DETR系列大盘点 | 端到端Transformer目标检测算法汇总!
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!
自从VIT横空出世以来,Transformer在CV界掀起了一场革新,各个上下游任务都得到了长足的进步,今天就带大家盘点一下基于Transformer的端到端目标检测算法!
原始Tranformer检测器
DETR(ECCV2020)
开山之作!DETR!代码链接:https://github.com/facebookresearch/detr
论文提出了一种将目标检测视为直接集预测问题的新方法。DETR简化了检测流程,有效地消除了对许多人工设计组件的需求,如NMS或anchor生成。新框架的主要组成部分,称为DEtection TRansformer或DETR,是一种基于集合的全局损失,通过二分匹配强制进行一对一预测,以及一种transformer encoder-decoder架构。给定一组固定的学习目标查询,DETR分析了目标和全局图像上下文之间的关系,以直接并行输出最后一组预测。与许多其他检测器不同,新模型概念简单,不需要专门的库。DETR在具有挑战性的COCO目标检测数据集上展示了与成熟且高度优化的Faster RCNN基线相当的准确性和运行时间。此外,DETR可以很容易地推广到以统一的方式输出全景分割。
DETR的网络结构如下图所示,从图中可以看出DETR由四个主要模块组成:backbone,编码器,解码器以及预测头。主干网络是经典的CNN,输出降采样32倍的feature。

实验结果如下所示,性能上倒是还不错,就是训练太慢了,300 epochs。

DETR还展示了COCO上的全景分割结果,可以看出实例区分能力还是比较有限,中间的Bus。

Pix2seq(谷歌Hinton)
代码链接:https://github.com/google-research/pix2seq
一句话总结:一个简单而通用的目标检测新框架,其将目标检测转换为语言建模任务,大大简化了pipeline,性能可比肩Faster R-CNN和DETR!还可扩展到其他任务。
论文提出Pix2Seq,一个简单而通用的目标检测框架!!!与显式集成关于任务的先验知识的现有方法不同,Pix2seq将目标检测作为一个基于观察到的像素输入的语言建模任务。目标描述(例如,边界框和类标签)表示为离散token,训练神经网络来感知图像并生成所需序列。Pix2seq主要基于这样一种直觉,即如果神经网络知道目标的位置和内容,我们只需要教它如何read them out。除了使用特定于任务的数据扩充,Pix2seq对任务的假设最少,但与高度专业化和优化的检测算法相比,它在具有挑战性的COCO数据集上取得了有竞争力的结果。
网络主要包含四个组件:
图像增强:正如在训练计算机视觉模型中常见的那样,论文使用图像增强来丰富一组固定的训练示例(例如,使用随机缩放和裁剪);
序列构造和扩充:由于图像的目标注释通常表示为一组边界框和类标签,论文将它们转换为一系列离散token;
架构:使用编码器-解码器模型,其中编码器感知像素输入,解码器生成目标序列(一次一个token);
目标/损失函数:对模型进行训练,以最大化基于图像和先前token的token的对数似然性(使用softmax cross-entropy loss)。

序列构造示意图:

训练300 epochs,实验结果:

稀疏注意力
Deformable DETR(ICLR 2021)
代码链接:https://github.com/fundamentalvision/Deformable-DETR
最近提出了DETR,以消除在物体检测中对许多手动设计部件的需要,同时证明了良好的性能。然而,由于Transformer注意力模块在处理图像特征图时的限制,它存在收敛速度慢和特征空间分辨率有限的问题。为了缓解这些问题,论文提出了Deformable DETR,其注意力模块只关注参考周围的一小组关键采样点。Deformable DETR可以实现比DETR更好的性能(特别是在小目标上),训练时间减少10倍。COCO基准的大量实验证明了算法的有效性。

- DETR存在的问题
训练周期长,相比faster rcnn慢10-20倍!
小目标性能差!通常用多尺度特征来解小目标,然而高分辨率的特征图大大提高DETR复杂度!
- 存在上述问题的原因
初始化时,attention model对于特征图上所有像素权重几乎是统一的(即一个query与所有的k相乘的贡献图比较均匀,理想状况是q与高度相关且稀疏的k相关性更强),因此需要长时间学习更好的attention map;
处理高分辨率特征存在计算量过大,存储复杂的特点;
- Motivation
让encoder初始化的权重不再是统一分布,即不再与所有key计算相似度,而是与更有意义的key计算相似度可变形卷积就是一种有效关注稀疏空间定位的方式;
提出deformable DETR,融合deformable conv的稀疏空间采样与transformer相关性建模能力在整体feature map像素中,模型关注小序列的采样位置作为预滤波,作为key。
实验结果

