基于现代深度学习的目标检测方法综述
论文地址:A Survey of Modern Deep Learning based Object Detection Models
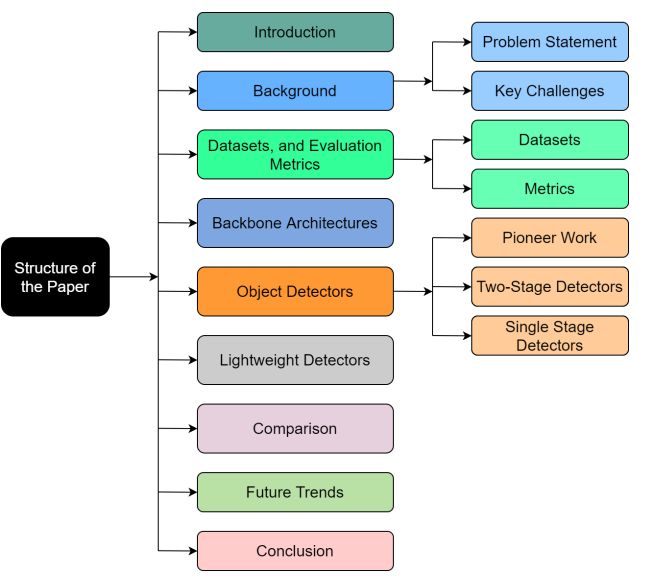
论文结构:
一、论文亮点(与其他综述不同):
1、深度分析了两类检测方法:单步和两步检测,并从历史的角度分析;
2、详细的评估了重要的体系结构和轻量化模型。
二、背景
1、目标:识别出图像中所有物体并用框出
2、挑战:
1)内类差异:同一物体的不同形态,或被环境影响;
2)过多的分类量:需要更多的带标签数据集;
3)效率:需要更强的算力,尤其是随着移动设备和边缘设备的普及
三、数据集和评估标准
1、数据集
1)PASCAL VOC:2005年产生。11k图片,27k标签,20种类,提出mAP在0.5 IoC评估模型;
2)ILSVRC :ImageNet的数据集,包含1百万图片,1000种类(其中50万图片,200个种类是手工选出的)。通过减小IoC的门槛来帮助小目标检测;
3)MS-COCO:2015年微软制作,包含2百万图片,每张图片平均包含3.5个种类和7.7个实例,评价标准更严格,把IoC从0.5到0.95每步长为0.5分一个等级;
4)Open Image:2017年谷歌制作,包含9百余万图片,其中1.9百万的图片中有16百万边界框和600个种类,特点是忽略未注释的类,类的检测要求类及其子类等。
上述数据集倾斜问题:Pascal VOC, MS-COCO, 和Open Images 中人和车等数量最多前五类相比其他数据数量不平衡,其他数据数量太少了。ImageNet 数据集中数据数量最多的是考拉和键盘,它们在现实世界中并不是最常见的。
2、标准
FPS:frames per second,每秒图片(处理的数量);
IoU:检测到的边界框区域与实际边界框区域的相交面积;
准确率:(Precision)TP/TP+FP
召回率:(Recall)TP/TP+FN
PR:横纵为Recall,纵轴为Precision的曲线;
AP:PR的面积,越接近1越好;
mAP,所有AP的均值。
四、重要的基础
1、AlexNet:获得2012年ILSVRC冠军,包含8个网络层——五个卷积层和三个全连接层,最后一个全连接层和softmax分类器连接。通过多个卷积核获得图像特征,AlexNet是神经网络火热起来;
2、VGG:包含更多更小的卷积层(16-19个网络层,8-16个卷积层,两个卷积层后接池化层),使参数更少,收敛更快。
3、GoogLeNet/Inception:其他神经网络随着精确度的提升,算力需求也在增加。为此GoogLeNet提出使用局部稀疏连接架构而不是完全连接架构来解决这些问题。它有22个深层网络,由多个Inception模块堆叠在一起;
4、ResNet:其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题;
5、ResNeXt:本质是ResNet,其中的残差网络块被特制的拓扑模块代替,它中间产生的参数更少,赢得2016年ILSVRC冠军;
6、CSPNet:网络结构分为两个网络层:一个是卷积层块,一个卷积层和卷积层块的输出结合。它更容易实现并且削减了重复的梯度;
7、EfficientNet:提出使用一个复合参数来均匀缩放所有三个维度,每一个模块的参数总是有联系。它的精确率和速度都。
五、目标检测方法
1、先前方法
1)Viola-Jones:2001年提出,主要用于人脸识别,首先通过滑动窗口和计算积分图像获取Haar-like特征,然后用Adaboost缩放对特征分类和识别;
