吴恩达深度学习之五《序列模型》学习笔记
一、循环序列模型
1.1 为什么选择序列模型
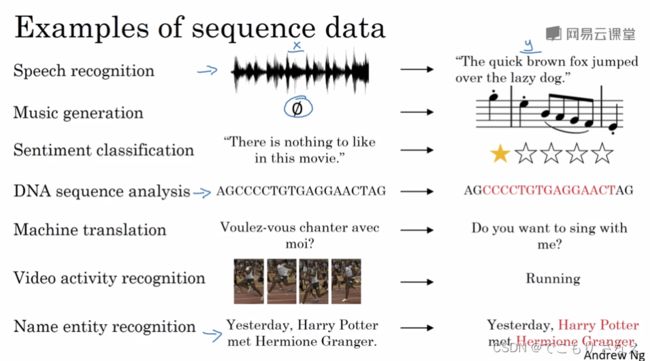
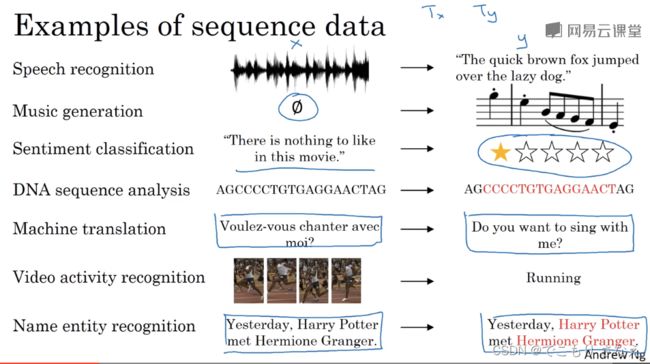
如图所示是一些序列数据的例子
1.2 数学符号

如图所示,我们用 ![]() 表示一个序列的第 t 个元素,t 从 1 开始
表示一个序列的第 t 个元素,t 从 1 开始
NLP中一个单词就是一个元素(又称时间步或时间戳)
用 ![]() 表示序列的长度,或说元素个数
表示序列的长度,或说元素个数
比如 ![]() 就是第 i 个样本的特征序列的第 t 个元素,同理有
就是第 i 个样本的特征序列的第 t 个元素,同理有 ![]()
再比如 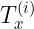 表示第 i 个样本特征序列的长度,同理有
表示第 i 个样本特征序列的长度,同理有 ![]() ,如图所示的是
,如图所示的是 ![]()
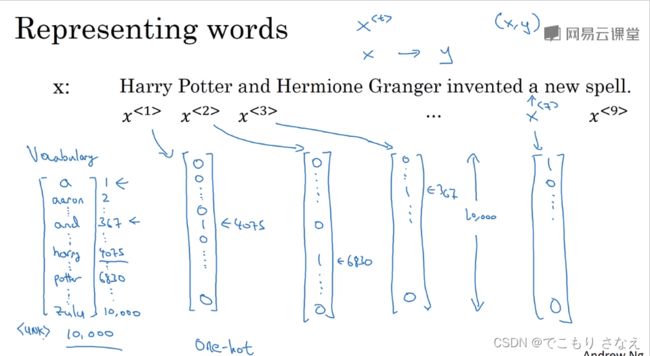
如图所示,如何表示一个单词呢
一个可行的方法是预先设置一个 字典 或者说 词表
对每一个单词,我们用 one-hot 独热编码表示
如图所示,为了方便讲课,词表中有 10000 个词,比如单词 a 在第一个位置,用向量表示就是 1 和 9999 个 0
onehot 就是用 n 个 0/1 来标识 n 个状态,同一时刻只有一个是1,其余是0,于是称作 onehot
当然,也是有 manyhot(nhot) 的,或者简称热编码,比如第一个图中的标签就是用热编码做的标记,来标记句子中的所有人名,当然标签的形式不止那一种,这只是一种方法
关于词表大小,一般30000到50000比较常用,也有用100000的,有时候在一些大型互联网公司,甚至能够达到百万级
1.3 循环神经网络模型
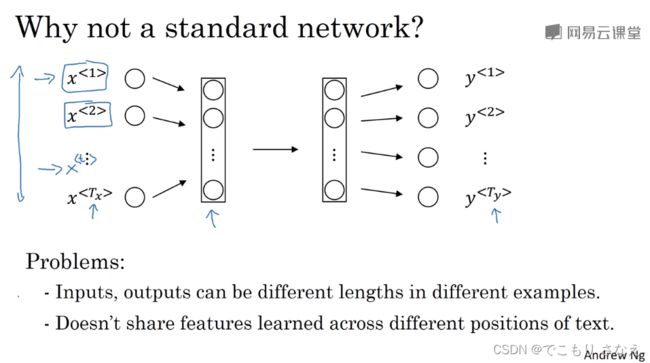
首先要讲的是为什么不用一个标准的网络呢
两个问题
第一,不同样本的输入输出长度可能不同,尽管你可以 padding 填充 0,但这依然不是一个很好的方法,而且单词数可能很庞大,权重太多
第二,文本不同位置的特征并不共享。意思就是,打个比方,比如一个房价预测的机器学习模型,你设置的第一个特征是房屋面积,那第一个特征所对的权重就是房屋面积带来的影响对吧,这种就是特征位置固定。再比如图像识别,同一类问题的图基本上内容的位置都是那样,这种就是特征位置几乎固定或高度相关。我们知道不同样本的同一类特征肯定要用同一个权重表示其影响。然而在序列模型中,比如 NLP,你要预测句中人名,句子中的内容与位置具有高度不相关性,人名在哪都有可能,不是说第k个位置全是名词,第k'个位置全是动词,特征位置对应不上,所以完全没法用一个标准的神经网络来做
那你可能会想,是不是应该对独立的 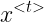 直接预测得一个
直接预测得一个 ![]()
但是注意 NLP 的特征间并非无关,而且与位置次序确实有关,只是这份关系无法用固定位置体现
所以这就需要我们的循环神经网络 RNN 了
如图所示便是一个 RNN,就是把单个元素的预测给串连起来,形成一条链。![]() 的激活值
的激活值 ![]() 乘以参数
乘以参数 ![]() 作为激活第
作为激活第 ![]() 个时间步的一部分。
个时间步的一部分。![]() 激活当前时间步用的参数记作
激活当前时间步用的参数记作 ![]() 。根据需求
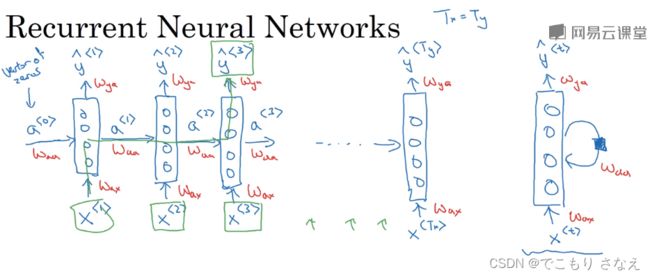
。根据需求 ![]() 也可能有一个输出
也可能有一个输出 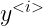 ,用的参数记作
,用的参数记作 ![]()
这里符号记录的含义就是,比如 ![]() 就是计算 a 由 x,
就是计算 a 由 x,![]() 就是计算 y 由 a
就是计算 y 由 a
图中右边是某些论文中的简记法。
显然 RNN 的第 i 个元素可以得到前 i-1 个元素的信息,但是 NLP 中往往与前后文都有关,这就需要 Bidirectional RNN 双向循环神经网络(BRNN)
更具体而言,RNN做的计算如下所示
初始化 ![]() 为 0 向量
为 0 向量
![]()
![]()
更进一步地,我们可以用增广阵简化符号
记 ![]() ,于是
,于是
![]()
![]()
实际上 ![]() 后面那个 a 是多余的,因为
后面那个 a 是多余的,因为 ![]() 里只有它,所以实际上就是直接去掉
里只有它,所以实际上就是直接去掉
1.4 通过时间的反向传播

