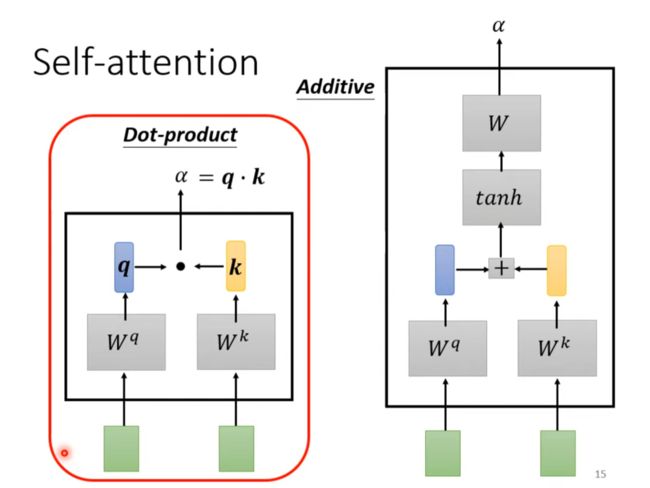
Self-attention

Part of attention network

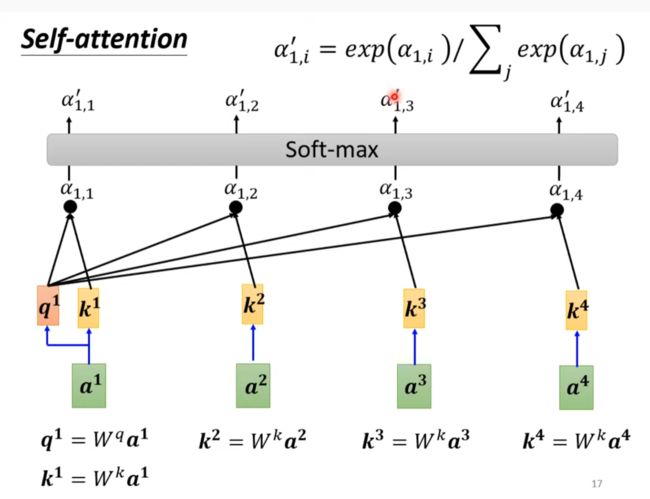
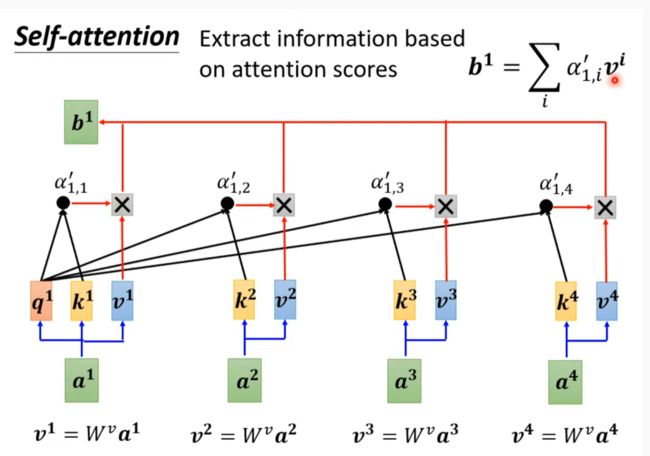
谁的关联性更大,其向量就会更占支配地位,b1就会更像谁

自注意力機制 (Self-attention) (下)
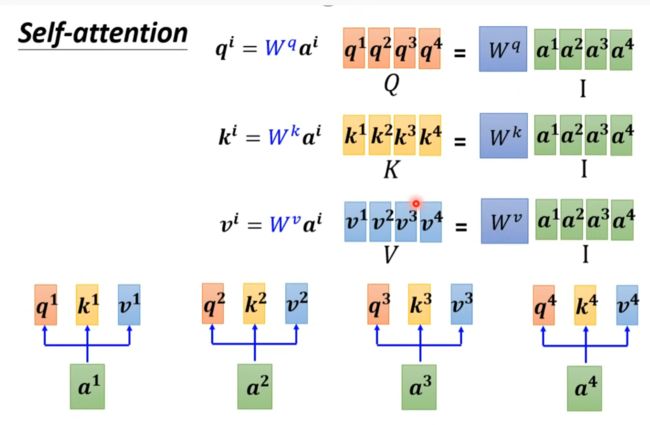
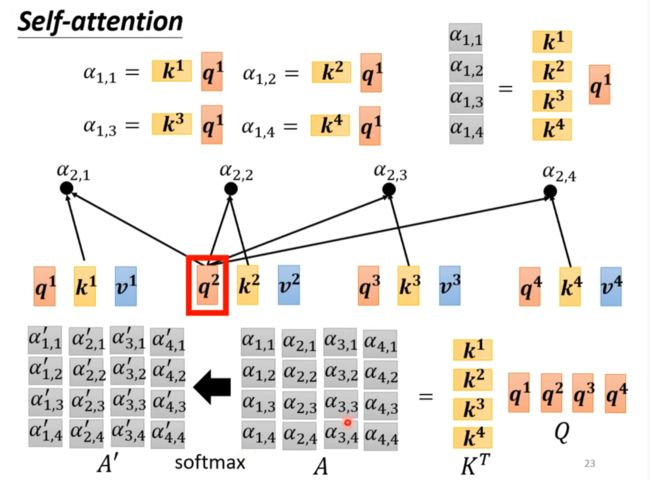

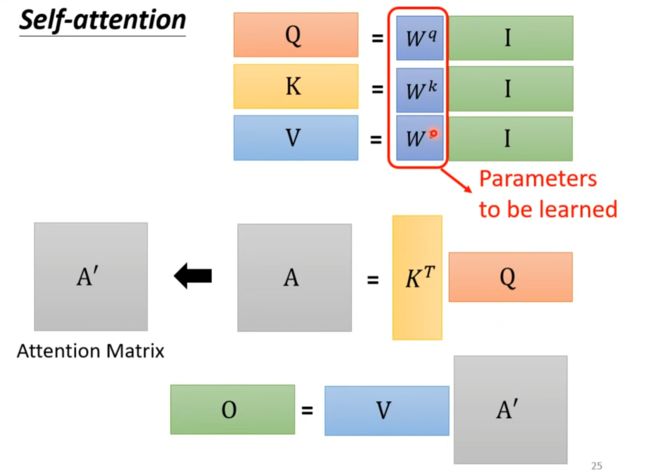
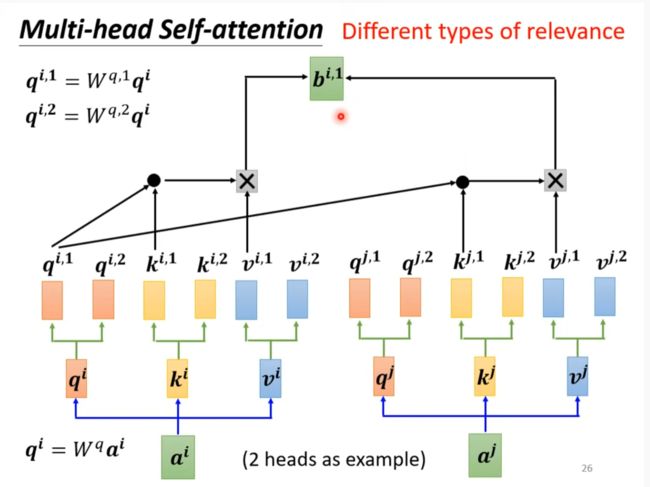
Multi-head self-attention
得到qi,ki,vi后再乘两个矩阵得到两个结果。

Positional Encoding
之前的公式没有结合位置信息

这里每个位置的向量是订好的
后来有了新的动态生成的办法
Application

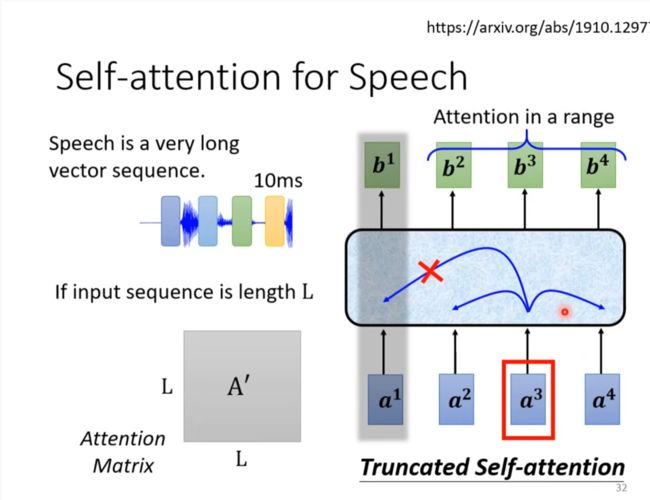
Speech
用于语音识别时要有所更改,因为语音识别所生成的向量太大了,如果结合所有输入的话计算量可能接受不了。
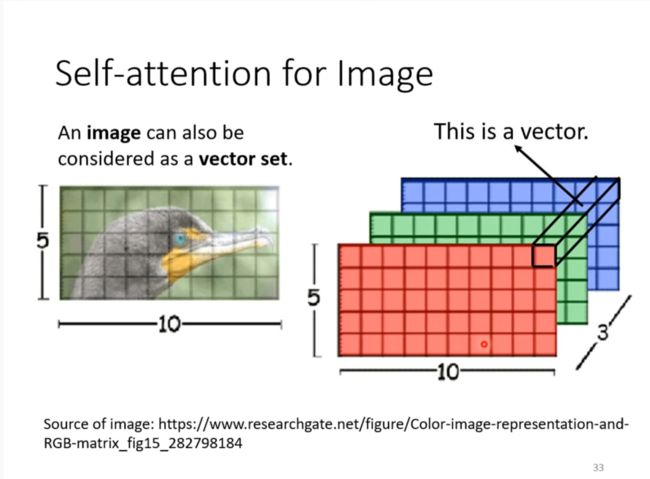
Image

Self-attention for Graph

To Learn more about GNN

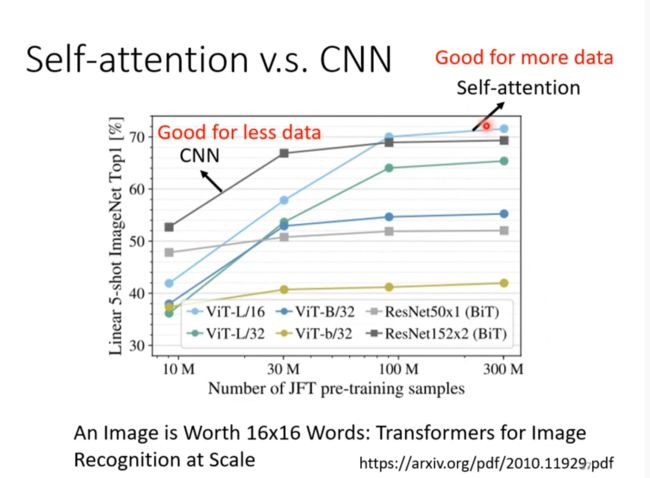
Self-attention v.s. CNN
CNN 可以看作Self-attention的子集,


