使用MindStudio进行语义分割应用开发
- 介绍
1、 MindStudio
MindStudio是一款专为AI开发设计的代码编辑器。旨在提供满足AI开发全过程所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。本篇文章针对应用开发这一任务,分享使用经验。
2、 模型和任务介绍
我在本次开发中使用的模型为AttU_Net。该模型使用了PyTorch框架,用于图片的语义分割。模型原作者提出了一种新的结构——注意力门(attention gate,AG)。AttU_Net会自动学习区分目标的外形和尺寸。这种有attention gate的模型在训练时会学会抑制不相关的区域,注重有用的显著特征。就像人类的视觉运作的方式一样,只会把注意力放在关键的部分,attention gate模拟了这一机制,也会给模型带来类似于人类注意力机制的能力,让模型拥有自动寻找图片中重要的位置的能力,并着重分析这一部分。
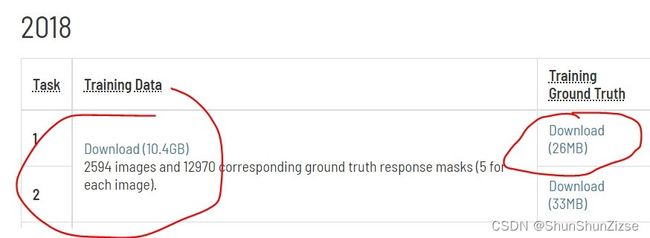
在本实例中,使用的数据集为ISIC 2018 Task 1的数据,包括2594张显微镜下拍摄的医学图片以及对应的分割结果。我这里下载的是Task 1的training data和training ground truth,也就是在下面的图片中圈出来的两个。想要使用相同数据集的话可以自行到数据集名称关联的超链接中进行下载。
本次应用开发基于MindX SDK进行,关于MindX SDK的更多详细信息可以在昇腾官方发布的MindStudio文档的“基于MindX SDK开发应用”章节中查看。
二、 环境搭建
1、 MindStudio下载和安装
MindStudio下载连接如下:
MindStudio下载-昇腾社区 (hiascend.com)
进入页面后可以看到MindStudio的基本信息和版本介绍,往下翻可以就看到Linux系统和Windows系统的安装包,以及Windows系统下的免安装压缩包。可以根据自己的需要进行下载和安装。安装过程比较简单,同意服务协议、确认安装位置之后,等待安装完成即可。
2、 CANN下载和安装
CANN (Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。CANN包含的几个部分如下图所示。使用MindStudio开发的过程需要使用CANN。

CANN安装,可以参考下面的连接,按照官方文档给出的步骤进行下载和安装。
软件安装-环境准备-5.1.RC1-CANN商用版-文档首页-昇腾社区 (hiascend.com)
下面详细展示一下在MindStudio中配置CANN的过程。
首先需要配置SSH连接到远程服务器。在Settings中找到SSH Configurations,位置如下图所示,在Tools菜单下。 如果是第一次使用MindStudio,可以在初始窗口左侧边栏中点击Customize,然后在出现的界面中点击最下方的All Settings。项目界面中可以在左上角图标旁边的File菜单中找到Settings,和PyCharm、CLion等编辑器相同。

填写好对应信息后,点击上图中圈出的Test Connection按钮,检查连接是否成功。看到下面的小窗口在屏幕中间弹出则表示连接成功。如果提示连接失败,请检查服务器状态、网络是否正常、信息填写是否准确无误等关键部分。

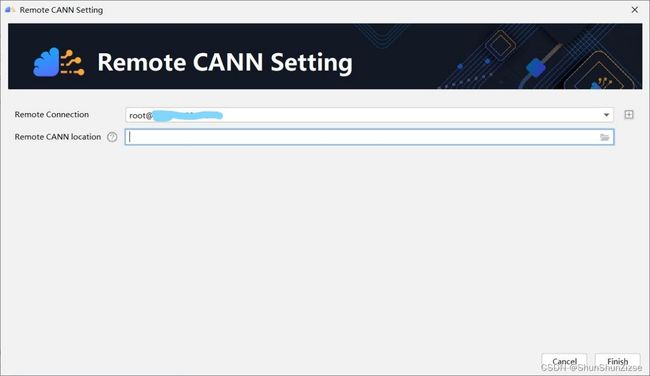
接下来是CANN的设置。找到Settings -> Appearance & Behavior -> System Settings -> CANN。进入CANN管理界面。点击右上角的文件夹Change CANN按钮。如果尚未完成CANN安装,按钮上的文字会显示为Install CANN,点击它。进入CANN设置界面。