神经网络框架会自动实现反向传播,所以这里我们只需要粗略了解即可
如图所示,一个样本的损失函数就是各个时间步的损失函数之和
然后反向传播梯度下降实际上还是老样子,换汤不换药,不具体讲了
横着的 ![]() ,实际上就和普通的网络一样,就是往回一步步链式求导就行
,实际上就和普通的网络一样,就是往回一步步链式求导就行
但是注意一个问题,实际上本质不一样对吧,我们这里是一层隐藏层,T个时间步,这是随时间步的反向传播,而并非随层的反向传播,然后一定不要把层和时间步叫混了,这个很重要
然后就是名字比较炫酷,Backpropagation through time 通过时间的反向传播,给人的感觉就像时间回溯一样,实际上就是这样
1.5 不同类型的循环神经网络
如1.1的图所示,我们前面的例子是识别人名,这是一个 Tx 和 Ty 对等的例子
问题来了,Tx 不等于 Ty 怎么办呢
比如音乐生成,它是 Tx = 0,比如情感分类,它是 Ty = 1,比如机器翻译 Tx 和 Ty 可能是某个不相同的值
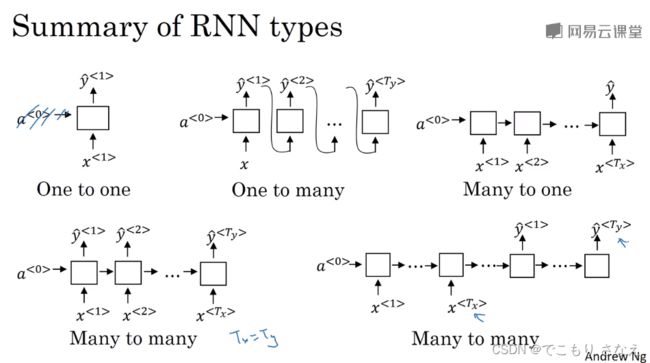
如图所示,可以分为 one to one、one to many、many to one、many to many 四类问题
其中 one to one 不是 RNN,many to many 又分成 Tx 和 Ty 是否相等两种情况
音乐生成用的就是 one to many,这种情况下会把 y^{
情感分类用的就是 many to one,这种情况下很简单,最后一个时间步输出 y 即可
人名识别用的就是左边那个 Tx=Ty 时的 many to many
机器翻译用的就是右边那个 Tx!=Ty 时的 many to many,其思想是输入输出拆成左右结构,看成 x 的 encode 到 decode 得到 y 的一个过程
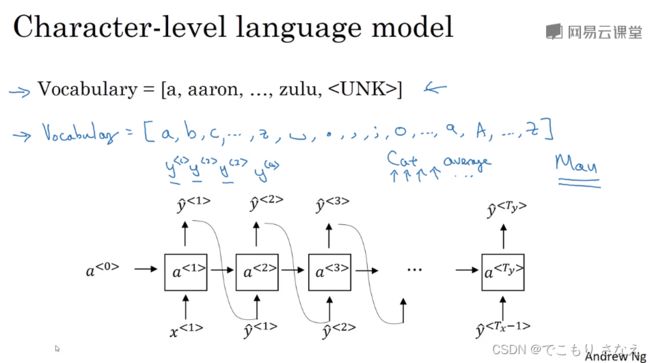
1.6 语言模型和序列生成
![]()
如图所示,对 NLP 的句子,像我们之前讲的那样,首先要 tokenize 标记化,比如用 onehot 编码
其中对于词典中不存在的,标记为
对句尾,多一个标记
对于标点符号,你觉没用那就删掉,觉得有用那就加到字典里
对于输出,是对应于 onehot 的一个 softmax
图中是 one to many 的例子,有一些细节需要注意
对预测,我们是拿预测的 ![]() 喂给 t+1 时间步,对训练实际上我们应该把真实标签喂进去,后面的时间步的训练基于正确的前提才是有意义的,也就是预测
喂给 t+1 时间步,对训练实际上我们应该把真实标签喂进去,后面的时间步的训练基于正确的前提才是有意义的,也就是预测 ![]() ,但是不喂给 t+1 时间步,而是把真实的
,但是不喂给 t+1 时间步,而是把真实的 ![]() 喂给 t+1 时间步,这里要注意,喂的是上一个时间步的真实标签,所以就是相当于
喂给 t+1 时间步,这里要注意,喂的是上一个时间步的真实标签,所以就是相当于 ![]() ,然后
,然后 ![]() (需要补充的是,因为喂真实标签,就不用前后传了,所以就把线掰开了,于是就相当于把真实标签看作特征,也就是图中的那种形式)
(需要补充的是,因为喂真实标签,就不用前后传了,所以就把线掰开了,于是就相当于把真实标签看作特征,也就是图中的那种形式)
对于整个句子预测正确的概率,实际上就是各个时间步概率的乘积,但要注意这个概率实际上已经是个条件概率了对吧,因为你是基于前面时间步的预测,所以符号表示如图右下角所示
损失函数还是很简单,就是全加一起就行了
这里我发现第二个课程中 3.8 吴恩达忘讲了 softmax 的损失函数,这里博主补充一下
你可能会很疑惑为什么图中损失函数没有 ![]() 这一项
这一项
回忆第一个课程的 2.18,损失函数怎么来的
对一个特定标签预测正确的概率进行极大似然估计来让这个概率最大
比如 sigmoid
如果真实标签为真,此时预测正确概率就是 ![]() 这个表达式,对它做极大似然估计
这个表达式,对它做极大似然估计
如果真实标签为假,此时预测正确概率就是 ![]() 这个表达式,对它做极大似然估计
这个表达式,对它做极大似然估计
为了方便,不做分类讨论,我们合并成了一个表达式,把条件融入数学表达式中
让 ![]()
这样比如 y=1,后面那项就没了,y=0 前面那项就没了
然后做 log 再取负号,就是我们的损失函数,回看第一个课程的 2.18 即可,不再赘述了
sigmoid 是因为 1-y 来表示了第二个类别,那么对 softmax,当然没有 1-y 的必要啊,不妨设想,softmax 比如三个类别,预测正确概率分别是什么啊,当然是 ![]() 啊
啊
于是就是 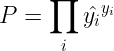 ,写成 log 就是图中那样只有 -ylogy
,写成 log 就是图中那样只有 -ylogy
1.7 对新序列采样
序列生成,说成预测实际上确实不太对,我纠正一下,我们应该用 采样 这个词
毕竟这种生成就是凭空生成
生成环节就是我们之前讲的穿起来的这样,如图所示
然后关于
目前一般都是基于词汇的序列化,实际上也有基于字符的,但是太耗费算力了,未来算力提升的话有可能更多投入应用,基于字符就没有
再就是讲一下序列生成的理解吧,就有点像彩云小梦的这个应用对吧,瞎写下文,只不过小梦上下文处理的更好,而且它在最初的时间步是有输入的。然后就是例子中这个有啥用呢,回忆上个课程学的神经风格转换,就和那个生成图像有点像的地方。比方说你拿了一堆莎士比亚的文章训练,大概其用途就是会随机生成出一个瞎写的莎士比亚风格的文章。
1.8 带有神经网络的梯度消失
回忆第二个课程1.10学的梯度消失和梯度爆炸,我们当时讲了梯度下降收敛得非常慢,为什么
梯度下降说到底就是该改变 W 让 y帽 逐渐趋近 y 的一个过程,而时间步过深,大量参数相乘,导致 y帽 不是大到爆炸,就是趋近0,这就导致 y帽 很难快速趋近到 y,即迭代次数过多,即整个网络的参数 W 变化收敛得很慢
那放到 RNN 中呢

如图所示,RNN它是有很多 ![]() 的,实际上你可以看作 t 个深度差 1 的网络的合并,这就导致什么呢,对一个很浅的 i 时间步,一个很深的 j 时间步,对
的,实际上你可以看作 t 个深度差 1 的网络的合并,这就导致什么呢,对一个很浅的 i 时间步,一个很深的 j 时间步,对 ![]() 损失的下降,其
损失的下降,其 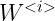 的收敛是很慢的,很难影响前面时间步的计算,很难传播回去再传播回来,即
的收敛是很慢的,很难影响前面时间步的计算,很难传播回去再传播回来,即 ![]() 对
对 ![]() 的有效影响很小,没起到什么用途,换言之图中例子,序列很长,前面的主语 cat/cats ,对后面很远的谓语 was/were 很难产生影响,而就人类语法而言它本应当有很重要的影响
的有效影响很小,没起到什么用途,换言之图中例子,序列很长,前面的主语 cat/cats ,对后面很远的谓语 was/were 很难产生影响,而就人类语法而言它本应当有很重要的影响
这就是RNN中的梯度消失,也是RNN的一个弊端,不擅长处理长期依赖的问题,这个问题很难处理,之后几节课会讲
然后还有梯度爆炸的问题,就是太大或太小变成NaN,即参数的数值溢出,这个实际上比较好解决,可以用梯度修剪,其方法就是设置一个阈值,或说最大值,让梯度下降向量或说其变化值不超过这个即可,事实证明这个方法有很强的鲁棒性
1.9 GRU单元
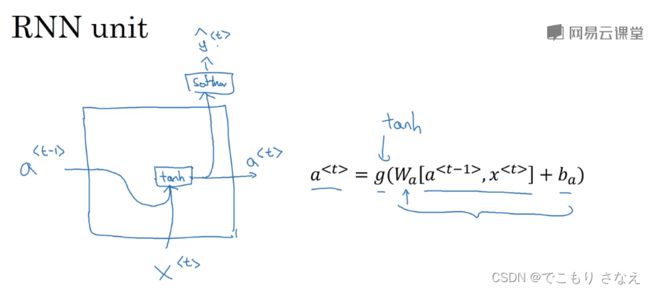
如图所示,就是我们前面学的RNN中的一个隐藏层单元
下面我们要讲的是在RNN单元基础上加入记忆功能得到的优化,GRU单元( Gated Recurrent Unit )门控循环单元
首先先说一下这个字母 ![]() 是大写的 gamma,看着很像门
是大写的 gamma,看着很像门
我们先理解门控单元在干什么