资料少时用CNN,多时用self-attention,因为self-attention弹性更大(插眼,为啥?),需要的资料更多。
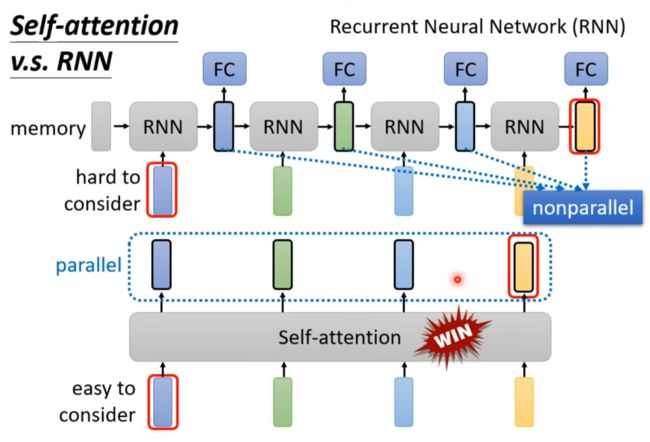
Self-attention vs RNN
RNN:
- 很难考虑远处的信息
- 不是平行的
self-attention:
- 相反

To learn more about RNN

To Learn More
Transformer(上) Encoder
Sequence-to-sequence’s application
transformer 是一个Sequence-to-sequence(Swq2seq) model
输出长度是由模型决定的

由闽南语音直接转为汉字

在翻译倒装句时错误率会更高
Seq2seq for Chatbot
Question Answering 可以理解为Seq2seq model 的问题

Seq2seq for Syntactic parsing
输入句子输出文法分析树
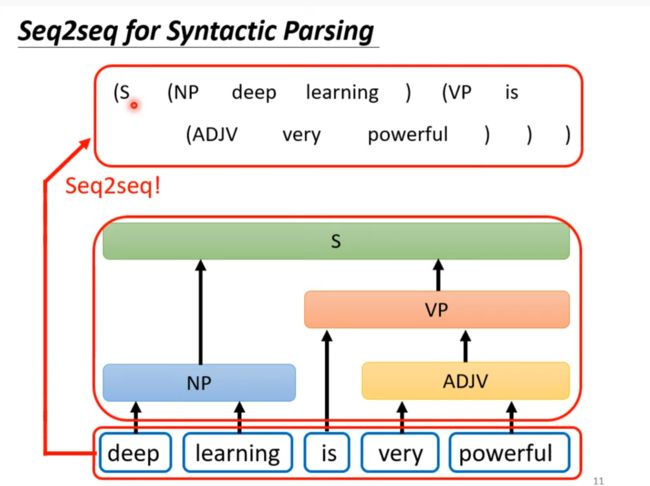

将文法视作一种语言用翻译的模型得到结果
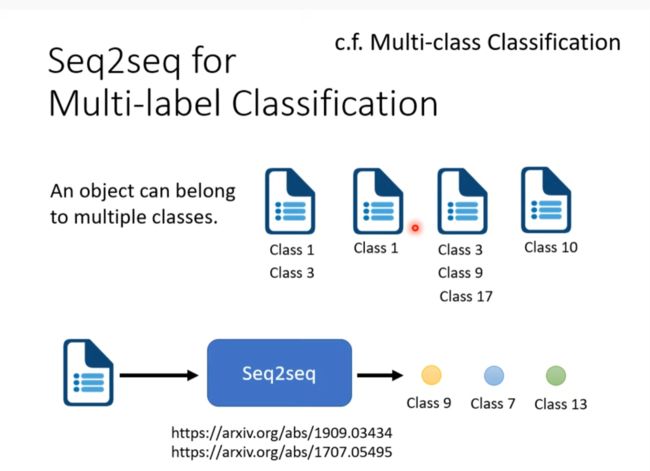
seq2seq for multi-label classification
Seq2Seq for Object Detection

Seq2seq
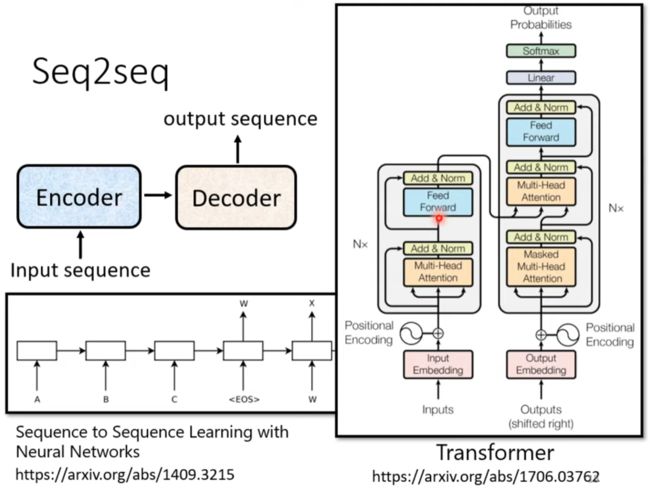
Encoder

先讲个其他的,再回来进行比对

Block原来更加复杂:
batch normalization:对不同example 不同feature同一dimension 计算mean 和 standard deviation,在这里没有用到,用到的是layer normalization,他是对不同统一example 同一feature的不同dimension计算mean 和standard deviation.

最后回到encoder的结构,其实是一样的
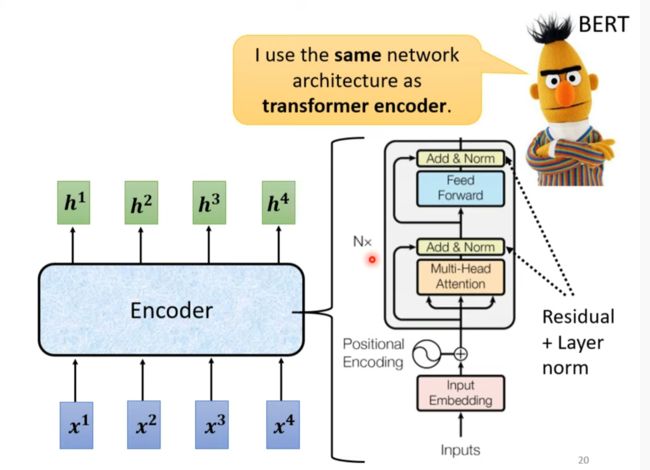
To learn more

Transformer (下) Decoder

Autoregressive(Speech Recognition as example)(AT)
一步错步步错
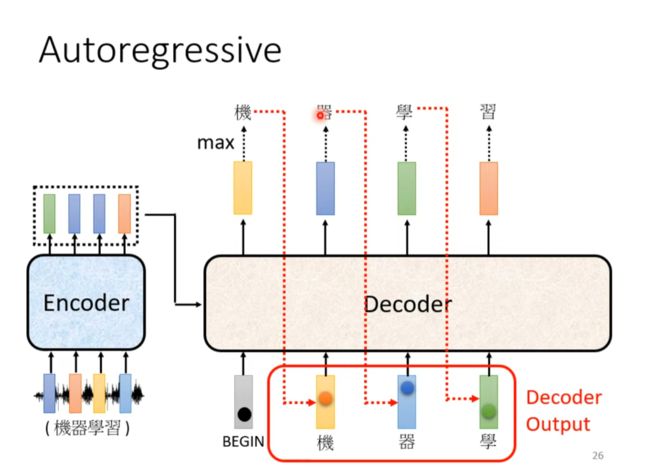
Decoder

除了篮框这部分其他的和encoder很像,除了multi-attention 加了mask

Masked multi-head attention
在计算b2时没办法把考虑a3,a4,因为还没生成出来,模型是从左至右计算的


Stop Token: We don’t know the correct output length
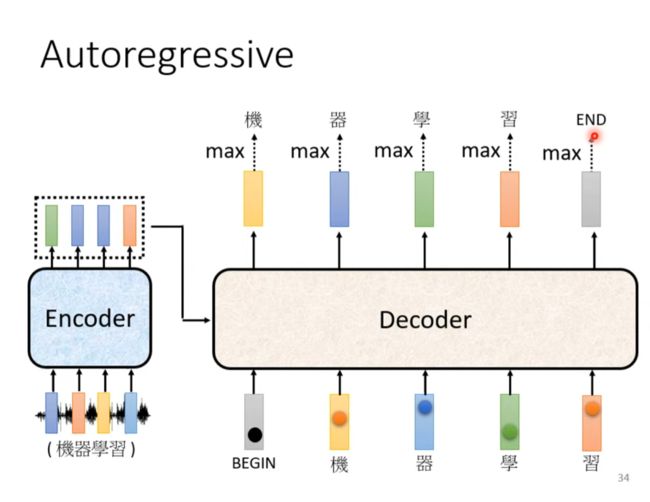
Non-autoregressive(NAT)
优势在于平行输出,所以时间会变快。而且可以控制输出长度。

To learn more about nat

Encode-Decoder
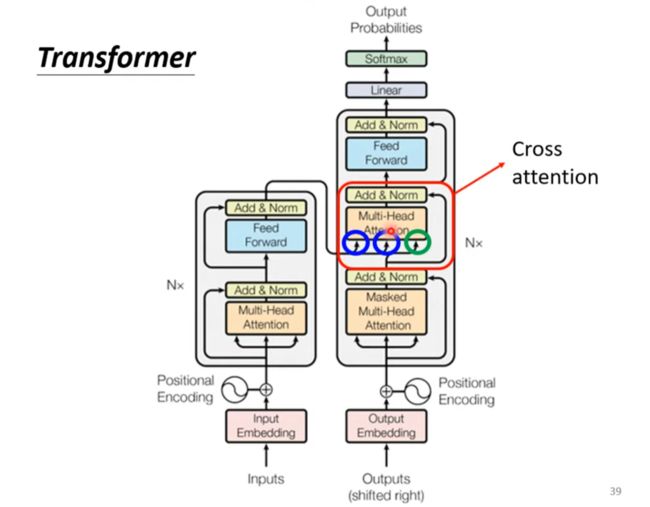
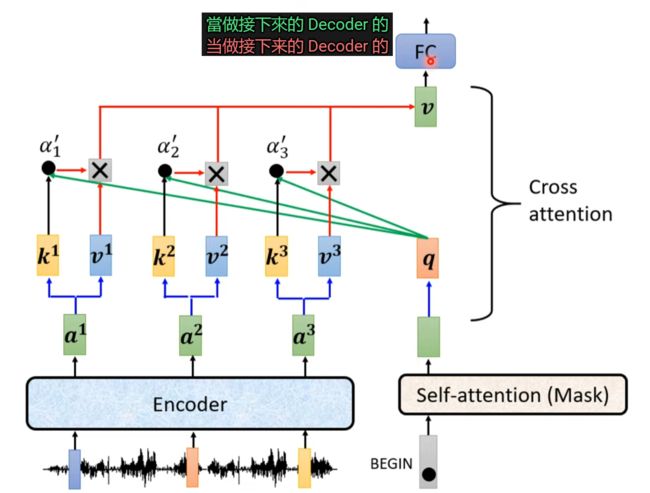

