【数据挖掘与分析】python网络爬虫入门学习及实践记录 | part02-网络请求(6-10)
端午回家呆了几天,完全放松。收假来赶个课程汇报,所以晚上没能及时跟上学习节奏,碰巧师兄分享学习进度,为所动。考试周正好大部分课程开始结课,可以有大块的时间来学习。下面介绍一下学习目标:
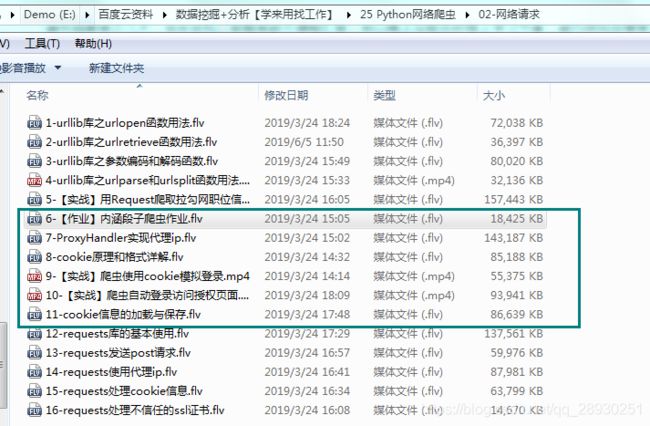
这篇博文会完成这部分视频的笔记和练习。
6-【作业】内涵段子爬虫作业
这里按照老师给的url:www.neihanshequ.com已经找不到网址了,可能是已经停止运营。所以选择天涯完成练习(http://bbs.tianya.cn/list.jsp?item=develop&nextid=1560313772000)这里选择了天涯社区的财经频道进行挖取,通过chrome浏览器的调试台可以看出,获取更多信息的链接为thttp://bbs.tianya.cn/list.jsp?item=develop&nextid=1560313772000,于是点开这个链接在右侧的请求头中找到需要抓取的url,参照上节练习,伪造一层请求头,get请求方式一致。顺利拿到本页代码,这里思考一个问题,为什么拉勾网爬取到的是json,而这个练习中爬取到的是html代码,如果需要进一步的拿到需要的信息应该怎么做?这里贴出拉勾网从控制台拿到的json数据格式化后的内容,可以看出来,确实已经拿到了职位信息,进一步的就是存储的问题。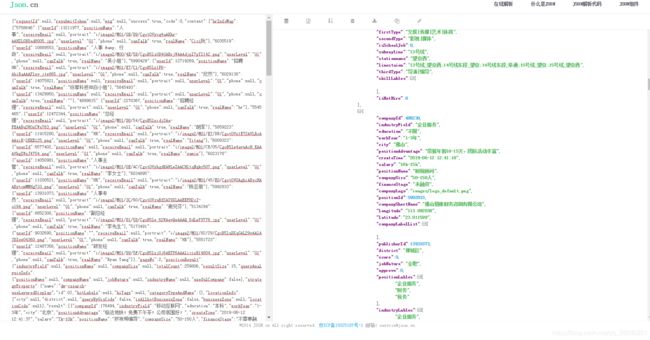
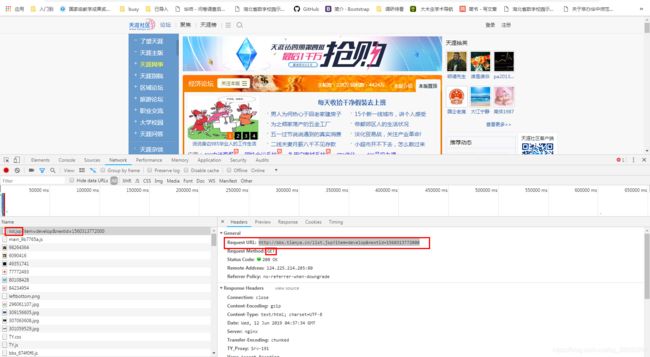
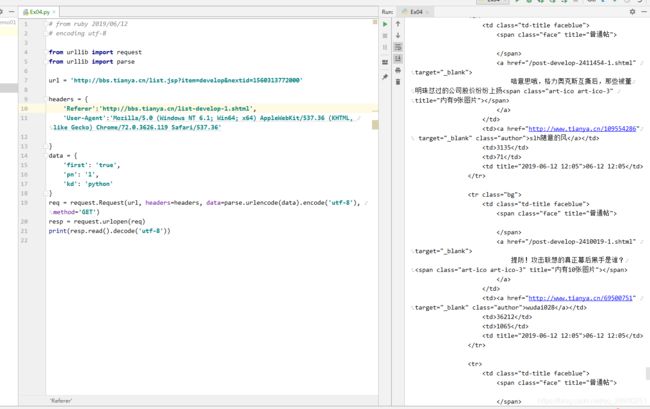
而这个练习中,仍然存在是html代码,可以自行补充一个练习,比如爬58或者智联招聘、boss直聘的职位信息。
先拿boss分析一波,发现,职位搜索页,找到都是代码,点击下一页分析后才发现,boss把职位信息先编码,后拿到的职位信息就都是编码对应的信息,试着拿了一下编码信息,
