时间序列分析ARMA模型原理及Python statsmodels实践(下)
目录
- 4. ARMA模型预测销量实践
-
- 4.1. 统计分析包statsmodels
- 4.2. 常用函数概述
-
- 4.2.1. 绘制自相关、偏自相关图
- 4.2.2. 白噪声检验
- 4.2.3. 单位根检验
-
- 4.2.3.1. 单位根如何确定数据是否平稳?
- 4.2.4. 选定模型参数
- 4.2.5. ARIMA模型函数
-
- 4.2.5.1. 常用方法
- 4.2.5.2. 常用属性/参数
- 4.3. Python实践过程
-
- 4.3.1. 时序数据平稳性检验
- 4.3.2. 差分及相关检验
- 4.3.3. 白噪声检验
-
- 4.3.3.1. 单位根ADF检验
- 4.3.3.2. Ljung-Box检验
- 4.3.4. 模型定阶
- 4.3.5. 模型训练及拟合分析
- 4.3.6. 残差分析
- 4.3.7. 模型报告与预测
- 5. 总结
-
- 5.1. 适用场景
- 5.2. 应用效果
- 5.3. 结论
续上文,时间序列分析ARMA模型原理及Python statsmodels实践(上)。
4. ARMA模型预测销量实践
-
实践概述:
以每月销售油量时序数据为分析对象,按时序数据分析方法,建立ARMA模型,预测未来油的销量。 -
实践目标:
- 时序数据检验
- ARMA建模
- 销售预测
4.1. 统计分析包statsmodels
statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化。statsmodels包含更多的“经典”频率学派统计方法,而贝叶斯方法和机器学习模型可在其他库中找到。
与scikit-learn相比,statsmodels包含经典的(高频词汇)统计学、经济学算法。它所包含的模型如下。
- 回归模型:线性回归、通用线性模型、鲁棒线性模型、线性混合效应模型等
- 方差分析(ANOVA )
- 时间序列分析:AR、ARMA、ARIMA、VAR等模型
- 非参数方法:核密度估计、核回归
- 统计模型结果可视化
statsmodels更专注于统计推理,提供不确定性评价和p值参数。相反,scikit-learn更专注于预测。能够很好的和Numpy和Pandas等库结合起来,提高工作效率。
安装statsmodels包:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple statsmodels
注,本文仅讨论普通ARMA模型,未讨论季节性ARMA,请关注后续内容。
4.2. 常用函数概述
4.2.1. 绘制自相关、偏自相关图
- statsmodels.graphics.tsa.plot_acf(),绘制时间序列的自相关图。
- statsmodels.graphics.tsa.plot_pacf(),绘制时间序列的偏自相关图。
其中,参数(x, ax=None, lags=None, alpha=0.05, use_vlines=True, unbiased=False, fft=False, title=‘Autocorrelation’, zero=True, **kwargs)
- x:一维的数据序列。
- lags:滞后阶数,若未提供,则取np.arange(len(corr))
- alpha:如果给定一个数字,则返回给定级别的置信区间。例如,如果alpha=0.05,返回95%置信区间,如果无,则不绘制置信区间。
4.2.2. 白噪声检验
对数据序列的随机性做假设检验,如果是随机序列,那它们的值之间没有任何关系,使用statsmodels.stats.diagnostic.acorr_ljungbox(x, lags=None, boxpierce=False, model_df=0, period=None,
return_df=True, auto_lag=False)函数检验白噪声。
主要输入:
- x:一维的数据序列;
- lags:滞后阶数;
- period:季节性时间序列的周期。用于计算最大滞后阶数,对于使用min(2*period,nobs//5)(如果设置)的季节性数据。如果为None,使用默认lags规则设置滞后阶数。设置后,必须大于等于2。
返回:
- lb_stat:Ljung-Box测试统计。
- pvalue:它主要返回一个基于卡方分布的p值。
原假设:是随机的序列,既是白噪声序列。计算p值,p值大,接受原假设;p值小,拒绝原假设。分割线:0.05。
0.05置信区间以下,可以认为出现显著的自回归关系,且序列为非白噪声。
4.2.3. 单位根检验
ADF检验全称是 Augmented Dickey-Fuller test,是 Dickey-Fuller检验的增广形式。DF检验只能应用于一阶情况,当序列存在高阶的滞后相关时,可以使用ADF检验,所以说ADF是对DF检验的扩展。
statsmodels.tsa.stattools.adfuller(x, maxlag=None, regression=‘c’, autolag=‘AIC’, store=False, regresults=False)
输入:
- x:1维时间序列
- maxlag:最大延迟阶数
- regression:回归中包含的常数和趋势阶数。
- ‘c’:默认,仅有常数均值
- ‘ct’ :有常数均值,有趋势
- ‘ctt’ :有常数均值有线性和二次趋势
- ‘nc’:无常数均值,无趋势。
返回值说明:
| 行号 | 返回 | 类型 | 说明 |
|---|---|---|---|
| 1 | adf | float | 测试统计值,用于和下边 1%,5%,和10%临界值比较。 |
| 2 | pvalue | float | p值,即数据不平稳的概率 |
| 3 | usedlag | int | 使用的滞后数 |
| 4 | nobs | int | 本次检测用到的观测值个数 |
| 5~7 | Critical values | dict | 1%(无截距无趋势项形式)、5%(有截距无趋势项形式)、10%(有截距有趋势项形式)标准下的临界值 |
| 8 | icbest | float | 如果自动滞后不是“无”,则为最大化信息标准 |
4.2.3.1. 单位根如何确定数据是否平稳?