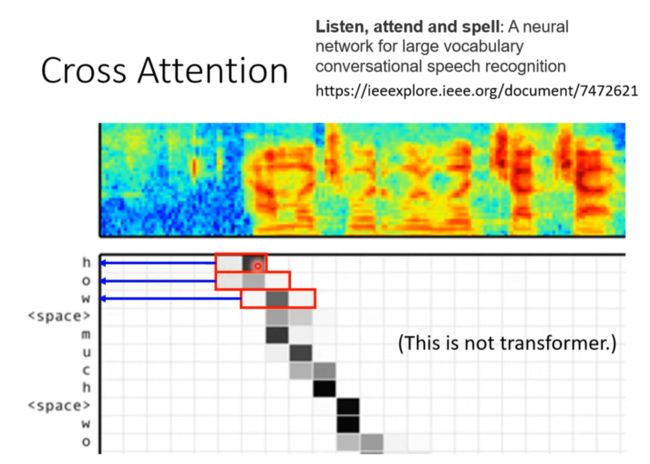
Cross Attention
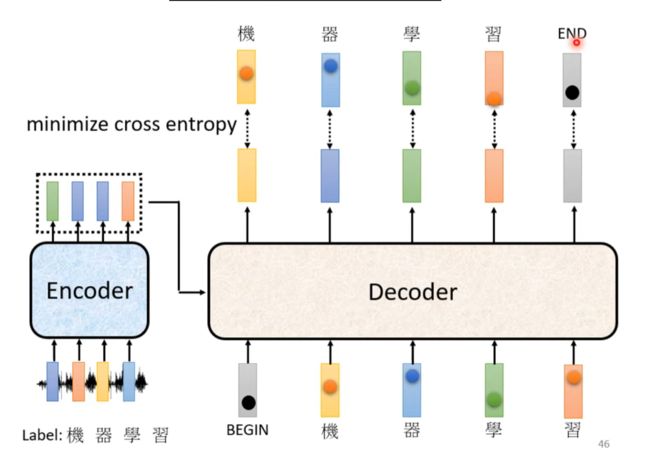
train
使用已经有结果的数据
给正确答案,希望输出越接近越好
Teacher Forcing
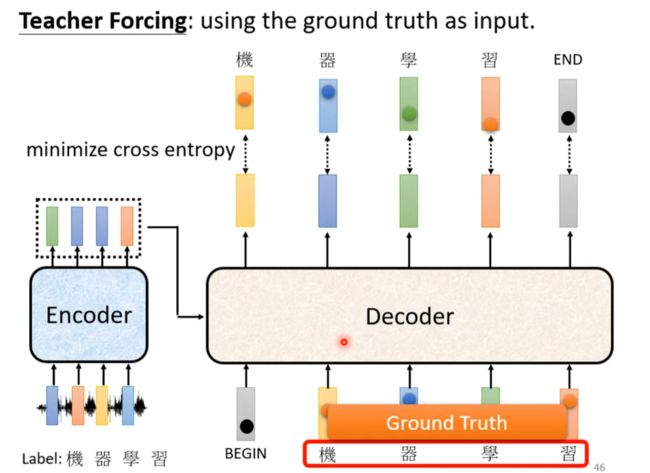
tips about train seq2seq
Copy Mechanism

To learn more

Summarization

Guided Attention
强迫attention有一定固定的行为,比如语音识别必须由左向右


Beam Search
尝试多种可能性

有争议,很多人说很烂
因为有可能说重复的话,但是加入一点杂音反而会好很多,说明分数最高的路不一定就是最好的答案。
有明确答案的任务效果更好,需要发散思路的问题可能更需要加入杂音。
另外,tts需要加入杂音才能更好的产生结果

Optimizing Evaluation Metrics?
训练用Cross entry评价用BLEU score.

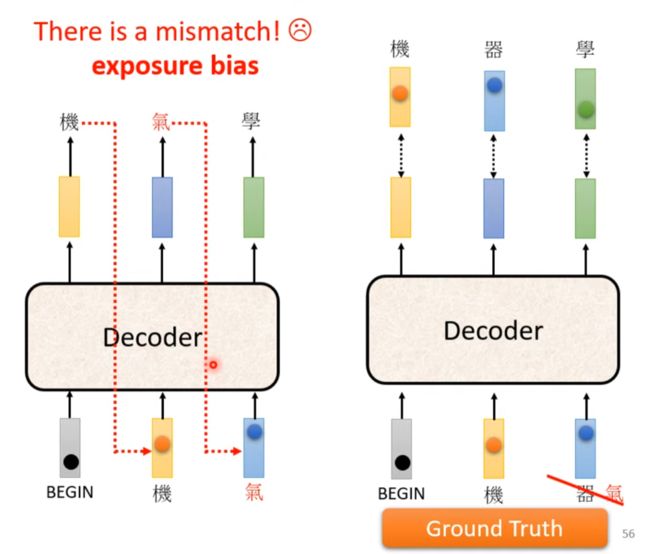
训练和测试不一致(Exposure bias)
训练永远看到的是正确的东西,测试会有错的
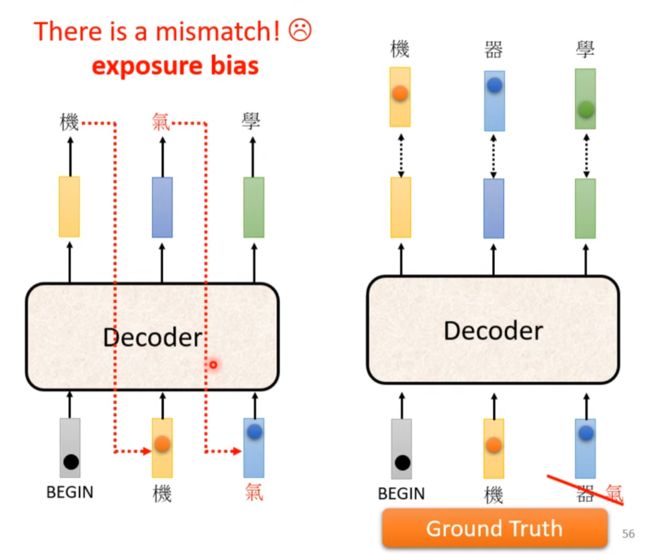
Scheduled Sampling
训练时给点错误的
生成式對抗網路 (Generative Adversarial Network, GAN) (一) – 基本概念介紹
Network as Generator

两个结合输出一个新的分布。
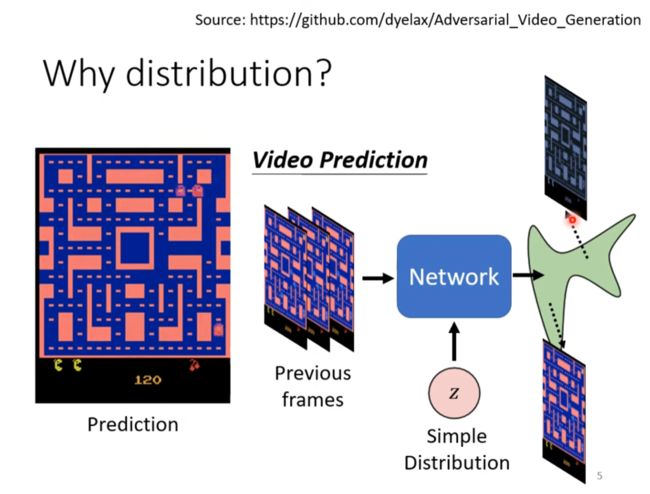
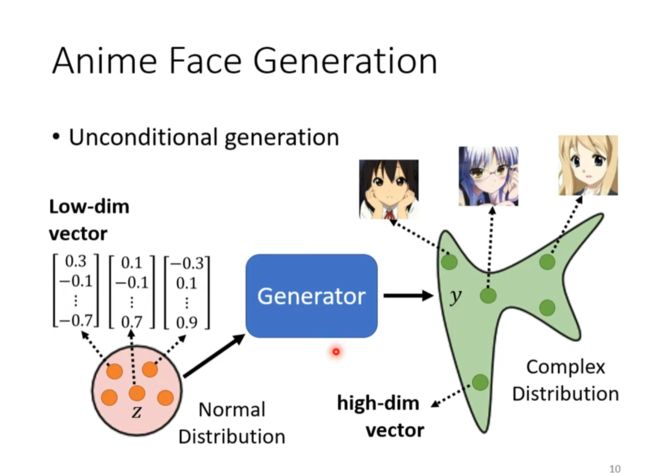
为什么要输出一个分布?
由于问题的发散产生了分支(过于发散),这时往往会需要输出一个分支

训练中可能会出现同时向左向右转的现象

GAN
Anime Face Generation
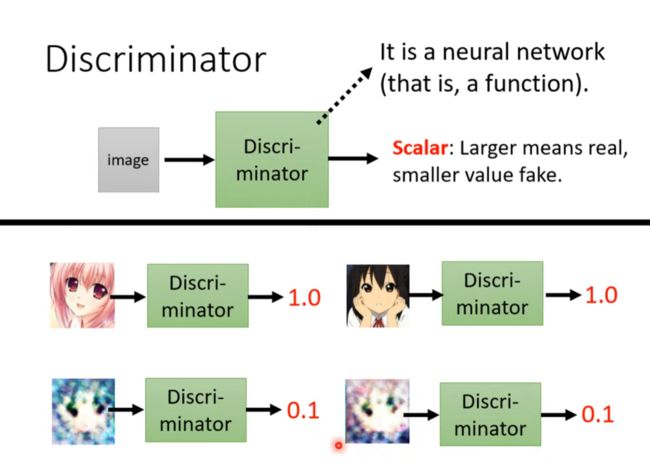
Discriminator
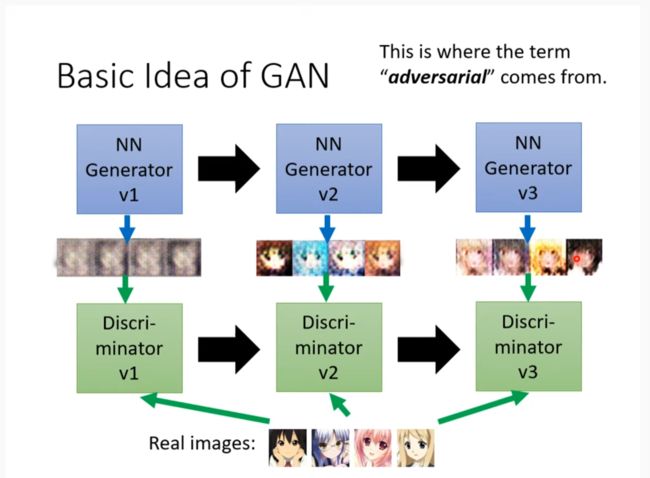
Basic Idea of GAN
两相竞争
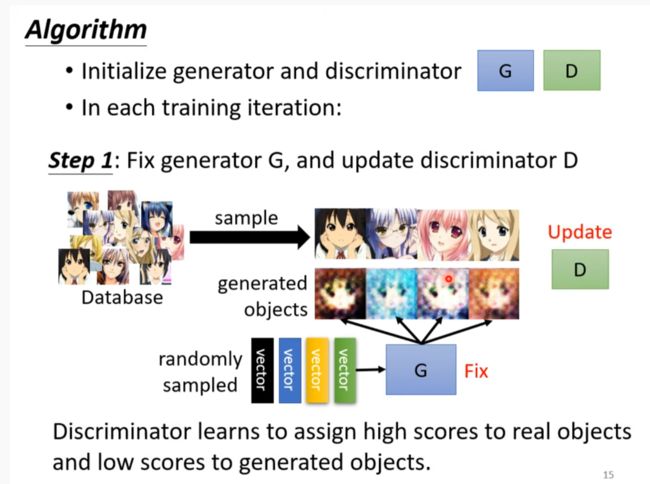
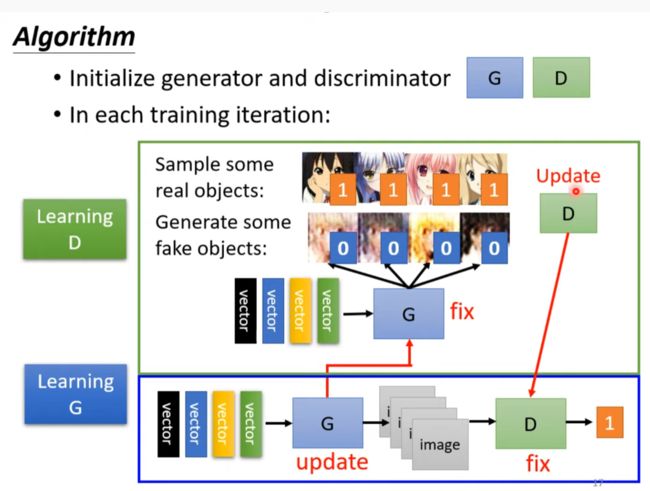
Algorithm
discriminator不断的将生成的和实际的图片分类出来,generator为了不被分辨出来儿不断进步

Progressive GAN

生成式對抗網路 (Generative Adversarial Network, GAN) (二) – 理論介紹與WGAN
Our Objective

But it is too hard to compute the divergence
How to solve the problem of divergency(sample and discriminator)

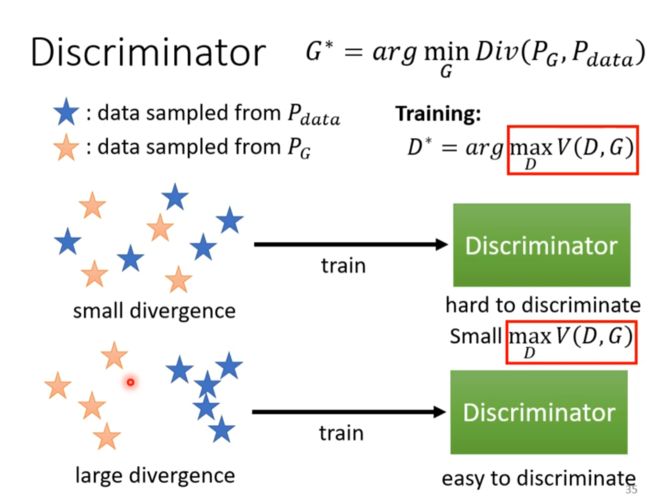
Discriminator
D* 与divergence 相关


can we use other divergence?

