yolov5推理出大的错误框--一种简单粗暴但局限的规避方法
目录
一。概述
二。问题描述
三。验证
四。一种简单粗暴但局限的规避方法
一。概述
yolov5在匹配格子、anchor与物体标签的时候,有可能把同一个格子同一个anchor匹配给不同的物体,甚至是尺度相差的比较大的物体,此时就有可能导致在推理的时候推理出一些置信度偏低、尺度比真实物体大很多的物体框。本文采用了一种简单粗暴并且有局限性的办法来规避,但是在一定的限度内确实蛮有效的~~
二。问题描述
在yolov5源码解析(10)--损失计算与anchor_扫地僧1234的博客-CSDN博客
的末尾抛出了一个问题,具体可以去看一下那一期的内容(强烈建议去看一下!),简单的说,就是标注的物体a、b有重叠,在训练的时候有可能同一个格子即负责预测物体a,也负责预测物体b。你可能会说这不是很正常吗。
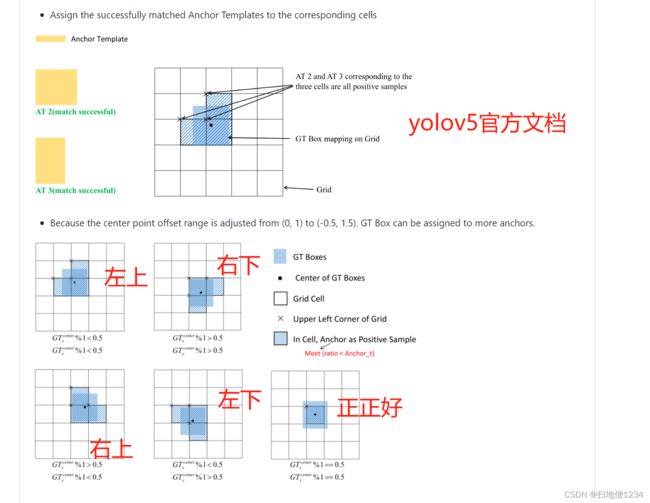
但是如果物体a、b的尺度相差比较大,比如物体a大,物体b小,而物体a、b的中心点比较接近,此时也会发生这种情况,比如下图:

耳塞基本在平板的中间,这样它们的中心点就能归到同一个格子上,那么这个格子就有可能会既负责预测平板,也负责预测耳塞。
注意:
(1)这里说的是有可能,因为除了中心点与格子的关系之外,物体的宽高与anchor的宽高比例不能超过4(超参anchor_t)
(2)也不一定中心点非得落在这个格子, 比如中心点落在格子c里,位置偏左上,那么格子c的左侧格子,上侧格子都会负责预测该物体。
如下图,详见yolov5源码解析(10)--损失计算与anchor_扫地僧1234的博客-CSDN博客
那么如果一个格子既要预测平板,又要预测耳塞会有什么问题呢:
(1)显然在非多标签分类的情况下,这个格子不管是预测平板还是预测耳塞的分类得分都会被抑制,所以两个得分都会比较低,sigmoid之后会接近0.5。这好像问题不是太大,0.5咱就不要它呗,咱要得分高的。
(2)这个格子还得预测物体的宽高啊,平板和耳塞的尺寸差距比较大,一会儿用平板的宽高真值给他计算损失,一会儿用耳塞的宽高直值给他计算损失,那最终得出的宽高可能不靠谱。
(3)问题(1)里面说0.5的就不要,但是如果我们训练出来的东西里面,有些东西的效果不太好,置信度比较低,跟0.5很接近,而我们又想要预测出这些东西,那置信度就有点难设了。
三。验证
光说无用,我们先验证一下到底会不会有上面说的问题,拍了一批图片,一共50张,拍的时候没用耳塞,拿着耳机了(不要在意这些细节。。),训练集45张图,测试集5张图

另外为了省时间,拍的图有点少。有兴趣的同学也可以多拿些图验证验证,其实我是工作中验证的东西遇到了这个问题,当时用了几百张图,有300多张的,也有900多张的,都有这个问题。所以这个可能跟图多图少关系不是太大。
标注的分类就是平板和耳塞(耳机。。)
接下来开始训练:
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --cache --name exp_earplug 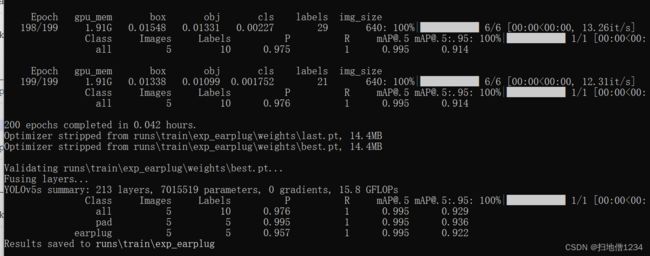
看上面的数据可能不能直接反映出我们的问题,直接再推理一遍验证集:
python detect.py --weights D:\workPython\yolov5-6.2\runs\train\exp_earplug\weights\best.pt --source D:\dataset\earplug_data\images\val --name exp_earplug 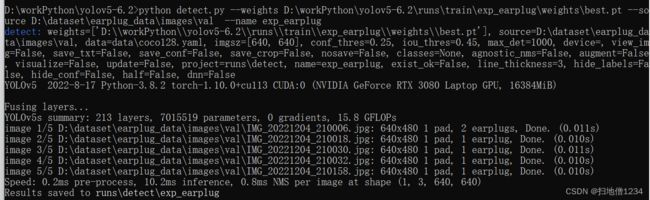
第一张图就出问题了,推理出了一个置信度0.55,类型为耳塞的物体,但是尺寸明显比耳塞大,可能位于耳塞与平板之间的尺寸。
其它4张图没什么问题
现在的问题很明显,就是在推理的时候,如果耳塞与平板的中心点接近,就有可能有问题,跟上面说的情况一致。
四。一种简单粗暴但局限的规避方法
怎么解决这个问题呢,其实yolov5的作者可能知道这个问题,但是这个问题可能暂时并没有很好的解决方案,或者说这个问题本身就是在一些特殊的场景下才会有的,比如你有1万张图,但只有10张才会有这种问题(即问题场景只有千分之1),这种情况下训练出来的模型还有没有这个问题我就没验证过了。
但是同一个框,同时预测两种尺度相差比较大的物体,明显是不太合理的。
先回顾一下,yolov5一共有3层输出,分别是80x80,40x40,20x20,浅层的用来预测小物体,中层的预测中物体,深层的预测大物体。每一层都有3个anchor分别对应不同尺度的宽高。如果能设计一种规则,让不同层的anchor把要预测的物体分摊一下,不要出现这种同一个格子的同一个anchor同时预测两个不同的东西的情况,那就没这个问题了。但问题就是,这个规则很难设计,如果必须保证一个格子一个anchor只预测一个物体,而不预测其它物体,那就有可能导致有些物体没人负责预测了,它们就丢了!