有两种看法:
- 1%、%5、%10不同程度拒绝原假设的统计值【第五~第七行】和 adf【第一行】的比较,adf同时小于1%、5%、10%即说明非常好地拒绝该假设。
- P-value是否非常接近0,接近0,则是平稳的,否则,不平稳。
4.2.4. 选定模型参数
statsmodels.tsa.stattools.arma_order_select_ic(y, max_ar=4, max_ma=2, ic=‘bic’, trend=‘c’, model_kw=None, fit_kw=None)
该方法可用于初步识别ARMA的阶数过程,前提是时间序列是平稳的和可逆的。这个函数计算每个模型的完全精确MLE估计,因此有点慢。
输入:
- y:待输入的时间序列,是pandas.Series类型
- max_ar、max_ma:是p、q值的最大备选值
返回:
- order.bic_min_order返回以BIC准则确定的阶数,是一个tuple类型。
4.2.5. ARIMA模型函数
Autoregressive Integrated Moving Average (ARIMA) model。
该模型是ARIMA型模型的基本接口,包括具有外生回归因子的模型和具有季节成分的模型。模型的最一般形式是SARIMAX(p,d,q)x(p,d,q,s)。它还允许所有特殊情况,包括
- 自回归模型:AR§
- 移动平均模型:MA(q)
- 混合自回归滑动平均模型:ARMA(p,q)
- 集成模型:ARIMA(p,d,q)
- 季节模型:SARIMA(P,D,Q,s)
具有遵循上述ARIMA-type模型之一的误差的回归
4.2.5.1. 常用方法
| 方法名称 | 说明 |
|---|---|
| clone(endog[, exog]) | 使用新数据和可选的新规范克隆状态空间模型 |
| filter(params[, transformed, …]) | 卡尔曼滤波 |
| fit([start_params, transformed, …]) | 拟合(估计)模型参数 |
| fit_constrained(constraints[, start_params]) | 使用受等式约束的某些参数拟合模型 |
| initialize() | 初始化SARIMAX模型 |
| predict(params[, exog]) | 模型拟合后,预测返回拟合值。 |
4.2.5.2. 常用属性/参数
- resid. 残差
- param_names:可读的参数名称列表(用于模型中实际包含的参数)
4.3. Python实践过程
时序数据的数据源为实际工作中部分按月统计的销售数据。开发实践环境是基于python3.8环境,导入statsmodels及相关包。
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
import statsmodels.api as sm
from scipy import stats
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.api import qqplot
4.3.1. 时序数据平稳性检验
dta = pd.read_csv('citymonthvolumn202209.csv')
df = dta[['ym','volumn']].loc[略去筛选条件].sort_values(by=['ym'], ascending=True).copy()
df = df.reset_index(drop=True)
xticks = df['ym'].to_list()
del df['ym']
df = df.rename(columns={'volumn':'x'})
ax = df.plot(figsize=(12, 8))
#以每5显示
ticks = []
lables = []
for i in range(len(xticks)):
v = i%5
if v == 0:
ticks.append(i)
lables.append(xticks[i])
ax.xaxis.set_major_locator(mticker.FixedLocator(lables)) # 定位到图的x轴
ax.set_xticks(ticks)
ax.set_xticklabels(lables)
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.rcParams.update({"font.size":10.5})
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(df.values.squeeze(), lags=24, title='自相关', ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(df, lags=5, title='偏自相关', ax=ax2)
按月统计油销量图。

自相关与偏自相关图。