Tips of gan
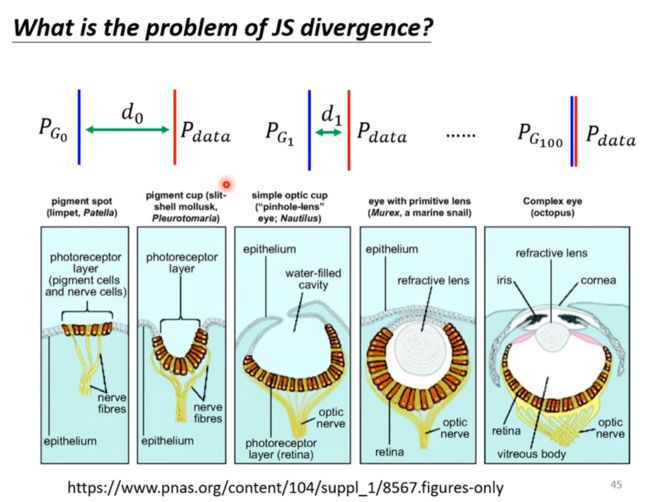
JS divergence is not suitable

如果取样太少的话,命名generator已经取得了进步但是无法在discriminator 体现不出来

只要没有相交js divergence就为log2,但是有可能已经进步了,只不过没有达到那个程度。

Wasserstein distance
让一个分布与另一个分布重合所用的精力

但是当分布复杂时,想让它们重合有不同的moving plan,所以需要穷举。


WGAN


生成式對抗網路 (Generative Adversarial Network, GAN) (三) – 生成器效能評估與條件式生成
GAN is still challenging
如果一方停下了,没办法再前进的话,另一方也会停下。

GAN for Sequence Generation
如果有多个输出且去max的话,那么其他输出的参数因参数的变化而增长是无法体现出来的


For more


为什么用GAN
因为GAN目前效果比VAE FLOW好。。。即使是它比较难train也比其他的方法也不会难太多
Possible Solution
Train一个输入向量,输出图片的模型

Quality of Image


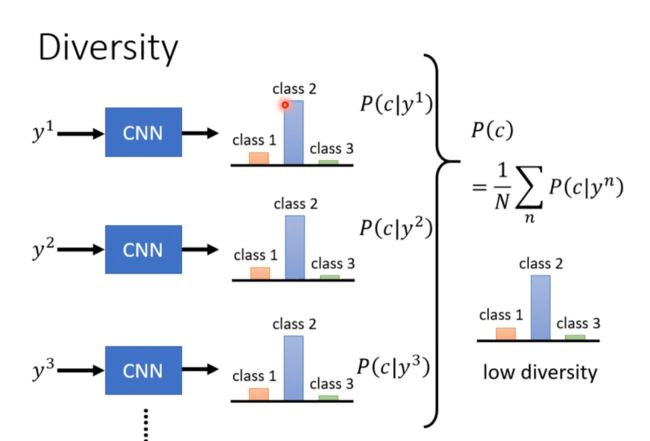
Diversity - Mode Collapse
Discriminator万一有弱点被generator抓到的话。。。
Diversity - Mode Dropping
看似分布和质量都合理,但是其实真实数据比这更大

用分类器分类的结果如果过去集中则可能是这个问题
如果够平均则可能没有这个问题。
Frechet inception Distance(FID)(插眼)

We don’t want memory GAN
产生的跟训练资料的一模一样是不行的
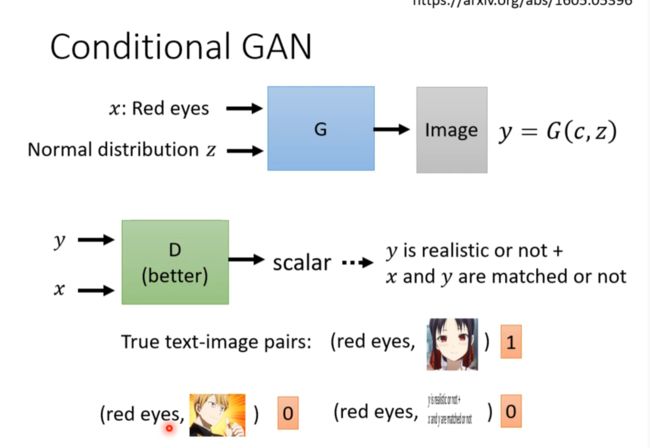
Conditional Generation
Text to image


Application


生成式對抗網路 (Generative Adversarial Network, GAN) (四) – Cycle GAN
Learning from Unpaired Data(无监督)
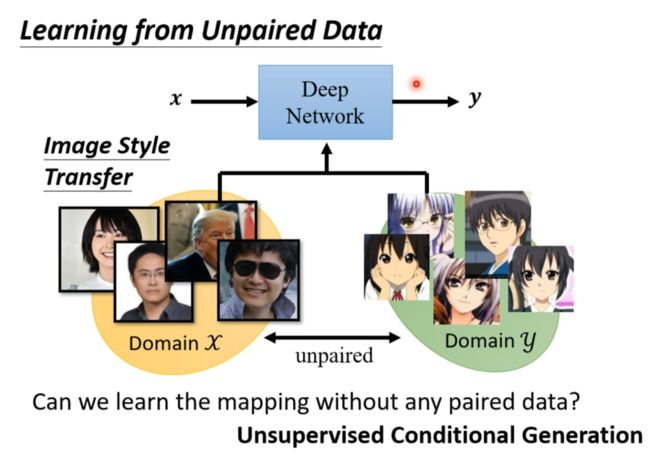


没有成对的资料来训练

由于有了还原,产生的图片就不能和输入差太多(保证有一些关系(即使很奇怪(暂时还没啥好解法)))

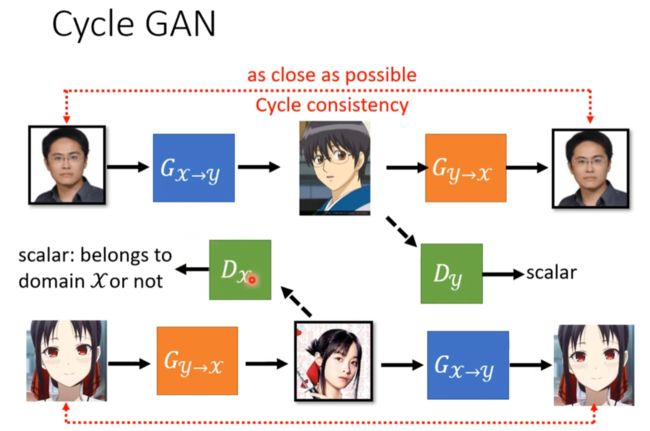
more


SELFIE2ANIME

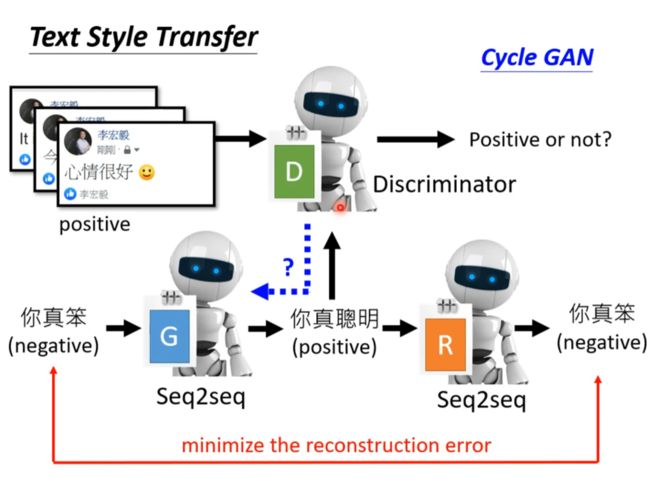
Text Style Transfer
Other
自督導式學習 (Self-supervised Learning) (一) – 芝麻街與進擊的巨人

自督導式學習 (Self-supervised Learning) (二) – BERT簡介
Self-supervised Learning
Masking Input
Next Sentence Prediction
分辨两个句子是不是该接在一起
被认为不是很有用,model没有学到很多东西
Downstream Tasks 将前面的训练结果用在其他训练上
GLUE

How to use BERT
Case 1 input asq output class
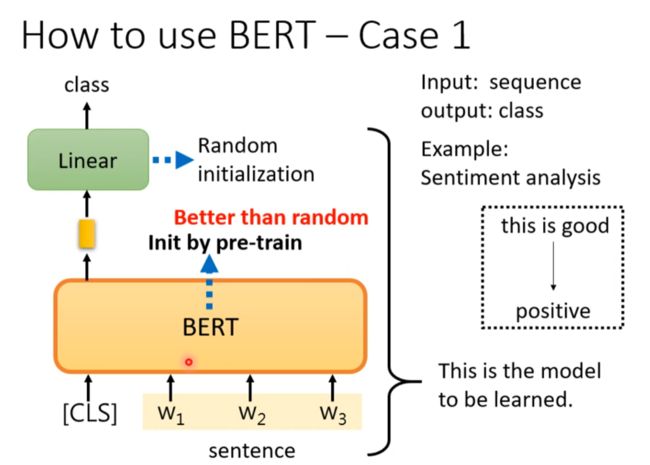
Case 2 input seq output same as seq
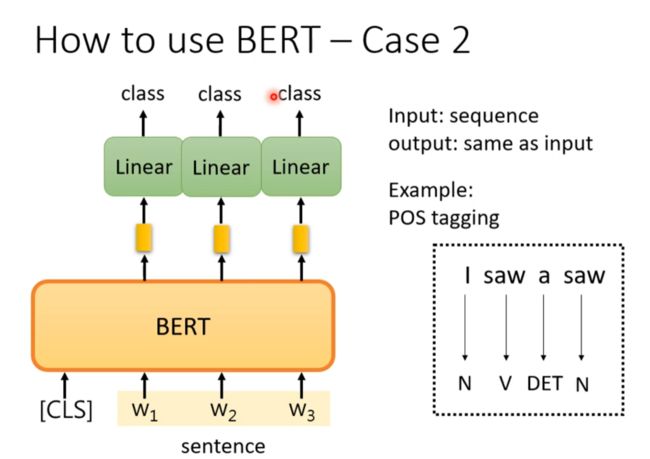
Case 3 input two seq output class