参考文献 2014 论文如图所示
如图是一个简化版的 GRU,c 表示一个叫记忆细胞的变量 memory cell,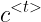 是在第 t 时间步仍然被记住的一个前面的激活值
是在第 t 时间步仍然被记住的一个前面的激活值
我们可以理解为总是让候选值 ![]() ,然后用一个叫作更新门的变量(u代表update)
,然后用一个叫作更新门的变量(u代表update)![]() 来控制我们是让 更新为
来控制我们是让 更新为 ![]() ,还是沿用以前的激活值,
,还是沿用以前的激活值,![]() 表示更新
表示更新
图中的例子,就是把 cat 时间步的激活值一直记忆着,一直没有被更新了,在 was 时间步被直接使用了,然后之后可能不用了,就可以在这里被更新了
感觉上有点像第四个课程2.3学的残差网络
这时候你可能会有一个问题,一旦某时间步的记忆有用,那我是不是将被迫记着直到它被用才能释放,其他想被记忆与使用是不可能的了,有多个同时起作用应当一次记多个也是不可能的了,确实是这样,所以需要完整版的GRU,这个稍后讲,我们先理解完简化版
简化版的公式写出来就像下面这样
![]()
![]()
![]()
回忆激活值怎么算,是 ![]()
注意 ![]() 的写法,实际上没必要单独分开
的写法,实际上没必要单独分开 ![]() 、嘛,直接激活作为记忆细胞一部分就好,c既包含激活的部分又包含记忆的部分,所以GRU里没有 a,用 c 代替了 a
、嘛,直接激活作为记忆细胞一部分就好,c既包含激活的部分又包含记忆的部分,所以GRU里没有 a,用 c 代替了 a
然后更新门 ![]() 用的是 sigmoid 来计算的,并不是严格的 0/1,但最后基本上总是挺接近0或1的,所有前馈已知量就是
用的是 sigmoid 来计算的,并不是严格的 0/1,但最后基本上总是挺接近0或1的,所有前馈已知量就是 ![]() 嘛,所以显然就是用
嘛,所以显然就是用 ![]() 乘以这俩,来通过前面所有已知信息自己训练是否更新。
乘以这俩,来通过前面所有已知信息自己训练是否更新。
然后说完整版的
我们前面讲过实际上你可能混合着记嘛
所以就像图中那样多一个门调整 c 的比重就好了,r 可以看作相关性,但实际上是 reset,![]() 叫作复位门或重置门,作用是可以丢弃无用的历史信息或是调整其影响权重
叫作复位门或重置门,作用是可以丢弃无用的历史信息或是调整其影响权重
最终公式如下
![]()
![]()
![]()
![]()
这里还需要注意,为了方便学习,吴恩达刻意选用了这些符号,在其他一些论文中, 一般用 ![]() ,
,![]() 用
用 ![]() ,二者不叫记忆细胞而是称之为隐藏状态和候选隐藏状态,
,二者不叫记忆细胞而是称之为隐藏状态和候选隐藏状态,![]() 用
用 ![]() ,
,![]() 用
用 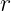
1.10 长短期记忆(LSTM)

参考文献如图所示,可以看到 LSTM 是 1997 就已经提出的,GRU是其简化版本,按 GRU 我们讲的来理解就好,实际上 LSTM 比 GRU 看起来正常多了,也更好理解,记忆细胞和激活值也是分开的,具体理解就不讲了,直接给出公式
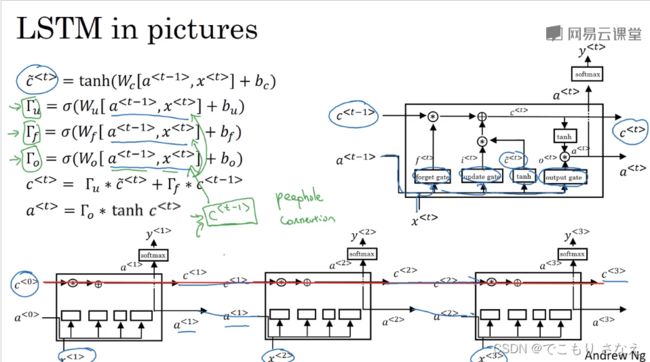
三个门,分别叫 更新门、遗忘门、输出门,公式如下
![]()
![]()
![]()
![]()
![]()
![]()
一般最常用的版本实际上是窥视孔连接 peephole connection,改变是输出门公式中考虑了上一时间步的记忆细胞的值,如下所示
![]()
什么时候用 GRU,什么时候用 LSTM?GRU作为简化版,仅两个门,计算效率更高,适合更大规模的问题,建立更大规模的网络。一般情况下会默认选用 LSTM,但这两个都是值得尝试的。
1.11 双向神经网络
标题的翻译不太对,是双向循环神经网络 BRNN
非常简单,打个比方,比如 6 个元素,x1->x2->x3->x4->x5->x6
比如对 y3 的预测,用的是 a2 和 x3 对吧,缺什么,缺 x4、x5、x6 对吧,那怎么办
你倒过来再来一个网络不就完事了吗,对吧,就像这样 x1<-x2<-x3<-x4<-x5<-x6,就是前向传播和反向传播颠倒一下再来个网络,这下就传给了 x3 一个用 x4、x5、x6 得到的 a
对 t 时间步的激活值,正向网络算出的记作![]() ,反向网络算出的记作
,反向网络算出的记作![]()
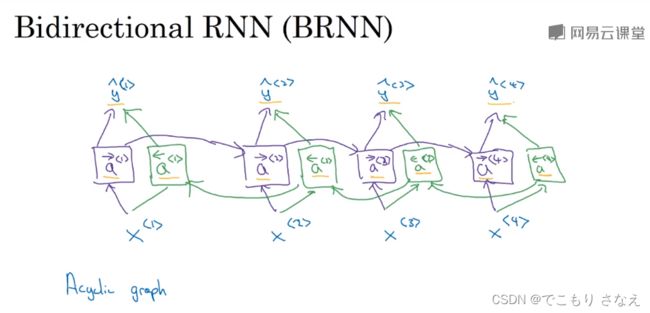
如图所示就是这样,特别好理解
但是我觉得这个画的不好看,下面这个从网上找的可能舒服一些
这一个隐藏层可以看作两个,一个前向层和一个反向层

1.12 深层循环神经网络
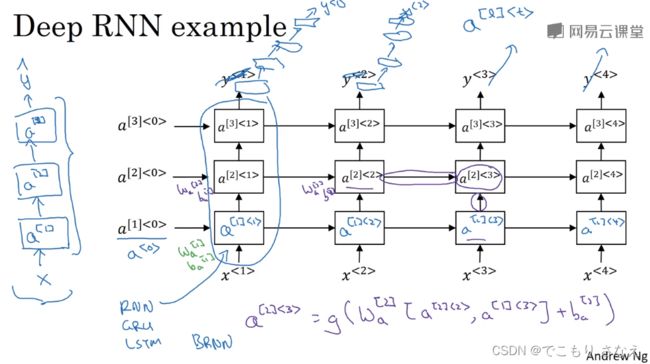
我们前面学的都是以一层RNN隐藏层为例
实际情况应该像图中那样整体从下往上接很多层,一个激活值来自对其左边和下边激活值的计算
当然 RNN 不像普通网络那样,实际上三层就会使总的单元数足够多了
一般不会有太多的 RNN 单元,一种常见的架构是,会在几层 RNN 隐藏层后,每个时间步从下网上有一些自己的普通神经网络,这些就是没有时间步间的传递了
二、自然语言处理
2.1 词汇表征
词嵌入 word embedding,是对词单射到另一个空间的映射,映射结果称作 word representation,前面我们讲了一个最暴力的 one-hot representation
然后具体说下本课程中符号,比如10000维字典,Man这个词是第5391个词,那么它就可以表示为一个onehot向量,第5391处为1,其它为0,这个向量我们记作 ![]()
onehot有个什么缺点呢,考虑比如我们见过
I want a glass of orange juice
那么对于
I want a glass of apple ____
从人类知识角度,显然我们能很容易预测到这个应该填 juice
然而我们的机器没见过 apple,也不知道 apple 和 orange 都是水果。onehot 任意词与词之间内积是0,其缺点就是,它把每个词孤立起来,以至于使得算法对相关词的泛化能力不强,也就是它表示不了词义间的关联,以至于上面那种看起来很显然的东西,没有充足全面的训练数据,它将无法轻松地实现很好的预测,而为了这种事搞数据搞不起的,就是浪费,所以我们要优化我们的算法
解决方案就是特征表示的方法,实际上就是类似我们平常机器学习做的特征工程,只不过深度学习里相当于把 DataFrame 横过来看了,如下图所示