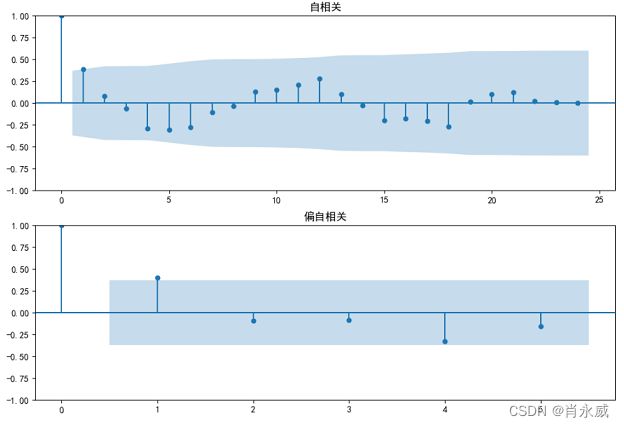
4.3.2. 差分及相关检验
# 一阶差分
diff=df.diff(1)
diff.dropna(inplace=True)
diff.plot(figsize=(12,8),marker='o',color='black') #画图
一阶差分图

一阶差分自相关与偏自相关图。

4.3.3. 白噪声检验
4.3.3.1. 单位根ADF检验
sm.tsa.adfuller(df,regression='c')
| 数据标签 | 原值 | 一阶值 | 说明 |
|---|---|---|---|
| adf | (-2.954, | (-6.077 | 原值和下边 10%临界值比较小,一阶都满足 |
| pvalue | 0.039, | 1.117e-07 | p值小于0.05,即数据是平稳的概率 |
| usedlag | 0, | 0, | 使用的滞后数 |
| nobs | 27 | 26 | 本次检测用到的观测值个数 |
| Critical values | {‘1%’: -3.670, | {‘1%’:-3.711, | |
| Critical values | ‘5%’: -2.976, | ‘5%’:-2.981, | |
| Critical values | ‘10%’: -2.628}, | ‘10%’:-2.630}, | |
| icbest | 763.205) | 724.925) | 如果自动滞后不是“无”,则为最大化信息标准 |
注:一阶差分满足单位根检验,adf值-6.077小于1%、5%、10%的值,落在置信区间,而原值只有满足10%,也就是说置信区间在90%。
4.3.3.2. Ljung-Box检验
# 使用LB检验来检验序列是否为白噪声,原假设为在延迟期数内序列之间相互独立。
from statsmodels.stats.diagnostic import acorr_ljungbox
lags = [1,2,4,8,12]
p_value = acorr_ljungbox(df, lags=lags) #lags可自定义,返回统计量和p值 lags为检验的延迟数
p_value
| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 4.637966 | 0.031272 |
| 2 | 4.839239 | 0.088955 |
| 4 | 7.909142 | 0.094964 |
| 8 | 14.755725 | 0.064073 |
| 12 | 22.947166 | 0.028178 |
对于每一个P值都小于0.05或等于0,说明该数据不是白噪声数据,数据有价值,可以继续分析。因此,只有延迟1和12有分析意义。
4.3.4. 模型定阶
在模型定阶过程中,如果时间序列的ACF和PACF不是很明确,我们可以用其他模型来定阶。其中就包括AIC和BIC信息准备判别。
这里的定阶结果都是理论给出的结果,实际中的定阶还是要根据模型表现不断调整,一般阶数越高越复杂,拟合效果越强,但过拟合概率也越高,所以要不断尝试不断调整。
import statsmodels.tsa.stattools as st
order_analyze = st.arma_order_select_ic(df, max_ar=5, max_ma=5, ic=['aic', 'bic'])
order_analyze.bic_min_order
输出结果是(1,0),可以选定AR(1)模型。
我们常用的是AIC准则,AIC鼓励数据拟合的优良性但是尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个模型。
为了控制计算量,我们限制AR最大阶不超过5,MA最大阶不超过5。 但是这样带来的坏处是可能为局部最优。
4.3.5. 模型训练及拟合分析
# 模型训练
arma_mod111 = ARIMA(df, order=(1, 0, 0)).fit()
print(arma_mod111.params)
const 2.301073e+09
ar.L1 4.252070e-01
sigma2 1.327135e+17
# 拟合情况
predictions_ARIMA = arma_mod111.fittedvalues
df['y'] = predictions_ARIMA
ax = df.plot(figsize=(12, 8))
#以每5显示
ticks = []
lables = []
for i in range(len(xticks)):
v = i%5
if v == 0:
ticks.append(i)
lables.append(xticks[i])
ax.xaxis.set_major_locator(mticker.FixedLocator(lables)) # 定位到图的x轴
ax.set_xticks(ticks)
ax.set_xticklabels(lables)
4.3.6. 残差分析
