遥感图像语义分割比赛整理
好久没有写博客了(最近有两篇论文的投稿,到年前就没啥时间),寒假期间参加了一个遥感图像分割的比赛:一次不是很成功的参赛,第一次参加这种比赛吧,过程十分坎坷。本来就是在初赛ddl前10天才找到队友,然后在成功组队的第三天,被队友鸽了,只剩下我carry另一个。强撑着坚持到了初赛结束,名次100/234,极限操作,真的很不容易。本文主要想简单总结下,对大家估计没啥借鉴意义,但是对我这个小白来说还是能学习一下代码以及相关框架的使用,也希望能为自己之后的比赛积累些经验…
文章目录
- 比赛介绍
- 一、数据集
- 二、模型选择
-
-
- 1.Unet++
- 2.SwinUnet
- 3.HRNet+OCR
-
- 三、提升性能方法
- 四、实验结果
- 五、评价指标
- 总结
比赛介绍
1、背景
地物要素分类是地物第五要素观测与测绘的重要手段之一,然而目前地物要素的提取方法主要依赖人工,效率低且成本高昂,急需通过先进的算法提高精度并使其自动化。充分运用智能算法与大数据技术突破遥感影像的信息提取与分析瓶颈,不仅是业务端的迫切需要,更是一个企业在数据时代打造数字化业务的重要标杆。
2、任务
基于赛事官方提供的数据及建模分析平台,参赛者需要对光学遥感图像中各类光谱信息和空间信息进行分析,将遥感图像进行土地类型语义分割处理,为图像中具有语义信息的各个像元赋予语义类别标签。
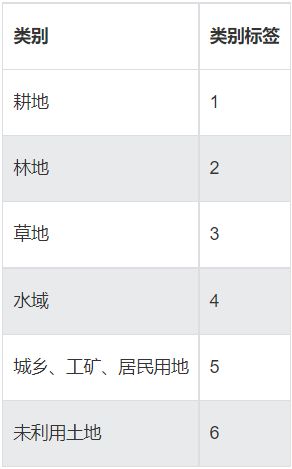
主要有以下6个类别:
一、数据集
- 初赛训练集:
数据集大小: 5000张tif图像
下载链接:训练集下载链接
提取码:6jvv - 初赛测试集:
数据集大小:2000张tif图像
下载链接:测试集下载链接
提取码:t3yw - 数据集可视化:
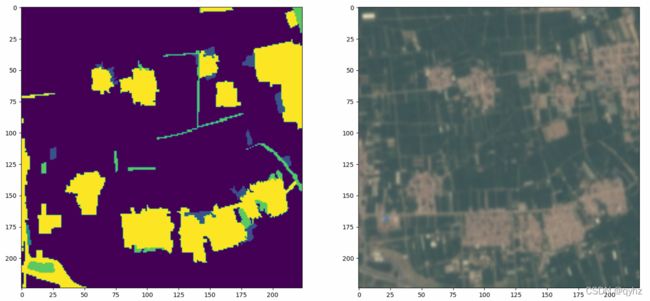
训练集图像和标签:
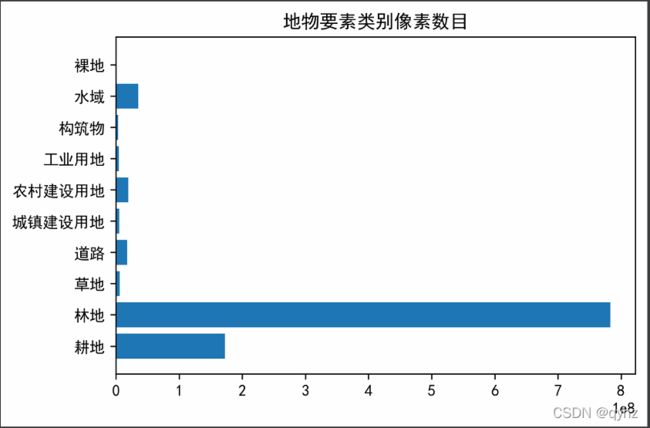
各个地物要素类别的像素数目比例:
相应的代码:
gendi_num, lindi_num, caodi_num, shuiyu_num, chengxiang_num, others_num = 0, 0, 0, 0, 0, 0
for label_path in label_paths:
label = cv2.imread(label_path)
gendi_num += np.sum(label == 1)
lindi_num += np.sum(label == 2)
caodi_num += np.sum(label == 3)
shuiyu_num += np.sum(label == 4)
chengxiang_num += np.sum(label == 5)
others_num += np.sum(label == 6)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示的问题
plt.rcParams['axes.unicode_minus'] = False
classes = ('耕地', '林地', '草地', '水域', '城乡、工矿、居民用地', '未利用土地')
numbers = [gendi_num, lindi_num, caodi_num, shuiyu_num, chengxiang_num, others_num]
plt.barh(classes, numbers)
for i, v in enumerate(numbers):
plt.text(v, i, str(round(v / label.size / len(label_paths) * 100, 1)) + "%", verticalalignment="center")
plt.title('类别数目')
plt.xlabel('像素数量')
plt.ylabel('类别')
plt.show()
可以看出各个类别分布是不均衡的,其中林地和耕地相对占的比重最大,其余类别所占比重较小,如何对这种类别分布不平衡的数据进行处理是面临的第一个问题。
- 数据集处理:
官方版本:
官方代码的dataset是直接读取的tif文件,对训练集和测试集分别进行了相应的数据增强。这里我学习的地方主要有两点:
(1) 如何读取.tif文件
(2) 如何对图像和label同时进行数据增强
img = cv2.imread(self.image_paths[index], cv2.IMREAD_UNCHANGED)
import albumentations as A
A.Compose([
A.RandomResizedCrop(CFG.img_size, CFG.img_size),
A.Transpose(p=0.5),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.ShiftScaleRotate(p=0.25),
A.RandomRotate90(p=0.25),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=1023.0, p=1.0), #注意这里的最大像素是1023
ToTensorV2(p=1.0),
], p=1.)
class MyDataset(Dataset):
def __init__(self, image_paths, label_paths, transforms=None, mode='train'):
self.image_paths = image_paths
self.label_paths = label_paths
self.transforms = transforms
self.mode = mode
self.len = len(image_paths)
def __getitem__(self, index):
img = cv2.imread(self.image_paths[index], cv2.IMREAD_UNCHANGED)
if self.mode == "train":
label = cv2.imread(self.label_paths[index], 0) - 1 #提交的是从1才代表耕地类别,模型类别是从0开始,所以-1
augments = self.transforms(image=img, mask=label) #可以同时对image和label进行transform变换
return augments['image'], augments['mask'].to(torch.int64)
elif self.mode == "test":
augments = self.transforms(image=img)
return augments['image']
def __len__(self):
return self.len
实验版本:
在具体实验中,将tif格式转为了jpg的格式并进行保存,代码如下:
def tifs2jpgs(src_dir, dst_dir):
def tif2jpg(tif_path, lower_percent=0.6, higher_percent=99.4):
ds = gdal.Open(tif_path, gdal.GA_ReadOnly)
origin_label = np.empty(shape=(ds.RasterYSize, ds.RasterXSize, ds.RasterCount),
dtype='float64')
for i in range(ds.RasterCount):
band = ds.GetRasterBand(ds.RasterCount - i)
origin_label[:, :, i] = band.ReadAsArray()
label = np.zeros_like(origin_label, dtype='uint8')
for i in range(origin_label.shape[2]):
l, h = 0, 255
l_cut, h_cut = np.percentile(origin_label[:, :, i], lower_percent), \
np.percentile(origin_label[:, :, i], higher_percent)
channel = l + (origin_label[:, :, i] - l_cut) * (h - l) / (h_cut - l_cut)
channel[channel < l] = l
channel[channel > h] = h
label[:, :, i] = channel
return label
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
tif_path_list = glob.glob(os.path.join(src_dir, '*.tif'))
for tif_path in tif_path_list:
name = str(tif_path.split(os.sep)[-1]).split('.')[0]
cv2.imwrite(os.path.join(dst_dir, f'{name}.jpg'), tif2jpg(tif_path))
二、模型选择
1.Unet++
官方提供的代码中使用的是Unet++,在使用时,直接调用现有的库里面Unet++的接口即可(之前一直都是写网络去实现,很麻烦,像这种比较简单使用的比较多的网络,并且不需要进行修改,以后直接用现成的:
import segmentation_models_pytorch as smp
segmentation_models_pytorch库除了封装了如Unet++,Unet,Deeplab系列的实现,还有如DiceLoss, SoftCrossEntropyLoss, LovaszLoss等,都可以直接调用。
Unet++类的实现:
class MyModel(nn.Module):
def __init__(self, num_classes=5):
super().__init__()
self.model = smp.UnetPlusPlus(
encoder_name="resnet34", //encoder网络
encoder_weights="imagenet", //预训练权重加载
in_channels=3, //输入通道数
decoder_attention_type="scse", //decoder中attention类型
classes=num_classes, //分割类别
)
def forward(self, x):
out = self.model(x)
return out
2.SwinUnet
SwinUnet的具体介绍见我上一篇博文:
https://blog.csdn.net/weixin_43788575/article/details/121074755?
SwinUnet在医学图像分割上表现的很好,并且有预训练模型(224*224),于是想在遥感图像上验证下效果。
3.HRNet+OCR
由于针对于遥感图像分割的特定网络不多,因此选择了在cityscapes表现最sota的网络。在Cityscapes test数据集上mIOU排行如下:

其中表现最好的为HRNet+OCR。
HRNet:
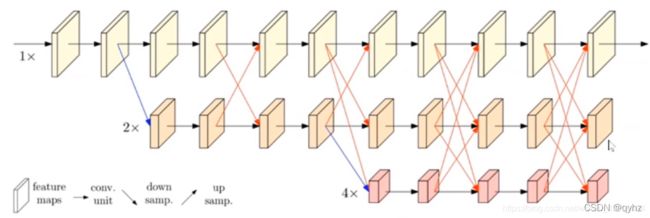
传统的分割网络结构如Unet系列,SegNet等都是encoder部分下采样降分辨率,decoder部分上采样的过程。作者认为在encoder下采样降低分辨率的过程中会损失比较多的信息,因此设计将原来的串行结构改为并行结构,通过插值或者stride=2的3*3卷积实现不同分支之间的交互融合。显然,这种网络结构的设计虽然增加了参数量和计算量,但是很大程度上减少了信息损失,融合了多尺度的信息,提升了性能。
OCR:
在分割网络设计过程中考虑上下文信息可以提高分割的精度。PSPNet和ASPPNet等通过空洞卷积增加感受野来提取上下文信息,然而这种方式不能给待分割的像素准确地提供同类别的上下文信息,影响了分割性能。

解决方法关键在于首先用base_network提取各个类别的特征表示,再用待分割像素与各个类别的表征进行相似度计算并进行加权,得到增强后的特征。
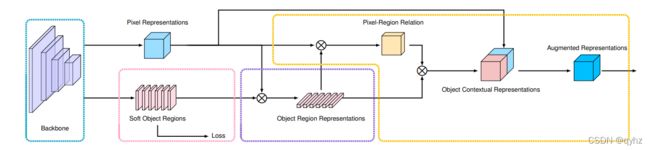
如上图所示,整个过程分为以下几步:
(1) 根据网络中间层的特征表示估测一个粗略的语义分割结果作为 OCR 方法的一个输入 ,即Soft Object Regions。
(2) 根据粗略的语义分割结果和网络最深层的特征表示计算出 K 组向量,即物体区域表示(Object Region Representations),其中每一个向量对应一个语义类别的特征表示。
(3) 计算网络最深层输出的像素特征表示(Pixel Representations)与计算得到的物体区域特征表示(Object Region Representation)之间的关系矩阵,然后根据每个像素和物体区域特征表示在关系矩阵中的数值把物体区域特征加权求和,得到最后的物体上下文特征表示 OCR (Object Contextual Representation) 。
(4)当把物体上下文特征表示 OCR 与网络最深层输入的特征表示拼接之后作为上下文信息增强的特征表示(Augmented Representation),可以基于增强后的特征表示预测每个像素的语义类别。
在代码实现时,发现该网络已经被收入openseg/mmseg中。一种可以下载mmseg,安装mmcv,里面确实包含了很多网络结构,对于比赛来说是很友好的,关于mmseg/mmdetection的安装使用见博文:
https://blog.csdn.net/weixin_43788575/article/details/119773280?spm=1001.2014.3001.5502
如果想比较方便地训练某一个网络,也可以在外部直接调用,代码如下:
import warnings
warnings.filterwarnings('ignore')
import paddle
import paddleseg
from paddleseg import transforms as T
from paddleseg.core import train
from paddleseg.models import MixedLoss, CrossEntropyLoss, LovaszSoftmaxLoss
train_transforms = [
T.ResizeStepScaling(min_scale_factor=0.8, max_scale_factor=1.2, scale_step_size=0.1),
T.RandomHorizontalFlip(0.5),
T.RandomVerticalFlip(0.5),
T.RandomDistort(
brightness_range=0.2, brightness_prob=0.5,
contrast_range=0.2, contrast_prob=0.5,
saturation_range=0.2, saturation_prob=0.5,
hue_range=15, hue_prob=0.5),
T.RandomPaddingCrop(crop_size=(256, 256)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
eval_transforms = [
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
num_classes = 6
train_dataset = paddleseg.datasets.Dataset(
mode='train',
num_classes=num_classes,
dataset_root='data',
train_path='data/train_list.txt',
transforms=train_transforms)
eval_dataset = paddleseg.datasets.Dataset(
mode='val',
num_classes=num_classes,
dataset_root='data',
val_path='data/val_list.txt',
transforms=eval_transforms)
backbone = paddleseg.models.backbones.HRNet_W48(
pretrained='https://bj.bcebos.com/paddleseg/dygraph/hrnet_w48_ssld.tar.gz',
has_se=True)
model = paddleseg.models.OCRNet(
num_classes=num_classes,
backbone=backbone,
backbone_indices=(0,),
pretrained='https://bj.bcebos.com/paddleseg/dygraph/ccf/ocr_hrnetw48_rs_256x256_160k/model.pdparams')
iters = 120000
train_batch_size = 4
learning_rate = 0.002
decayed_lr = paddle.optimizer.lr.PolynomialDecay(
learning_rate=learning_rate,
decay_steps=iters,
power=0.9,
end_lr=0.0)
optimizer = paddle.optimizer.Momentum(
learning_rate=decayed_lr,
momentum=0.9,
weight_decay=paddle.regularizer.L2Decay(1e-4),
parameters=model.parameters())
losses = {
'types': [
MixedLoss([CrossEntropyLoss(), LovaszSoftmaxLoss()], [0.8, 0.2]),
MixedLoss([CrossEntropyLoss(), LovaszSoftmaxLoss()], [0.8, 0.2])
],
'coef': [1, 0.4]
}
train(
train_dataset=train_dataset,
val_dataset=eval_dataset,
model=model,
optimizer=optimizer,
losses=losses,
iters=iters,
batch_size=train_batch_size,
save_interval=1000,
log_iters=100,
num_workers=0,
save_dir='output/OCRNet_HRNetW48_120k',
use_vdl=True)
主要需要定义以下几项:
- 数据增强方式
- 训练/验证数据集
- 选用的backbone/model
- 学习率下降策略/优化器
- loss选择
三、提升性能方法
尝试过的方法如下:
- 引入LovaszSoftmaxLoss
LovaszSoftmaxLoss具体原理有待学习,不过精度确实有提高。 - 在backbone中加入attention
在mmseg中实现起来比较简单,只需要设置相应的参数即可,如下:
其中has_se设置为True即可。
backbone = paddleseg.models.backbones.HRNet_W48(
pretrained='https://bj.bcebos.com/paddleseg/dygraph/hrnet_w48_ssld.tar.gz',
has_se=True)
- K折交叉验证
这里也学习了下,在深度学习的网络训练过程中如何使用K折交叉验证。之前接触都是在机器学习算法中使用交叉验证,同样是调用sklearn.model_selection库,代码如下:
from sklearn.model_selection import train_test_split, GroupKFold, StratifiedKFold, KFold
train_image_paths = np.array(train_image_paths)
train_label_paths = np.array(train_label_paths)
test_image_paths = np.array(test_image_paths)
# eda_visual(train_image_paths, train_label_paths) # 可视化图片和标签
folds = KFold(n_splits=CFG.n_fold, shuffle=True, random_state=CFG.seed).split(range(len(train_image_paths)),
range(len(train_label_paths))) # 多折
for fold, (trn_idx, val_idx) in enumerate(folds):
# if fold > 1: # 示例代码仅呈现前两个fold的训练结果
# break
print(f"===============training fold_nth:{fold + 1}======================")
train_dataset = MyDataset(train_image_paths[trn_idx], train_label_paths[trn_idx], get_train_transforms(),
mode='train')
val_dataset = MyDataset(train_image_paths[val_idx], train_label_paths[val_idx], get_val_transforms(),
mode='train')
train_loader = DataLoader(train_dataset, batch_size=CFG.batch_size, shuffle=True, num_workers=0)
val_loader = DataLoader(val_dataset, batch_size=CFG.batch_size * 2, shuffle=False, num_workers=0)
在每一折模型训练时,都需要重新声明网络,优化器,loss等。同时要注意记录每一折在验证机上表现的最好的模型参数。
- TTA:Test-Time Augmentation
在mmseg中实现起来也比较简单,同样进行相关参数的设置即可。具体思路为对测试图像进行平移、旋转等数据增强,对预测的结果进行逆操作,将几种通过以上方法得到的测试结果进行取平均,得到最后的分割mask:
from paddleseg.core import predict
predict(
model=model,
model_path=params_path,
transforms=eval_transforms,
image_list=test_path_list,
save_dir='predict',
custom_color=[1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6],
aug_pred=True,
flip_vertical=True,
flip_horizontal=True)
// 首先需要设置aug_pred为True,flip_vertical和flip_horizonal设置为true才有效
待尝试方法:
- 模型ensemble
这边主要是在模型预测时进行投票,至少三个模型参与投票,代码如下:
import numpy as np
import cv2
import argparse
RESULT_PREFIXX = ['./result1/','./result2/','./result3/']
# each mask has 5 classes: 0~4
def vote_per_image(image_id):
result_list = []
for j in range(len(RESULT_PREFIXX)):
im = cv2.imread(RESULT_PREFIXX[j]+str(image_id)+'.png',0)
result_list.append(im)
# each pixel
height,width = result_list[0].shape
vote_mask = np.zeros((height,width))
for h in range(height):
for w in range(width):
record = np.zeros((1,5))
for n in range(len(result_list)):
mask = result_list[n]
pixel = mask[h,w]
#print('pix:',pixel)
record[0,pixel]+=1
label = record.argmax()
#print(label)
vote_mask[h,w] = label
cv2.imwrite('vote_mask'+str(image_id)+'.png',vote_mask)
vote_per_image(3)
- 对于数量较少的类别训练二分类模型
找到了一篇写的非常好的比赛总结,解决了类别不平衡的问题:
https://cloud.tencent.com/developer/article/1798821
四、实验结果
由于时间比较紧张,实验做得不是很充分:
| Methods | FWIOU |
|---|---|
| Unet++ + TTA + 2 Fold + scse + (Dice, softcrossentropy) | 0.730 |
| SwinUnet + TTA + 2 Fold + scse + (Dice, softcrossentropy) | <0.700 |
| HRNet + OCR + (CrossEntropy, LovaszSoftmax) | 0.744 |
| HRNet + OCR + TTA + (CrossEntropy, LovaszSoftmax) | 0.748 |
推荐参考的遥感图像分割的比较好的方法总结,基本上都是飞桨的遥感图像分割的常规赛前几名的方案:
- https://aistudio.baidu.com/aistudio/projectdetail/3227402
- https://aistudio.baidu.com/aistudio/projectdetail/2324953?channelType=0&channel=0
- https://aistudio.baidu.com/aistudio/projectdetail/1911200?channelType=0&channel=0
五、评价指标
FWIOU: 在MIoU上的基础上做的提升,对每一个类根据出现的频率为其设置权重。
实现代码:
def Frequency_Weighted_Intersection_over_Union(confusion_matrix):
freq = np.sum(confusion_matrix, axis=1) / np.sum(confusion_matrix)
iu = np.diag(confusion_matrix) / (
np.sum(confusion_matrix, axis=1) + np.sum(confusion_matrix, axis=0) -
np.diag(confusion_matrix))
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU
def _generate_matrix(gt_image, pre_image, num_class):
mask = (gt_image >= 0) & (gt_image < num_class)
label = num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=num_class ** 2)
confusion_matrix = count.reshape(num_class, num_class)
return confusion_matrix
总结
虽然这次比赛很多东西还来不及尝试,硬件资源也跟不上(无奈)…但是还是有收获的一周。这次经历也为之后的参赛积累了经验和教训,加油加油!!