对字典里一万个词,我们不再用onehot,不在把其位次化作向量,而是设置了我们想要的一些特征,比如性别、年龄、大小等等,图中有300个这样的特征,每个词都对应有300个值,用一个300维的特征向量来表示一个词
比如性别,那男人可能就是-1附近,女人就是1附近,橘子苹果可能就是0附近
这样我们对词的表示就可以在含义上相似
然后之后的视频中会讲到如何自己学习这种词嵌入方法,毕竟这种如果人工标记就太离谱了
然后这里课程中我们用的符号表示比如男人是字典中第5391个,它的这个三百维向量我们用符号 ![]() 来表示,或者更简单一点,你可以写作
来表示,或者更简单一点,你可以写作 ![]()
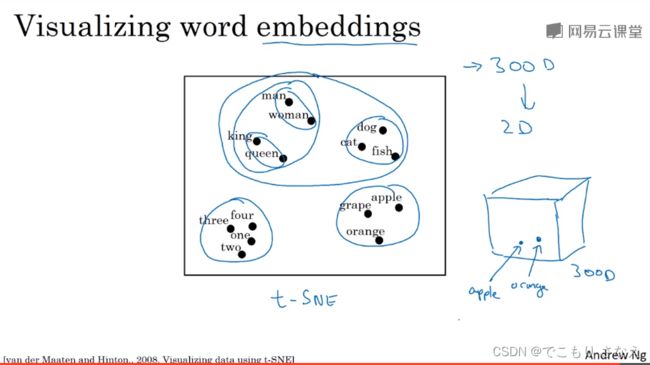
如图所示的2008论文提出了一个叫作 t-SNE 的可视化算法,它将 300 维向量映射到了二维从而实现了可视化分析,这也是我们常用的可视化方法
可以看到,男人女人都是普通人,聚在一起,国王王后都是皇族,聚在一起,这四个又整体聚在一起,都是人。再比如猫狗鱼都是动物,聚在一起,上面说的这些又都是生物,整体聚在一起
2.2 使用词嵌入

回想以前的课程,用学习的词嵌入实际上本质就是迁移学习预训练微调的过程对吧,这里就不多说了
那么词嵌入模型怎么来,一种方式是,你可以从大型文本语料库下载大量文本用聚类算法训练。另一种方式是你可以直接就下载别人现成的预训练模型。实际上吧,现在已经都是调包时代了,甚至都不用费劲找了
然后再需要注意的就是你目标任务的训练集不要太大,要相对小一点。毕竟是迁移学习对吧,微调一定要相比于预训练小一些才会效果好。
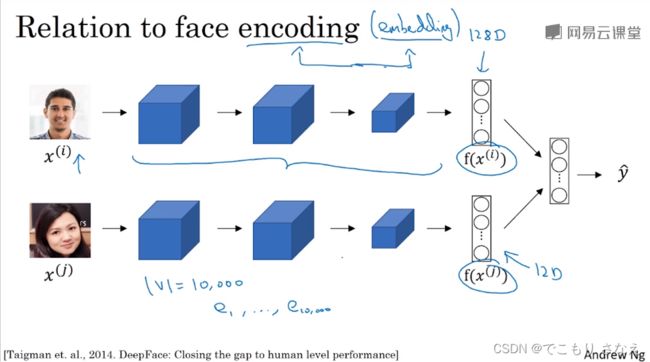
上一个课程里的图,人脸图像的编码encoding,有没有发现和词嵌入embedding很像
实际上就是这样的,二者是完全一个道理的,但是用语上我们还是会区分,二者是有一点小区别的,人脸识别我们要面对未知的海量数据,而词典我们可能就限定在了10000个词,不会变,这就是二者最大的区别
2.3 词嵌入的特性
词嵌入的一个很重要的特性是类比推理,它可以帮助我们理解词嵌入做了什么、能够做什么
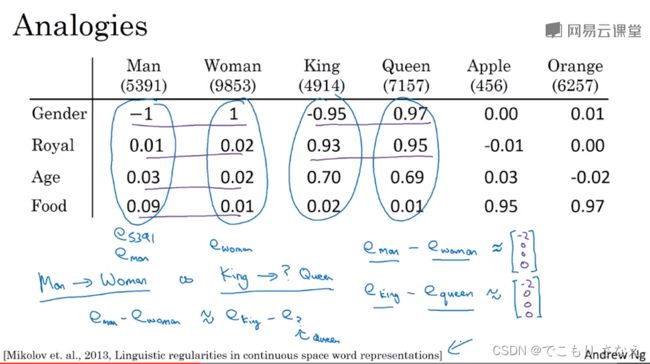
2013论文如图所示
man 相对于 woman,相当于 king 相对于 queen
这只需要看 ![]() 和
和 ![]() 这两个向量的相似程度
这两个向量的相似程度
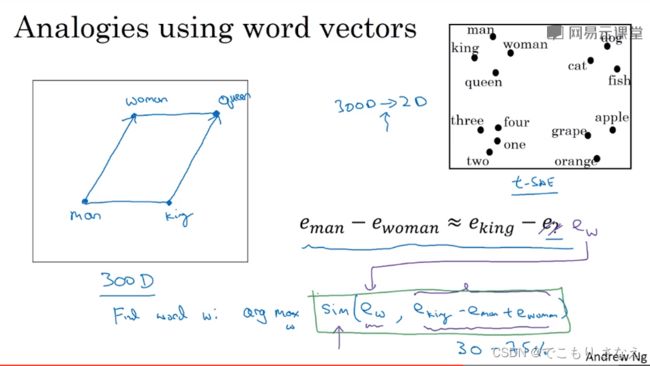
类比推理也是有着很重要的使用价值的,如图所示,我们知道 man 相对于 woman,那么 king 相对于什么呢
换言之,就是找一个 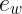 ,让
,让 ![]() 相似程度尽可能高
相似程度尽可能高
换言之,移项过去,就是令一个相似度函数 sim,取让 ![]() 最大的一个
最大的一个 ![]()
不用神经网络模型,单纯的这样一个相似度函数做这个类比推理问题,其结果正确率可以达到约 30% 到 75%
下面我们讲一种相似度函数

如图所示是余弦相似度函数,字面义就是求两个向量夹角的余弦值
公式就是

实际上高中解析几何经常用这个,就不多讲了
注意写法,以后也是这样,![]() 我不表示自带平方的那个第二范式,而是单纯的欧几里得距离,也就是平方和后要开根,如果表示平方距离,我会写成
我不表示自带平方的那个第二范式,而是单纯的欧几里得距离,也就是平方和后要开根,如果表示平方距离,我会写成 ![]() 或者
或者 ![]()
那么这个余弦相似度就是越大越相似,越小越不相似
另一个可以考虑的相似度函数是直接的平方距离 ![]() ,实际上从概念角度讲,相似度要用大表示相似,小表示离异,所以这个平方距离表示的其实应当叫离异度,所以作相似度的话最好要整个式子前面填一个负号
,实际上从概念角度讲,相似度要用大表示相似,小表示离异,所以这个平方距离表示的其实应当叫离异度,所以作相似度的话最好要整个式子前面填一个负号
2.4 嵌入矩阵
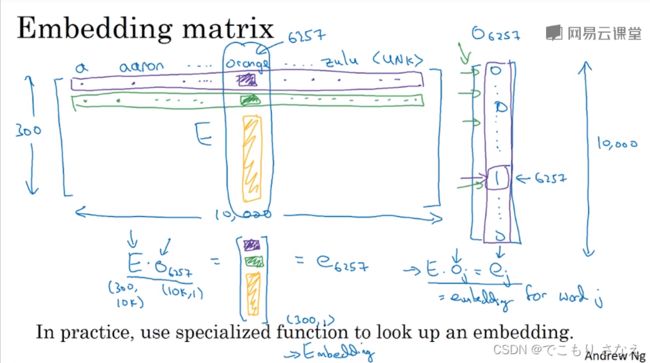
如图所示,整个字典的所有词的特征表示的那个矩阵就称作 嵌入矩阵 E
然后比如第 6257 个词,你会发现显然 ![]() ,o 是 onehot 向量
,o 是 onehot 向量
整个 E 由参数构成,学习这个 E 就是在学习我我们词嵌入
但实际上现在有更好的方法提取和嵌入特征矩阵中的特征向量,这比矩阵乘法肯定要快的,但是我们写记号还是会愿意去这样写,便于理解
2.5 学习词嵌入