2)HOG Detector:把图像分成小的连通区域,叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器;
3)DPM:分而治之的思想,把目标的不同部位分别检测,去除不可能组成目标的部分,然后把它们排列作为检测。
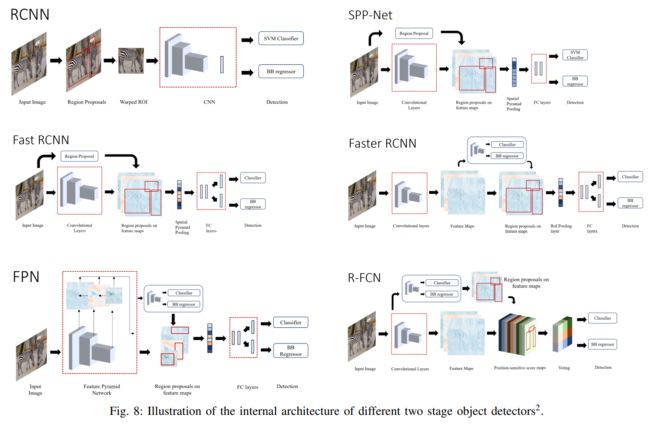
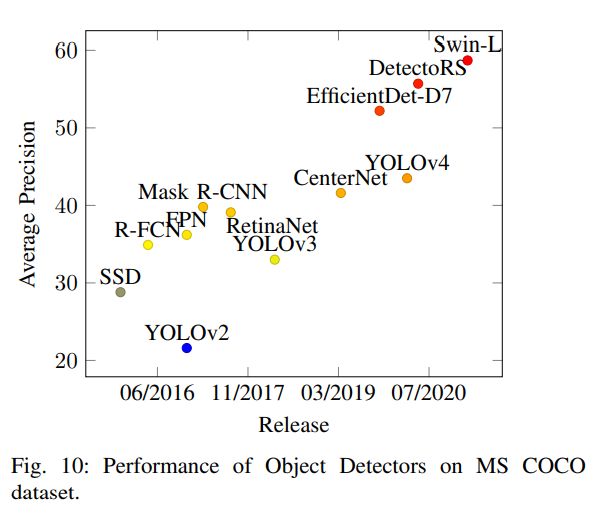
2、两阶段检测器
1)R-CNN:R-CNN分为提取框(selective search生成2000个候选区域)、框提取特征(CNN得到特征向量)、图像分类(SVG)、 非极大值抑制(NMS)四个步骤进行目标检测。不过在特征提取这一步将传统的特征(如 SIFT、HOG 特征等)换成了深度卷积网络提取的特征。速度较慢。
2)SPP-NET:可以输入尺寸不同的图片进行识别,卷积层对尺寸没要求,全连接层需要固定尺寸进行连接,于是在它们之间加上空间金字塔池化层(SSP-NET)得到同一尺寸向量。首先通过SS搜索出的候选框用CNN进行一次特征提取,得到feature maps,在其中找到各个候选框的区域,再对候选框进行SSP,提取出固定长度的特征向量,最后用SVM对特征向量进行分类识别。速度有提升,但也比较慢。
3)fast R-CNN:将整幅图像和region proposal(SS产生)作为输入,经过卷积层提取feature map后,经过RoI pooling后输出固定大小的特征图,然后输入到全连接层,将特征向量分支为两个同级的输出层:一个用于分类,即类别个数+1个Softmax概率估计。另一个用于边框回归,输出检测框位置信息的纠正值。速度较快。
4)faster R-CNN:首先让输入图像经过CNN网络,得到一个feature map,利用Region ProPosal Network(RPN)(不再使用SS)对feature map产生候选框,然后把候选框在feature map的区域经过RoI pooling产生一个尺度固定的特征向量,接着进入全连接层做分类以及边框回归。速度接近实际需求。
5)FPN:FPN(feature pyramid netword)首先对正向传播的feature map下采样得到特征金字塔,然后自顶向下对高层特征进行上采样和对底层特征求和,每层得到特征对其对进行卷积和分类。它使用了更大的feature map(top-down),使得小目标的检测更加有效。
6)R-FCN:输入的图像首先通过ResNet得到feature maps,使其通过RPN得到RoI proposals,最后的输出通过卷积层并输入到分类器和回归器。R-FCN速度比前面模型更快。
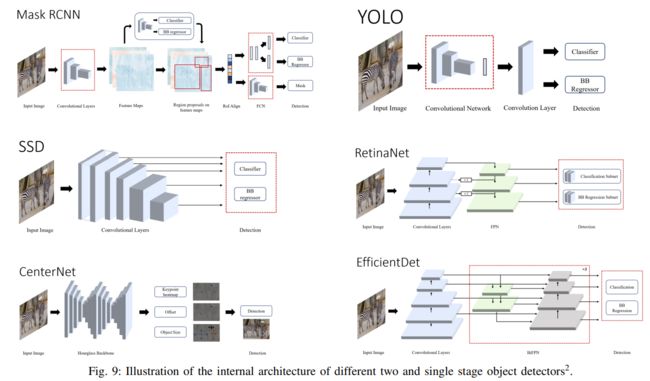
7)Mask R-CNN:类似于Faster R-CNN,它不再使用RoIPooL layer而是RoIAlignlayer。论文作者选用ResNeXt和FPN作为backbone。
8)DetectoRS:宏观层面采用FPN生成的Recursive Feature Pyramid(RFP),微观层面采用Switchable Atrous Convolution (SAC)统一卷积的尺寸。
3、单阶段检测器
1)YOLO:诞生于2016年。输入的图片分成S*S的网格细胞,然后对物体中心所在细胞进行回归检测。速度快,但物体密集或目标小时效果较差。
2)SSD:结构由VGG16和多尺度特征检测网络构成,速度和准确率都好,能够检测较小的物体。
