爱彼迎的数据分析与建模
Airbnb是AirBed and Breakfast(“Air-b-n-b”)的缩写,爱彼迎是一家联系旅游人士和家有空房出租的房主的服务型网站,它可以为用户提供多样的住宿信息。我们现在对数据进行分析。
一,对数据处理
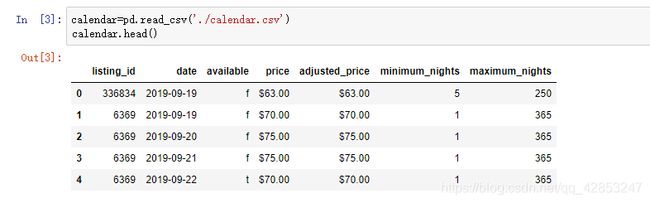
1.因为price里面的数据有’$‘和’,’,我们要替换成空格,便于我们之后的运算
calendar['price'] = calendar['price'].str.replace(r"[$,]","").astype(np.float32)
calendar.head()
并且转换浮点类型。
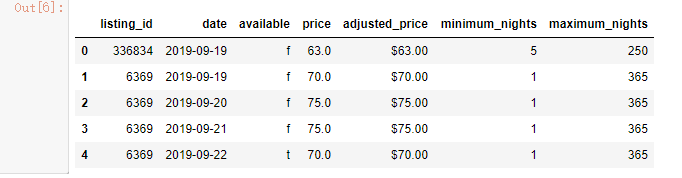
同理,对adjusted_price进行相同操作,再对date进行时间序列转换,得到结果。

如图所示,我们发现类型还是object,再修改一下。
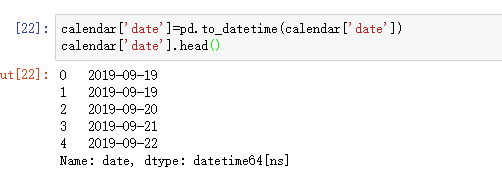
完成了,现在是datetime类型。
2.用时间序列我们可以很轻松地返回商品的相关时间
calendar['weekday']=calendar['date'].dt.weekday
calendar['month']=calendar['date'].dt.month
calendar['year']=calendar['date'].dt.year
calendar['year']
会返回商品交易的年份,非常方便。做出柱状图我们可以看到商品月份的波动。

可以看出,3到8月份房屋价格递增,8月份达到峰值。
二,对listing_detail进行分析
listing_detail数据比较多。足足有106列

元素比较多,这里有个小技巧
我们可以用
listings_detaile.columns.values.tolist()
对每一列的元素进行查看

1.我们要对这一列的数据价格进行同样的处理,去掉不必要的符号便于运算
2.然后要求出最低消费,便于我们后边模型的建立
listings_detailed['minimum_cost']=(listings_detailed['cleaning_fee']+listings_detailed['price'])*listings_detailed['minimum_nights']
最低消费是费用加消费乘以最低天数。
3.要添加一个新字段。包含设施的数量,设施的数量与价格有直接关系

