基于MapReduce和协同过滤算法的推荐系统研究
1 项目背景及意义
当前互联网信息越来越多,呈现指数增长的趋势。视频服务网站是互联网的重要组成部分,往往都存着数以万计的电影资源[1],用户打开电影网站时也许没有明确的目标,使得查找时所涉及的电影资源数量仍然巨大,并且很难轻松获得符合自己兴趣的新资源。在这种情况下,通过对用户行为信息和电影资源信息进行关联性分析来预测并推荐与用户喜好相符的电影,会很大程度上增加用户的观看兴趣。视频服务已经成为用户浏览互联网时最关注的服务之一,因而,提升在线视频服务的用户体验具有重要的研究价值[2]。而视频服务中的电影推荐系统可以通过提高推荐算法的准确度来增加用户的点击率、购买率或观看时间等,从而也给视频服务商带来更多的经济收益。一个好的推荐系统,能自动挖掘用户的兴趣点,引导用户发现自己的信息需求,同时,通过为用户提供个性化的推荐服务从而与用户建立联系,使得用户对推荐系统产生依赖。
基于上述意义,本文基于传统的协调过滤算法结合设计了一款电影推荐系统。
2 相关技术介绍
2.1协同过滤算法
协同过滤( CF)算法是推荐系统中最为经典的算法,包括基于用户的协同过滤算法( User-CF)和基于物品的协同过滤算法( Item- CF) [3]。协同过滤算法可以通过获得用户的观看行为数据作为隐性反馈或者评分记录的数据作为显性反馈,利用一定的算法预测出用户没有观看过但可能喜欢的电影并达到推荐给用户观看的目的[4]。
本文所写的推荐系统为基于物品的协调过滤算法的电影推荐系统,基于物品的协调过滤算法的主要步骤如下 :
(1)构建物品-用户操作行为矩阵;
(2)计算物品之间相似度;
(3)获取推荐结果。
2.2 爬虫技术
爬虫是一种能自动运行的程序,其功能是从网络上爬取到特定的数据。Scrapy 是一个基于 Python 的开源爬虫框架,包含多种中间件接口。目前 Scrapy 已广泛应用于数据挖掘、检测和自动化测试等项目上,采用 Scrapy 爬取豆瓣网上的电影信息作为本系统个性化推荐的基础数据。
Scrapy原理图如下:
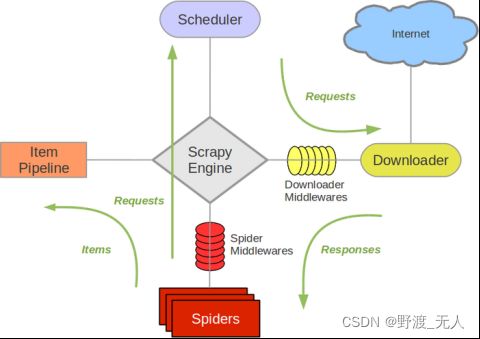
2.3 MapReduce框架