## 查看模型的拟合残差分布
fig = plt.figure(figsize=(12,5))
ax = fig.add_subplot(1,2,1)
plt.plot(arma_mod111.resid)
plt.title("ARMA(1,0)残差曲线")
## 检查残差是否符合正太分布
ax = fig.add_subplot(1,2,2)
sm.qqplot(arma_mod111.resid, line='q', ax=ax)
plt.title("ARMA(1,0)残差Q-Q图")
plt.tight_layout()
plt.show()

4.3.7. 模型报告与预测
print(arma_mod111.summary()) #给出一份模型报告
print(arma_mod111.forecast(12)) #作为期12个月的预测,返回预测结果、标准误差、置信区间。

预测结果:

5. 总结
5.1. 适用场景
ARMA可谓是时间序列最为经典常用的预测方法,广泛应有于涉及时间序列的各个领域。特别是时间序列预测的应用在经济领域,例如文中参考的资料,北京大学数学科学学院金融数学系金融数学应用硕士《金融时间序列分析》,在经济量化分析中被广泛使用。
ARMA在市场研究中常用于长期追踪资料的研究,如:Panel研究中,用于消费行为模式变迁研究;在零售研究中,用于具有季节变动特征的销售量、市场规模的预测等[百度]。
5.2. 应用效果
从结果来看,当数据波动不大时,用ARIMA模型比LSTM要更好。而当数据变化比较大时,ARIMA的预测效果就不如LSTM了。
个人理解ARIMA原理时滑动平均和自回归,所以预测的结果都和历史的平均值比较接近,当真实值波动不是很剧烈是,用ARIMA预测可能更适用。
而神经网络LSTM由于对于过往数据都会存到‘记忆神经’,也就是遗忘门,输入门,输出门中。也就不是只简单看一个平均,所以预测可能会激进偏颇一点,但是对于原始数据波动比较大时,可能效果更好。
简单的结论就是:原始数据波动不大(例如稳定股票每天价格,汇率等),建议用ARIMA模型。原始数据波动较大(例如每天成交额,购买额),建议用神经网络预测效果更好。[21]
5.3. 结论
本文通过一段时间的销售数据集来实战演示ARIMA模型的理论、建模及调参选择过程,其中包括时序数据的随机性、稳定性检验,综合ARMA模型表现的不理想,考虑到销售的季节性,后续将实践季节ARMA模型。本文旨在通过实践的操作过程,完成ARIMA模型的分享,相信大家也会通过此文而有所收获,欢迎讨论反馈。
参考:
[1]. 阿丢是丢心心. 【Python数据分析】时间序列分析——AR/MA/ARMA/ARIMA. CSDN博客. 2022.02
[2]. Autoregressive Moving Average (ARMA): Sunspots data
[3]. 数据分析-中志. 一文搞懂时间序列预测模型(2):ARIMA模型的理论与实践. CSDN博客. 2022.03
[4]. geek精神. Python时间序列数据分析–以示例说明. 博客园. 2017.05
[5]. 李东风. 金融时间序列分析讲义. 北京大学数学科学学院. 2022
[6]. 酒酿小圆子~. 利用ARIMA模型进行时间序列分析(Python_Statsmodels包). CSDN博客. 2020.06
[7]. 灯下鼠. 理解 AR 和 MA 模型. 简书. 2022.05
[8]. TUJC. Arima相关概念. CSDN博客. 2019.03
[9]. 大象咖啡. 时间序列学习(5):ARMA模型定阶(AIC、BIC准则、Ljung-Box检验). CSDN博客. 2021.09
[10]. Avasla. 模型评估方法【附python代码】(信息准则:赤池信息量准则AIC、贝叶斯信息准则BIC). CSDN博客. 2022.05
[11]. 心诣. Python ARMA模型. 知乎. 2022.09
[12]. 爱雅. ARMA模型时间序列分析全流程(附python代码). 知乎. 2022.07
[13]. CCC考研. 《利用Python进行数据分析》13.3statsmodels介绍. 简书. 2018.12
[14]. 天海一直在. 机器学习——时间序列ARIMA模型(四):自相关函数ACF和偏自相关函数PACF用于判断ARIMA模型中p、q参数取值.CSDN博客. 2022.05
[15]. 李东风. 应用时间序列分析备课笔记. 北京大学数学科学学院…2021.11
[16]. 米米吉吉. 时间序列之单位根检验(1). CSDN博客. 2020.11
[17]. pingzishinee. 白噪声检验. CSDN博客. 2020.09
[18]. KaneBurger. python数据分析之时间序列分析详情. 脚本之家. 2022.08
[19]. 时光之笛. ARIMA模型的定阶原理与建模分析. 知乎. 2022.08.
[20]. lbship. 数据分析之利用ARMA算法对销售进行预测. CSDN博客. 2019.03
[21]. herain. ARIMA时间序列与LSTM神经网络的对比. 知乎. 2022.01