【实例分割】基于PaddleDetection的MaskRCNN对自己数据集进行检测
简介
最近项目需要用到实例分割,起初以为飞浆将模型放在PaddleSeg里,其实归类到目标检测的工具包**PaddleDetection**。
本文主要流程:
- labelme标记的如何自己数据、以及配置
- PaddleDetection安装与测试
- labelme实例分割数据转化PaddleDetection训练所支持的coco格式
- 修改配置文件开始训练
第一步:labelme标记分割数据集
- 官方源: https://github.com/wkentaro/labelme
- 国内源下载与安装:https://gitee.com/monkeycc/labelme
启动与标记
【主要参考】:https://gitee.com/monkeycc/labelme/tree/master/examples/instance_segmentation
在安装后,在cmd或者shell输入
labelme ./imgs --autosave --labels labels.txt --config '{shift_auto_shape_color: -2}'
- .
/imgs改为你需要数据集的路径 --autosave标记后会自动保存--labels是预先建立的标签'{shift_auto_shape_color: -2}'彩色显示不同的类别- labels.txt内容可为:
-
ignore
background
people
cow
第二步:PaddleDetection安装
PaddlePaddle开发环境配置与安装
需要安装百度的深度学习框架PaddlePaddle:https://www.paddlepaddle.org.cn/
或者直接在其在线平台: https://aistudio.baidu.com/aistudio/index
下载并安装PaddleDetection的依赖
- https://gitee.com/paddlepaddle/PaddleDetection/blob/master/docs/tutorials/INSTALL_cn.md
下载项目
git clone https://gitee.com/paddlepaddle/PaddleDetection
安装依赖
cd PaddleDetection
pip install -r requirements.txt
测试成功
python ppdet/modeling/tests/test_architectures.py
使用预训练模型预测图像,快速体验模型预测效果:
use_gpu参数设置是否使用GPU
python tools/infer.py \
-c configs/ppyolo/ppyolo.yml \
-o use_gpu=true\
weights=https://paddlemodels.bj.bcebos.com/object_detection/ppyol
第三步:将labelme标记json转化为PaddleDetection训练所需格式
筛选数据集(可跳过)
- 由于数据集不是所有的图片都标记了,且原图和json标记文件放一起
需要将其转化为图片、json分开放的两个数据集 - 见附录find_img_by_json.py
飞浆labelme转换为coco数据
请将文件名改为自己的数据集
- https://gitee.com/paddlepaddle/PaddleDetection/blob/master/docs/tutorials/Custom_DataSet.md
cd PaddleDetection
python tools/x2coco.py \
--dataset_type labelme \
--json_input_dir your_path/toupi_labelme_countHair_choose/jsons \
--image_input_dir your_path/toupi_labelme_countHair_choose/imgs \
--output_dir ./dataset/toupi_plus_hair_coco0317 \
--train_proportion 0.85 \
--val_proportion 0.10 \
--test_proportion 0.05
- 其中val是用作训练时测量模型性能的数据
- test是训练完成后验证模型泛化性能的数据
第四步:选择模型并进行配置
模型库
- https://gitee.com/paddlepaddle/PaddleDetection/blob/master/docs/MODEL_ZOO_cn.md
骨架网络 网络类型 每张GPU图片个数 学习率策略 推理时间(fps) Box AP Mask AP 下载 配置文件
ResNet50-vd-FPN Mask 1 2x 15.825 39.8 35.4
修改配置
-
RCNN系列模型参数配置教程
备份原配置
mask_rcnn_r50_vd_fpn_2x.yml以及mask_fpn_reader.yml
cp ./configs/mask_rcnn_r50_vd_fpn_2x.yml ./configs/mask_rcnn_r50_vd_fpn_2x_toupi.yml
cp ./configs/mask_fpn_reader.yml ./configs/toupi_mask_fpn_reader.yml
toupi_mask_rcnn_r50_vd_fpn_2x.yml主要修改
在 mask_rcnn_r50_vd_fpn_2x.yml中修改
-
max_iters: 36000(本人数据量为100,所以迭代次数少) -
weights=output/toupi_mask_rcnn_r50_vd_fpn_2x/model_final -
num_classes: your_num -