End-to-End Object Detection with Adaptive Clustering Transformer(北大&港中文)
代码链接:https://github.com/gaopengcuhk/SMCA-DETR/
DETR使用Transformer实现目标检测,并实现与Faster RCNN等两阶段目标检测类似的性能。然而,由于高分辨率的空间输入,DETR需要大量的计算资源用于训练和推理。本文提出了一种新的Transformer变体——自适应聚类Transformer(ACT),以降低高分辨率输入的计算成本。ACT使用Locality Sensitive Hashing(LSH)自适应地聚类query特征,并使用prototype-key交互来近似query-key交互。ACT可以将自注意力内部的二次()复杂度降低为(),其中K是每个层中原型的数量。ACT可以是一个嵌入式模块,取代原来的自注意力模块,无需任何训练。ACT在精度和计算成本(FLOP)之间实现了良好的平衡。
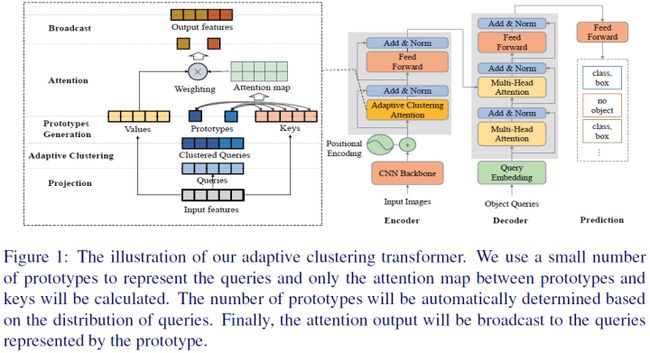
本文的主要贡献如下:
开发了一种称为自适应聚类Transformer(ACT)的新方法,该方法可以降低DETR的推理成本。ACT可以降低原始Transformer的二次复杂度,同时ACT与原始Transformer完全兼容;
将DETR的FLOPS从73.4 Gflops减少到58.2 Gflops(不包括骨干Resnet FLOPS),而无需任何训练过程,而AP的损失仅为0.7%;
通过多任务知识蒸馏(MTKD)进一步将AP的损失降低到0.2%,该技术实现了ACT和原始Transformer之间的无缝切换。
实验结果如下:

PnP-DETR(ICCV 2021)
论文链接:GitHub - twangnh/pnp-detr: Implementation of ICCV21 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers
DETR虽然有效,但由于在某些区域(如背景)上的冗余计算,转换完整的特征图可能代价高昂。在这项工作中,论文将减少空间冗余的思想封装到一个新的poll and pool(PnP)采样模块中,利用该模块构建了一个端到端PnP DETR架构,该架构自适应地在空间上分配其计算,以提高效率。具体地说,PnP模块将图像特征映射抽象为精细的前景目标特征向量和少量粗略的背景上下文特征向量。Transformer对精细-粗糙特征空间内的信息交互进行建模,并将特征转换为检测结果。此外,通过改变采样特征长度,PnP增强模型可以立即在单个模型的性能和计算之间实现各种期望的权衡,而不需要像现有方法那样训练多个模型。因此,它为具有不同计算约束的不同场景中的部署提供了更大的灵活性。论文进一步验证了PnP模块在全景分割上的泛化性以及最近基于Transformer的图像识别模型ViT[7],并显示出一致的效率增益。论文认为PnP-DETR为使用Transformer进行有效的视觉分析迈出了一步,其中通常观察到空间冗余。
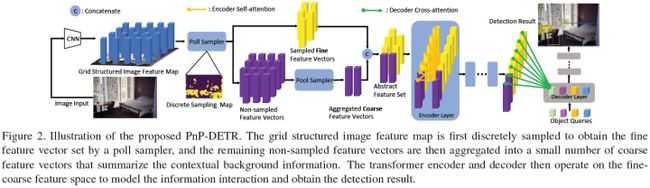
本文的主要贡献如下:
分析了DETR模型中图像特征图的空间冗余问题,该问题导致transformer网络计算量过大。因此,提出对特征映射进行抽象,以显著降低模型运算量;
设计了一种新颖的两步轮询池采样模块提取特征。该算法首先利用poll采样器提取前景精细特征向量,然后利用pool采样器获取上下文粗特征向量;
构建了PnP-DETR,该变换在抽象的细粗特征空间上进行操作,并自适应地将计算分布在空间域。通过改变精细特征集的长度,PnP-DETR算法效率更高,在单一模型下实现了即时计算和性能折衷。
PnP抽样模块是通用的,是端到端学习的,没有像RPN那样的明确监督。论文进一步在全景分割和最近的ViT模型上对其进行了验证,并显示出一致的效率增益。这种方法为未来研究使用transformer的视觉任务的有效解决方案提供了有用的见解。实验结果如下:

Sparse DETR(ICLR 2022)
代码链接:https://github.com/kakaobrain/sparse-detr
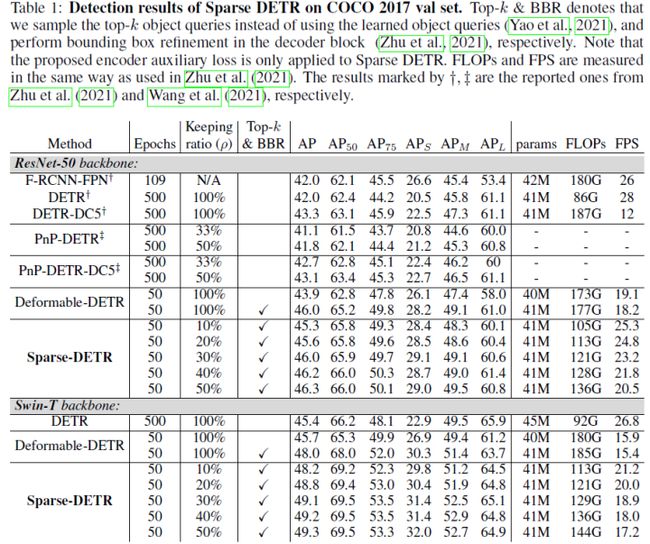
Deformable DETR使用多尺度特征来改善性能,然而,与DETR相比,encoder tokens的数量增加了20倍,encoder注意力的计算成本仍然是一个瓶颈。在本文的初步实验中,发现即使只更新了encoder tokens的一部分,检测性能也几乎不会恶化。受这一观察的启发,论文提出了Sparse DETR,它只选择性地更新decoder预期引用的令牌,从而帮助模型有效地检测目标。此外,在encoder中对所选token应用辅助检测损失可以提高性能,同时最小化计算开销。本文验证了Sparse DETR即使在COCO数据集上只有10%的encoder tokens,也比Deformable DETR获得更好的性能。尽管只有encoder tokens被稀疏化,但与Deformable DETR相比,总计算成本降低了38%,FPS增加了42%。
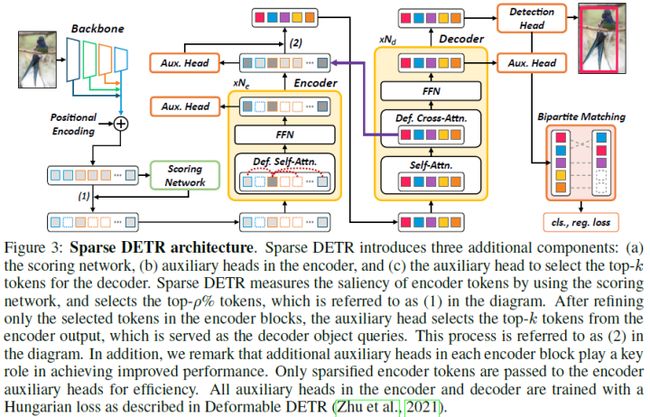
论文的主要贡献如下:
提出了一种有效的端到端目标检测器的编码器token稀疏化方法,通过该方法减轻了编码器中的注意力复杂性。这种效率使得能够堆叠比Deformable DETR更多的编码器层,从而在相同的计算量下提高性能;
提出了两个新的稀疏化标准来从整个token集合中采样信息子集:Objectness Score(OS)和Decoder cross-Attention Map(DAM)。基于decoder cross-attention map标准,稀疏模型即使在仅使用整个token的10%时也保持了检测性能;
仅对所选token采用编码器辅助损失。这种额外的损失不仅稳定了学习过程,而且大大提高了性能,只略微增加了训练时间。

实验结果如下:
空间先验
Fast Convergence of DETR with Spatially Modulated Co-Attention(ICCV 2021)
DETR的收敛速度较慢。从头开始训练DETR[4]需要500个epoch才能获得高精度。为了加速其收敛,本文提出了一种简单而有效的改进DETR框架的方案,即Spatially Modulated Co-Attention(SMCA)机制。SMCA的核心思想是通过将co-attention响应限制在初始估计的边界框位置附近的较高区域,在DETR中进行regression-aware co-attention。本文提出的SMCA通过替换decoder中的原始co-attention,同时保持DETR中的其他操作不变,提高了DETR的收敛速度。此外,通过将multi-head和scale-selection注意力设计集成到SMCA中,与基于空洞卷积的主干的DETR相比,本文的SMCA可以实现更好的性能。论文对COCO数据集进行了广泛的消融研究,以验证所提出的SMCA的有效性。

主要贡献如下:
提出了一种新的空间调制共同注意(SMCA),它可以通过进行位置约束目标回归来加速DETR的收敛。SMCA是原始DETR中的即插即用模块。没有多尺度特征和多头注意力的SMCA的基本版本已经可以在50个epoch达到41.0 mAP,在108个时期达到42.7 mAP。将SMCA的基本版本训练50个时期需要265个V100 GPU小时。
完整SMCA进一步集成了多尺度特征和多头空间调制,这可以通过更少的训练迭代进一步显著改进和超越DETR。SMCA在50个epoch可达到43.7mAP,在108个时期可实现45.6mAP,而DETR-DC5在500个时期可获得43.3mAP。将完整的SMCA训练50个epoch需要600 V100 GPU小时。
对COCO 2017数据集进行了广泛的消融研究,以验证所提出的SMCA模块和网络设计。
动机
为了加速DETR收敛,本文通过动态预测一个2D的空间高斯weight map,来跟co-attention feature maps相乘来达到加快收敛速度的目的。即插即用,让DETR涨点明显。性能优于可变形DETR、DETR等网络。
实验结果如下:

Conditional DETR(ICCV 2021)
本文针对DETR训练收敛缓慢这一关键问题,提出了一种用于快速DETR训练的conditional cross-attention机制。动机是DETR中的cross-attention高度依赖内容嵌入来定位和预测box,这增加了对高质量内容嵌入的需求,从而增加了训练难度。
本文的方法称为Conditional DETR,从解码器嵌入中学习条件空间query,用于解码器multi-head cross-attention。好处在于,通过条件空间query,每个交叉注意力头能够关注包含不同区域的band,例如,一个目标末端或目标框内的区域。这缩小了用于定位目标分类和box回归的不同区域的空间范围,从而放松了对内容嵌入的依赖,并简化了训练。实验结果表明,对于主干R50和R101,Conditional DETR收敛速度快6.7倍,对于更强的主干DC5-R50和DC5-R101,收敛速度快10倍。

动机
为了分析 DETR 为什么收敛慢,论文对 DETR decoder cross-attention 中的 spatial attention map 进行了可视化。

每个 head 的 spatial attention map 都在尝试找物体的一个 extremity 区域。论文认为,DETR 在计算 cross-attention 时,query 中的 content embedding 要同时和 key 中的 content embedding 以及 key 中的 spatial embedding 做匹配,这就对 content embedding 的质量要求非常高。而训练了 50 epoch 的DETR,因为 content embedding 质量不高,无法准确地缩小搜寻物体的范围,导致收敛缓慢。所以用一句话总结 DETR 收敛慢的原因,就是DETR 高度依赖高质量的 content embedding 去定位物体的 extremity 区域,而这部分区域恰恰是定位和识别物体的关键。
基于此,提出Conditional DETR!
实验结果如下:

Anchor DETR(AAAI 2022)
代码链接:https://github.com/megvii-research/AnchorDETR
本文提出了一种新的基于Transfomrer的目标检测查询机制。在以前的基于Transfomrer的检测器中,object query是一组学习的嵌入。然而,每个学习到的嵌入都没有明确的物理意义,我们无法解释它将集中在哪里。由于每个object query的预测slot没有特定的模式,因此很难进行优化。换句话说,每个object query都不会关注特定区域。为了解决这些问题,在本文的query设计中,object query基于anchor point,这在基于CNN的检测器中被广泛使用。因此,每个object query都集中在anchor附近的目标上。此外,本文的query设计可以在一个位置预测多个目标以解决困难:“一个区域,多个目标”。此外,本文设计了一种注意力变体,它可以降低内存成本,同时实现与DETR中的标准注意力相似或更好的性能。由于query设计和注意力变体,本文方法名为Anchor DETR,可以实现比DETR更好的性能,并且运行速度比DETR更快。

