python文本分析和提取_Python文本特征抽取与向量化算法学习
本文为大家分享了Python文本特征抽取与向量化的具体代码,供大家参考,具体内容如下
假设我们刚看完诺兰的大片《星际穿越》,设想如何让机器来自动分析各位观众对电影的评价到底是“赞”(positive)还是“踩”(negative)呢?
这类问题就属于情感分析问题。这类问题处理的第一步,就是将文本转换为特征。
因此,这章我们只学习第一步,如何从文本中抽取特征,并将其向量化。
由于中文的处理涉及到分词问题,本文用一个简单的例子来说明如何使用Python的机器学习库,对英文进行特征提取。
1、数据准备
Python的sklearn.datasets支持从目录读取所有分类好的文本。不过目录必须按照一个文件夹一个标签名的规则放好。比如本文使用的数据集共有2个标签,一个为“net”,一个为“pos”,每个目录下面有6个文本文件。目录如下所示:
neg
1.txt
2.txt
......
pos
1.txt
2.txt
....
12个文件的内容汇总起来如下所示:
neg:
shit.
waste my money.
waste of money.
sb movie.
waste of time.
a shit movie.
pos:
nb! nb movie!
nb!
worth my money.
I love this movie!
a nb movie.
worth it!
2、文本特征
如何从这些英文中抽取情感态度而进行分类呢?
最直观的做法就是抽取单词。通常认为,很多关键词能够反映说话者的态度。比如上面这个简单的数据集,很容易发现,凡是说了“shit”的,就一定属于neg类。
当然,上面数据集是为了方便描述而简单设计的。现实中一个词经常会有穆棱两可的态度。但是仍然有理由相信,某个单词在neg类中出现的越多,那么他表示neg态度的概率越大。
同样我们注意到有些单词对情感分类是毫无意义的。比如上述数据中的“of”,“I”之类的单词。这类词有个名字,叫“Stop_Word”(停用词)。这类词是可以完全忽略掉不做统计的。显然忽略掉这些词,词频记录的存储空间能够得到优化,而且构建速度也更快。
把每个单词的词频作为重要的特征也存在一个问题。比如上述数据中的”movie“,在12个样本中出现了5次,但是出现正反两边次数差不多,没有什么区分度。而”worth“出现了2次,但却只出现在pos类中,显然更具有强烈的刚晴色彩,即区分度很高。
因此,我们需要引入TF-IDF(Term Frequency-Inverse Document Frequency,词频和逆向文件频率)对每个单词做进一步考量。
TF(词频)的计算很简单,就是针对一个文件t,某个单词Nt 出现在该文档中的频率。比如文档“I love this movie”,单词“love”的TF为1/4。如果去掉停用词“I"和”it“,则为1/2。
IDF(逆向文件频率)的意义是,对于某个单词t,凡是出现了该单词的文档数Dt,占了全部测试文档D的比例,再求自然对数。
比如单词“movie“一共出现了5次,而文档总数为12,因此IDF为ln(5/12)。
很显然,IDF是为了凸显那种出现的少,但是占有强烈感情色彩的词语。比如“movie”这样的词的IDF=ln(12/5)=0.88,远小于“love”的IDF=ln(12/1)=2.48。
TF-IDF就是把二者简单的乘在一起即可。这样,求出每个文档中,每个单词的TF-IDF,就是我们提取得到的文本特征值。
3、向量化
有了上述基础,就能够将文档向量化了。我们先看代码,再来分析向量化的意义:
# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)
运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
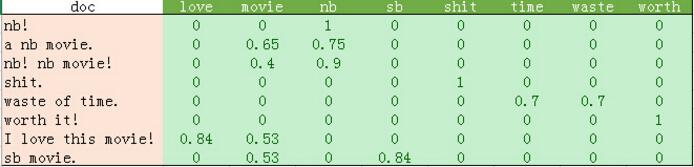
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3、count_vec.fit_transform的结果是一个巨大的矩阵。我们可以看到上表中有大量的0,因此sklearn在内部实现上使用了稀疏矩阵。本例子数据较小。如果读者有兴趣,可以试试机器学习科研工作者使用的真实数据,来自康奈尔大学:http://www.cs.cornell.edu/people/pabo/movie-review-data/。这个网站提供了很多数据集,其中有几个2M左右的数据库,正反例700个左右。这样的数据规模也不算大,1分钟内还是可以跑完的,建议大家试一试。不过要注意这些数据集可能存在非法字符问题。所以在构造count_vec时,传入了decode_error = 'ignore',以忽略这些非法字符。
上表的结果,就是训练8个样本的8个特征的一个结果。这个结果就可以使用各种分类算法进行分类了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。