我们可以看到,设施用一个大括号括起来,我们可以用切片提取里面的数值,再用split分割逗号。
listings_detailed['accommodates_type']=pd.cut(listings_detailed['accommodates'],bins=[1,2,3,5,100],include_lowest=True,right=False,labels=['Single','Couple','Family','Group'])
4.再把剩余需要的数据提取,整合到新的df里边
listings_detailed['neighbourhood_group_cleansed'].head()
listings_detailed['review_scores_rating'].head()
listings_detailed_df=listings_detailed[['id','host_id','listing_url','room_type','neighbourhood_group_cleansed',
'price','cleaning_fee','amenities','n_amenities','accommodates','accommodates_type',
'minimum_nights','minimum_cost']]
listings_detailed_df.head()
得到一个新df,用来方便之后的运算
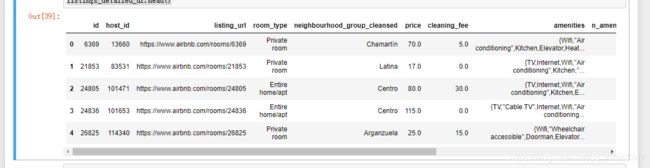
.二,对房间类型和社区类型进行初步分析
用饼图和柱状图对房间类型进行分析
room_type_counts=listings_detailed_df['room_type'].value_counts()
fig,axes = plt.subplots(1,2,figsize=(10,5))
axes[0].pie(room_type_counts.values,autopct='%.2f%%',labels=room_type_counts.index)
sns.barplot(room_type_counts.index,room_type_counts.values)
plt.tight_layout()
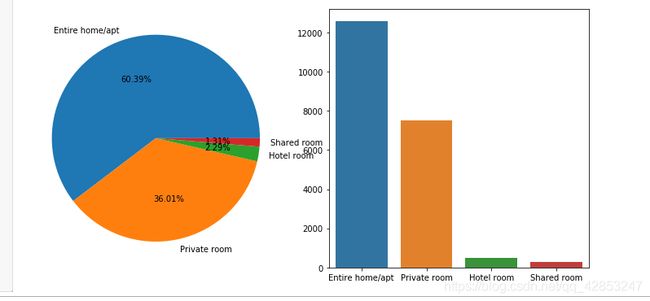
我们能看出entrie home即是整套房间,占比最高
然后对社区类型进行分析
neighbourhood_counts = listings_detailed_df['neighbourhood_group_cleansed'].value_counts()
sns.barplot(y=neighbourhood_counts.index,x=neighbourhood_counts.values,orient='h')
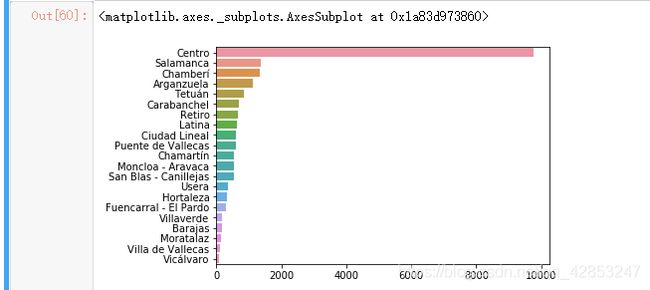
可以看出社区类型排名,都是一些比较专业的名,萨拉曼卡什么的。
三,对房东进行相关分析
host_number=listings_detailed_df.groupby('host_id').size().sort_values(ascending=False)
sns.distplot(host_number[host_number<10])

