如何在AI工程实践中选择合适的算法?
在使用深度强化学习(Deep Reinforcement Learning,DRL)算法解决实际问题的过程中,明确任务需求并初步完成问题定义后,就可以为相关任务选择合适的DRL算法了。
以DeepMind的里程碑工作AlphaGo为起点,每年各大顶级会议DRL方向的论文层出不穷,新的DRL算法如雨后春笋般不断涌现,大有“乱花渐欲迷人眼”之势。
然而,落地工作中的算法选择并不等同于在这个急剧膨胀的“工具箱”中做大海捞针式的一对一匹配,而是需要根据任务自身的特点从DRL算法本源出发进行由浅入深、粗中有细的筛选和迭代。
在介绍具体方法之前,笔者先尝试按照自己的理解梳理近年来DRL领域的发展脉络。
1
DRL算法的发展脉络
尽管DRL算法已经取得了长足进步,但笔者认为其尚未在理论层面取得质的突破,而只是在传统强化学习理论基础上引入深度神经网络,并做了一系列适配和增量式改进工作。
总体上,DRL沿着Model-Based和Model-Free两大分支发展。
前者利用已知环境模型或者对未知环境模型进行显式建模,并与前向搜索(Look Ahead Search)和轨迹优化(Trajectory Optimization)等规划算法结合达到提升数据效率的目的。
作为当前学术界的研究热点,Model-Based DRL尚未在实践中得到广泛应用,这是由于现实任务的环境模型通常十分复杂,导致模型学习的难度很高,并且建模误差也会对策略造成负面影响。
在笔者看来,任何Model-Free DRL算法都可以解构为“基本原理—探索方式—样本管理—梯度计算”的四元核心组件。
其中按照基本原理,Model-Free DRL又存在两种不同的划分体系,即Value-Based和Policy-Based,以及Off-Policy和On-Policy。
如图1所示,DQN、DDPG和A3C作为这两种彼此交织的划分体系下的经典算法框架,构成了DRL研究中的重要节点,后续提出的大部分新算法基本都是立足于这三种框架,针对其核心组件所进行的迭代优化或者拆分重组。
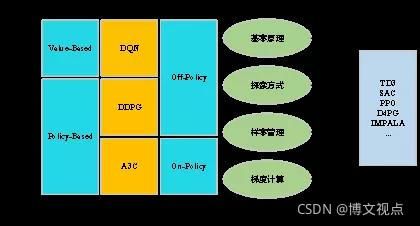
图1 Model-Free DRL的发展脉络和四元核心组件解构方法
图1中几个关键术语的解释是:
Off-Policy指算法中采样策略与待优化策略不同;
On-Policy指采样策略与待优化策略相同或差异很小;
Value-Based指算法直接学习状态-动作组合的值估计,没有独立策略;
Policy-Based指算法具有独立策略,同时具备独立策略和值估计函数的算法又被称为Actor-Critic算法。
关于上述Model-Free DRL算法的四元核心组件,其中:
基本原理层面依然进展缓慢,但却是DRL算法将来大规模推广的关键所在;
探索方式的改进使DRL算法更充分地探索环境,以及更好地平衡探索和利用,从而有机会学到更好的策略;
样本管理的改进有助于提升DRL算法的样本效率,从而加快收敛速度,提高算法实用性;
梯度计算的改进致力于使每一次梯度更新都更稳定、无偏和高效。
总体而言,DRL算法正朝着通用化和高效化的方向发展,期待未来会出现某种“超级算法”,能够广泛适用于各种类型的任务,并在绝大多数任务中具有压倒式的性能优势,同时具备优秀的样本效率,从而使算法选择不再是问题。
2
一筛、二比、三改良
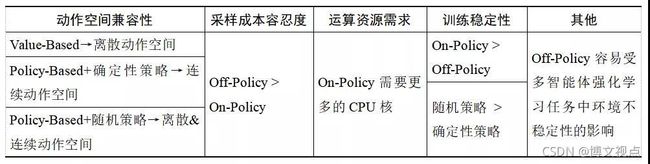
从一个较粗的尺度上看,依据问题定义、动作空间类型、采样成本和可用运算资源等因素的不同,的确存在一些关于不同类型DRL算法适用性方面的明确结论。
例如,Value-Based算法DQN及其变体一般只适用于离散动作空间;相反,采用确定性策略的Policy-Based算法DDPG及其变体只适合连续动作空间;而A3C和SAC等采用随机策略的Policy-Based算法则支持离散和连续两种动作空间;此外,随机策略通常比确定性策略具有更好的训练稳定性(如图2所示)。
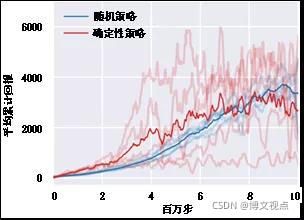
图2 随机策略相比确定性策略的稳定性优势
在MuJoCo-Humanoid控制任务中,分别采用随机策略和确定性策略的两种SAC算法变体在不同随机种子下多次训练的曲线显示,随机策略比确定性策略对随机因素的影响更加鲁棒,因此具有更好的训练稳定性。
对于机器人等涉及硬件的应用,或者其他采样成本较高的任务,能够重复利用历史数据的Off-Policy算法相比On-Policy算法更有优势。
