爱彼迎数据分析
简单的python爱彼迎数据分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
导入需要的库
1.calender数据集分析
calendar = pd.read_csv(r'C:\Users\12435\Desktop\shujufenxi\数分清华\aibiying\calendar_detail.csv')
calendar.head()
导入数据集并查看

calendar.info()

首先将价格转换为为浮点数
calendar['price']=calendar['price'].str.replace(r'[$,]','',regex=True).astype(np.float32)
calendar['adjusted_price'] = calendar['adjusted_price'].str.replace(r'[$,]','',regex=True).astype(np.float32)
#将日期转换为日期格式
calendar.date=pd.to_datetime(calendar.date,format='%Y-%m-%d')
#添加月份和星期
calendar['month']=calendar.date.dt.month
calendar['weekday'] = calendar.date.dt.weekday+1
calendar.head()
#月份与价格的关系
month_price = calendar.groupby('month')['price'].mean()
sns.barplot(month_price.index,month_price.values)
plt.ylim(600,700)
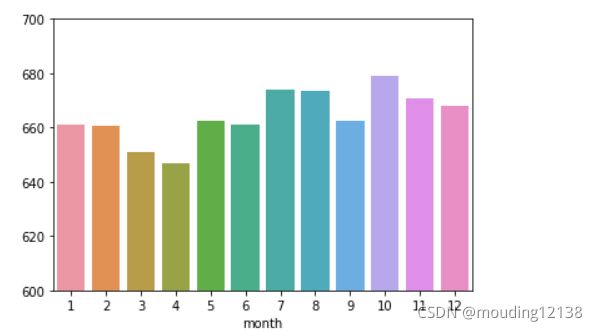
可以看到3.4月淡季价格较低,78月暑假10月国庆价格较高.
#星期与价格的关系
weekday_price = calendar.groupby('weekday')['price'].mean()
sns.barplot(weekday_price.index,weekday_price.values)
plt.ylim(600,700)

周五周六价格较高.
分析一下价格占比
sns.distplot(calendar[calendar['price']<1000]['price'])
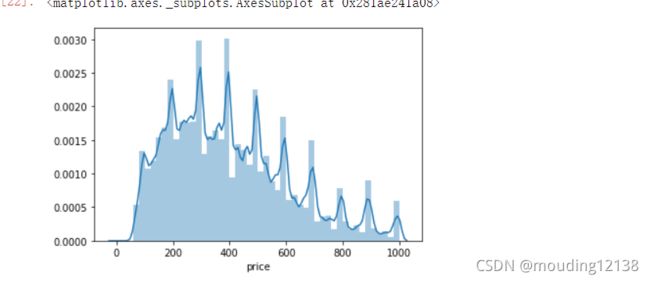
排除一些异常值后,可以看出条形图呈右偏分布.大部分房屋价格都在200-400元左右
2.listings数据集分析
listings = pd.read_csv(r'C:\Users\12435\Desktop\shujufenxi\数分清华\aibiying\listings_detail.csv')
listings.head()
#数据集特征较多,有106个,通过将列名转换为列表查看完整特征.寻找感兴趣的特征进行处理.
listings.columns.to_list()

修改金额列的数据类型
listings['price'] = listings['price'].str.replace(r'[$,]','',regex=True).astype(np.float32)
listings['cleaning_fee'] = listings['cleaning_fee'].str.replace(r'[$,]','',regex=True).astype(np.float32)
listings['cleaning_fee'].head()
#存在空值,说明有些旅馆是不需要小费的,用0填充即可
listings['cleaning_fee'].fillna(0,inplace = True)
#添加一个新的字段,最低消费 (价格+小费)*最低入住天数
listings['min_cost']=(listings['price']+listings['cleaning_fee'])*listings['minimum_minimum_nights']
listings['min_cost'].head()

#添加设施的数量
listings['amenities'].head()

listings['n_amenities'] = listings['amenities'].str[1:-1].str.split(',').apply(len)
listings['n_amenities'].head()

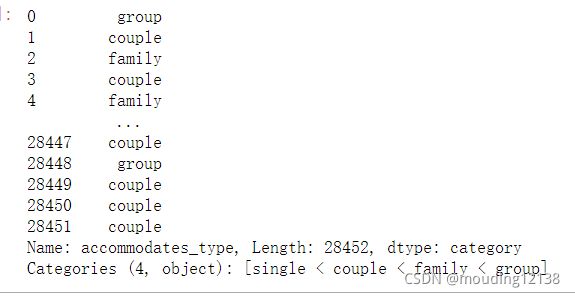
#根据可以容纳的人数,添加一个新的列,用来表示类型:single(1),couple(2),family(5),group(100)
listings['accommodates_type']=pd.cut(listings['accommodates'],bins=[1,2,3,5,100],include_lowest=True,right=False
,labels=['single','couple','family','group'])
listings['accommodates_type']
选取对价格影响较大的特征进行分析
listings_df=listings[['id','host_id','listing_url','room_type','neighbourhood_cleansed'
,'price','cleaning_fee','amenities','n_amenities',
'accommodates','accommodates_type','minimum_minimum_nights','min_cost']]
对数据集的处理:
将价格和小费转换成浮点数格式,将小费空值填充为0,与最小居住天数联合计算最低消费
根据设施集计算设施数量.listings[‘amenities’].str[1:-1].str.split(’,’).apply(len)
新增一个列,根据可容纳人数给房屋分类.pd.cut
将需要的特征单独提出来组成一个新的df
listings_df.head()

#房间类型的情况
listings_df['room_type'].unique()
![]()
共有三种房间的类型
room_type_counts = listings_df['room_type'].value_counts()
fig,axes =plt.subplots(1,2,figsize=(10,5))
axes[0].pie(room_type_counts.values,autopct='%.2f%%',labels = room_type_counts.index)
sns.barplot(room_type_counts.index,room_type_counts.values)
plt.tight_layout()
plt.show()

查看房屋类型占比
可以看到公寓形的整租占了60%,私人房屋占了35%,多人同住一屋只占了不到6%
#分析房源所在城区分布
plt.rcParams['font.sans-serif']=['SimHei']
neighbourhood_counts = listings_df['neighbourhood_cleansed'].value_counts()
sns.barplot(x=neighbourhood_counts.values,y=neighbourhood_counts.index,orient='h')

排名第一的是朝阳区,这里房源最多,其次是东城区和海淀区,但是这两个都只有朝阳区的三分之一左右
#查看每个区的房屋类型占比
neighbourhood_room_type = listings_df.groupby(['neighbourhood_cleansed','room_type'])\
.size()\
.unstack('room_type')\
.fillna(0)\
.apply(lambda row:row/row.sum(),axis = 1)\
.sort_values('Entire home/apt')
neighbourhood_room_type

columns = neighbourhood_room_type.columns
plt.figure(figsize=(10,8))
plt.barh(neighbourhood_room_type.index,neighbourhood_room_type[columns[0]])
left = neighbourhood_room_type[columns[0]].copy()
plt.barh(neighbourhood_room_type.index,neighbourhood_room_type[columns[1]],left=left)
left +=neighbourhood_room_type[columns[1]]
plt.barh(neighbourhood_room_type.index,neighbourhood_room_type[columns[2]],left=left)
plt.legend(columns)

#较为简单的方法
fig,ax=plt.subplots(figsize=(10,5))
neighbourhood_room_type.plot(kind='barh',stacked = True,width=0.75,ax=ax)

查看户主名下房源数量的分布
host_num = listings_df.groupby('host_id').size()
sns.distplot(host_num)
#可以看到大部分人都只有几套房子,当然也有夸张的一人有两百多套.这里排除这些异常值,
#只考虑房子数量少于10套的数据

#只查看房源数量少于10套的户主,排除异常值
sns.distplot(host_num[host_num<10])

#户主分类py
host_num_bins = pd.cut(host_num,bins=[1,2,3,5,1000],include_lowest=True,right=False,labels=['1','2','3-4','5+'])
plt.pie(host_num_bins.value_counts().values,autopct='%.2f%%',labels=host_num_bins.value_counts().index)
plt.show()

拥有一套房子的户主占了60%,两套房子的户主有15%,3-4套占了12%
host_num_cumsum=host_num.sort_values().cumsum()
h = host_num_cumsum.reset_index()
sns.lineplot(h.index,h[0])

由上图可以看出,8成的人只占了不到40%的房源.剩下2成的人占了超过一半的房源,比较符合二八法则
3,reviews数据分析
reviews = pd.read_csv(r'C:\Users\12435\Desktop\shujufenxi\数分清华\aibiying\reviews_detail.csv',parse_dates=['date'])
reviews.head()

reviews['year'] = reviews['date'].dt.year
reviews['month'] = reviews['date'].dt.month
n_reviews = reviews.groupby('year').size()
sns.barplot(n_reviews.index,n_reviews.values)

reviews.date.max()

month_reviews = reviews.groupby('month').size()
sns.barplot(month_reviews.index,month_reviews.values)

