【大数据】常用大数据工具介绍
整理了工作中常用到的大数据工具的简单介绍。
【zookeeper】—— 分布式应用程序协调服务
ZooKeeper是一个分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它为分布式应用提供一致性服务,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home/src/recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
【原理简述】
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个 proposer 交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos做了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
ZooKeeper的基本运转流程:
- 选举Leader。
- 同步数据。
- 选举Leader过程中算法有很多,但要达到的选举标准是一致的。
- Leader要具有最高的执行ID,类似root权限。
- 集群中大多数的机器得到响应并接受选出的Leader。
【hadoop】—— 分布式文件系统(HDFS + MapReduce)
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
【优点】
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点 :
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低 。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ 。
【HBase】—— 分布式数据库
HBase(Hadoop Database)是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。
HBase是Apache的Hadoop项目的子项目。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列(columns)的而不是基于行的模式。
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现。
- 类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;
- Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;
- Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
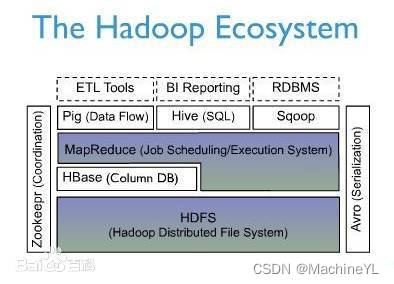
上图描述Hadoop EcoSystem中的各层系统。其中,HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
【Hive】—— 数据仓库工具
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。(很多语法和MySQL中的语法一样,有的甚至可以共用;hive还多了指定分区的功能)hive十分适合对数据仓库进行统计分析。
hive 查询语句如下:(MySQL的很像,有MtySQL基础会比较容易上手)
select t.* from (select * from user_feature_table where dt = '2021-11-01') t limit 3【Kafka】—— 分布式发布订阅消息系统
Kafka是一种高吞吐量的分布式发布订阅消息系统(Producer/Consumer),它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
【主要特性】
- Kafka 是一种高吞吐量 的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万 的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
【相关概念】
- "Broker" Kafka集群包含一个或多个服务器,这种服务器被称为broker。
- "Topic" 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- "Partition" Partition是物理上的概念,每个Topic包含一个或多个Partition.
- "Producer" 负责发布消息到Kafka broker
- "Consumer" 消息消费者,向Kafka broker读取消息的客户端。
- "Consumer Group" 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
【Spark】—— 大数据处理框架(第三代)
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和 数据源(批量数据或实时的流数据)的大数据处理的需求。
官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。
【架构及生态】
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:
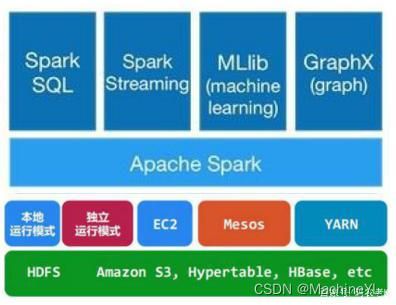
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
【Spark架构】
Spark架构的组成图如下:
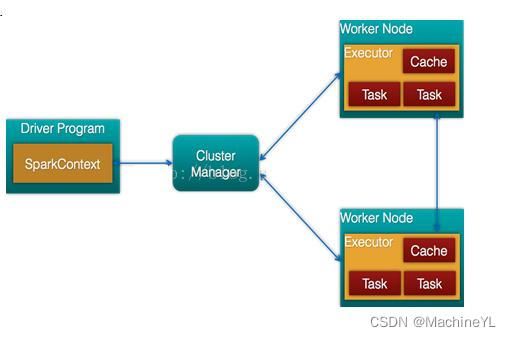
- Cluster Manager:在stand alone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
- Driver: 运行Application 的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程
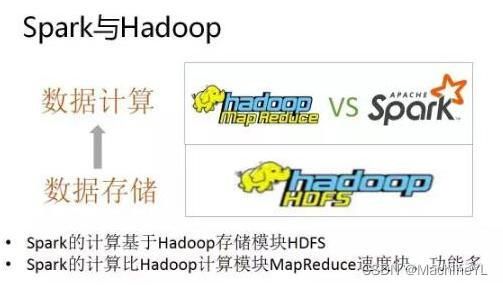
【Spark与hadoop关系】
- Hadoop有两个核心模块,分布式存储模块(HDFS) 和 分布式计算模块(MapReduce)。
- spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS。
- Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富。
关系图如下:
【Flink】—— 流式数据分布式处理引擎(第四代)
Flink是一个用于对无界和有界数据流进行有状态计算的分布式处理引擎。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。 数据可以作为无界或有界流处理:
- 无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
- 有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。