MapReduce 是对大数据进行并行处理的计算平台和框架。即使用户并不十分了解分布式系统的底层细节,也能比较容易地开发出并行的应用程序,并将其应用在各类廉价的计算机机群上,用于大规模数据的并行计算,完成海量数据的处理任务。在进行数据处理时,一些较复杂或者是在大规模集群上运行的并行计算,MapReduce 会将它们抽象到 Map和 Reduce 两个函数上。其中,Map 完成指定数据集上独立元素的操作,生成中间结果“键值”对;Reduce 则完成“规约”中间结果中相同“键”的所有“值”的操作,最终生成运算结果。
MapReduce 工作流程:
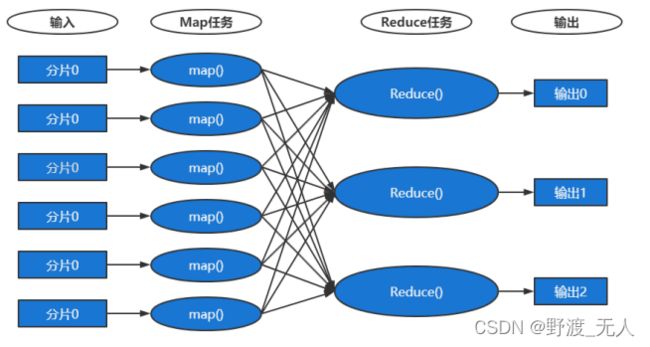
2.4 SpringMVC
SpringMVC是一种基于Java,实现了Web MVC设计模式,请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将Web层进行职责解耦。基于请求驱动指的就是使用请求-响应模型,框架的目的就是帮助我们简化开发,SpringMVC也是要简化我们日常Web开发。
MVC设计模式的任务是将包含业务数据的模块与显示模块的视图解耦。这是怎样发生的?在模型和视图之间引入重定向层可以解决问题。此重定向层是控制器,控制器将接收请求,执行更新模型的操作,然后通知视图关于模型更改的消息。
3 推荐系统实现
3.1 系统开发环境
本系统是基于 Liunx 系统平台实现的电影推荐,系统使用基于物品的协同推荐算法和Map Reduce框架。
Liunx 操作系统是一种免费使用和自由传播的类 UNIX 操作系统。其内核由林纳斯·托瓦兹于 1991 年 10 月 5 日首次发布,是一个基于 POSIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。它能运行主要的 Unix 工具软件、应用程序和网络协议,是一个性能稳定的多用户网络操作系统。
3.2 推荐系统整体架构
本系统主要由三个模块组成:数据采集、数据处理、结果展示。
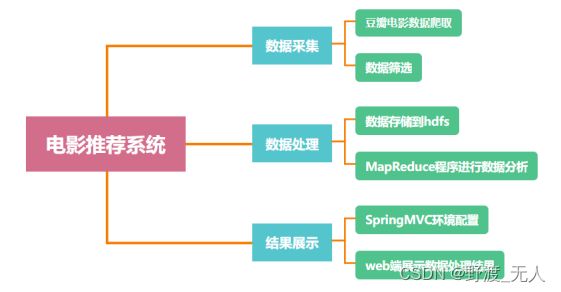
3.3 数据采集
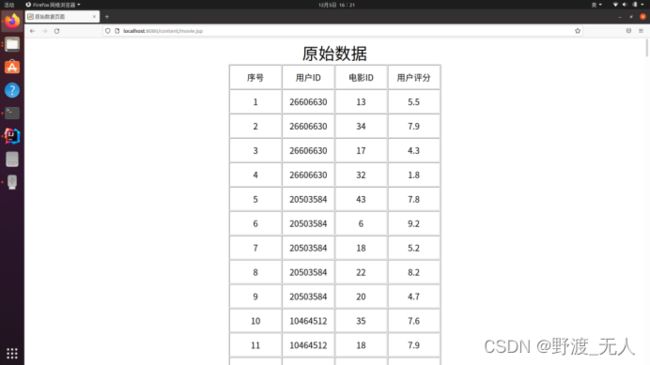
该系统所用原始数据为python爬虫爬取豆瓣网上用户ID、对电影的评分、电影类型等数据,共三千多条。
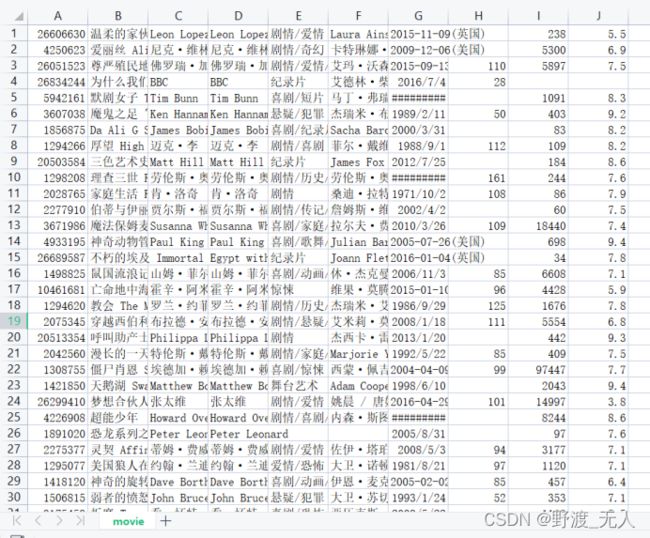
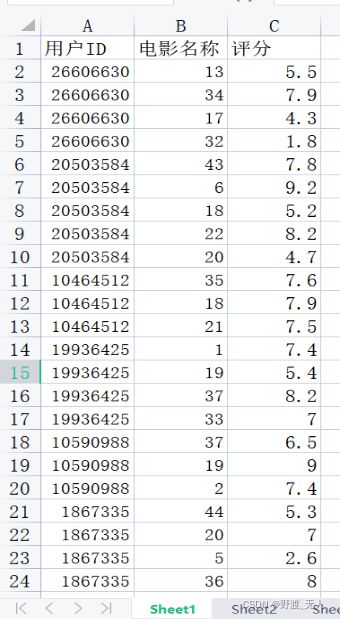
为减轻工作量,本系统选取用户ID、电影以及评分三个参数来完成对推荐系统的设计。从以上三千多条原始数据中选取了204条数据,并仅保留用户ID、电影和评分三个属性,选取的数据中共包含48部电影和52个用户。为了后续编程模型实现的方便,我们对电影编号1-48。处理后的数据如下:
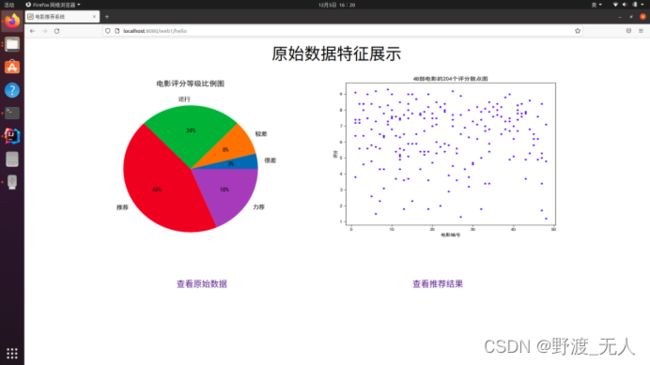
对选取的数据做散点图以观察其分布特征:
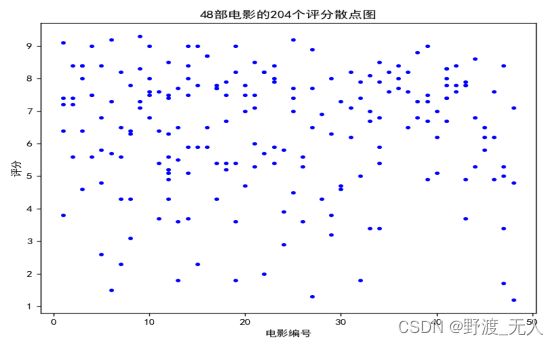
由图可知选择的数据分布的比较均匀。
3.4 数据处理
将图所示数据通过程序从本地上传至hdfs,然后使用基于物品的协同过滤算法对数据进行处理。
实现步骤:
(1)得到用户评分向量:map函数以用户ID作为key,电影ID和评分拼接形成的字符串作为value,将该键值对传递给reduce函数。reduce函数将具有相同键值的value通过逗号拼接。
(2)由用户评分向量得到共现矩阵:map函数对(1)得到的一行数据进行处理,将任意两个电影的拼接作为key,以1作为value将键值对传递给reduce函数,reduce函数将k值相同的value相加即得到共现矩阵。
(3)对用户评分向量处理,(1)的输出即为(3)的输入,仅使用map函数以电影ID为key,以用户ID和评分的拼接作为key。
(4)共现矩阵与用户评分向量矩阵相乘。
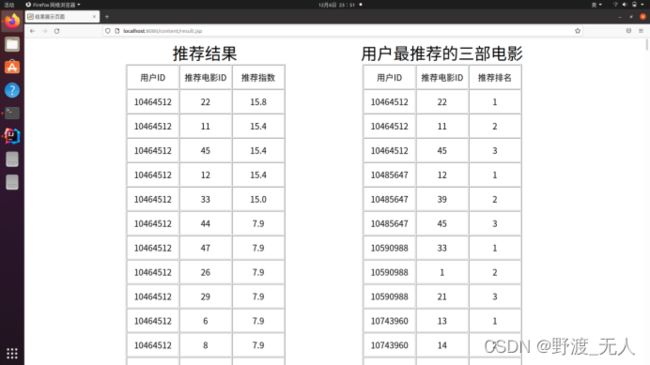
(5)对(4)得到的结果进行过滤和排序:过滤掉用户已经打过分的;按推荐权重倒序排列,得到最终结果。
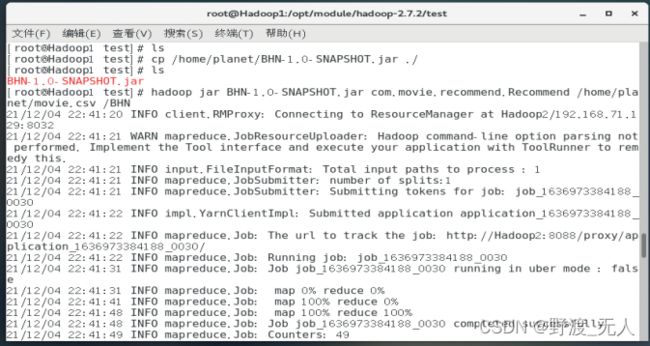
Hadoop集群上运行过程展示:
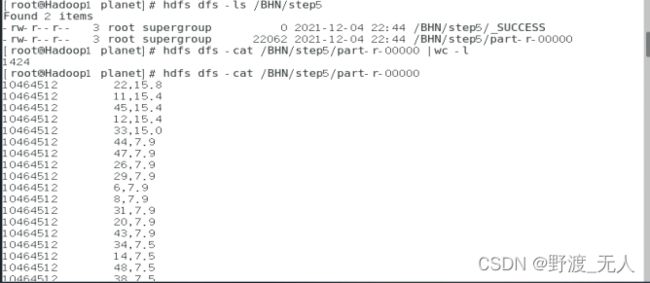
查看程序运行结果:
产生结果1424条数据。
3.5 结果展示
网页端我们在idea使用SpringMVC框架编写,共展示了三个页面:原始数据特征页面、原始数据集页面、推荐结果页面。在推荐结果页面我们对程序执行结果进行筛选显示了对每个用户最推荐的三部电影。
网页端展示
网页端查看原始数据
网页端查看推荐结果
4 总结
本系统实现了简单的基于协同过滤算法的电影推荐系统,并利用python爬取了豆瓣的真实数据进行分析,最后通过创建springMVC项目对结果进行了展示。但是该系统仍存在很多不足,编写的协同过滤算法仅结合了用户对电影的评分进行分析,比较简单,不足以满足用户的需求。因此后续我将继续研究协同过滤算法,将用户对电影的评价等其他因素也纳入算法中,完成推荐效果更好的电影推荐系统。