2003论文如图所示
当时提出的一个学习词嵌入的方法是
当前位置的词作为标签要被预测,当前位置前的四个词每个都乘以 E 后得到 e 作为四个输入特征
不妨设想 orange juice 和 apple juice,我们用 apple 和 orange 的 e 都想预测得到 juice,显然二者会学习出在这方面相似的参数,于是不难理解这个方法可以很好地为我们学习出 E

考虑一些其他的 上下文/目标词对 选取方法
我们可以用目标前四个词,也可以目标左边右边各四个,也可以仅用目标词前一个词,也可以用目标词附近一个词
事实表明,当你建立语言模型时,上下文应当像第一个那样,选取目标词前的上下文。学习词嵌入时,四个方法都可以考虑。
对于目标附近一个词,比如图中 juice 用前面的 glass 预测这样,具体怎样选取,之后会讲一些公式化的选取方法,其中比较著名的是 skip gram
2.6 Word2Vec

如图是 Word2Vec 的其中一个版本 skip gram
这里 context 我们可以简记作 c,target 我们可以简记作 t
对于 (c,t) 对的选取,我们首先全文随机选一个 c,然后在一定 c 的词距内随机选一些 t,来构成一些 (c,t) 对,词距可以正负5或者10范围内选一些,然后选多少个你可以自己调节

了解完怎么采样后,接下来是构建什么样的模型以训练
如图所示,选完 (c,v) 对后,![]() 作为输入特征,模型仅由一层 softmax 构成
作为输入特征,模型仅由一层 softmax 构成
比如词典大小 10000(图里多写了个k),我们预测目标词用 softmax 做10000 分类
回忆我们第二个课程 3.8 学过的 softmax,本课程前面也提到过
概率公式和损失函数公式如下

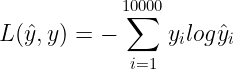
最关键的问题是什么,这个softmax你算损失函数是把字典那么长的向量求和,计算代价非常大

关于这个问题,是 softmax 本身的优化问题,如图所示 hierachical softmax(分级softmax)可以解决这个问题,它将复杂度从 V 降到了 logV 一个笨方法是二分判定树,实际 分级softmax 采用的是右边那种类似哈夫曼,不常用的词在下面,当然具体细节我就不知道怎么算的了,这个数据结构学过都会,但是我不知道它怎么用到求和里的,暂时了解即可
关于上下文c的采样,实际上一些 stop words,比方说 the、of 这种会频繁出现,太多了,反复计算这些的 ![]() 非常浪费,其他该被算的都没能被多算算
非常浪费,其他该被算的都没能被多算算
所以实际上 ![]() 的分布并不是在语料库上随机且均匀的采样得到的,而是采用了不同的启发来平衡常用的词和不常用的词
的分布并不是在语料库上随机且均匀的采样得到的,而是采用了不同的启发来平衡常用的词和不常用的词
实际上这篇论文中还有另一个 Word2Vec 版本,CBOW模型(Continuous Bag-Of-Words Model 连续词袋模型),它也有一些优缺点,本课中跳过了没有具体讲
2.7 负采样
负采样是对 skip-gram 的优化,它大幅降低了计算复杂度,尽管有些地方难以用理论证明,但它确实有效

2013论文如图所示
负采样做的是二分类预测,它预测的是是正样本还是负样本,换句话说就是 context 是否是用来推断 word,注意这里是 (c,w,t) 对,t 用于表示正负(1/0)
t 为 1 表示 (c,w) 在词距内,t 为 0 表示 (c,w) 不在词距内或者 c,w 之一是停用词
对每个 context,我们取一个随机正样本,和 k 个随机负样本,随机取样方式类似 skip-gram
k 的选取规则是,小型数据集在 5 ~ 20,大型一点一般用 2~5

如图所示是 k=4 的例子,网络模型 输出层不再是以前的 V个结点的 softmax,而是 k+1 个 sigmoid 结点

对于采样分布,我们上节课讲过均匀分布肯定不好,会取到很多停用词
论文作者经尝试后表示 词频的3/4次幂 在词频和中的占比是一个很好地采样概率,如图所示
尽管这没有被理论证明,但确实有效,很多人也都采用了这个方式
2.8 Glove向量
Glove算法虽然用的没有 Word2Vec 那么多,但还是有一部分人在用,其主要优势是简便
 2014论文,如图所示
2014论文,如图所示
Glove:global vectors for word representation 词表示的全局向量
我们用 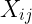 表示 词距内词 i 出现在词 j 前的次数
表示 词距内词 i 出现在词 j 前的次数
易证 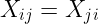

模型非常简单,梯度下降一个所有出现次数构成的二次函数即可,如图所示,即
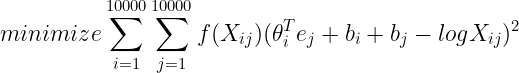
其中注意乘了个权重 ![]() ,依据启发性原则,不应均匀,应当给停用词一个比较低的权重,而实际上并非用的少就一定是停用词,比如 durian,像这种词应该调高一点权重
,依据启发性原则,不应均匀,应当给停用词一个比较低的权重,而实际上并非用的少就一定是停用词,比如 durian,像这种词应该调高一点权重
然后注意到 ![]() 时,
时,![]() 会出错,实际上
会出错,实际上 ![]() 本身也确实属于忽略的,所以令
本身也确实属于忽略的,所以令![]()
对于 ![]() 、
、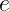 这两个参数,你会发现二者在式中是完全对称的,其功能完全一样
这两个参数,你会发现二者在式中是完全对称的,其功能完全一样
我打个比方,比如 ![]() 和
和 ![]() 有区别吗,没有!上面那个求和式展开就是这样一个完全可颠倒的
有区别吗,没有!上面那个求和式展开就是这样一个完全可颠倒的
不妨思考 ab=4,求 a+b 最值,最后 a=b=2 对吧。理想状态下,取得最值时,显然 ![]() 等于某个值,那是梯度下降最终的理想结果,而梯度下降实际上总是在不断接近这个理想值,比方说 a 下降到 1.9,b 下降到 2.105,那么这种情况下取平均作为最终结果是非常好的,如下所示
等于某个值,那是梯度下降最终的理想结果,而梯度下降实际上总是在不断接近这个理想值,比方说 a 下降到 1.9,b 下降到 2.105,那么这种情况下取平均作为最终结果是非常好的,如下所示
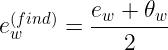

这张图讲的内容其实比较废话,但是值得了解,人为设定的嵌入向量是可理解的,而且基本正交的,比方说图中那样画出的 royal 和 gender 那样,但是我们自动学习得到的可能像图中 e_w,1,e_w,2 那样,基本不可理解,甚至都不正交
然后下面那个带 A 的我不是很懂他要表达什么,可逆消掉是很显然的,![]() 大概是这个公式的原始式,之所以这样写大概有什么含义在里面,我不是很懂,有懂的可以在评论区给讲下
大概是这个公式的原始式,之所以这样写大概有什么含义在里面,我不是很懂,有懂的可以在评论区给讲下
2.9 情绪分类
首先要说一下,这标题翻译不太对,大家都是叫情感分类
对于情感分类问题,一个问题是,可能标记的训练集没有那么多,所以说根据迁移学习理论,利用词嵌入,即便中等规模的数据集也可以得到不错的表现
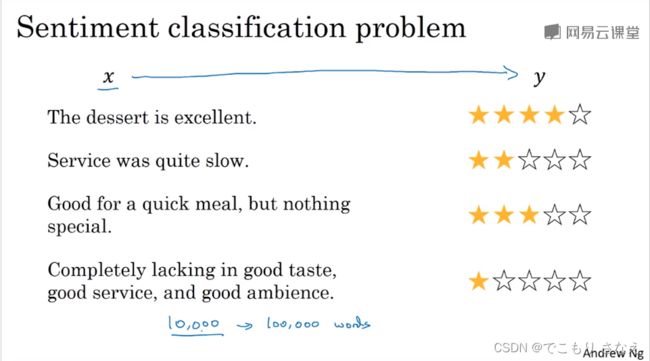
情感分类问题,比如说根据评论预测分数

如果不用 RNN,如图将一句话的各个词的特征向量直接取平均值然后 softmax
那这个意思应该理解的不错,但是预测结果可能恰恰相反,比如左下角那个例子 lacking in good,很多很多 good,这样一平均就成了好评,实际上这是个差评
所以这是个序列模型问题,一定要用RNN