所以这里先提出一种简单粗暴的方法,比如本文中的实例,这个平板很大,直接让20x20这一层的最大的anchor来预测它就行了啊。即373,326这个anchor。剩下的8个anchor负责预测耳塞(不管能不能匹配上,分正我们把它们分开了!)
怎么实现呢,修改utils/loss.py的build_targets函数(注,这里用的是yolov5-6.2的代码,先跟前面的源码解析系列保持一致,但我看了一下yolov5-7.0的代码,这一块应该没怎么变)
直接上完整代码。
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=self.device) # normalized to gridspace gain
ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor(
[
[0, 0],
[1, 0],
[0, 1],
[-1, 0],
[0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
],
device=self.device).float() * g # offsets
for i in range(self.nl):
anchors, shape = self.anchors[i], p[i].shape
gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain # shape(3,n,7)
if nt:
# Matches
r = t[..., 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
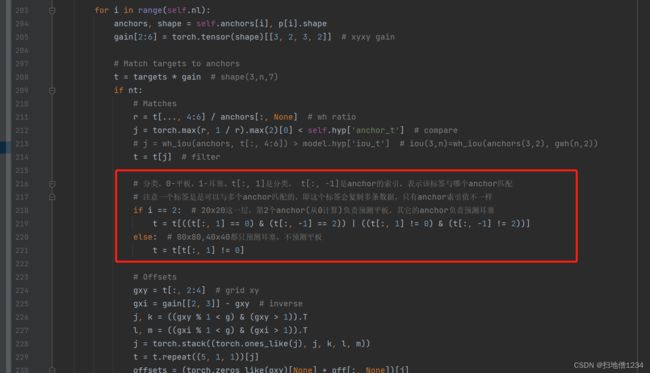
# 分类,0-平板,1-耳塞。t[:, 1]是分类, t[:, -1]是anchor的索引,表示该标签与哪个anchor匹配
# 注意一个标签是是可以与多个anchor匹配的,即这个标签会复制多条数据,只有anchor索引值不一样
if i == 2: # 20x20这一层,第2个anchor(从0计算)负责预测平板,其它的anchor负责预测耳塞
t = t[((t[:, 1] == 0) & (t[:, -1] == 2)) | ((t[:, 1] != 0) & (t[:, -1] != 2))]
else: # 80x80,40x40都只预测耳塞,不预测平板
t = t[t[:, 1] != 0]
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
gij = (gxy - offsets).long()
gi, gj = gij.T # grid indices
# Append
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
添加的就是这一块,就可以把平板和耳塞分开。
接下来重新训练
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --cache --name exp_earplug_anchor_modify 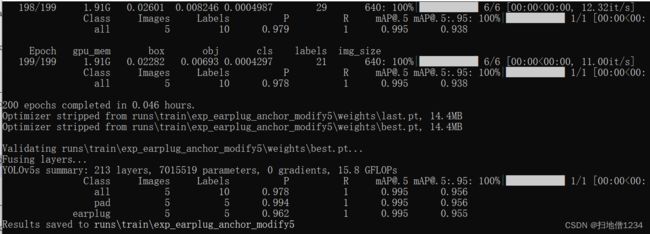
exp_earplug_anchor_modify5都到5了是因为一开始没改对,调试了一次。。。
就不仔细看这个数据了,直接再推理一遍
python detect.py --weights D:\workPython\yolov5-6.2\runs\train\exp_earplug_anchor_modify5\weights\best.pt --source D:\dataset\earplug_data\images\val --name exp_earplug_anchor_modify
可以看到,不再在那个置信度0.55但尺度比耳塞大不少的物体框了!
其它4张图还是没什么问题就不贴了。
那么为什么说这是一种有局限性的办法呢,因为我这边就两种物体,9个anchor来分的话,绰绰有余。但如果物体比较多,并且尺度变化都蛮大的,那就不是那么好分了。
那怎么办呢?
(1)上面说的设计一种规则来分摊不同的物体,虽然有点难。。
(2)9个anchor不够,咱给它多加些anchor?势必会增加一点计算量,但是好像加的也不是太多。
我在这里抛砖引玉,欢迎大家的高见!