可以看到23月春节,78月暑假,10月国庆评论量都比较多,56月没有假期,评论量比较少
year_month_reviews = reviews.groupby(['year','month']).size().unstack().fillna(0)
year_month_reviews

fig,ax =plt.subplots(figsize=(10,5))
for index in year_month_reviews.index:
series = year_month_reviews.loc[index]
sns.lineplot(series.index,series.values)
ax.legend(labels = year_month_reviews.index)
ax.grid()
ax.set_xticks(range(1,13))
plt.show()

从上图可以看出,评论量其实一直都是保持同一增速平稳平稳上升的,每年年初的评论数与上年年末的评论数几乎持平,一直处在波动上升的阶段.只有一小部分时间会发生下降的情况,如2018年的2,3月,2017年的9,10月,需要结合当时的业务进行分析
4.预测房间价格
ml_listings = listings[listings['price']<300][[
'host_is_superhost',
'host_identity_verified',
'neighbourhood_cleansed',
'latitude',
'longitude',
'property_type',
'room_type',
'accommodates',
'bathrooms',
'bedrooms',
'cleaning_fee',
'minimum_minimum_nights',
'maximum_maximum_nights',
'availability_90',
'number_of_reviews',
#'review_scores_rating',
'is_business_travel_ready',
'n_amenities',
'price'
]]
ml_listings.dropna(axis = 0,inplace=True)
ml_listings.isnull().sum()

from sklearn.preprocessing import StandardScaler
#分割特征值和目标值
features = ml_listings.drop(columns=['price'])
target = ml_listings['price']
#对特征值进行处理
#对离散型数据进行one_hot编码
disperse_columns = [
'host_is_superhost',
'host_identity_verified',
'neighbourhood_cleansed',
'property_type',
'room_type',
'is_business_travel_ready'
]
disperse = features[disperse_columns]
disperse = pd.get_dummies(disperse)
#对连续性数据进行标准化(因为连续性数值相差不大,所以对预测结果影响可能不大)
continuouse_features = features.drop(columns = disperse_columns)
scaler = StandardScaler()
continuouse_features=scaler.fit_transform(continuouse_features)
#处理后的数据进行组合
feature_array = np.hstack([disperse,continuouse_features])
#使用线性回归模型进行预测
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error,r2_score
xtrain,xtest,ytrain,ytest = train_test_split(feature_array,target,test_size = 0.3)
line = LinearRegression()
line = line.fit(xtrain,ytrain)
ypredict = line.predict(xtest)
print('平均误差',mean_absolute_error(ytest,ypredict))
print('R2误差',r2_score(ytest,ypredict))
平均误差 3009977153.5992937
R2误差 -5.155611729394443e+18
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
regressor = RandomForestRegressor(n_estimators = 10)
score = cross_val_score(regressor,feature_array,target,cv=5)
score.mean()
0.39684796601257405
使用随机森林进行预测,效果不好
5,评论数的预测
ym_reviews = reviews.groupby(['year','month']).size().reset_index().rename(columns={0:'count'})
feature = ym_reviews[['year','month']]
target = ym_reviews['count']
cross_val_score(regressor,feature,target,cv=6).mean()
xtrain,xtest,ytrain,ytest = train_test_split(feature,target,test_size=0.3)
regressor = RandomForestRegressor(n_estimators = 100)
regressor.fit(xtrain,ytrain)
ypredict = regressor.predict(xtest)
print(mean_absolute_error(ytest,ypredict))
print(r2_score(ytest,ypredict))
170.16655172413795
0.9863879670160787
预测2019年之后几个月的评论数
a=list()
for i in range(5,13):
a.append([2019,i])
regressor.fit(feature,target)
y_predict = regressor.predict(a)
ypredict = pd.DataFrame([[2019,5+index,x] for index,x in enumerate(y_predict)],columns = ['year','month','count'])
final_reviews = pd.concat([ym_reviews,ypredict],axis = 0).reset_index()
years = final_reviews['year'].unique()
fig,ax = plt.subplots(figsize=(15,5))
for year in years:
df = final_reviews[final_reviews['year']==year]
sns.lineplot(x='month',y='count',data = df)
ax.legend(labels = year_month_reviews.index)
ax.grid()
ax.set_xticks(list(range(1,13)))
plt.show()

这里可以看出来,预测的2019年4月之后的评论数保持略微上涨的趋势,不太符合之前的推测.