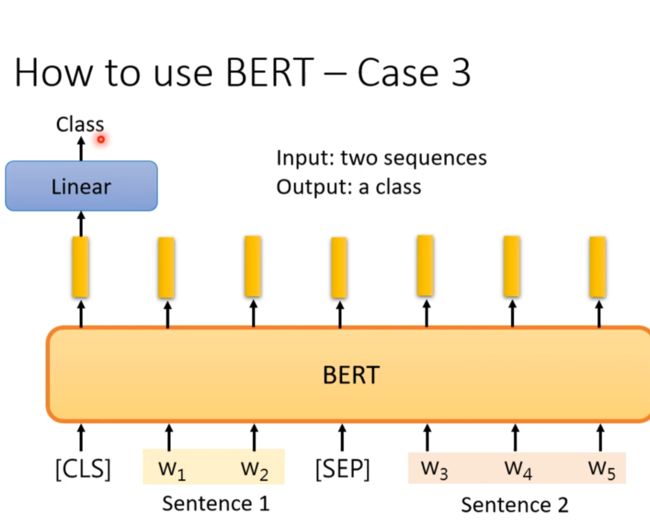
Case 4 input document and query output answer


Training BERT is challenging

BERT Embryology(胚胎学)
了解BERT学习到知识的细节
Pre-training a seq2seq model
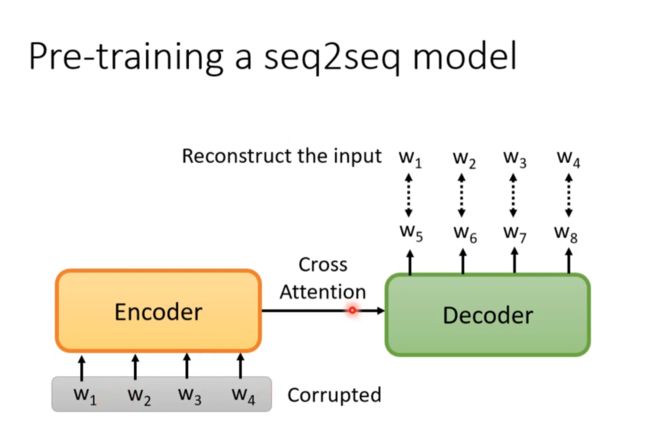
输入encoder弄坏的数据,decoder输出没坏的数据

自督導式學習 (Self-supervised Learning) (三) – BERT的奇聞軼事
Why does BERT work
同一个字有不同的意义
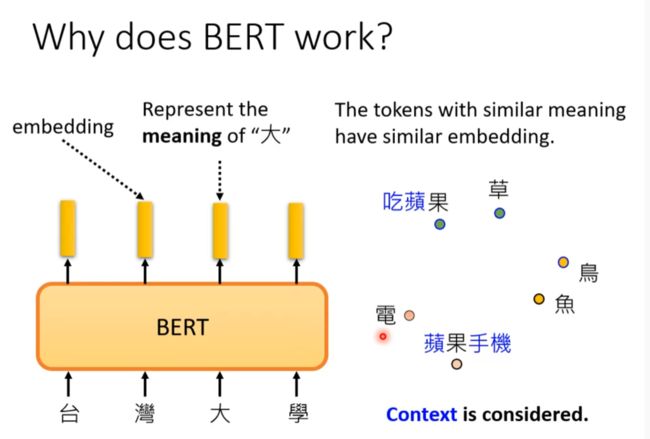
一个词汇的意思取决于它的上下文
Applying BERT to protein,DNA,music classification


Multi-lingual BERT
训练在英文反而在中文的test上取得了进步
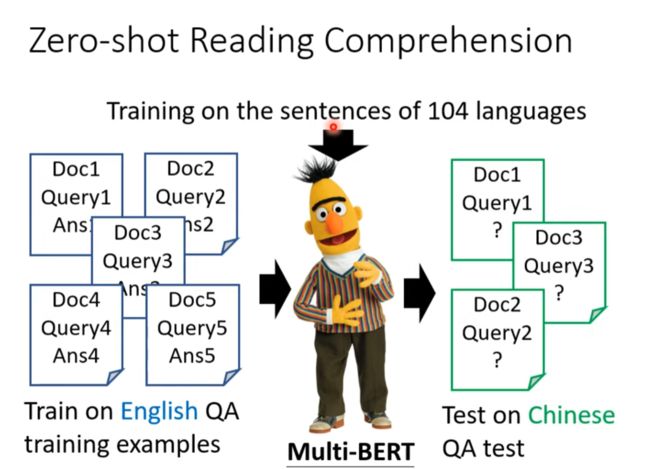

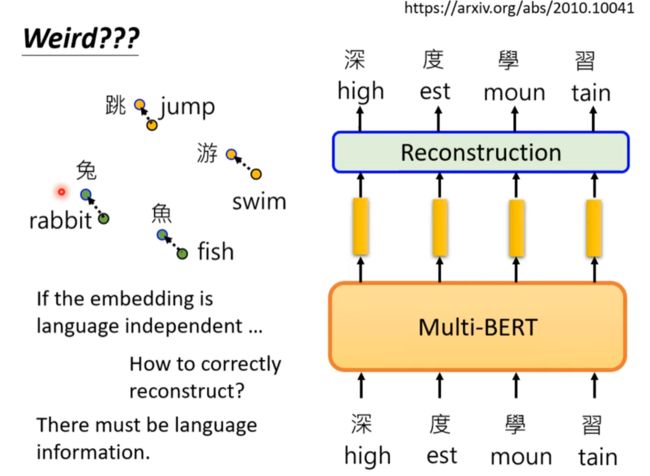
Cross-lingual Alignment(一种解释)

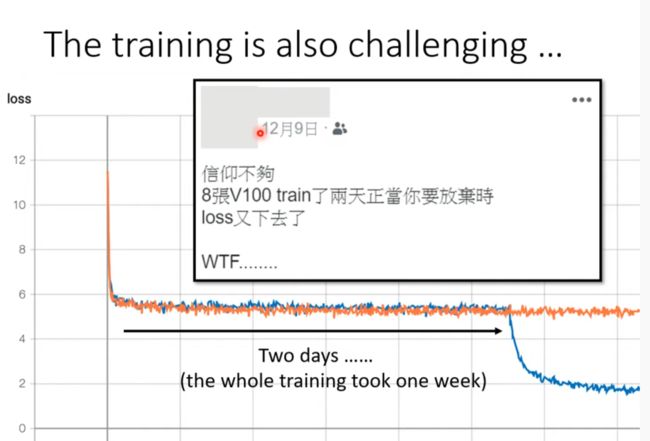
似乎不同语言向量的差异就是语言的信息?

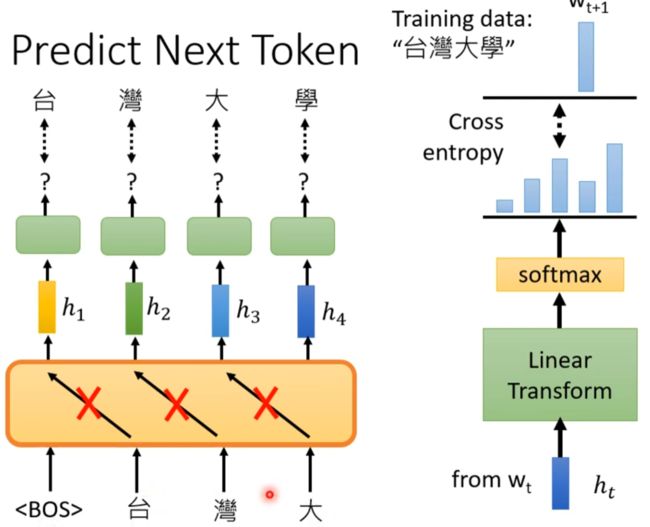
自督導式學習 (Self-supervised Learning) (四) – GPT的野望
如下,只不过是数据量特别大
How to use GPT

Few-shot learning (no gradient descent) “In-context” Learning
只用很少的资料去训练。效果见仁见智


Beyond Text
Image
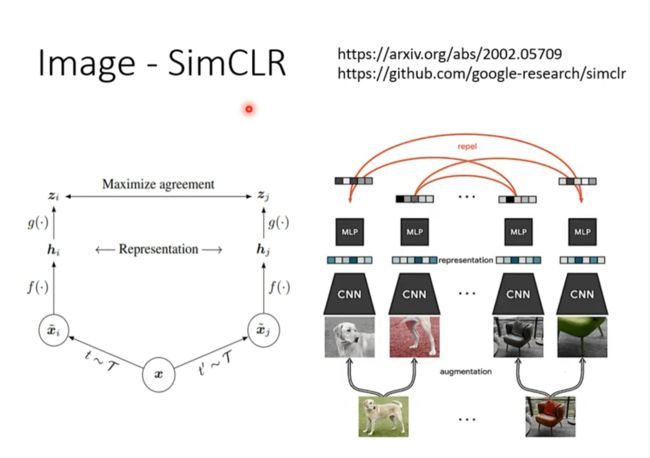
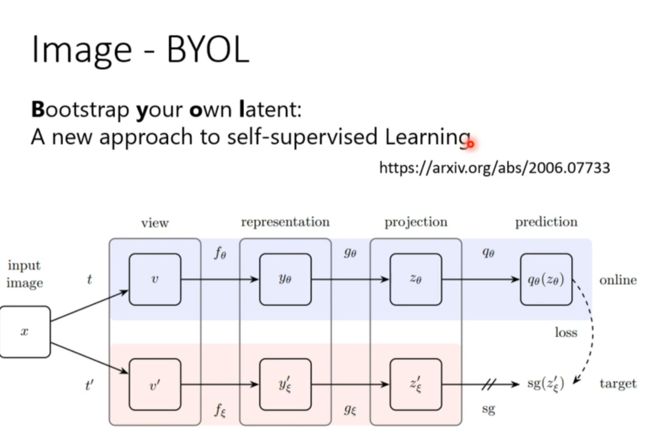
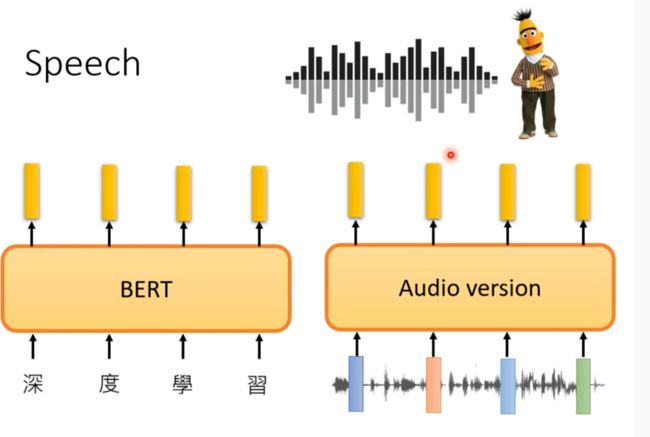
Speech
语音方面暂时没有公认的像GLUE的资料库
他自己做了一个

Application of self supervised
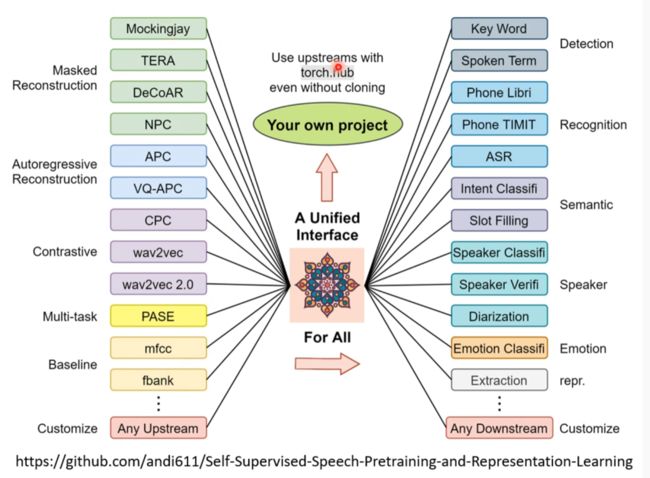
自編碼器 (Auto-encoder) (上) – 基本概念
Outline

review of self-supervised learning frame work
学习没有标注资料的任务,在有bert gpt之前,就有了auto-encoder。
auto-encoder in image
Dimension reduction

for more

Why auto-encoder?

并不是3*3的向量都是图片,其形式是有限的,所以可以用更小的维度表示3*3的图片。
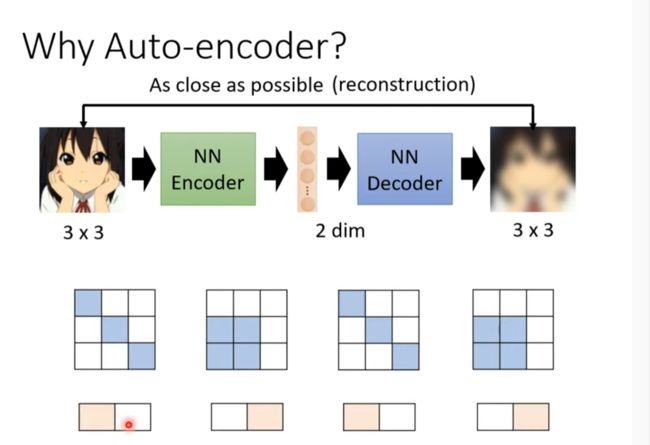
Auto-encoder is not a new idea

De-noising Auto-encoder


自編碼器 (Auto-encoder) (下) – 領結變聲器與更多應用
Feature Disentangle
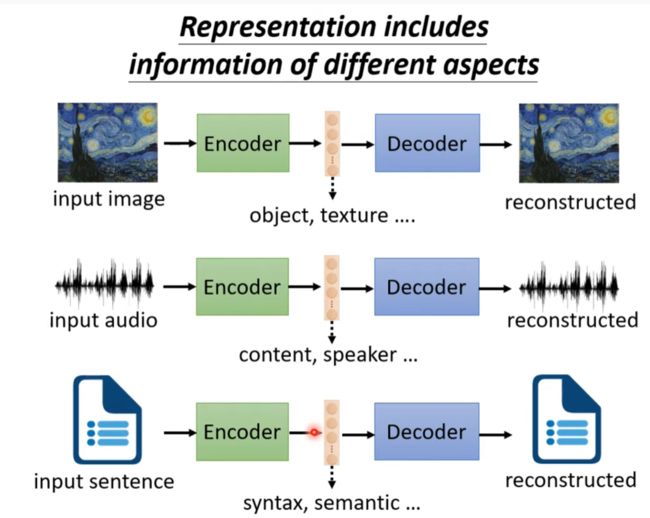
分解中间向量,理解其信息
Representation includes information of different aspects

Application: voice conversion
不需要资料库中两个人说一样的话。

discrete representation

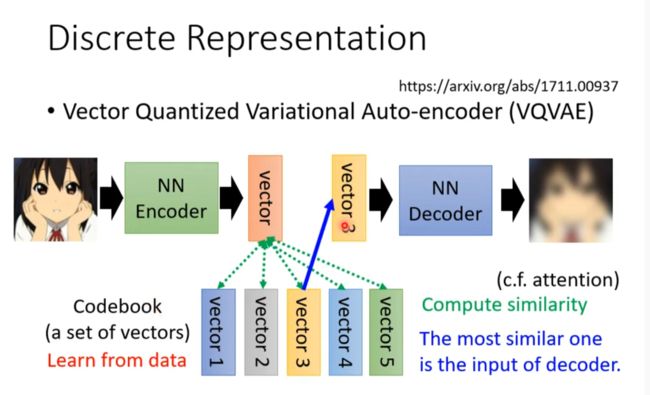

固定输出的可能性,不是无限的而是离散的
Text as representation

强迫encoder train出人话一样的中间向量。
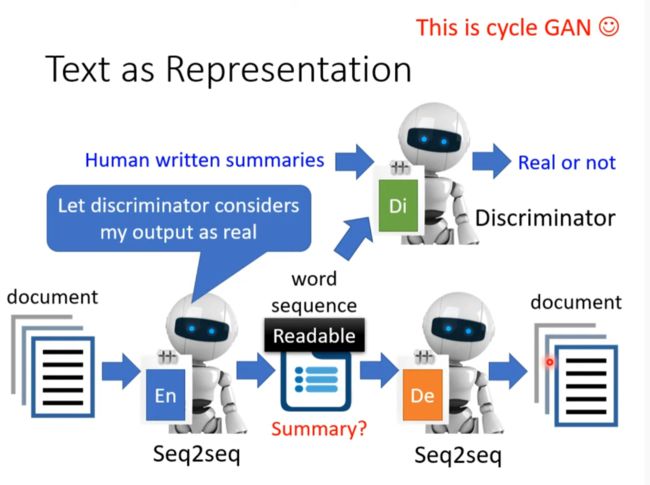


Tree as Embedding

Generator

Compression

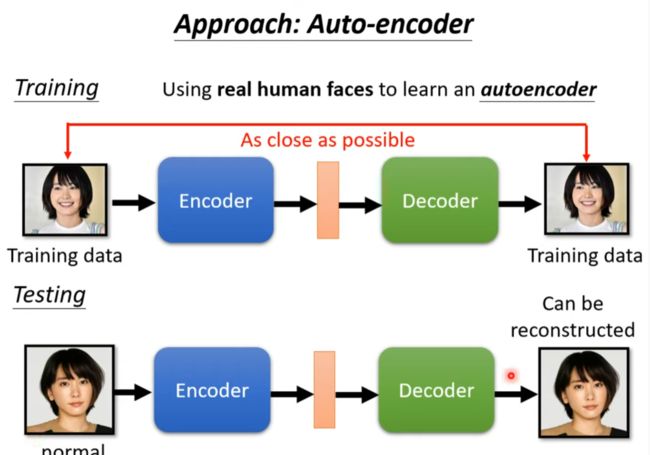
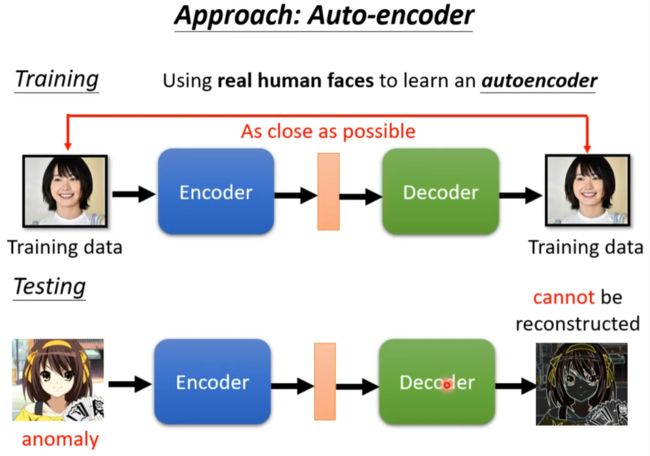
Anomaly Detection


用来探测异常交易,异常请求,异常病情等
和分类器还是有区别的,因为训练资料大多数只有一类

For More

來自人類的惡意攻擊 (Adversarial Attack) (上) – 基本概念
Motivation
需要在有人试图欺骗他的情况下正常工作

How to arrack
Example of attack
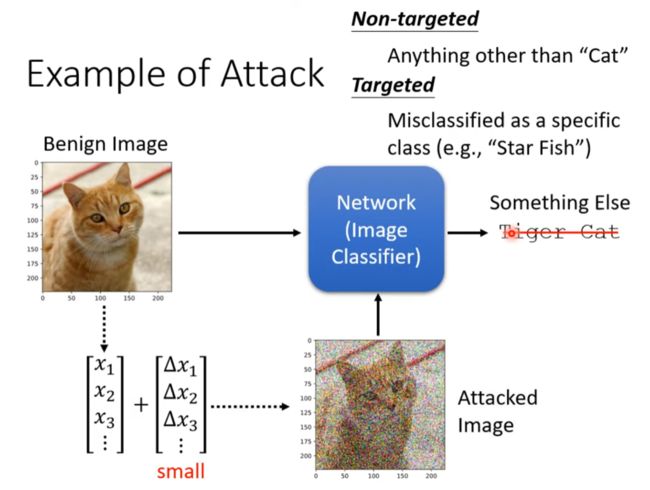

正常的错误应该是这样的
含恶意的噪音
尽量让正确的目标概率变小,让目标概率变大,同时尽量让差距小于人类能感知的差异的最小值

Non-perceivable

Attack Approach
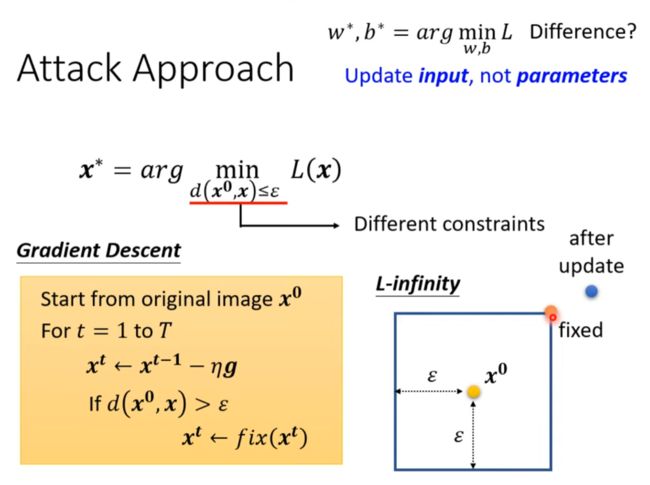
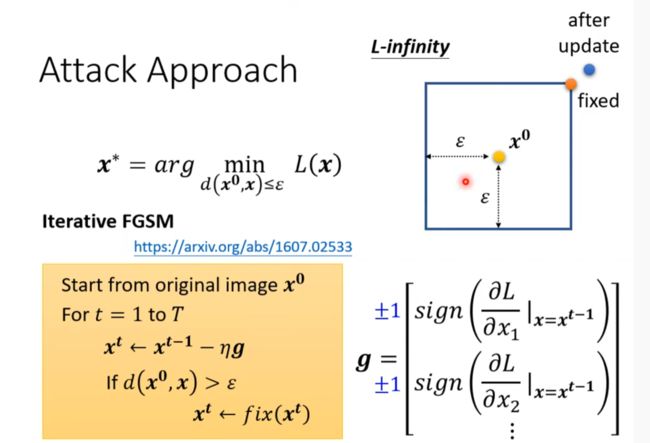
來自人類的惡意攻擊 (Adversarial Attack) (下) – 類神經網路能否躲過人類深不見底的惡意?
White Box vs Black Box

Black Box


不同的数据产生的结果截然不同

One pixel attack
只改变一点导致结果改变

Universal Adversarial Attack

Beyond Images

Attack in the Physical World

Backdoor in Model

Solution
模糊化,让攻击信号被改变
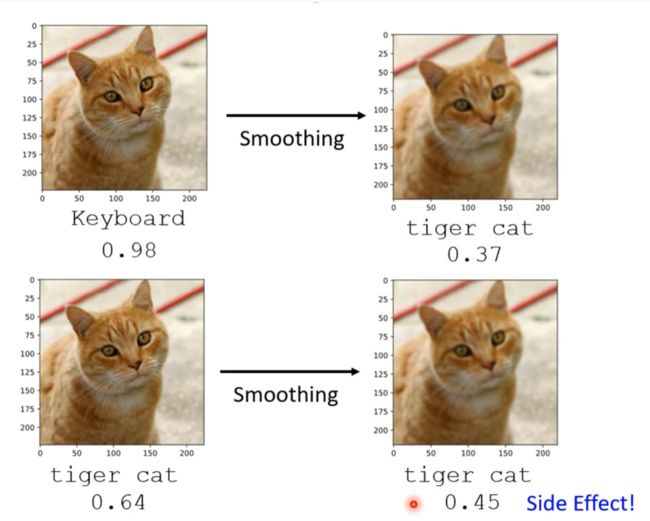

但是如果被知道了使用了这种方法,攻击时也可以加上这个,所以可以加上随机性

## Proactive Defense
自己攻击自己然后把攻击数据学习进去

機器學習模型的可解釋性 (Explainable ML) (上) – 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢?
Why we need Explainable ML?


Interpretable vs powerful



Goal of Explainable ML

人们只是需要一个理由去接受 - .-
Explainable ML
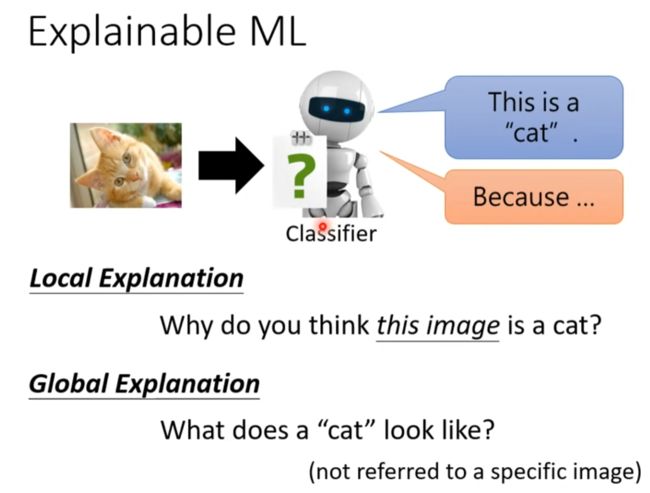
Local Exception
改造或删除某部分导致结论错误,那么它就是原因

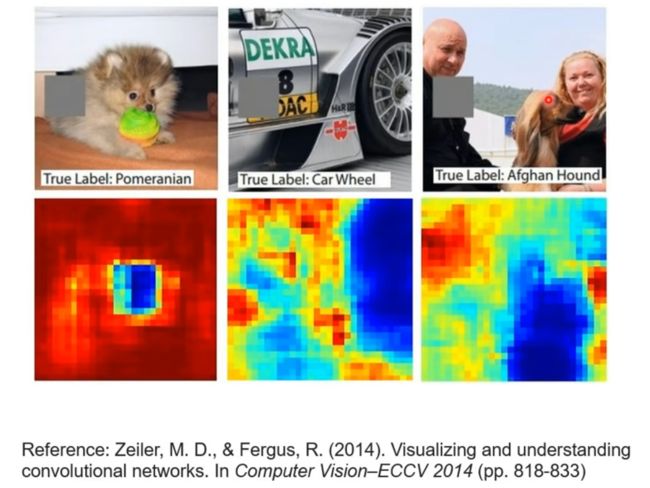
更改向量的值,计算偏导数,得出是哪个参数更重要
Saliency Map

A test


结果是由于数据错误,,,背景问题
因为介绍文字而判断图片

SmoothGrad

Gradient Saturation
如果在平滑处取导数的话会得出鼻子长度与判读大象无关的结论


How a net work process the input data
为了观察过程压缩中间向量的维度
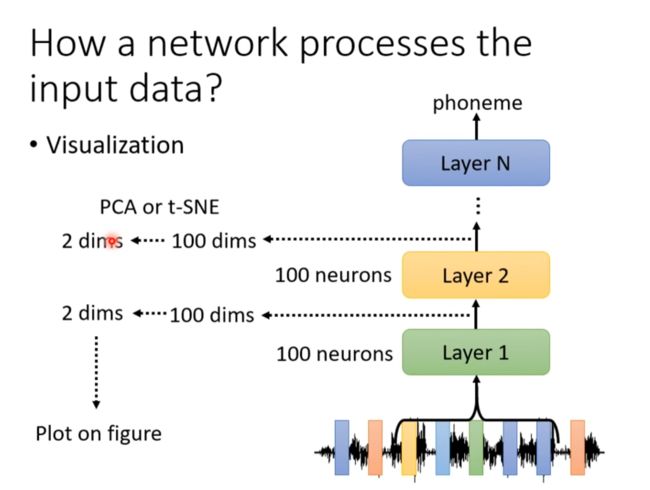

很多问题尚待研究。。
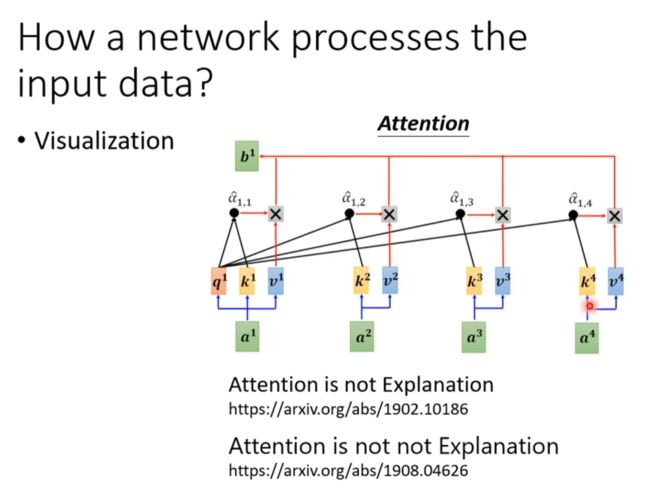
用探针处理中间向量
但注意Classifier的正确情况
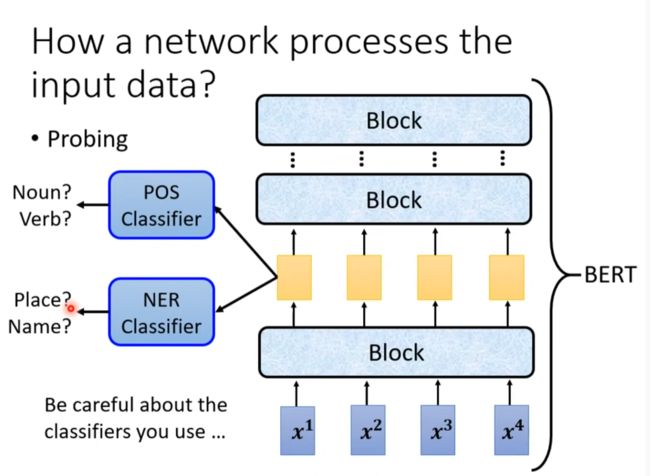
example
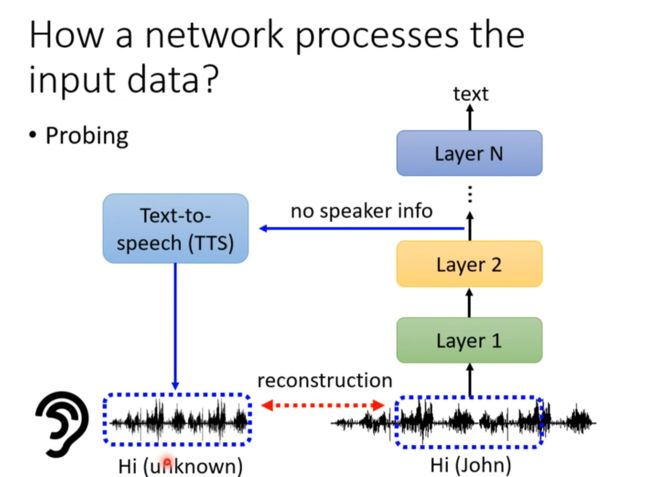
在不同层加探针看语音到底在那里失去了性别信息,或者杂音。
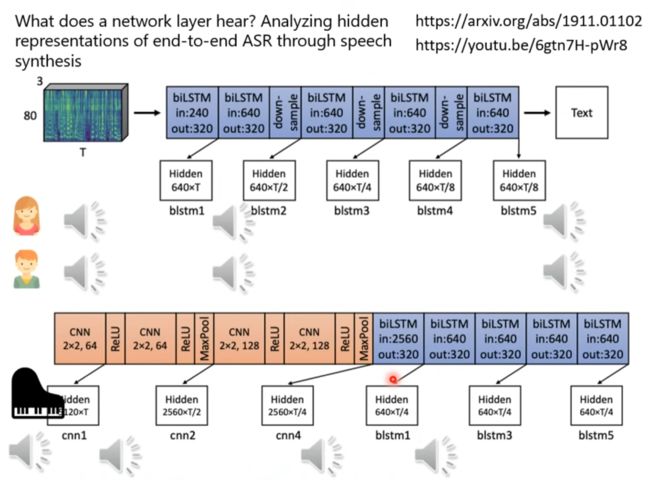
機器學習模型的可解釋性 (Explainable ML) (下) –機器心中的貓長什麼樣子?
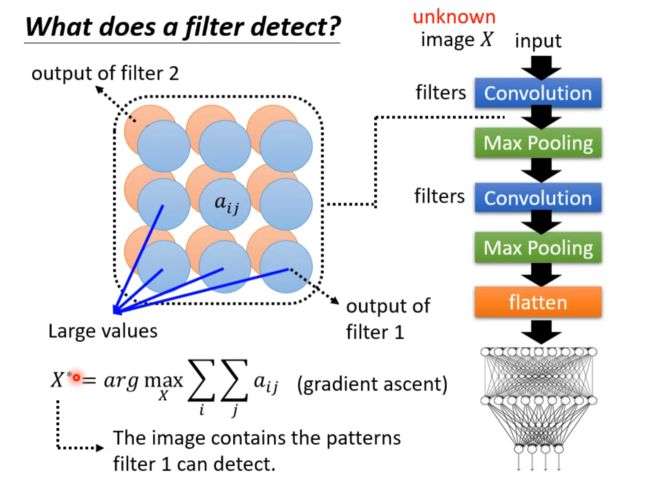
What does a filter detect?(插眼,他在说什么)
通过filter观察模型在观察什么
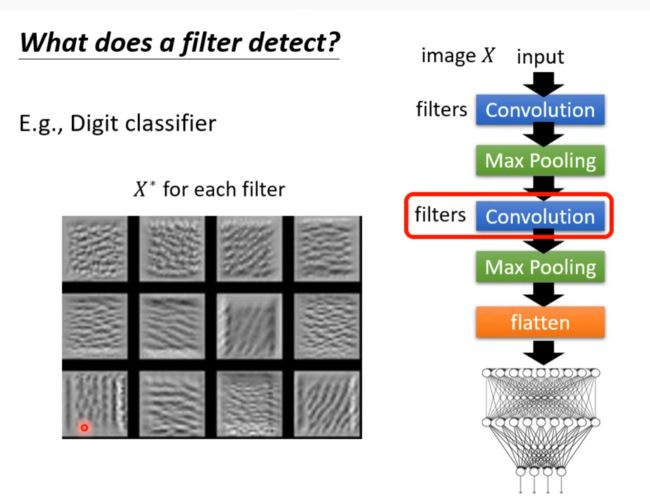
图示是某个filter
下图是被攻击了,命名看不出来是什么,机器却觉得是0123456789。
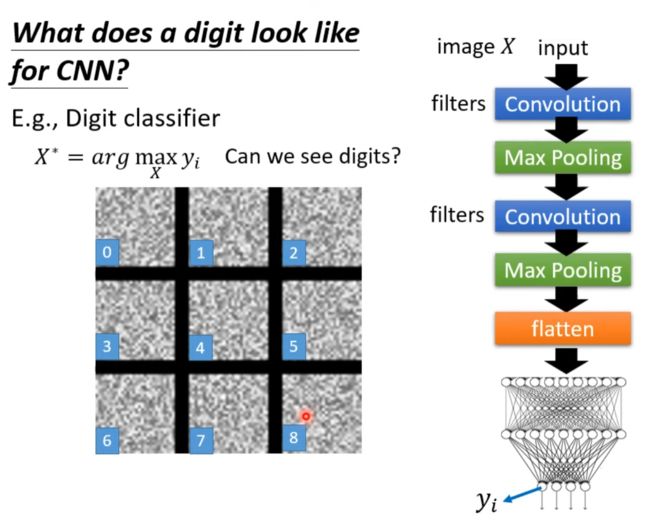