如图所示就是一个最基本的多对一模型,输入我们用词嵌入而非onehot,这样去应用就好多了
2.10 词嵌入除偏

2016参考论文如图所示
很不幸的是,词嵌入连一些偏见和歧视也学会了,当然这和社会经济意识形态有着密切的关系
举个例子就是把 男人和程序员 关联,把 女人 和 家庭主妇 关联

以性别歧视为例,消除偏见的方法如上图所示
第一步,求偏见向量。把这些明确的性别词相减求平均,比如 ![]() 、
、![]() ,当然实际上直接求平均并不是很好,实际上论文中使用的算法叫 SVU,sigular value decomposition,奇值分解,类似于主成分分析 PC,principle component。然后这个算出来的实际上就是视作 1D 的 bias 轴,比如300维,可以算出相互正交的其他 299 个向量,就是非偏见轴
,当然实际上直接求平均并不是很好,实际上论文中使用的算法叫 SVU,sigular value decomposition,奇值分解,类似于主成分分析 PC,principle component。然后这个算出来的实际上就是视作 1D 的 bias 轴,比如300维,可以算出相互正交的其他 299 个向量,就是非偏见轴
第二步,中和步,对所有没有明确定义性别的词消除性别偏见。比方说 doctor、babysitter 这种词就是性别中立的,应当消除偏见,减去偏见向量(大概不是直接减去,可能有些其他的数学算式在里面)。然后比如 grandma 和 grandpa 就是明确的非性别中立,再比如一般都是男人才有 beard,这些非性别中立的要保持。那么怎么判断这种词呢,作者的方法是训练一个分类器。
第三步,平衡步,对非性别中立的词对进行平衡。注意是pairs,你想 beard 这种就不用管了,要处理的是 grandma 和 grandpa,如图所示,实际上 babysitter 到他俩的距离还是不一致,这是对 grandma 和 grandpa 本身的偏见程度不一致的问题,如图所示就是两个都往左挪一挪就行,具体的用到一些线代的理论,这里没有具体讲,暂时了解即可
当然,实际上原文有很多更复杂的细节,本课中只是浅显的了解一下,需要注意的是词嵌入除偏也是目前的研究者们不断研究的内容之一
三、序列模型和注意力机制
3.1 基础模型
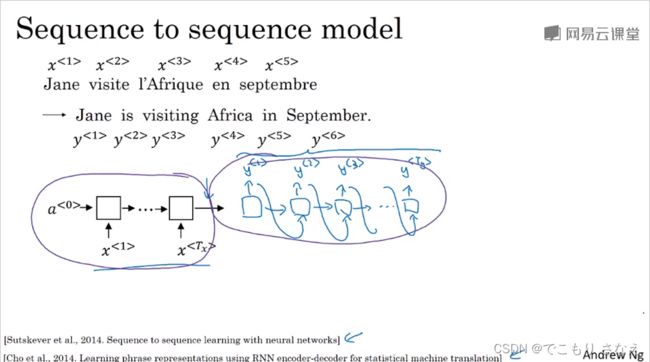
如图所示是一个最基本的 seq2seq 模型,一个编码网络接一个解码网络,做的是法语翻译成英语
前面我们讲 多对多的m!=n 的序列模型时讲过
最早是由如图所示的2014论文提出

如图所示是一个最基本的 image2seq 模型
几乎由如图所示的几个论文同时提出
实际上我们前面也学过这样的内容,图像识别的编码接一个序列模型的解码,做的是看图讲故事
3.2 选择最可能的句子
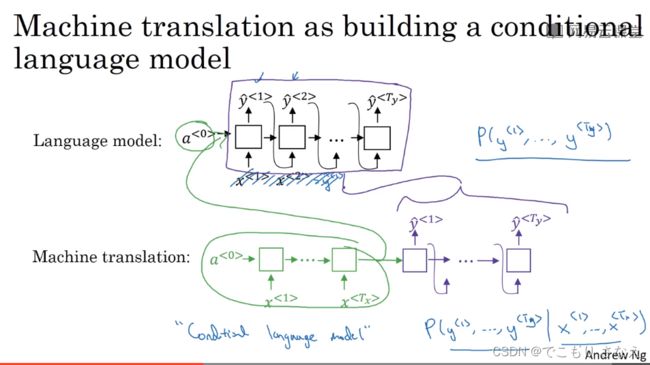
你会发现 多对多m!=n 实际上 解码部分就是一对多的序列生成
二者的唯一区别在于解码前的输入,一个是 0 向量,一个是提供了前提条件的编码
从数学上来看,就是 ![]() 和
和 ![]() 的区别,就是多了条件,变成了条件概率
的区别,就是多了条件,变成了条件概率
吴恩达把这种模型称作 条件语言模型
我们前面讲过所谓梯度下降,就是极大似然估计,让正确概率最大
考虑如果用ACM算法搜索的话,比如词典 10000 个词,句长为10,那么暴搜就是枚举 10000^10 个所有可能的情况,然后选出其中概率最大的那个

这里我要说明一下,你注意序列生成喂的是上一层标签,RNN模型训练的过程完全没有问题,喂的是真实标签,这个不需要搜索,但是对验证集测试集以及投入使用的预测中,喂的是前面的预测,那么我们softmax的原始功能中,输出、传递的是概率最高的,这实际上就相当于贪心搜索,依据前面的最优的条件,给出当前时间步最优的预测值,为什么贪心不行呢,这个很简单,因为我们关心的是整个句子的概率,而非每个单独时间步的概率,而且在这个问题中每个单独时间步在条件概率下最优,无法代表整个句子概率最优,这就说明了为什么我们要专门设计搜索,为什么不能用天然具备的贪心功能,这是一个要全局最优且无法被局部最优替代的问题,局部最优反而可能在全局很差,举个最简单的例子就是,1时间步最优0.9,假设在这个前提下,2时间步最优0.5,句子正确概率只有 0.45,而假设1时间步0.8前提下,2时间步最优0.8,句子正确概率 0.64,显然后者要好很多
具体例子就是如图所示,翻译成下面那个将来时可能更好,但是贪心的话 visiting 那里绝对不会预测成 going,这是很显然的
当然暴搜不可能的,所以提出了一个优化的方法,叫作束搜索(beam search,又称集束搜索),下节课会讲
3.3 定向搜索
这节课讲的是束搜索,标题定向搜索究竟是别称还是翻译错了我也不清楚,我觉得大概率是翻译错了...
集束搜索是一种启发式的搜索方法,在贪心的基础上优化,将其放宽,与其选出当前最好的,不如选出当前最好的几个,再进一步判断,局部最优不一定是全局最优,但全局最优往往可能是局部的前几名,即便我们这样挑没能挑出全局最优,但也经过了一些更好的比较,挑出来的比纯贪心要好,更接近全局最优
我们把集束宽度设为 B
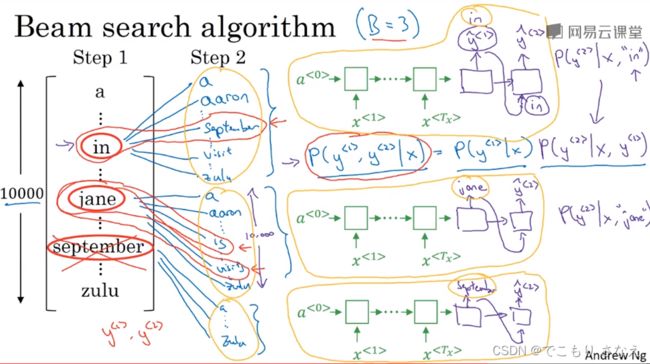
如图所示,假定 B=3,字典大小为 10000,来进行我们的讲解
对 ![]() ,通过 softmax,可以得到10000分类每个可能的概率,我们取前 3 名,前 3 名的输出分别喂给下一个时间步,预测正确概率要暂存一下,根据条件概率公式,前两个词都正确的概率是
,通过 softmax,可以得到10000分类每个可能的概率,我们取前 3 名,前 3 名的输出分别喂给下一个时间步,预测正确概率要暂存一下,根据条件概率公式,前两个词都正确的概率是 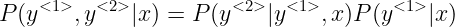 ,实际上就是独立事件的乘积关系,那么我们可以对原前 3 名分别进行下一个时间步的预测,即总共 30000 个情况,然后可以再次取出前 3 名,喂,暂存概率乘积,然后到第三个时间步,又是 30000 个情况,重复这样的操作,其中一名给出
,实际上就是独立事件的乘积关系,那么我们可以对原前 3 名分别进行下一个时间步的预测,即总共 30000 个情况,然后可以再次取出前 3 名,喂,暂存概率乘积,然后到第三个时间步,又是 30000 个情况,重复这样的操作,其中一名给出
3.4 改进定向搜索

普通的集束搜索有两个问题,第一个问题是概率小于1,不断连乘连乘,越来越小,最后可能下溢出,所以我们整体取 log,连乘P取log,于是就是 logP 求和
第二个问题还是不断连乘连乘越来越小,这意味着这样一个算法偏向长度短的,所以要惩罚项,归一化,除以长度 ![]()
实际应用中一般加一个超参数 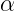 ,除以长度的 次幂,
,除以长度的 次幂,![]() ,想象一下,α=1意味着完全归一化,α=1,那么除的恒为1,没有归一化,介于完全归一化和不归一化之间可能比较好,比如 0.7,这是一个探索性方法,是超参数,需要实际使用时进行尝试
,想象一下,α=1意味着完全归一化,α=1,那么除的恒为1,没有归一化,介于完全归一化和不归一化之间可能比较好,比如 0.7,这是一个探索性方法,是超参数,需要实际使用时进行尝试
然后这样一个优化后的概率函数称作归一化的对数似然目标函数,如下所示
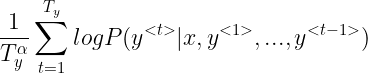
然后注意回忆我们前面讲的,还有一个需要注意的超参数是集束宽度 B
对于 B,显然 B 越大结果越好性能越差,B 越小结果越差性能越好
一般比较常用的是 B=10,100的话就已经感觉太大了,研究性论文一般会压榨性能,甚至曾出现1000、3000这样的选择,实际上B越大,性能提升空间就越小,从 3 到 10 能明显看到改善
3.5 定向搜索的误差分析
验证集结果不好,那如何判断是集束搜索出了问题,还是RNN模型本身出了问题呢
盲目增大 B 未必可取,问题可能出在 RNN 身上,所以我们有必要判断有没有花这个时间增大B的价值

如图所示,我们将人工标记的结果记作 ![]() ,预测的是
,预测的是  ,我们将
,我们将 ![]() 带进 RNN 中,也就是用其对应的 RNN softmax 计算的概率相乘,来计算
带进 RNN 中,也就是用其对应的 RNN softmax 计算的概率相乘,来计算 ![]()
第一种情况,如果 ![]() ,这意味着我们没能挑出最好的结果,是 beam search 的问题
,这意味着我们没能挑出最好的结果,是 beam search 的问题
第二种情况,如果 ![]() ,这意味着我们的 RNN 网络计算的有问题,把
,这意味着我们的 RNN 网络计算的有问题,把 ![]() 算小了,这是 RNN 的问题
算小了,这是 RNN 的问题

像第三个课程 2.1 讲过的那样,我们可以选一些误差大的用例,绘制表格具体分析,统计到底谁的错误更多,对每个例子,beam search 犯错记 B,RNN 犯错记 R,就这样统计,找出原因
3.6 Bleu得分
翻译可能有多个都不错的答案,那么怎样计算准确性更好呢,为了解决这个问题于是有了 Bleu 分数
 2002参考论文如图所示
2002参考论文如图所示
Bleu:bilingual evaluation understudy 双语评估替补
Bleu是基于查准率的思想,图中举例计算的是一个词的Bleu中的查准率
对于一句话的翻译,我们可以给出多个答案
如图所示两个参考,The cat is on the mat. 和 There is a cat on the mat.
我们的预测输出,the the the the the the the(七个)
计算一个词的查准率方式,实际上就是 7 个则在参考中都有出现,于是是 ![]() ,当然这显然不合理,所以实际上 Bleu 中我们使用一种修正版本
,当然这显然不合理,所以实际上 Bleu 中我们使用一种修正版本
对一个词 the,我们取参考中出现 the 最多的那个参考,这里就是参考1,The cat is on the mat. 我们计算输出的 the 中答对了几个参考 the 的占比,这里就是输出了 7 个 the,参考 2 个,即答对 2 个,于是 the 的查准率是 ![]()
上面那个例子有点特别,实际上输出句子我们是把一句话每个长度为1的词组划分开,这里我给它拆开来说明,这样更容易说明、更好理解,实际做的时候实际上应该合并按个数大小去比对,我们拆开看,比如输出句子是 the cat the the mat,它一个一个看,每个词单独看最多的那个参考,the 中了,cat 中了,the 中了,the 没中,mat 中了,于是句子长为 1 的词组的查准率为 ![]()
再比如词组长为 2 的例子,如下图所示

输出中所有长为 2 的词组,按顺序看 the cat、cat the(没中)、the cat(没中)、cat on、on the、the mat,所以是 ![]() ,当然这里注意我们说每个词组单独看最多的那个,the cat 看的是参考1,而 cat on 看的是参考2
,当然这里注意我们说每个词组单独看最多的那个,the cat 看的是参考1,而 cat on 看的是参考2

n 个词的词组的查准率就是 n 个词的词组的 bleu 分数
最后不同长度词组组合的 bleu 分数如下

n 多大你自己设,图中例子就是 n=4,我想或许 4 是一个比较具有鲁棒性的大小
注意一个问题,比如我们设 n=2,上面的例子中,输出两个 the 是不是就满分了呢,确实是这样,换言之就是为了保住目前的分数而不去大胆预测,导致根本都没做些什么预测,就拿到了满分,这恰恰就是查准率的特点,宁可漏掉,也不错杀,请回忆机器学习课程笔记,或者深度学习第三个课程的1.3,为了解决这个问题,我们对输出长度比参考长度短的肯定要扣点分数,加一个惩罚项
这里的 BP 就是我们说的那个惩罚项,它实际上字面义就是这个 brevity penalty,公式如下
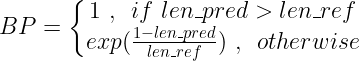
当然我们用的其实不止一个参考,那怎么比较啊,这里吴恩达并没有讲,具体细节还是要去看图中所示的那篇论文
3.7 注意力模型直观理解
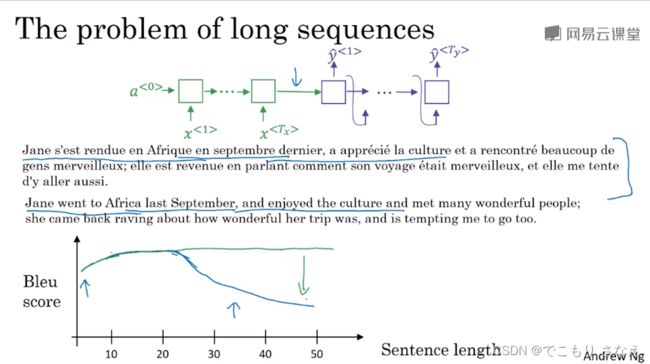
如图所示,当句子很长的时候效果可能会变差,想象一下人类也是这样,注意力记忆力有限,一个长句都是一部分一部分翻译
如果我们不是编码整个句子后然后解码,而是编一部分解一部分,那长句就会像短句一样好,就像图中绿线那样
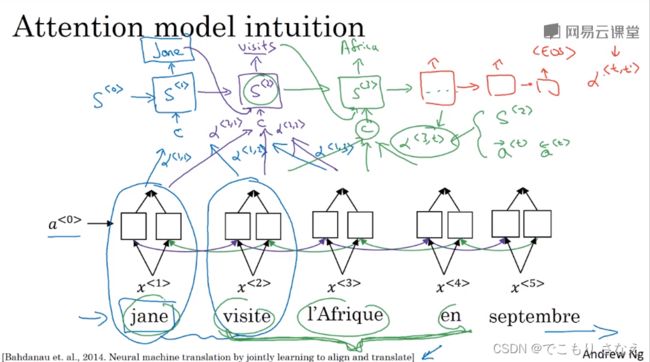
2014论文如图所示
这节课讲的是直观理解,可以看作一个 BRNN 网络每个单词进行编码,然后再用一个网络生成解码结果,相比于以前输入整个编码网络前向传播的整个句子编码,我们对生成一个解码单词,可以选择附近的一部分编码单词,将其注意力放在最重要的附近单词,而BRNN又确保了其确实考虑到了整个句子
对解码网络或者说生成网络我们的激活值或者说隐藏值的符号做了下区分,用 ![]() ,在编码网络中记作
,在编码网络中记作 ![]() ,然后对解码网络的激活值计算,我们有一些参数 ,比如
,然后对解码网络的激活值计算,我们有一些参数 ,比如 ![]() 表示用编码网络的第 t 层计算解码网络第 3 层,这个参数在论文中给出的形式与
表示用编码网络的第 t 层计算解码网络第 3 层,这个参数在论文中给出的形式与 ![]() 有关,细节下节课会讲。像我们前面讲的那样,对附近几个编码词做解码,比方说第三层计算可能用到
有关,细节下节课会讲。像我们前面讲的那样,对附近几个编码词做解码,比方说第三层计算可能用到 ![]() 等等,然后这些特定的权重又表明着附近词的重要程度
等等,然后这些特定的权重又表明着附近词的重要程度
3.8 注意力模型
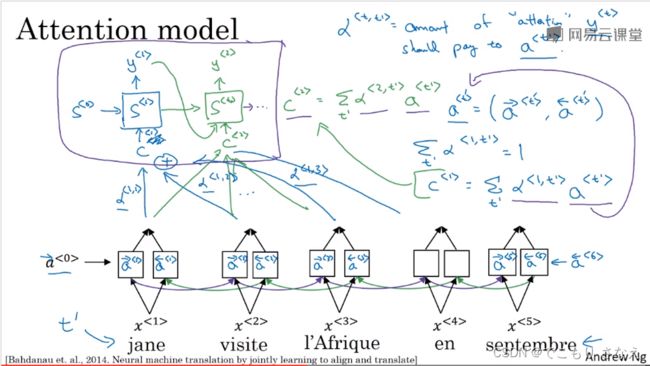
首先要说的是,注意力模型一般和 GRU 或 LSTM 联用,效果很好
然后把解码网络可以看作一个普通的生成网络,但是增加了来自编码的特征输入,这里这个输入我们简记作 ,然后简记 ![]() ,然后公式就是简单的相乘求和,如下
,然后公式就是简单的相乘求和,如下