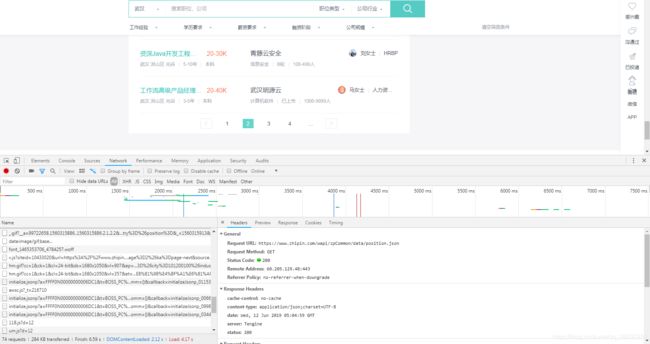
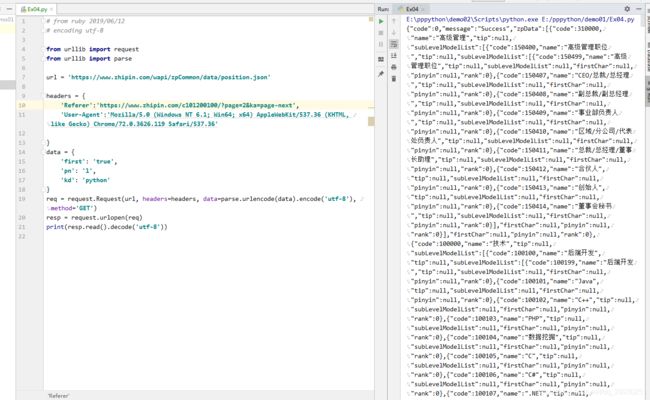
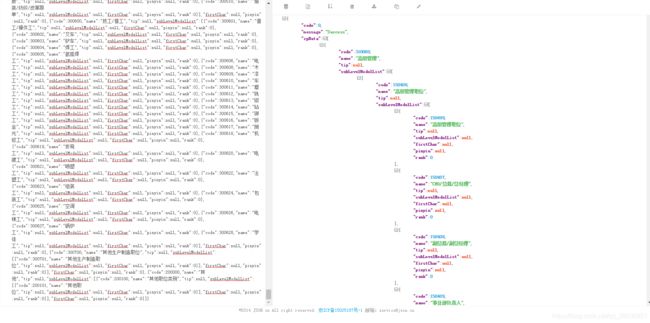 格式化后发现,每个职位对应着不同码,职位城市可以编码,公司呢?这里不禁想到这个问题,我决定稍微深挖一下,另外在
格式化后发现,每个职位对应着不同码,职位城市可以编码,公司呢?这里不禁想到这个问题,我决定稍微深挖一下,另外在
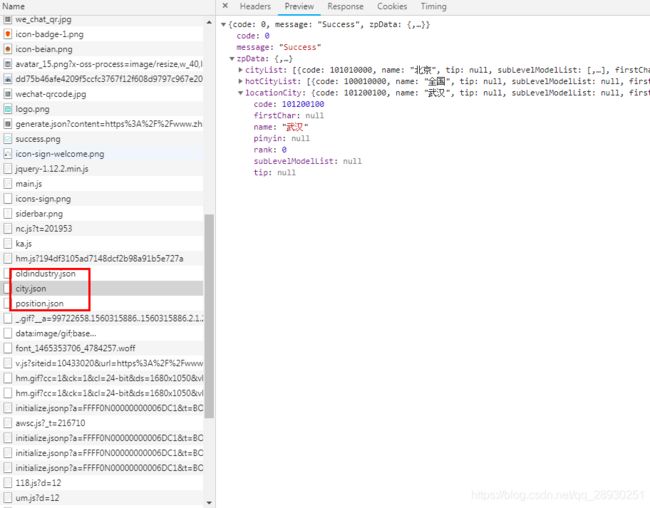
可以抓到这三个json文件,在里面没有找到其他有用信息,疑似有反爬虫的加密机制,现在我还看不懂,搁一下往后走吧。
58同城里面的把职位信息编码写进了js,抓取应该能抓下来,和boss一样需要进一步分析。

这部分练习告一段落,可以进行下一部分学习。
7-ProxyHandler实现代理ip
·ProxyHandler处理器(代理设置)
防止被封ip,同一时间段访问过多有些网站会封掉ip。
#from Ruby in 2019/06/12
# ProxyHandler练习
from urllib import request
#没有用代理
resp = request.urlopen('http://httpbin.org/ip')
print(resp.read().decode("utf-8"))
#使用代理的
# handler = request.ProxyHandler({"http":"218.66.161.88:31769"})
#
# opener = request.build_opener(handler)
# req = request.Request("http://httpbin.org/ip")
# resp = opener.open(req)
# print(resp.read())
# 常用代理
# 西刺免费代理 xicidaili
# 快代理 https://www.kuaidaili.com/ops/
# 代理云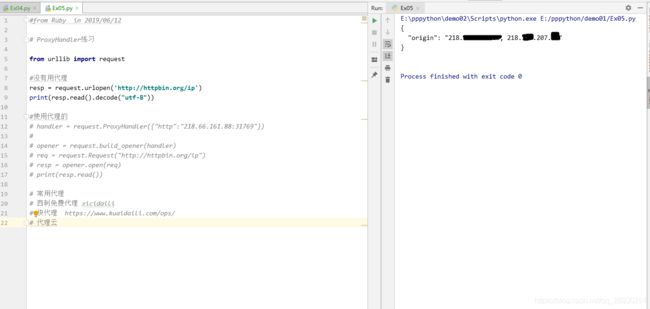
是可以获取到本机ip的, 接着测试代理方式,选择快代理的开放代理,选取一个支持HTTP/HTTPS的ip

 确实完成了,ip的代理。检测后发现ip已经换成了140开头。这里过一遍伪造的步骤,
确实完成了,ip的代理。检测后发现ip已经换成了140开头。这里过一遍伪造的步骤,
1.传入代理构建一个handler;2.使用创建的handler构建opener;3.使用opener发送请求
也对应着上方使用代理的12/14/16三行代码的作用,第15行是request链接,第17行是打印结果
演示完代理ip后,老师补充说明了,上面未使用代理的方法,从原理上和使用代理三步一样,可以进到request.py文件中查看,urlopen函数内部构造,之所以可以直接使用函数就能免去构建handler和opener,是urlopen函数把这些工作都已经写好封装起来的。
代理的原理-
请求目的网站之前,先请求代理服务器,让代理服务器去请求目的网站,拿到数据后转发给我们。
这里拿ip的网站是点我【http://httpbin.org/ip】返回上级目录还有其他功能,可以方便查看http请求的一些参数。
刚好两点,去吃个饭回来再接着跟。
顺便补充说明一下,上一节中,老师使用urllib库中urlretrieve函数爬存图片,我没有实现,但是放到同门电脑上是可以跑的,当时也解决了一个request一直提示模块没有的问题,后来切换了编译环境,就解决了。我回来后土法炮制,来anaconda里面新建了一个老师之前要求的3.6版本的python开发环境,再用pycharm配置一下,马上就能保存,不再提示ssl问题了,噢,先提示了一下,去anaconda里面down了一个open-ssl的包,再次运行就没问题了。
所以前面跟的代码就可以顺利跑通了,好去吃个饭,回来继续开新节!
吃个饭吃了一个半小时,好的吧~
Cookie原理和格式
请求无状态,cookie帮助服务器与浏览器间留下访问记录。一般不超过4KB,只能存储小体量数据。原理如下:

cookie的格式 Set-Cookie:NAME=VALUE:Expires/Max-age=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE

使用cookielib库和HTTPCookieProcessor模拟登录:
Cookie是指网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,可以保持登录信息到用户下次与服务器的会员。
e.g: 人人网的访问,需要登录才能访问目标的主页→需要cookie信息,用代码的方式访问的话需要正确的cookie信息,有两种:1.使用浏览器访问,复制cookie信息放入headers,伪造一层请求头。
跟着老师做,先做请求,发现拿到的是未登录的静态网页
补充加了一层请求头中登录后的cookie,继续抓取,并且记住补充打开使用‘utf-8’编码格式, 成功拿到登录后的大鹏主页。
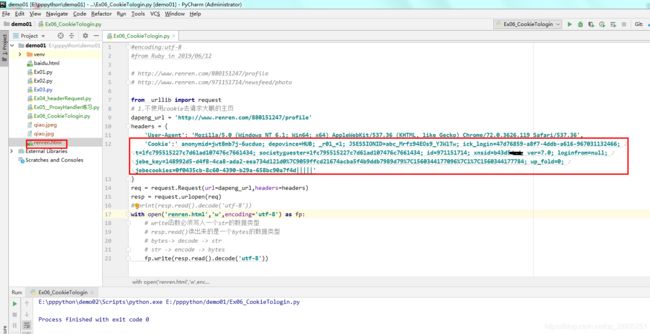
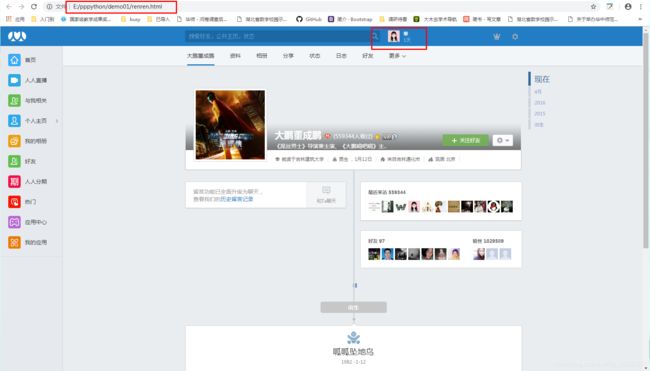
并且,其中确实保存到了本地,与上张爬取结果不同的是,新增了在open()中补充属性‘encoding=‘utf-8’’,这里是手动拿到的cookie
10-【实战】爬虫自动登录访问授权页面
首先老师介绍了一下为什么上面可以爬到目标主页,还需要再进行爬取,因为上面的cookie是手动拿到的,不属于自动登录。所以这里,一个解决的思路是:使用账号密码登录后自动存储cookie,再使用cookie去读取主页信息。
接着老师介绍了一下,这个过程会使用到的模块:http.cookiejar模块(主要四类 CoolieJar-管理存储HTTP cookie值、FileCookieJar-从上一个类派生而来,检索并存储、MozillaCookieJar-从上一个类派生而来与火狐浏览器兼容实例、LWPCookieJar-从FileCookieJAr派生而来 创建与libwww-perl标准的Set-Cookie3文件格式兼容的实例)
过了一遍老师就开始带入实例:利用 http.cookiejar 和 request.HTTPCookieProcessor登录人人网,思路见注释
#未整理前,跟着老师敲的代码
#encoding:utf-8
#from Ruby in 2019/06/12
# http://www.renren.com/880151247/profile
# http://www.renren.com/971151714/newsfeed/photo
from urllib import request
from urllib import parse
from http.cookiejar import CookieJar
# 1. 登录
# 1.1 创建一个cookiejar对象
cookiejar = CookieJar()
# 1.2 使用cookiejar创建一个HTTPCookieProcess对象
handler = request.HTTPCookieProcessor(cookiejar)
# 1.3 使用上一步创建的handler创建一个opener
opener = request.build_opener(handler)
# 1.4 使用opener发送登录的请求(人人网的邮箱和密码)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
data = {
'email':'[email protected]',
'password':'****(填写自己的密码)'
}
login_url = 'http://www.renren.com/'
req = request.Request(login_url,data=parse.urlencode(data).encode('utf-8'),headers=headers)
opener.open(req)
# 2.访问个人主页
dapeng_url = 'http://www.renren.com/880151247/profile'
# 获取个人主页页面 无需新建opener 而应该使用之前opener 因为之前已经包含了所需的cookie信息
req = request.Request(dapeng_url,headers=headers)
resp = opener.open(req)
with open('dapeng.html','w',encoding='utf-8') as fp:
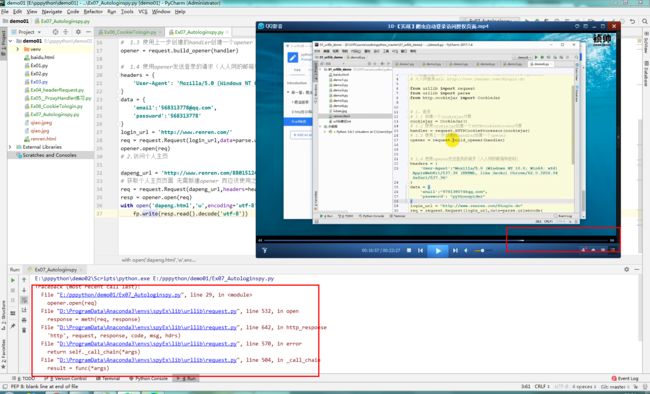
fp.write(resp.read().decode('utf-8'))搞不完了,先回家。跑出来问题,明天再来解决。
来了以后,先看完老师的视频,老师把三个部分抽出来作为函数,单独再用main函数中调用。视频中可以跑,老师强调不要再url或者运行结果这个部分来纠结,可以先跟着。
前面试着这样一个思路来解决出现的问题,贴出来以供参考:1.反复检查代码,跟视频确实一致,替换了最新的人人访问登录的url,加了多条伪请求头信息;2.怀疑是版本问题,去m老师电脑上跑了一下,还是没有出来,换个环境也不行;3.怀疑是用法问题,这里发现一个说明,urllib库在python2/3中用法不同,仔细对比了一下代码,发现确实是python3的用法,试图修改了一下后面open函数,中间加了一个request,虽然报错信息变少,只有两条,但是提示没有这种用法,故而放弃,转向去研究python中open函数及opener函数的用法,试图找到一些蛛丝马迹,能够解决。
前两个因为核对了,加上手动拿cookie可以访问到,所以排除,主要是第三个原因,第三个原因又有两种可能①人人网识别了爬虫,有反爬机制;②python3.6中open/opener函数的用法不对。两种可能性都挺大,目前从第二个开始搜相关解决办法,比如 参考同类型错误提示贴/看菜鸟教程里两种函数的使用。如果梳理清楚,这里需要补充进来。

因为下午政治考试,所以先去上课,回来接着完成 后面六个视频,但是这一部分,已经完成了。
等下,补充一下抽象出来整理好的代码。三部分抽成函数,用主函数调用。
# encoding:utf-8
# from Ruby in 2019/06/12
# http://www.renren.com/880151247/profile
# http://www.renren.com/971151714/newsfeed/photo
from urllib import request
from urllib import parse
from http.cookiejar import CookieJar
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
'Referer': 'http://www.renren.com/SysHome.do',
'Upgrade-Insecure-Requests': '1',
'Connection': 'keep-alive'
}
def get_opener():
# 1. 登录
# 1.1 创建一个cookiejar对象
cookiejar = CookieJar()
# 1.2 使用cookiejar创建一个HTTPCookieProcess对象
handler = request.HTTPCookieProcessor(cookiejar)
# 1.3 使用上一步创建的handler创建一个opener
opener = request.build_opener(handler)
return opener
def login_renren(opener):
# 1.4 使用opener发送登录的请求(人人网的邮箱和密码)
data = {
'email': '[email protected]',
'password': '568313778'
}
login_url = 'http://www.renren.com/SysHome.do'
req = request.Request(login_url, data=parse.urlencode(data).encode('utf-8'), headers=headers)
opener.open(req)
def visit_profile(opener):
# 2.访问个人主页
dapeng_url = 'http://www.renren.com/880151247/profile'
# 获取个人主页页面 无需新建opener 而应该使用之前opener 因为之前已经包含了所需的cookie信息
req = request.Request(dapeng_url, headers=headers)
resp = opener.open(req)
with open('dapeng.html', 'w', encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
opener = get_opener()
login_renren(opener)
visit_profile(opener)