回顾基于CNN的检测器,anchor与位置高度相关,包含可解释的意义。受此启发,作者提出了一种基于锚点(anchor points)的查询设计,即将anchor points编码为目标查询。查询是锚点坐标的编码,因此每个目标查询都具有显式的物理意义。
但是,这个解决方案还有一个限制:多个目标可能出现在一个位置 。在这种情况下,只有这个位置的一个查询不能预测多个目标,因此来自其他位置的查询必须协同预测这些目标。它将导致每个目标查询负责一个更大的区域。因此,作者通过向每个锚点添加多个模式(multiple patterns,即一个锚点可以检测多个目标)来改进目标查询设计,以便每个锚点都可以预测多个目标
除了查询设计之外,作者还设计了一个attention变体—行列解耦注意(Row-Column Decouple Attention,RCDA) 。它将二维key特征解耦为一维行特征和一维列特征,然后依次进行行注意力和列注意力。RCDA可以降低计算成本,同时实现与DETR中的标准注意力相似甚至更好的性能。
实验结果如下:

Efficient DETR(旷视)
DETR和Deformable DETR,具有堆叠6个解码器层的级联结构,以迭代更新object query,否则它们的性能会严重下降。本文研究了目标容器(包括object query和reference point)的随机初始化主要负责多次迭代的需求。基于论文的发现提出了Efficient DETR,这是一种用于端到端目标检测的简单高效的管道。通过利用密集检测和稀疏集合检测,Efficient DETR在初始化目标容器之前利用密集先验,并消除了1解码器结构和6解码器结构之间的差距。在MS COCO上进行的实验表明,本文的方法仅具有3个编码器层和1个解码器层,与最先进的目标检测方法相比,可以获得具有竞争力的性能。Efficient DETR在拥挤的场景中也很强大。它在CrowdHuman数据集上大大优于当期检测器。

实验结果如下:

Dynamic DETR(ICCV 2021)
本文提出了一种新的Dynamic DETR(Transfomrer检测)方法,将动态注意力引入DETR的编码器和解码器阶段,以打破其在小特征分辨率和训练收敛慢方面的两个限制。为了解决第一个限制,这是由于Transformer编码器中的自注意力模块的二次计算复杂性,论文提出了一种动态编码器,以使用具有各种注意力类型的基于卷积的动态编码器来近似Transformer编码器的注意力机制。这种编码器可以基于诸如尺度重要性、空间重要性和表示(即,特征维度)重要性的多个因素来动态调整注意力。为了减轻学习难度的第二个限制,论文引入了一个动态解码器,通过在Transformer解码器中使用基于ROI的动态注意力来替换交叉注意力模块。这种解码器有效地帮助Transfomrer从coarse-to-fine地关注ROI,并显著降低学习难度,从而实现更快的收敛。论文进行了一系列实验来证明我们的优势。Dynamic DETR显著缩短了训练时间(减少了14倍),但性能要好得多(mAP提升3.6)。

本文的主要贡献如下:
提出了一种新的Dynamic DETR方法,它相干地结合了基于动态卷积的编码器和基于动态Transformer的解码器。该方法显著提高了目标检测头的表示能力和学习效率,而无需任何计算开销。
与原始的DETR相比,Dynamic DETR大大减少了训练时间(减少了14倍),但却显著提高了性能(3.6 mAP),如图1所示;
是第一个在标准1x设置中实现优于传统性能的端到端方法,采用ResNet-50主干,42.9mAP。

实验结果如下:

结构重新设计
Rethinking Transformer-based Set Prediction for Object Detection(ICCV 2021)
代码链接:GitHub: Let’s build from hereEdward-Sun/TSP-Detection
DETR是最近提出的一种基于Transformer的方法,它将目标检测视为一个集合预测问题,并实现了最先进的性能,但需要额外的训练时间来收敛。本文研究了DETR训练中优化困难的原因,揭示了导致DETR缓慢收敛的几个因素,主要是匈牙利损失和Transformer中co-attention的问题。为了克服这些问题,本文提出了两种解决方案,即TSP-FCOS(使用FCOS的基于Transformer的集合预测)和TSP-RCNN(使用RCNN的基于Transformer集合预测)。实验结果表明,所提出的方法不仅比原始DETR收敛更快,而且在检测精度方面显著优于DETR和其他基线。
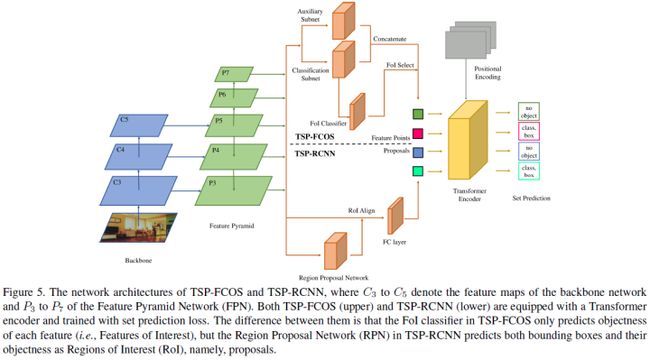
TSP-FCOS:在backbone和encoder之间加上了head;
TSP-RCNN:在backbone和encoder之间加上了RoIAlign;
实验结果如下:
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection(NeurIPS 2021)
代码链接:GitHub - hustvl/YOLOS: You Only Look at One Sequence (NeurIPS 2021)
Transformer能否在对2D空间结构了解最少的情况下,从纯sequence-to-sequence的角度进行2D目标和区域级别的识别?为了回答这个问题,论文提出了“你只看一个序列”(YOLOS),这是一系列基于朴素视觉Transformer的目标检测模型,具有最少的可能修改、区域优先级以及目标任务的归纳偏差。论文发现只有在中型ImageNet-1k数据集上预训练的YOLOS才能在COCO目标检测基准上获得相当有竞争力的性能,例如,直接采用BERT-Base架构的YOLOS-Base可以在COCO值上获得42.0 box AP。论文还通过YOLOS讨论了当前预训练方案和Transformer模型缩放策略的影响和局限性。

本文的主要贡献如下:
使用中等大小的ImageNet-1k[51]作为唯一的预训练数据集,并表明可以成功地迁移到普通ViT[21],以执行复杂的目标检测任务,并在COCO[36]基准上以最少的可能修改(即,only looking at one sequence(YOLOS))输出有竞争力的结果;
首次证明,通过将固定大小的非重叠图像块序列作为输入,可以以纯序列到序列的方式完成2D目标检测。在现有的物体检测器中,YOLOS利用最小的2D感应偏置。
对于朴素ViT,论文发现目标检测结果对预训练方案非常敏感,并且检测性能远未饱和。因此,所提出的YOLOS也可以作为一项具有挑战性的基准任务,以评估不同的(标签监督和自监督)ViT预训练策略。
实验结果如下:

匹配优化
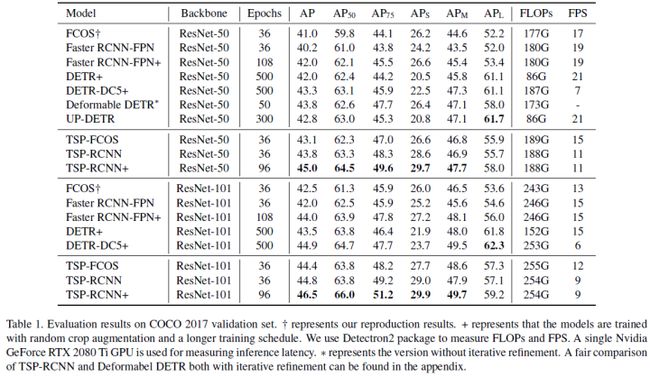
DN-DETR(CVPR 2022)
代码链接:https://github.com/FengLi-ust/DN-DETR
本文提出了一种新的去噪训练方法,以加速DETR(DEtection TRansformer)训练,并加深了对类DETR方法的收敛慢问题的理解。本文认为收敛缓慢是由于二分匹配的不稳定性导致的,这在早期训练阶段导致了不一致的优化目标。为了解决这个问题,除了匈牙利损失外,论文还将带有噪声的GT框输入Transformer解码器,并训练模型以重建原始框,这有效地降低了二分匹配的难度,并可以更快的收敛。本文的方法是通用的,可以通过添加几十行代码轻松地插入到任何类DETR的方法中,以实现显著的改进。因此,DN-DETR在相同的设置下产生了显著的改进(+1.9AP)。与相同设置下的基线相比,DN-DETR在50%的训练时间内实现了可比的性能。

本文的主要贡献如下:
设计了一种新的训练方法来加速DETR训练。实验结果表明,我们的方法不仅加快了训练收敛,而且导致了显著更好的训练结果—在12个epoch设置下,在所有检测算法中获得最佳结果。此外,我们的方法显示出比基线DAB-DETR显著的改进(+1.9AP),并且可以很容易地集成到其他类DETR的方法中;
从一个新的角度分析了DETR的缓慢收敛,并对DETR训练有了更深入的理解。设计了一个度量来评估二分匹配的不稳定性,并验证了我们的方法可以有效地降低不稳定性;
进行了一系列消融研究,以分析我们模型中不同组件的有效性,如噪声、标签嵌入和注意力mask。
实验结果后如下:
DINO
代码链接:https://github.com/IDEACVR/DINO
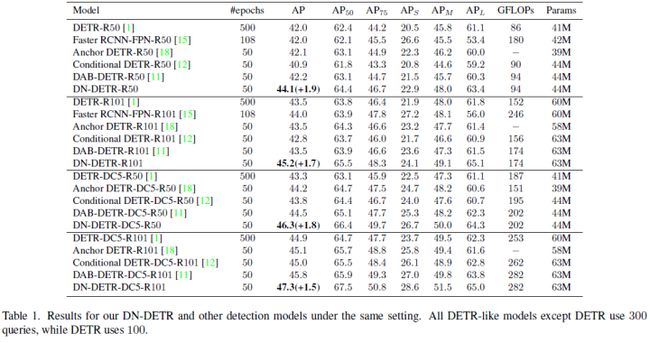
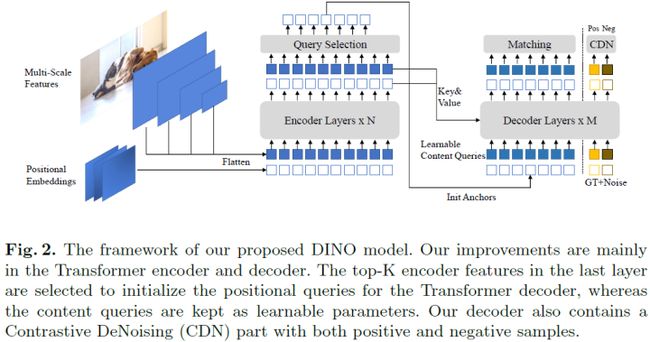
本文提出DINO,这是一种先进的端到端目标检测器。DINO通过使用对比的去噪训练方法、anchor初始化的混合query选择方法和box预测的look forward twice方案,在性能和效率上改进了以前的类DETR模型。DINO在具有ResNet-50主干和多尺度特征的COCO上实现了12个epoch的49.4 AP和24个epoch的51.3AP,与之前最好的类DETR的模型DN-DETR相比,分别显著提高了+6.0 AP和+2.7 AP。DINO在模型大小和数据大小方面都具有很好的扩展性。没有任何trick,在使用SwinL主干的Objects365数据集上进行预训练后,DINO在COCO val 2017(63.2AP)和测试集(63.3AP)上都获得了最好的结果。与排行榜上的其他模型相比,DINO显著减少了其模型大小和预训练数据大小,同时获得了更好的结果。
本文的主要贡献如下:
设计了一种新的端到端类DETR的目标检测器,采用了几种新技术,包括对比DN训练、混合查询选择,并对DINO模型的不同部分进行了两次前向。
进行了深入的消融研究,以验证DINO中不同设计选择的有效性。因此,DINO通过ResNet-50和多尺度特征在12个epoch内达到49.4AP,在24个epoch内实现51.3AP,显著优于之前最好的类DETR的模型。特别是,在12个epoch训练的DINO在小目标上表现出更显著的改善,提高了+7.5AP。
不用任何trick,DINO可以在公共基准上取得最好的成绩。在使用SwinL[23]主干对Objects365[33]数据集进行预训练后,DINO在COCO val2017(63.2AP)和测试集(63.3AP)基准上都取得了最好的结果。据我们所知,这是端到端Transformer检测首次在COCO排行榜上超过最先进(SOTA)模型[1]。实验结果如下:


往期回顾
一文详解视觉Transformer在CV中的现状、趋势和未来方向(分类/检测/分割/多传感器融合)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