milestones调低学习率的转折点 ,一般为coco数据集是在总迭代次数2/3 或者8/9 处,若总迭代次数为36000,可设置为[24000,26777], 也可根据训练曲线自行设置 -
snapshot_iter: 5000模型保存间隔,如果训练时eval设置为True,会在保存后进行验证 -
base_lr: 0.00125 # 0.01/8 0.01 是8卡的学习率 -
_READER_:最后一行,数据读取文件名改为最新的 ‘toupi_mask_fpn_reader.yml’
在toupi_mask_fpn_reader.yml 中修改数据集路径:
batch_size: 1
trian
dataset:
!COCODataSet
dataset_dir: dataset/toupi_plus_hair_coco0317
anno_path: annotations/instance_train.json
image_dir: train
EvalReader:
inputs_def:
fields: ['image', 'im_info', 'im_id']
dataset:
!COCODataSet
image_dir: val
anno_path: annotations/instance_val.json
dataset_dir: dataset/toupi_plus_hair_coco0317
TestReader:
anno_path: dataset/toupi_plus_hair_coco0317/annotations/instance_test.json
第五步:训练、推理、验证
训练
python -u tools/train.py -c configs/toupi_mask_rcnn_r50_vd_fpn_2x.yml \
--use_vdl=true \
--vdl_log_dir=vdl_dir/scalar \
--eval \
-o use_gpu=true
可视化训练过程
visualdl --logdir ./vdl_dir/scalar --host 127.0.0.1 --port 7890
每20次迭代记录一次,1200,相当于迭代24000次

验证指标
weights在寻址文件中设置
CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c configs/toui_mask_rcnn_r50_vd_fpn_2x_infer.yml -o use_gpu=true weights=output/toupi_mask_rcnn_r50_vd_fpn_2x/model_final
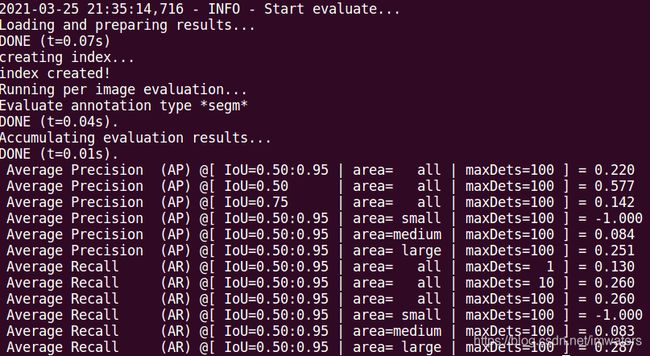
推理
python tools/infer.py -c configs/toui_mask_rcnn_r50_vd_fpn_2x_infer.yml \
--infer_dir dataset/toupi_plus_hair_coco0317/test/ \
--output_dir ./output/solo0318_train \
--draw_threshold 0.5
附录
find_img_by_json.py
import os
import shutil
input_dir = '/home/ai004/datasets/toupi_datasets/toupi_labelme_plus_hair'
out_dir = '/home/ai004/datasets/toupi_datasets/toupi_labelme_plus_hair_choose'
out_dir_jsons = out_dir + '/jsons'
out_dir_imgs = out_dir + '/imgs'
# input_dir='./all'
# os.path.walk
if not os.path.exists(out_dir_jsons):
os.makedirs(out_dir_jsons)
if not os.path.exists(out_dir_imgs):
os.makedirs(out_dir_imgs)
paths = os.listdir(input_dir)
suffix_names = [] # 看看有哪些后缀名
for i, file in enumerate(paths):
# a=paths[0]
# name,suffix=os.path.splitext(file)
# if suffix not in suffix_names:
# suffix_names.append(suffix)
if i % 500 == 0:
print(i)
if file.endswith('.json'):
# 找到json
name, suffix = os.path.splitext(file)
# print(name,suffix)
source_file = os.path.join(input_dir, file)
target_path = os.path.join(out_dir_jsons, file)
# print ("copy json",target_path)
# save_jpg
name = name + '.jpg'
img_source_file = os.path.join(input_dir, name)
img_target_path = os.path.join(out_dir_imgs, name)
if not os.path.exists(img_source_file):
continue
shutil.copyfile(source_file, target_path)
shutil.copyfile(img_source_file, img_target_path)
# print ("copy img",target_path)
# break
# print(ret)
# for name in paths: