【论文翻译】TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
近年来,从非结构化文本中提取实体和关系引起了越来越多的关注,但仍然具有挑战性,因为识别与共享实体的重叠关系具有内在的困难。以前的研究表明,联合学习可以带来显著的性能提升。然而,它们通常涉及顺序相关的步骤,并遭受暴露偏差的问题。在训练时,它们利用地面的真实条件进行预测,而在推理时则需要从零开始进行提取。这种差异导致误差累积。为了缓解这一问题,本文提出了一种单阶段联合提取模型,即TPLinker,该模型能够发现共享一个或两个实体的重叠关系,同时不受暴露偏差的影响。TPLinker将联合提取归结为标记对连接问题,并引入了一种新的握手标记方案,该方案将实体对的边界标记对齐在每种关系类型下。实验结果表明,TPLinker在重叠和多关系抽取方面表现明显更好,并在两个公共数据集上达到了最先进的性能。
1. 介绍
从非结构化文本中提取实体和关系是自动知识库构建的关键步骤。传统的流水线方法首先提取实体提及,然后对候选实体对之间的关系类型进行分类。但是,由于实体检测和关系分类完全分离,这些模型忽略了两个子任务之间的相互作用和相关性,容易产生级联错误。
在过去的几年里,建立联合模型同时提取实体和关系的研究越来越受到关注。最近的研究表明,联合学习方法可以有效地整合实体和关系的信息,因此在两个子任务中都取得了更好的性能。Zheng et al.(2017)提出了一种统一的标记方案,将联合提取转化为序列标记问题,但缺乏识别重叠关系的优雅性:一个实体可能参与同一文本中的多个关系。
 在处理实体对重叠EntityPairOverlap (EPO)和单实体重叠SingleEntiyOverlap (SEO)情况时,现有的大多数模型可以分为两类:基于解码器的和基于分解的。基于解码器的模型使用编码器-解码器架构,其中解码器每次提取一个单词或一个元组,就像机器翻译模型一样。基于分解的模型首先区分所有可能涉及目标关系的候选主体实体,然后为每个提取的主题标注相应的实体和关系。
在处理实体对重叠EntityPairOverlap (EPO)和单实体重叠SingleEntiyOverlap (SEO)情况时,现有的大多数模型可以分为两类:基于解码器的和基于分解的。基于解码器的模型使用编码器-解码器架构,其中解码器每次提取一个单词或一个元组,就像机器翻译模型一样。基于分解的模型首先区分所有可能涉及目标关系的候选主体实体,然后为每个提取的主题标注相应的实体和关系。
虽然这些方法都取得了不错的效果,但是都有同样的曝光偏差问题。对于基于解码器的方法,在训练时,ground truth token作为上下文,而在推理时,整个序列由结果模型自己生成,因此由模型生成的前一个token作为上下文。因此,训练和推理时的预测token来自不同的分布,即来自数据分布而不是模型分布(Zhang et al., 2019)。同样的,基于分解的方法在训练过程中使用gold主体实体作为特定输入引导模型提取客体和关系,而在推理过程中,输入头实体由训练过的模型给出,导致训练与推理之间存在差距。
在本文中,我们提出了一种用于实体和重叠关系联合提取的一阶段方法,即TPLinker,它弥合了训练和推理之间的鸿沟。TPLinker将联合提取任务转换为Token Pair Linking链接问题。
给定一个句子,两个位置p1、p2和一个特定关系r,TPLinker回答三个YES NO问题。
- p1和p2是否分别是同一实体的起始位置和结束位置?
- p1和p2是否分别为两个具有r关系实体的起始位置?
- p1和p2是否分别是r关系的两个实体的末端位置?
我们设计了一个握手标记方案,为每个关系标注三个Token Link 矩阵来回答上述三个问题。然后使用这些链接矩阵来解码不同的标注结果,从中我们可以提取所有实体及其重叠关系。
直观上,TPLinker不包含任何相互依赖的提取步骤,避免了训练时对ground truth条件的依赖,实现了训练与测试的一致性。
我们在两个公共数据集:NYT (Riedel et al., 2010)和WebNLG (Gardent et al., 2017)上评估我们的方法。实验结果表明,TPLinker在基准数据集上的性能优于以往的工作,达到了当前的水平。进一步分析表明,TPLinker显著提高了正常、SEO、EPO和多重关系提取的性能。
在本文中,我们提出了一种统一的标注方法来提取实体和重叠关系。与以往的方法不同,我们的模型在训练和推理之间没有间隙,只在一个阶段执行,并生成三元组。
3.策略
在本节中,我们首先介绍我们的握手标记方案及其解码算法。然后详细介绍了TPLinker模型的结构。
3.1 握手标注机制
3.1.1 标注
如图2左边所示,给定一个句子,我们枚举所有可能的token pair,并用矩阵标记token link。

