用python实现神经网络
一、BP神经网络
这里介绍目前常用的BP神经网络,其网络结构及数学模型如下: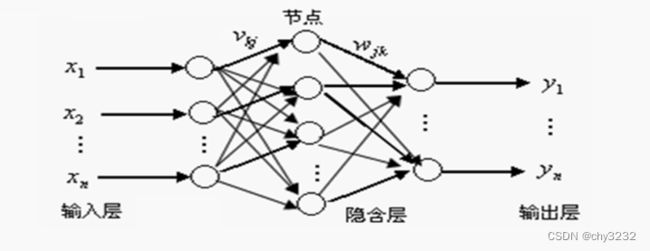
x为 n 维向量, y 为 n 维向量,隐含层有 q 个神经元。假设 N 有个样本数据,,,=1,2,…{y(t),x(t),t=1,2,…N}。从输入层到隐含层的权重记为: (=1,2,..,,=1,2,…)W_ki (k=1,2,..,q,i=1,2,…n),从隐含层到输出层的权重记为:=1,2,…,=1,2,… W_ki (k=1,2,…q,i=1,2,…n) 。
1)以澳大利亚信贷批准数据集为例,介绍Python神经网络分类模型的应用。具体计算流程及思路如下:
1.数据获取及训练样本、测试样本的划分
2.神经网络分类模型构建
(1)导入神经网络分类模块MLPClassifier。
from sklearn.neural_network import MLPClassifier
(2)利用MLPClassifier创建神经网络分类对象clf。
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5,2), random_state=1)
参数说明:
Solver:神经网络优化求解算法,包括lbfgs、sgd、adam三种,默认为adam
Alpha:模型训练误差,默认为0.0001
Hidden_layer_sizes:隐含层神经元个数,如果是单层神经元,设置其具体数值即可,本例中隐含层有两层,为5*2.
random_state:默认设置为1即可。
(3)调用clf对象中的fit()方法进行网络训练。
clf.fit(x, y)
(4)调用clf对象中的score ()方法,获得神经网络的预测准确率(针对训练数据)
rv=clf.score(x,y)
(5)调用clf对象中的predict()方法可以对测试样本进行预测,获得其预测结果
R=clf.predict(x1)
示例代码如下:
import pandas as pd
data = pd.read_excel('credit.xlsx')
x = data.iloc[:600,:14].as_matrix()
y = data.iloc[:600,14].as_matrix()
x1= data.iloc[600:,:14].as_matrix()
y1= data.iloc[600:,14].as_matrix()
from sklearn.neural_network import MLPClassifier
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5,2), random_state=1)
clf.fit(x, y);
rv=clf.score(x,y)
R=clf.predict(x1)
Z=R-y1
Rs=len(Z[Z==0])/len(Z)
print('预测结果为:',R)
print('预测准确率为:',Rs)
执行结果如下:
预测结果为: [0 1 1 1 1 0 0 1 0 1 1 0 0 0 1 1 0 0 0 1 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 1 1 0 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 1 0 0 1 0 1 1 0 0 1 0]
预测准确率为: 0.8222222222222222
2)以5.3.3中的发电场数据为例,预测AT=28.4,V=50.6,AP=1011.9,RH=80.54时的PE值。其计算流程及思路如下:
1.数据获取及训练样本构建
其中训练样本的特征输入变量用x表示,输出变量用y表示。
import pandas as pd
data = pd.read_excel('发电场数据.xlsx')
x = data.iloc[:,0:4]
y = data.iloc[:,4]2.预测样本的构建
其中预测样本的输入特征变量用x1表示
import numpy as np
x1=np.array([28.4,50.6,1011.9,80.54])
x1=x1.reshape(1,4)3.神经网络回归模型构建
(1)导入神经网络回归模块MLPRegressor。
from sklearn.neural_network import MLPRegressor(2)利用MLPRegressor创建神经网络回归对象clf。
clf = MLPRegressor(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=8, random_state=1)参数说明:
Solver:神经网络优化求解算法,包括lbfgs、sgd、adam三种,默认为adam
Alpha:模型训练误差,默认为0.0001
Hidden_layer_sizes:隐含层神经元个数,如果是单层神经元,设置其具体数值即可,如果是多层,比如隐含层有两层5*2,则hidden_layer_sizes=(5,2).
random_state:默认设置为1即可。
(3)调用clf对象中的fit()方法进行网络训练。
clf.fit(x, y)(4)调用clf对象中的score ()方法,获得神经网络回归的拟合优度(判决系数)。
rv=clf.score(x,y)(5)调用clf对象中的predict()可以对测试样本进行预测,获得其预测结果。
R=clf.predict(x1)示例代码如下:
import pandas as pd
data = pd.read_excel('发电场数据.xlsx')
x = data.iloc[:,0:4]
y = data.iloc[:,4]
from sklearn.neural_network import MLPRegressor
clf = MLPRegressor(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=8, random_state=1)
clf.fit(x, y);
rv=clf.score(x,y)
import numpy as np
x1=np.array([28.4,50.6,1011.9,80.54])
x1=x1.reshape(1,4)
R=clf.predict(x1)
print('样本预测值为:',R)
输出结果为:
样本预测值为: [ 439.27258187]