聚类分析在SPSS上的实现与结果分析——基于SPSS实验报告
实验目的
通过本次实验学习聚类分析在SPSS软件中的具体操作方法,包括系统聚类法和K-means聚类这两种方法,同时根据实验目的自己判断方法的适用情况选取最优方法完成聚类分析达到聚类的目的,并做出综合的评价。
实验步骤及过程:
题目一:依菜单选择“分析”→“分类”→“系统聚类”,然后将数据变量导入变量框中,“地区”变量导入到标注个案框中。在“图”选项中勾选系谱图,然后在“方法”中选择不同的聚类方法测试,根据实际聚类效果选择最优方案,这道题我测试得出的最优方法是 “组间距离”(类平均法)与“欧式距离”,因为原始数据量纲差异不大,不需要将数据做标准化处理。

题目二:依菜单选择“分析”→“分类”→“K-均值聚类”,然后将数据变量导入到变量框中,“国家和地区”变量导入到“个案标注依据”中;聚类数一般在2-4之间,根据实际聚类效果反复测试得出3类效果最好,所以聚类数这里输入3;在“选项”中可勾选要统计的聚类信息方便结果分析。

题目三:同时采用系统聚类和快速聚类的方法,根据实际结果的情况选择最优方案,这两种具体操作步骤见题目一和题目二。测试结果发现,K-means聚3类的方法和采用 “组间联接”、“欧式距离”的系统聚类方法结果一致,且均为最优聚类方案,所以从便捷快速的角度考虑这里选择采用K-means聚类。
实验结果分析或说明
题目一:
聚类结果如图所示

根据聚类结果的效果最终选择使用欧式距离法将31个省份分为了三类(结果保存了变量):
第一类:北京、天津、山西、内蒙古、吉林、黑龙江、上海、安徽、福建、江西、广西、重庆、贵州、云南、陕西、甘肃、新疆
第二类:河北、辽宁、江苏、浙江、山东、河南、湖北、湖南、广东、四川
第三类:海南、西藏、青海、宁夏
将分好组的三类数据求其各项指标的均值观察其特点。
| 类别 |
医疗机构床位数 |
卫生机构人员数 |
妇幼保健院 |
疾病预防控制中心 |
门诊部诊所 |
卫生院 |
医院 |
| 第一类 |
89470.24 |
141041.94 |
89.35 |
106.94 |
5713.76 |
1095.41 |
544.3 |
| 第二类 |
191388.60 |
312149.60 |
136.00 |
153.90 |
11123.20 |
2055.4 |
943.9 |
| 第三类 |
15288.25 |
25076.5 |
31 |
47.75 |
969.25 |
403.75 |
138.5 |
从图中的数据可以清楚地看出,第二类省、市、自治区的医疗卫生设备总量上处于一个较高的水平,每一项指标均为三类中的最高值,单从总量上来看相对于其他两类第二类样本的医疗卫生设配的条件最好,结合第二类中的具体省、市、自治区发现,第二类样本均为一些中东部的人口、经济大省,例如江苏、浙江、广东、湖北等省,所以其分类结果具有一定的合理性。
第一类样本的医疗设备总量处于一个中等的水平,但是观察其具体样本的数据发现,包含了北京、上海、天津等经济发达地区,观察其原始数据发现其数据总量也不是很大,并且发现四个直辖市均在第一类中,所以这里姑且考虑为医疗卫生设备的总量会受到地域大小的影响。第一类中的其他样本也大多为一些中部、西部发展较为中等的省、市、自治区,例如陕西、甘肃、贵州、云南等省,所以第一类的分类结果也有一定的合理性。
第三类相较而言其医疗设备总量处于一个较低的水平,每项指标的均值都为三类中的最低值,观察其样本数据不难发现,第三类的样本多为西部的欠发达地区,例如西藏、青海,其医疗设备总量上处于一个低水平也得以解释,其分类也较为合理。
题目二:
经过反复测试发现使用K-means聚类分3类的效果最好,聚类结果如下图所示。
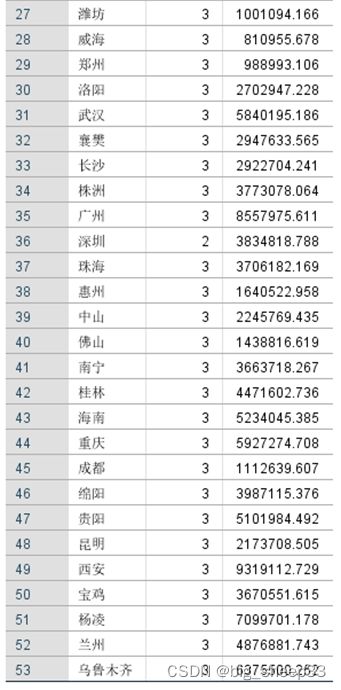
很显然,美国单独分为了第一列与其他样本差别较大,中国、日本、德国分为了第一类,其他国家和地区则是分为了第三类。

根据最终聚类中心结果得知,第二类样本对外贸易的各项指标基本都处于最高水平,联想到美国当前经济发展水平也不难理解,当今美国仍然是世界上第一大国在对外贸易方面占有着绝对的优势地位,但是其“货物贸易平衡”这一指标却又是这三类中最低水平,甚至为负值,这也许和美国实际的国情有关;
第一类大致处于一个中等片偏上的水平,中国为世界第二大经济体、日本岛国资源的稀缺、 “德国制造”的产品优势这些多多少少都是促使这三个国家成为贸易大国的因素之一,分为一类也不足为奇;
而最后一类,包含了东南亚和欧洲的一些国家,虽说不是组内水平较为平均,但相较另外两组而言这一类的样本与另两组的样本中心点差距还是过大,归为一类也较为合理。
题目三:
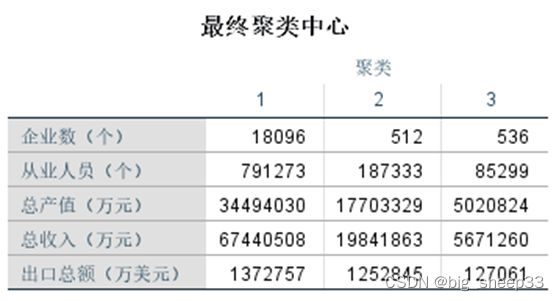
聚类结果如下图所示,北京市被单独分为了一类;上海、南京、无锡、苏州、深圳分为了第二类;而其余的省市分为了第三类。

观察各个类各项指标的聚类中心不难发现,北京之所以能单独分为一类,原因在于北京的各项指标均占据着绝对优势的地位,除了“出口总额”这个指标与第二类差距甚微外,其余的指标数值均远超其他类别,同时北京作为我国首都,在政策与历史积淀的作用下经济发展也有着绝对的优势地位;
第二类与第三类差别也存在着显著差异,除了“企业个数”这一指标和第三类差别不大外,其余的各项指标均为碾压状态,而观察样本发现,第二类的样本均为一些经济发展大市,上海和深圳两个经济特区全国前4的GDP贡献率,苏州、南京、无锡这三座城市也基本为全国GDP前十左右的存在,第二类的分类也较为合理;
第三类相较前两类略显后劲不足,考虑到第三类样本较大,样本水平参差不齐平均下来指标数值偏低,但相对于前两类而言差距均较大,分为一类也有一定的合理性。