可以看出,拥有一套房的房东数量居多。把拥有的房屋数量划分下等级得出下图,

四,评论数量与时间分析
读取reviews文件的时候可以直接把date的类型进行转换
reviews=pd.read_csv('./reviews_detailed.csv',parse_dates=['date'])
对时间序列进行相关处理
reviews['year']=reviews['date'].dt.year
reviews['month']=reviews['date'].dt.month
查看下年份的分布情况:
reviews.groupby('year').size()
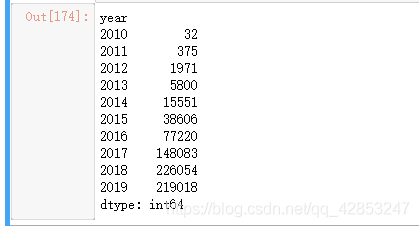
可以看的出,评论的数量在每年递增,知道2018年到顶峰,2019年有所下降。
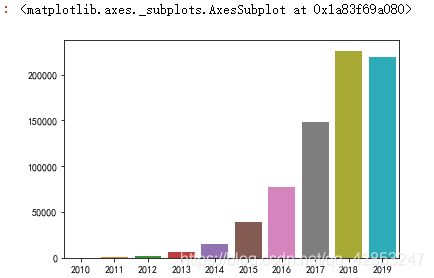
说明用户的活跃度也越来越高。
我们再按照月份来分:
n_reviews_months=reviews.groupby('month').size()
sns.barplot(n_reviews_months.index,n_reviews_months.values)
得到
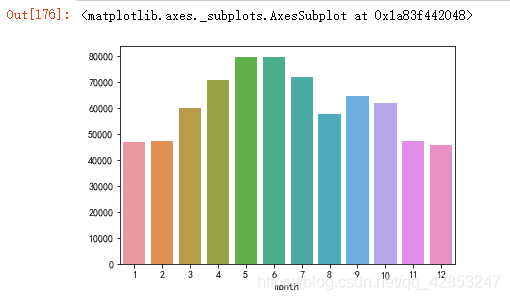
可以看出,4到7月用户的活跃度最高。
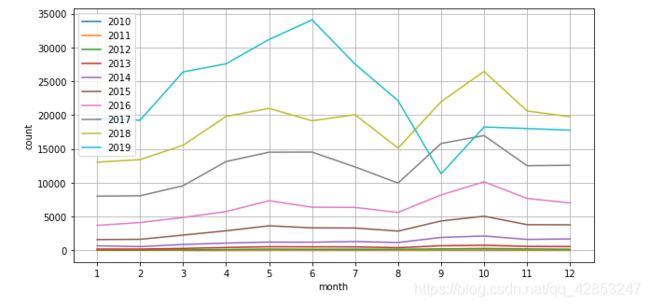
再做一个折线图,把历年评论数量整合在一起。
把历年评论数整合在一个表格
year_month_reviews=reviews.groupby(['year','month']).size().unstack('month').fillna(0)
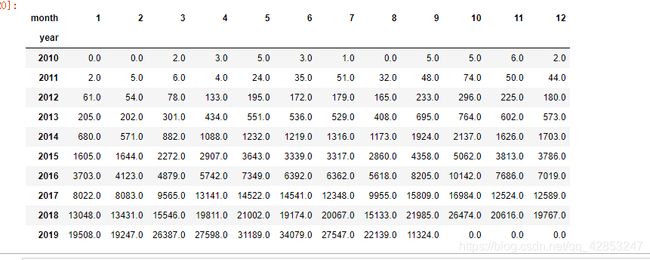
然后把2016到2019的代码整合到一张图
fig,ax=plt.subplots(figsize=(10,5))
for index in year_month_reviews.index:
series = year_month_reviews.loc[index]
sns.lineplot(x=series.index,y=series.values,ax=ax)
ax.legend(labels=year_month_reviews.index)
ax.grid()
ax.set_xticks(list(range(1,13)))
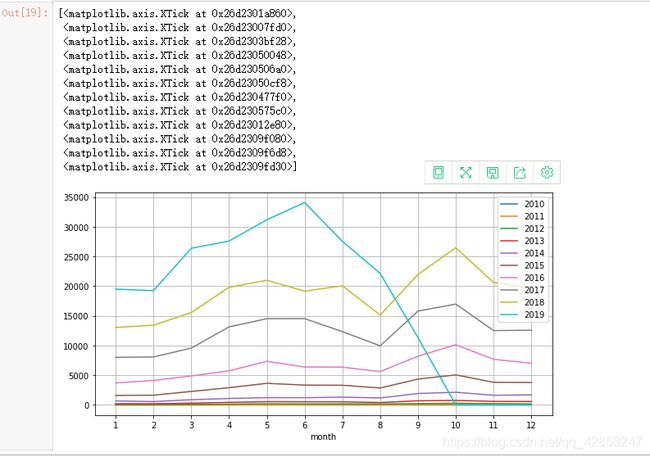
我们可以很方便地从图中看出各年评论的数量趋势
五,预测房间价格
首先我们可以看下影响房间价格的因素
'host_is_superhost',#超级房东,在爱彼迎混的比较久,价格可能会稍高
'host_identity_verified',#房东是否经过认证
'neighbourhood_group_cleansed',#社区
'latitude',#经度
'longitude',#纬度
'property_type',#公寓类型
'room_type',#房间类型
'accommodates',#可容纳人数
'bathrooms',#浴室数
'bedrooms',#卧室数
'cleaning_fee',#小费
'minimum_nights',#最少居住晚
'maximum_nights',#最多居住夜晚数
'availability_90',#在90天内有多少天是可用的
'number_of_reviews',#评论数量
'review_scores_rating',#评分
'is_business_travel_ready',#是否做好商务,旅游服务
'n_amenities',#设施数
'price'#价格
清理完异常值后,分割特征值和目标值
from sklearn.preprocessing import StandardScaler
#分割特征值和目标值
features = ml_listing.drop(columns=['price'])
targets=ml_listing['price']
features.head()
处理完成后,进行one-hot编码和标准化
#对特征值进行处理
#针对离散型数据进行one-hot编码
disperse_columns = [
'host_is_superhost',
'host_identity_verified',
'neighbourhood_group_cleansed',
'property_type',
'room_type',
'is_business_travel_ready'
]
disperse_features = features[disperse_columns]