在这里需要填写远程服务器地址。并选择CANN所在位置。
点击服务器地址栏右边的小加号,会弹出SSH Configuration的窗口。如下图。可以进行连接测试。

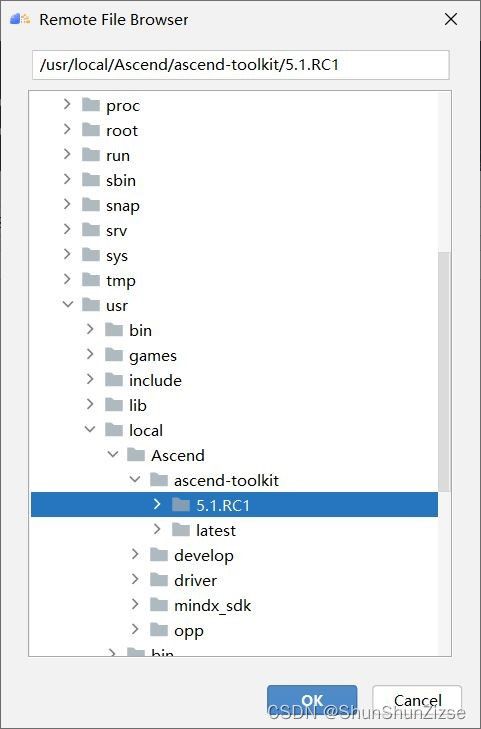
填写完服务器地址后,点击Remote CANN Location一栏,选择CANN位置。下图中展示了服务器中需要选择的文件夹。注意需要选到特定的版本。这里选择了5.1.RC1,也可以选择latest。
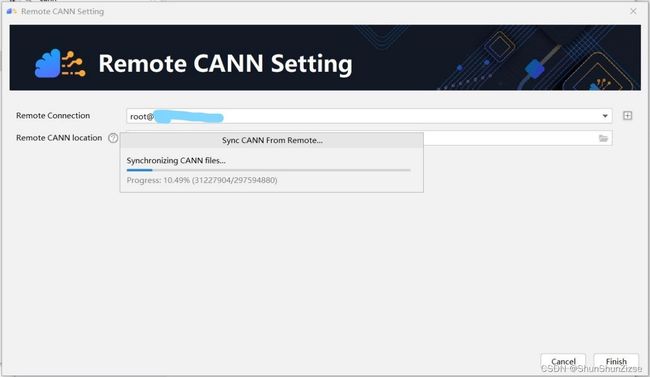
选好后点击CANN设置界面右下角的Finish按钮,开始同步CANN文件,需要稍等一会。
同步完成后返回Settings页,会提示需要重启MindStudio来激活CANN。点击OK,等待MindStudio重启。

重启后即可看到安装完成的CANN。

3、 MindX SDK安装
下面来展示本次应用开发中用到的MindX SDK的安装过程。
同样在设置Settings中,进入Appearance & Behavior -> System Settings -> MindX SDK,来到MindX SDK管理界面。下图展示的是MindX SDK已经安装完成的状态。界面中“MindX SDK Location”为软件包的默认安装路径,默认安装路径为“C:\Users\用户名\Ascend\mindx_sdk”。 单击“Install SDK”进入MindX SDK管理界面。

在这里需要填写远程服务器地址,等关键信息。

在选择SDK位置时,需要注意要选到linux-x86-64文件夹下的mxVision-3.0.RC1。路径中有一个父文件夹名字和它相同。如果选择错了,运行时会遇到问题。

完成信息填写后点击右下角的OK按钮,MindStudio开始自动同步SDK文件。需要等待一会。

完成同步后会回到MindX SDK管理页面。表格中的Operation一栏下,两个图标从左至右分别为删除和激活按钮。Activation一栏中,显示的SDK状态,可以看到现在我们的SDK状态为已激活,可以正常使用。MindX SDK安装完成。