要得到如下的结果要大量的知识和处理。
或者通过generator达到目的(插眼,他在说什么)
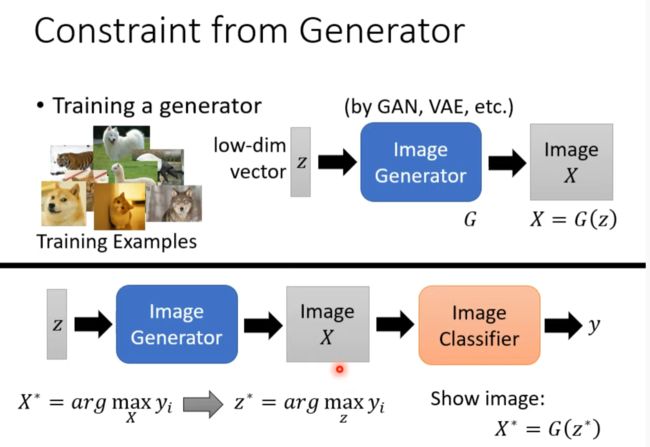
并不是在乎机器真正的注意点,而是将注意点转成人能理解的形式
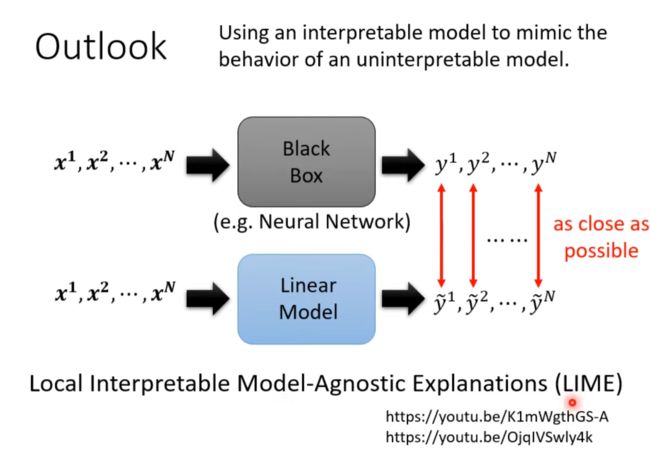
Outlook
用简单的linear模型模拟复杂的deep learning模型,再用简单的模型理解复杂的模型
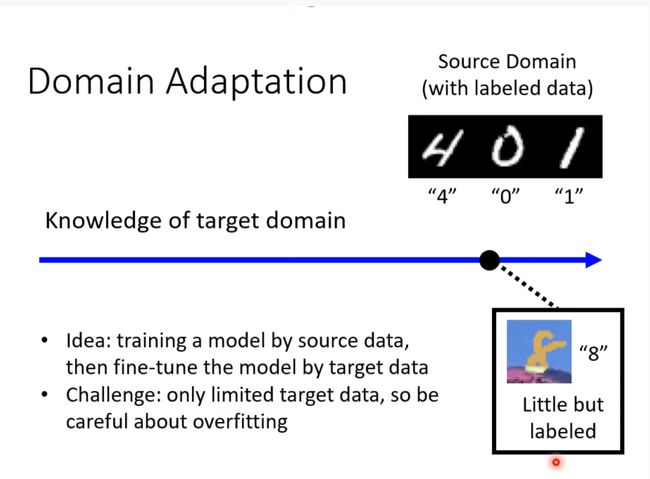
概述領域自適應 (Domain Adaptation)
Domain shift
有一些改变就会犯错


需要考虑两种情况
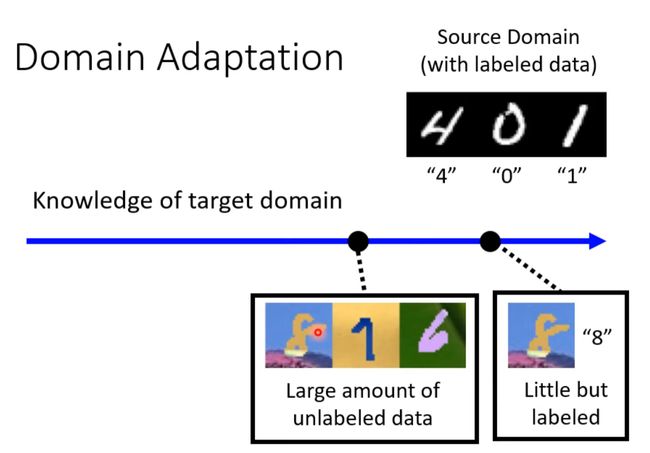
Basic idea

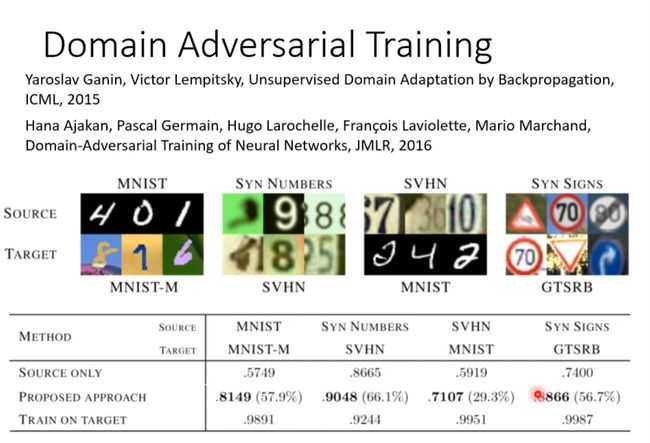
Domain Adversarial Training
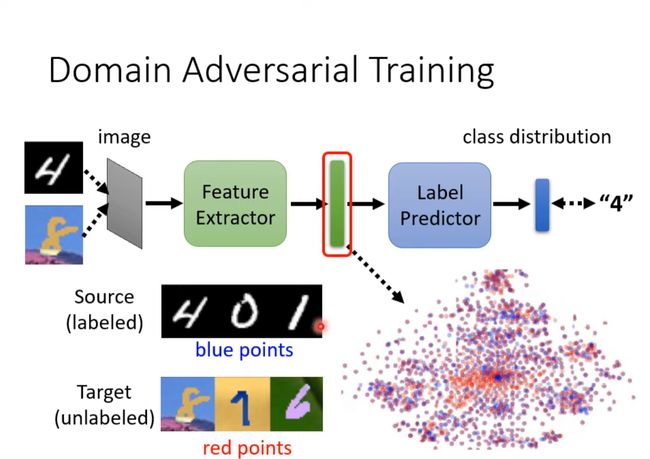
Domain Classifier用来分辨是黑白的还是彩色的,训练到它分别不出来且loss不再下降

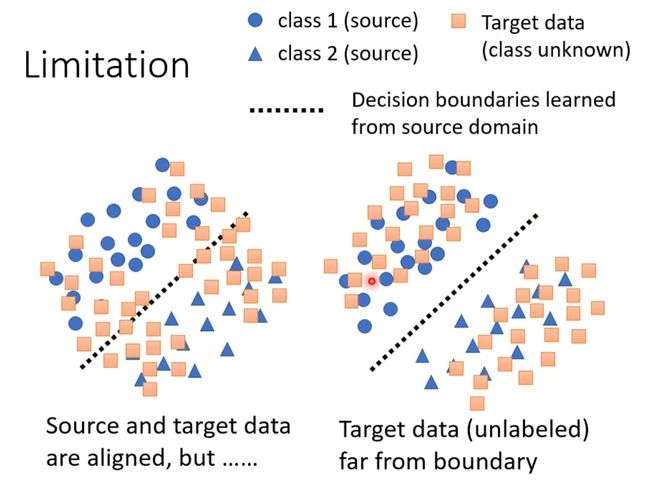
Limitation(插眼)

Outlook
有两者数据不完全重合的情况
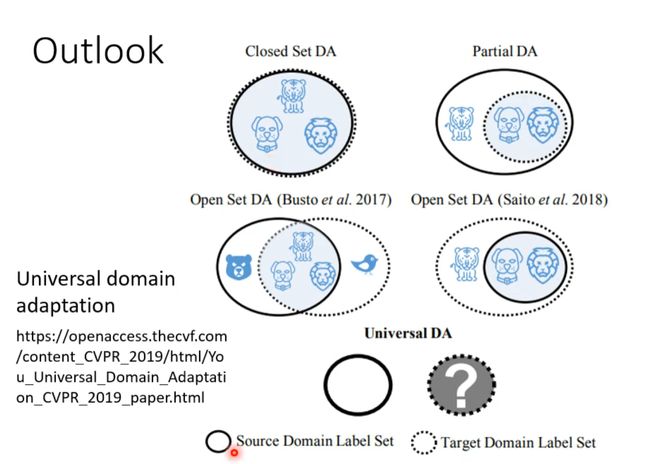
More condition in domain Adaptation
little unlabel
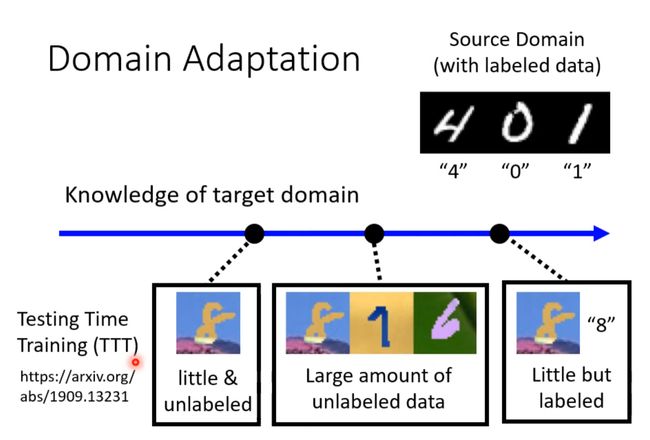
Know nothing
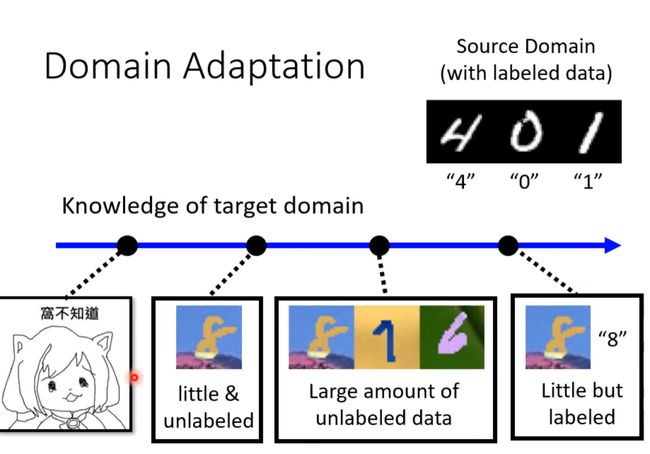
Domain Generation