左边是一个标记矩阵。为了便于说明,我们将所有标记显示在一个矩阵中,其中每种颜色对应一种特定的标记。
右边是握手标记方案的例子,阴影区域不包含在标签序列中。
在形式上,有三种类型的link定义如下:
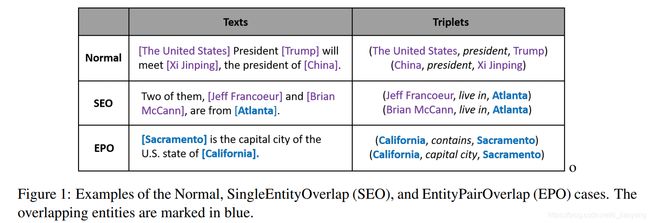
- EH-ET 实体头到实体尾:矩阵中的紫色标签表示对应的两个位置分别是实体的开始标记和结束标记。例如,“New York City”和“De Blasio”是句子中的两个实体,因此Token对(“New”,“City”)和(“De”,“Blasio”)被分配为紫色标签
- SH-OH 主体头到客体头:红色标记表示两个位置分别是成对的主体和客体的开始标记。例如,“New York City”和“De Blasio”之间存在“mayor”关系,因此Token对(“New”和“De”)被分配为红色标记
- ST-OT 主体尾到客体尾: 蓝色标记表示两个位置分别是成对的主体和客体的结束标记。例如,“New York City”和“De Blasio”之间存在“mayor”关系,Token对(“City”,“Blasio”)被分配为蓝色标记
从图2的左面板可以看出,矩阵是非常稀疏的,尤其是下三角区域。因为实体尾部不可能出现在实体头部之前,所以下三角区域的标签都是0,这是对内存的巨大浪费。但是,客体可能出现在对应的主体实体之前,这意味着直接删除下三角区域是不合理的。在此之前,我们将下三角区域中的所有标记1映射到上三角区域中的标记2,然后删除下三角区域。如图二右侧所示。
这样做之后,它不再是一个完整的矩阵了,在实际操作之中,我们把剩余的项平摊成一个序列,如图三所示。
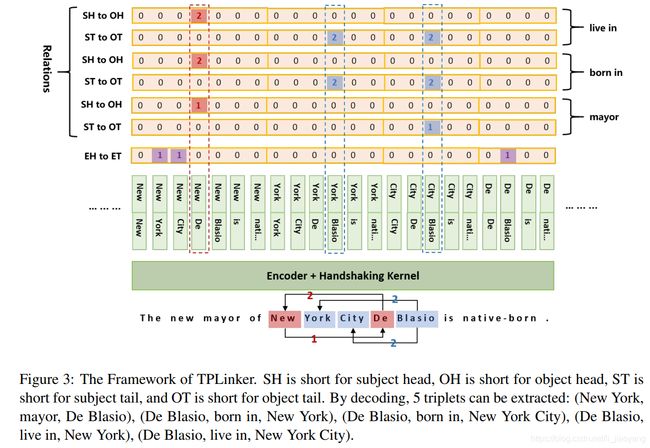
为了方便张量计算,用一个映射来记住原始矩阵中的位置。这个序列就像所有标记的握手,这就是为什么我们把这个方案称为握手标记方案的原因。
图2左侧中的案例表明,这个标记方案可以自然地处理单点重叠问题和嵌套实体问题。在本例中,“New York City”和“New York”是嵌套的,并共享同一个对象“De Blasio”,这对以前的许多方法都是一个挑战性的问题。
然而,通过这种标记方案,这三个实体和两个三元组都可以很容易地解码。然而,由于不同的关系不能被标记在同一矩阵中,因此该方法不能处理实体对的实体重叠问题。为了解决这个问题,我们对每个关系类型执行相同的矩阵标记工作。
EH-ET实体头 -实体尾的标记被所有关系共享,因为它关注于一般的实体提取,而不局限于特定的关系类型。
总的来说,如图3所示,将联合提取任务分解为2N+1序列标记子任务,其中N表示预定义关系类型的数量,每个子任务构建一个长度为(n2 + n)/2的标签序列,其中N为输入语句的长度。我们的标记方案似乎是非常低效的,因为标记序列的长度随着句子长度的增加呈平方数增加。幸运的是,我们的实验表明,利用编码器顶部的轻量级标记模型,TPLinker比起目前的SOTA很有竞争力。因为编码被所有标记共享,并且只需要一次产生n个token的表示。
3.1.2 解码
在图三中,(" New ", " York “), (” New ", " City “)和(” De ", " Blasio ")在属性中被标记为EH-ET序列,意思是“New York”,“New York City”,和“De Blasio ”是三个实体。
对于关系“mayor”,(“New”,“De”)在SH-to-OH序列中被标记为1,这意味着以“New”开始的主语的mayor就是以“De”开始的对象。(“City”,“Blasio”)在ST-to-OT序列中被标记为1,这意味着主体和客体都是以“City”和结尾的实体分别为“Blasio”。根据这三个序列所代表的信息,可以解码出一个三元组:(“纽约市”,“市长”,“白思豪”)。
算法1解释了解码的过程。
首先,从EH-ET序列中提取所有跨越的实体,然后用字典D将每个头位置映射到以该位置开始的对应实体。接下来,对每个关系,我们首先解码ST-OT序列,将他们添加到一组E,然后解码SH-OH,从字典D里查找以头实体位置开始的可能实体。最后,我们迭代所有候选主体客体对,检查他们的尾位置是否在E中。如果是,新的三元组答案被提取,添加到结果集T中。

3.2 实体对表示
给出一个句子,我们首先通过一个基本的编码器将每个token映射到一个低维的上下文向量hi中。然后我们可以为令牌对(wi;wj)生成一个表示hi,j 如下:

3.3 握手标注
对于EH-ET,SH-OH,ST-OT,我们使用统一的标注架构。

3.4 损失函数

N是输入句子的长度,l是正确答案。E H T分别表示EH-ET,SH-OH,ST-OT.
4. 实验
4.1 数据集
NYT 和 WebNLG,这两个数据集都给出了实体标记, 而关系,包括了普通关系 Normal,Entity Pair Overlap (EPO,多个subject对单个object),Single Entity Overlap (SEO,两个实体间存在多种关系) 。

与各个baseline模型对比
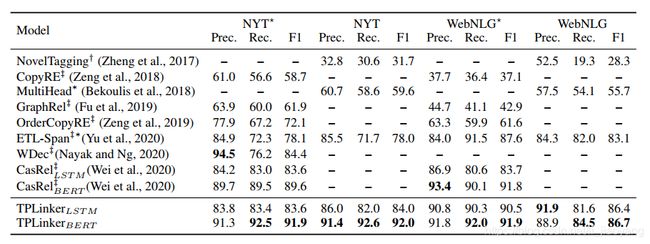 为了验证我们的握手标记方案的实用性,我们删除了BERT,并使用BiLSTM作为替代编码器来输出结果。可以看出,TPLinker BiLSTM仍然是非常有竞争力的现有的最先进的模型,CasRel BERT。
为了验证我们的握手标记方案的实用性,我们删除了BERT,并使用BiLSTM作为替代编码器来输出结果。可以看出,TPLinker BiLSTM仍然是非常有竞争力的现有的最先进的模型,CasRel BERT。
尽管SOTA的两种模型CasRel和ETL-Span取得了令人鼓舞的成绩,但它们仍然存在一些问题。为
它本质上是一种两阶段方法,既存在暴露偏差,也存在错误传播。
ETL-Span与CasRel有同样的问题,无法处理EPO问题。
当输入的句子复杂度增加,各种模型的成绩呈下降趋势,然而 TPLinker 表现出显著的提高:
 在计算性能上,TPLinker 也表现出巨大的优势:
在计算性能上,TPLinker 也表现出巨大的优势:
 CasRel BERT被限制一次只处理一句话,这意味着它的效率非常低,很难部署。相反,TPLinker BERT能够以批处理模式处理数据,因为它是一个单阶段模型。
CasRel BERT被限制一次只处理一句话,这意味着它的效率非常低,很难部署。相反,TPLinker BERT能够以批处理模式处理数据,因为它是一个单阶段模型。
此外,即使我们将TPLinker BERT的batch size设置为1,推理速度仍然很有竞争力。这再次证明了他的效率。实际上,CasRelBERT和TPLinkerBERT都使用BERT作为基本编码器,BERT是最耗时的部分,占用了大部分的模型参数,所以握手标注的时间成本并不显著。
6. 结论
本文提出了基于握手标注策略的端到端序列标注模型TPLinker,用于实体和关系的联合抽取,巧妙的将联合抽取转化为token pair的链接问题。据我们所知,TPLinker是第一个一步联合抽取模型,他可以在不暴露偏差影响的情况下提取各种重叠关系。实验结果表明,我们的模型优于所有基线,并在两个公共数据集上达到一个新的最先进的状态。