过程中遇到任何困难,或者想要了解更多信息,可以前往昇腾社区的官方文档中查阅相关信息。
安装MindX SDK软件包-基于MindX SDK开发应用-应用开发-用户指南-5.0.RC1-MindStudio-文档首页-昇腾社区 (hiascend.com)
三、 应用开发
1、 模型代码下载
AttU_Net模型的代码可以在昇腾社区和Gitee仓库中下载。两边的代码相同,推荐在昇腾社区中下载,不需要克隆仓库,直接以压缩包形式获取这一代码以及模型,更加方便一点。Gitee仓库中需要自己运行对应的代码生成onnx模型。

AttU-NET-昇腾社区 (hiascend.com)

PyTorch/built-in/cv/semantic_segmentation/AttU_Net_for_PyTorch · Ascend/ModelZoo-PyTorch - 码云 - 开源中国 (gitee.com)
拿到模型代码后,稍作修改就可以在MindStudio中运行。由于训练、测试和验证数据集是随机划分的,因此存在数据集对应的问题。如果模型在训练时使用的数据集划分和验证精度时不同,会出现使用训练数据验证精度的问题,精度虚高。因此,我在这里打包了一份在同一数据集划分下的,模型文件以及处理后的用于验证精度的数据文件,可以在网盘连接中自取。如果只是学习MindStudio的使用方法或只需打通功能,对精度没有要求,那么这个问题可以忽略。
链接:百度网盘 请输入提取码
提取码:1111
2、 项目创建
准备好模型和代码后,我们来创建项目。
进入New Project页面。我们需要创建的时Ascend App,选择左侧边栏中的第三个。Name栏可以填写项目名称。可以按需要在Decription栏中填写项目描述。CANN Version自动填充。Project Location一栏可以选择存放项目的位置,根据自己的情况选择。
整体流程和PyCharm等编辑器相似,用起来还是非常顺手的,不会有特别疑惑的地方。

接下来选择项目类型。我们这里需要创建一个空白的,使用Python的MindX SDK项目。因此选择用红色圈起来的这个选项。它左边的选项是使用C语言或C++语言的MindX SDK项目。
这两个项目下面的两个,分别是两种语言的模板项目。里面包含不同类型的多个模型,完整展示了MindStudio开发过程的所有代码。如有需要可以创建项目进行学习。可以参考官方文档中的教程“SDK样例工程使用指导“章节,进行详细地自主学习:
SDK样例工程使用指导-基于MindX SDK开发应用-应用开发-用户指南-5.0.RC1-MindStudio-文档首页-昇腾社区 (hiascend.com)

创建好的空白Python MindX SDK项目如下图所示。需要配置一下Python。点击黄色警示框最右边的连接进入设置界面,根据需要的版本,选择自己电脑中平常使用的Python环境就可以了。
AttU_Net模型代码是使用Python 3.7编写的。但在本次应用开发中不需要运行原始的模型代码。AttU_Net中涉及MindX SDK部分的代码可以在Python 3.9的环境下运行。如果代码需要特定版本的Python,请根据特定的要求安装,安装完成后在MindStudio中按照在Pycharm中配置的方式进行配置就好了。
3、模型转换
MindStudio中,可以对onnx和om模型文件进行可视化的展示。
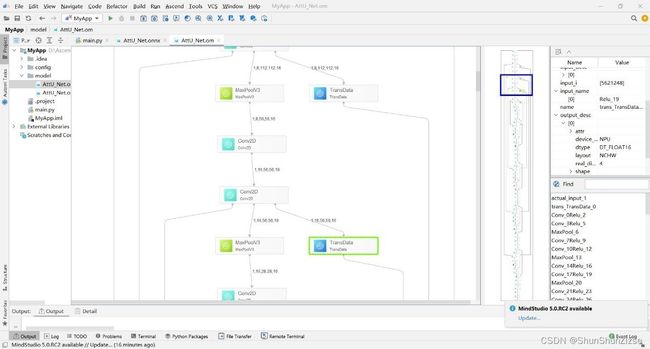

上面两张图片分别是om模型和onnx模型可视化得到的结果。主窗口中看到的是细节结构。右边紧挨着的是模型略缩图,而且展示了主窗口所展示的部分模型所处的位置。还可以选择模型中的节点,查看详细信息。点选节点后,像信息在最右侧的边栏中展示。
使用MindStudio可以方便地将onnx模型转换成om模型。
我们在项目中新建一个models文件夹,将下载下来的onnx模型放入该文件夹中。模型位置任意,这里放入models文件夹是为了让项目结构更加清晰。
下载下来的onnx模型是模型代码中通过PyTorch中的方法生成的。将训练后的模型以onnx格式保存了下来。
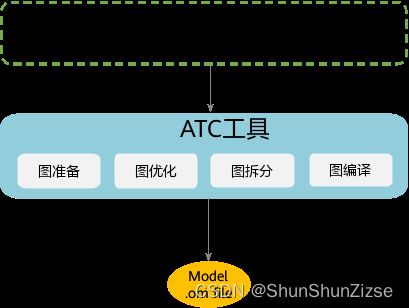
后续的MindX SDK开发需要om格式的模型。这里会使用到模型转换工具ATC。下图展示了模型转换工具ATC的功能和它所支持的源模型类型。用户使用Caffe/TensorFlow/PyTorch等框架训练好的模型,可通过ATC工具将其转换为昇腾AI处理器支持的离线模型,模型转换过程中可以实现算子调度的优化、权重数据重排、内存使用优化等,可以脱离设备完成模型的预处理。
关于ATC的详细讲解和功能使用说明、约束说明可以参考官方文档“模型转换章节:使用前必读-模型转换-用户指南-5.0.RC1-MindStudio-文档首页-昇腾社区 (hiascend.com)
下面展示模型转换的过程。
首先选择上方菜单栏中的Ascend菜单,选择Model Convertor。如图所示。
点击后弹出模型转换器参数窗口。第一项CANN Machine自动填写服务器地址。Model File一栏中,需要给出待转换的源模型路径。

点击右边的文件夹图标,看到下图这样的窗口弹出。我们的模型在本地,所以首先需要选择local path这个选项。然后再点击右边的文件夹按钮,选择到刚才放入models文件夹的onnx模型。点击下方OK按钮。
回到模型转换器窗口之后,MindStudio会开始解析模型。稍等一会。
Model Name会根据模型文件解析结果自动填充,也可以根据需要进行修改。转换后的模型文件会在这里的文件名后面增加“.om”后缀。
Target SoC Version是模型转换时指定芯片型号。需要根据板端环境具体芯片形态进行选择。我们这里选择默认的Ascend310。
Output Path启用后可以自定义模型输出位置。不开启的话模型会输入到一个默认位置。不用担心找不到,转换完成后可以看到这个路径。
Input Format根据输入模型的类型选用。我们的模型为onnx类型,需要选择NCHW。

上图中,下面的Shape属性是根据模型文件自动解析的,这里不需要修改。后面的Type属性为数据类型。根据读取数据时的存储格式选择。不匹配的话会在后续运行中报错,像下面这张图中展示的这样。
这里报错的原因是我把Type选择成FP16了,但是实际读取数据的时候,使用了FP32进行存储,并以FP32的格式传递给了模型。报错信息很长,需要将滚动条拉到最右边才可以看到这部分报错内容。所以Type这里一定要和需要的数据类型相匹配。

关于这个窗口中所有属性的含义,以及不同情况下应该如何填写的信息可以在模型转换-模型转换-用户指南-5.0.RC1-MindStudio-文档首页-昇腾社区 (hiascend.com)这个页面里面的“表1 Model Information界面参数配置”中查阅。
模型转换完成后可以卡到如下图所示的输出。绿色文字提示转换成功。在橙色方框圈出来的这行中可以看到文件输出路径。在这里可以找到拷贝到本地的om模型。同样将它放到models文件夹下。

4、 流程编排
MindX SDK实现功能的最小粒度是插件,每一个插件实现特定的功能,如图片解码、图片缩放等。将这些插件按照合理的顺序编排,实现相应的功能。可视化流程编排是以可视化的方式,开发数据流图,生成pipeline文件供应用框架使用。
已有插件可以在mxManufacture用户指南-制造业视觉质检-3.0.RC1-MindX SDK-文档首页-昇腾社区 (hiascend.com)和mxVision 用户指南-智能视频分析-3.0.RC1-MindX SDK-文档首页-昇腾社区 (hiascend.com)中的“已有插件介绍”章节中查找和查看功能。
如果已有的插件不能满足所需功能,可以参考插件开发-基于MindX SDK开发应用-应用开发-用户指南-5.0.RC1-MindStudio-文档首页-昇腾社区 (hiascend.com)自行开发插件。
在所下载的代码中,可以看到在infer -> data -> config目录下,有一个以.pipeline结尾的文件。这就是AttU_Net写好的流程编排文件。在项目中新建文件夹pipeline,将它复制到该文件夹下。这个文件稍作修改就可以直接使用。

MindStudio中,可以进行可视化的流程编排。我们来了解和学习一下这个功能。如下图,选择顶部菜单栏中的Ascend,载选择倒数第四个MindX SDK Pipeline,进入流程编排页面。

首先会创建一个空白的new.pipeline文件。圈出来的部分可以切换可视化编排和文字形式编排两种开发方式。

在Pipeline Stream Editor这个菜单中,可以按名称或分类查找需要的插件。找到后点击并拖拽到右边的画布上,就成功地添加了这个插件。
编排插件执行顺序只需要将两个插件连接起来。
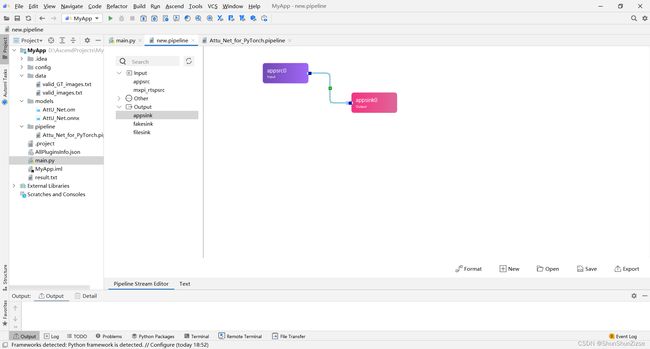
点击插件后可以在右边的边框中查看插件属性。对于需要配置模型位置的插件,可以在这里可视化地选择。
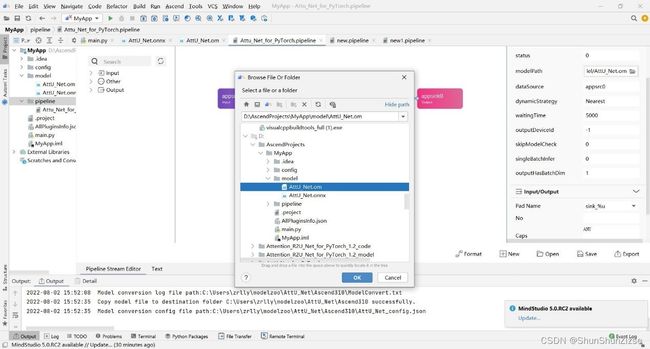
新生成的这个new.pipeline只是临时文件,在项目结构中是看不到的。点击右边栏下方的save按钮,进行保存后才会真正出现在项目内。
我们这里直接使用下载的模型中写好的流程编排文件。需要修改文件中的模型路径。注意这里的路径需要填写om模型文件相对于main.py的位置。
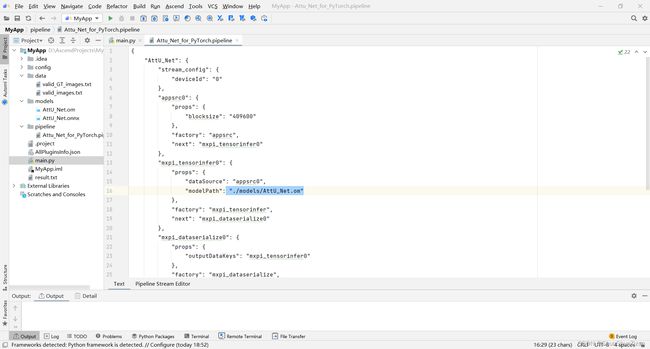
上图中stream的名称和输入插件名称、推理插件名称是下面的main.py文件中需要对应的填写的名字。下一节中会进行相应的解释。
5、 main.py的编写及项目运行
下载的模型文件中,infer -> sdk文件夹下有一个main.py文件,直接将代码内容拷贝过来。会有找不到包和方法的标红,没有关系,不用处理。标红的是本地没有的包和方法,但是在服务器上是可以找到的。
需要修改数据集文件路径和pipeline文件路径。

这里的数据文件存放在data文件夹下。数据处理采用了批量处理的方式。可以在下载的代码中的infer -> util文件夹下找到data_process.py文件,这个文件就是将ISIC 2018数据集中的图片转换成这里看到的txt文件的代码。文件数据在上文的百度网盘链接中可以获取。也可以使用下载的代码自行转换。当然页可以不使用这种批量处理的方式。只有一张图片也是可以进行语义分割的。
数据处理的步骤包括裁剪成224*224大小,和以0.5为均值和方差的数据归一化,以及保留六位小数这三个步骤。如需自行处理图片,可以参考data_process.py中的代码,进行这三个步骤,并将数据以需要的格式输出。
接下来的步骤是根据流程编排创建stream进行计算。需要按照下面的代码所展示的形式对参数进行设置。绿色的b开头的字符串后面跟的appsrc0、mxpi_tensorinfer0是流程编排中对应插件的名字,AttU_Net是流程编排文件中的stream名。可以在pipeline文件中相应的看到。

另外还有一处需要进行说明,那就是结果的输出方式和精度验证。这里采用的是批量输出为txt文件的形式。在下图中圈出的部分可以修改文件名。当然也可以采用其他方式。
在下载的代码中,infer -> util目录下,可以看到两个名字中带有evaluation的文件。这两个文件就是用于计算结果精度的。可以拿过来,在result_evaluation中设置好结果路径和valid_GT_images.txt路径后,直接调用计算精度。infer_evaluation文件中,有编写好的用于计算各种指标的函数,也可以利用这两个文件中写好的基本方法,按自己的需要编写验证模型效果的代码。当然也可以将效果验证融合在main.py中,得到结果后继续计算精度、F1等关键指标并输出。
AttU_Net模型的精度正常情况下在0.96左右。如果有使用训练集验证精度的情况,会导致精度过高,有可能达到0.98多。
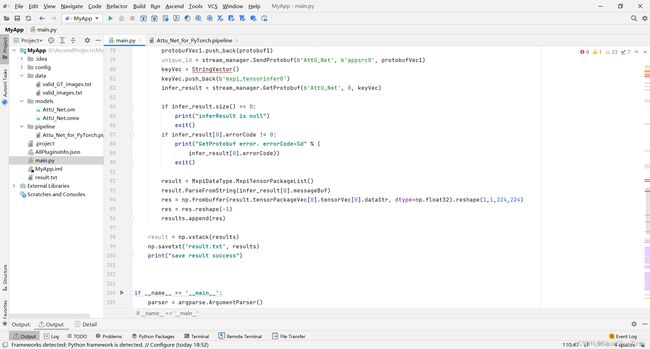
接下来就可以运行了。需要进行配置。Deployment会自动填写远端服务器地址。Executable栏需要选择刚刚编写好的main文件,点击OK。

点击左上部分的绿色运行按钮,开始运行。等待一会,就可以得到运行结果。
截图中是运行完成的状态,可以看到result.txt文件。

四、 总结
MindStudio使用下来,给我的感受是,它确实一款非常实用的AI开发工具。功能全面、强大,且支持多种编程语言,无需太多本地计算。可能是因为还比较新颖,而且功能很多,现在还没有非常普及。相信金子总会发光,随着时间的推移,会有越来越多的AI开发者发现它的实用性。
在华为云上可以找到MindStudio的专属论坛。链接放在这里MindStudio_昇腾_开发者论坛-华为云论坛 (huaweicloud.com),开发过程中遇到任何问题,都可以在上面提出和讨论,也可以查一查有没有同志遇到过相同问题,说不定已经有了解决方法。也可以在上面做开发经验分享,帮助其他开发者解决遇到的问题。欢迎大家来论坛上交流经验。