在多智能体强化学习任务中,多个交互的Agent互相构成对方环境的一部分,并随着各自策略的迭代导致这些环境模型发生变化,从而导致基于这些模型构建的知识和技能失效,学术界将上述现象称为环境不稳定性(Environment Nonstationarity)。
由于该问题的存在,除非Replay Buffer(经验回放缓存)中的数据更新足够快,否则重复使用历史数据的Off-Policy算法反而可能引入偏差。
由于利用贝尔曼公式Bootstrap特性的值迭代方法是有偏的(Biased),On-Policy算法在训练稳定性方面一般好于Off-Policy算法。
然而,为了尽可能获取关于值函数的无偏估计,On-Policy算法往往需要利用多个环境并行采集足够多的样本,这就要求训练平台具有较多的CPU核,而Off-Policy算法则没有这种要求,尽管后者也能够从并行采样中受益。
表1总结了Model-Free DRL算法适用性的一般性结论。
表1 Model-Free DRL算法适用性的一般性结论
在完成“粗筛”之后,对于符合条件的不同DRL算法之间的取舍变得微妙起来。
一般而言,学术界提出的新算法,尤其是所谓SOTA(State of the Art,当前最佳)算法,性能通常优于旧算法。
但这种优劣关系在具体任务上并不绝对,目前尚不存在“赢者通吃”的DRL算法,因此需要根据实际表现从若干备选算法中找出性能最好的那个。
此外,只有部分经过精细定义的实际任务可以通过直接应用标准算法得到较好解决,而许多任务由于自身的复杂性和特殊性,需要针对标准算法的核心组件进行不同程度的优化后才能得到较为理想的结果,这一点可以在许多有代表性的DRL算法落地工作中找到踪迹。
注意这里所说的优化未必是学术级创新,更多时候是基于对当前性能瓶颈成因的深入分析,在学术界现有的组件改良措施和思想中“对症”选择,是完全有迹可循的。
例如,为了改善DQN的探索,可以用噪声网络(Noisy Net)代替默认的图片-greedy;为了提升其样本效率,可以将常规经验回放改为优先级经验回放(Prioritized Experience Replay,PER);为了提高其训练稳定性,可以在计算目标值时由单步Bootstrap改为多步Bootstrap等。
在《深度强化学习落地指南》一书的5.2节和5.3节中介绍具体的DRL算法时,会专门列出针对相关算法的可用组件优化措施供读者参考。
3
从独当一面到众星捧月
需要强调的是,算法在学术研究和落地应用中与诸如动作空间、状态空间、回报函数等强化学习核心要素的关系是不同的。
具体可以概括为:学术研究为了突出算法的优势,其他要素只需要保持一致甚至被刻意弱化;落地应用为了充分发挥算法的性能,其他要素应该主动迎合算法需求以降低其学习难度。
可以说一边是独当一面,另一边是众星捧月,这种角色上的差异是由学术研究和落地应用各自不同的出发点决定的。
学术研究的目标是在普遍意义上解决或改善DRL算法存在的固有缺陷,如低样本效率、对超参数敏感等问题,因此算法自身特质的优劣处于核心地位。
为了保证不同算法之间进行公平的比较,OpenAI Gym、Rllab等开放平台为各种任务预设了固定的状态空间、动作空间和回报函数,研究者通常只需要专心改进算法,而很少需要主动修改这些要素,即使修改也往往是为了刻意提升任务难度,从而突出算法在某些方面的优点,比如将回报函数变得更稀疏,简化状态空间设计使其只包含低效的原始信息等。
与学术研究不同,落地应用的目标是在特定任务上获得最佳策略性能,而算法仅仅是实现该目标的众多环节之一。
一方面,在学术研究中依靠算法改进做到的事情,在实际应用中可以通过状态空间、动作空间和回报函数的协同优化达到相同甚至更好的效果。
另一方面,在学术研究中被认为应当尽量避免的超参数精细调节和各种难以标准化、透明化的训练技巧,在落地应用中成为必要工作。
总之,落地应用中的策略性能优化是一项系统工程,需要“不择手段”地充分调动包括算法在内的各种有利因素。
▼
本文摘自《深度强化学习落地指南》一书,欢迎阅读此书了解更多关于深度强化学习落地的内容。

▊《深度强化学习落地指南》
魏宁 著
一本讨论强化学习落地应用的技术书
本书从工业界一线算法工作者的视角,对深度强化学习落地实践中的工程经验和相关方法论做出了深度思考和系统归纳。
本书跳出了原理介绍加应用案例的传统叙述模式,转而在横向上对深度强化学习落地过程中的核心环节进行了完整复盘。主要内容包括需求分析和算法选择的方法,动作空间、状态空间和回报函数设计的理念,训练调试和性能冲刺的技巧等。
本书既是前人智慧与作者个人经验的交叉印证和精心整合,又构成了从理论到实践再到统一方法论的认知闭环,与市面上侧重于算法原理和代码实现的强化学习书籍形成了完美互补。。

(京东满100减50,快快扫码抢购吧!)