disperse_features = pd.get_dummies(disperse_features)
# 对连续性数据进行标准化(因为特征值之间相差并不是很大,所以标准化的可能对预测结果影响不是很大)
continuouse_features = features.drop(columns=disperse_columns)
scaler = StandardScaler()
continuouse_features = scaler.fit_transform(continuouse_features)
continuouse_features
对处理后的特征值进行组合
#对处理后的特征进行组合
feature_array = np.hstack([disperse_features,continuouse_features])
feature_array
导入模型,进行预测
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error,r2_score
X_train,X_test,y_train,y_test = train_test_split(feature_array,targets,test_size=0.25)
regressor = RandomForestRegressor()
regressor.fit(X_train,y_train)
y_predict = regressor.predict(X_test)
print("平均误差:",mean_absolute_error(y_test,y_predict))
print("R2评分:",r2_score(y_test,y_predict))
预测结果
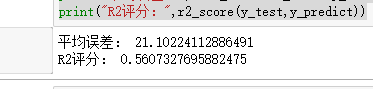
R2评分越接近1,结果越准确。
六,评论数量预测
评论数量分析用到reviews数据集
ym_reviews=reviews.groupby(['year','month']).size().reset_index().rename(columns={0:"count"})
features = ym_reviews[['year','month']]
targets = ym_reviews['count']
# X_train,X_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
# regressor = RandomForestRegressor(n_estimators=100)
# regressor.fit(X_train,y_train)
# y_predict = regressor.predict(X_test)
# print("平均误差:",mean_absolute_error(y_test,y_predict))
# print("R2评分:",r2_score(y_test,y_predict))
可以得出平均误差与R2值

R2值很接近1,证明这个模型很很合适。
代入2019年10到12月的值
regressor = RandomForestRegressor(n_estimators=100)
regressor.fit(features,targets)
y_predict = regressor.predict([
[2019,10],
[2019,11],
[2019,12]
])
y_predict
得到的就是预测值,分别是array([18252.94, 18020.23, 17785.06])
再把新的值代入可视化
predict_reviews = pd.DataFrame([[2019,10+index,x] for index,x in enumerate(y_predict)],columns=['year','month','count'])
final_reviews = pd.concat([ym_reviews,predict_reviews]).reset_index()
years = final_reviews['year'].unique()
fig,ax = plt.subplots(figsize=(10,5))
for year in years:
df = final_reviews[final_reviews['year']==year]
sns.lineplot(x="month",y='count',data=df)
ax.legend(labels=year_month_reviews.index)
ax.grid()
_ = ax.set_xticks(list(range(1,13)))
得到
至此,爱彼迎的数据分析算是完成了