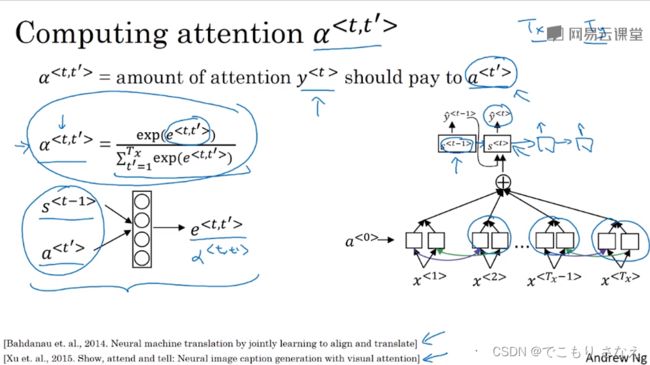
然后思考一个问题,限定 t' 范围合理吗,如果取附近几个词一定最好,那么我们也不可能费那么大力气研究记忆网络了,此外把它视作超参数调整合理吗,也许稍大一点的范围可能会好,但是所有解码单元都对应同样范围大小的编码单元这合理吗,显然不合理,另外如果每个单独都看作超参数那就更离谱了,这得调参到猴年马月呢,所以这是不合理的。不妨思考,既然我们都设了注意力权重 α 了,那毫无疑问整个编码网络每个词都分一个权重去输入给每一个解码词不就完事了,所有的每个词重不重要它自己学。
那考虑一个问题,如果权重直接设作未知数,完全随便瞎自学,那打个比方,一个例子就是,对解码网络的一个单元,来自下边的参数互相考虑彼此,相互权重比很合理,但是假设下边每个都很大,而来自左边的都很小,这合理吗,作为输入到解码中的一个的单元的一个编码词,它应当是一个词对吧,理解我的意思,打个比方,以前你输入 x1,现在比如你想输入考虑多一点的 x1+x2+x3+x4,那你真这样输入就太离谱了,肯定是输入 (x1+x2+x3+x4)/4 这种给它化作 1 倍大小的,所以怎么办,化为 1 要怎么办,这里我们是权重 α 乘以每个 a 求和,实际上就是要 α 的和为 1,回忆 softmax 单元,它是不是把概率和化作 1 了呢,那么我们就可以利用它来求权重
如图所示,我们设一个小型网络,将 ![]() 输进去,来预测其注意重要程度
输进去,来预测其注意重要程度 ![]() ,小型网络细节没有讲,然后求 α 实际上相当于小型网络后面还有一层 softmax,我觉得吴恩达是为了方便理解拆开看了,实际上就应该直接 softmax 输出 α,这样我们就将注意力权重 α 之和化为1了,公式就是如下所示(就是 softmax 的输出,可以回看以前的课程)
,小型网络细节没有讲,然后求 α 实际上相当于小型网络后面还有一层 softmax,我觉得吴恩达是为了方便理解拆开看了,实际上就应该直接 softmax 输出 α,这样我们就将注意力权重 α 之和化为1了,公式就是如下所示(就是 softmax 的输出,可以回看以前的课程)
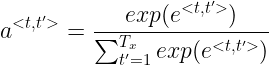
注意力模型的缺点是时间复杂度确实有点高,想象一下完全就是三层循环的一个暴搜,三次方消耗真的很大,但是翻译任务的句子一般可能不会太长,所以可以接受
然后像看图讲故事/标题之类的也可以使用这个模型

再就是日期格式的标准化,也是非常适合用注意力模型的
3.9 语音辨识
现在,振奋人心的是,seq2seq 在语音识别方面准确性有了很大的提升,最后两节课里我们将了解一下 seq2seq 模型是如何用于语音识别数据的
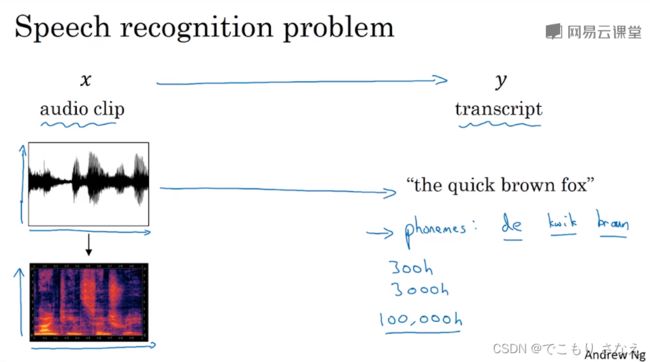 首先,需要注意的一件事是,人耳不会处理原始波形,而是通过一种特殊的物理结构来测量这些不同频率和强度的声波。换句话说,需要注意,给出这些标记数据的人类,识别、决定说出的这些话到底是什么的人类,听到的已经是人耳处理过的。所以音频数据最常见的一个预处理步骤就是运行这个原始的音频片段然后生成一个声谱图,如图所示,那个红的就是声谱图。
首先,需要注意的一件事是,人耳不会处理原始波形,而是通过一种特殊的物理结构来测量这些不同频率和强度的声波。换句话说,需要注意,给出这些标记数据的人类,识别、决定说出的这些话到底是什么的人类,听到的已经是人耳处理过的。所以音频数据最常见的一个预处理步骤就是运行这个原始的音频片段然后生成一个声谱图,如图所示,那个红的就是声谱图。
然后还需要注意的是,在第三个课程的2.10中我们也讲过,机器学习时代,常常依赖人工特征工程,语音学家们曾经把音频拆分为音位表示来作特征,而端到端学习证明了其没有意义,而且端到端也让我们现在可以不再费力设计许多人工特征工程
还要说的是,语音识别数据集合理的大小可能长达 300 小时,学术界可能 3000h 都被认为是合理大小,最好的商业系统可能已经训练超过 10000h,甚至是 100000h,并且还会继续变得更大

如何建立一个语音识别系统呢,一种方法是直接用注意力模型就行

还有一种效果也不错的方法,CTC损失函数(Connectionist temporal classification)
这里我们简单讲一下 CTC 模型的大致思想
输入音频片段是怎么看作一个序列模型呢,大概就是一个波动看作一个时间步,每秒的波动数即赫兹,比如10秒100Hz的一个音频样本,就是一个长度 1000 的音频序列
于是这就有一个什么问题呢,你的输出序列可能很短,比方说 'the quick brown fox',长度 19,然后你的 RNN 时间步可能很长,1000多这样,那当然这个用编码解码直接就能解决,这是我们讲的前面直接用注意力模型的想法,那有没有其他方法呢,这就是我们要讲的 CTC
CTC这个就很巧妙了,2006论文提出的,如图所示
它的一个基本原则是,输出下划线表示空白符,其他看作普通字符,将空白符之间重复的字符折叠起来
比如输出 ttt_h_eee___(空格)___qqq__,就是输出 'the q' 的意思
这个方法确实好用,目前许多应用场景还在沿用 CTC 这个方法,值得学习
3.10 触发字检测
关于触发词检测,在第三个课程的2.7迁移学习中曾提到过

触发词检测还处于发展阶段,这里给出了一个可用的标记数据的例子
我们可以在触发词说完后的一个RNN单元输出1,其他单元输出0
但问题是数据极度不平衡,0太多了1太少了
于是一个简单粗暴的解决方案是触发词说完后连续多输出几个时间步的1...