3)YOLOv2和YOLO9000:使用DarkNet19作为主干结构,加入了其他优秀的技术:Batch Normalization加快收敛,分类训练和检测系统增加检测层级,移除全连接层增加速度,使用学习过的锚框提高召回率。YOLO9000能够识别9000个种类。YOLOv2效果更好,并且参数更少。
4)RetinaNet:RetinaNet使用FPN作为backbone,FPN的每一层经过两层子网——分类子网通过物体的位置预测分数,box regression subnet回归偏移量,能够检测不同尺寸的物体大小。两个子网都是小的FCN,并且共享参数。RetinaNet综合表现比较好。
5)YOLOv3:使用DarkNet53作为主干结构提取特征图,借鉴FPN的思想,在高、中、低三个层次上分别预测目标框,更好的检测小尺寸物体。并用加入了data augmentation, multi-scale training, batch normalization等技术,把Softmax分类器换成了逻辑分类器。但是它没有突破性改变,甚至精确率更低。
6)CenterNet:CenterNet把识别物体边界框的中心点而不是整个物体。输入的图像通过FCN生成热力图,热力图的顶峰部位对应着整个检测物体。它使用在ImageNet上预先训练的Hourglass-101作为特征提取器,并且有3个头部——heatmap head决定物体中心,dimension head评估物体的大小,offset head纠正物体点的差额。它精确度高,耗时少,但是需要不同的backbone,并且和其他检测器一起工作时效果不好。
7)EfficientDet:使用EfficientNet作为主干,多层BIFPN(bi-direction FPN)提取特征, 它是根据NAS-FPN改进的,他消除了无效节点,增强高层特征,并且使用SGD优化器和swish激活函数。EfficientDet综合表现很好。
8)YOLOv4:融合了平滑层级标签、CIoC-loss、CmBN、余弦退火调度等多种技术。这些技术会增加训练时间不影响推断时间。YOLOv4使用预先训练的CSPNetDarknet-53作为主干,SPP和PAN作为neck,YOLOv3作为推断头部。YOLOv4训练算力要求不高,是最好的实时检测器。
9)Swin Transformer:Transformer在NLP领域效果很好,近来年也用在了CV领域。Swin Transformer用transformer作为主干,把图像分割为多块,去取重叠部分。图像块经过4个阶段,每个阶段减少块并且维持每层结构。transformer效果比较好,但是参数相对多。
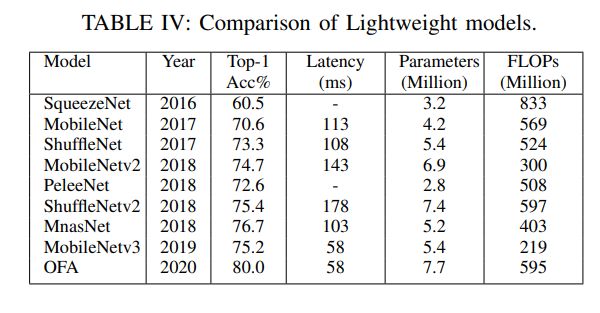
4、轻量化网络
以上方法有令人满意的结果,但是算力要求高不适用于边缘设备,为此通过轻量化模型可以解决这个问题。
1)SqueezeNet:通过更小的过滤器、减小输入通道来减少参数和保持精度,在网络后部放置降采样层提高精度。SqueezeNet由8层fire module构成,每层由挤压层和扩张层构成,都使用的ReLU激活函数。SqueezeNet的模型大小是AlexNet的1/510。
2)MobileNet:由28层分离卷积层构成,每层有批量归一化和ReLU激活函数。此外作者还引入两种模型减少超参数:宽度倍增器减小输入输出通道统一网络,分辨率倍增器改变图像的大小。MobileNet在一些领域效果好,但是它太简单,梯度流的方法少。
3)ShuffleNet:由一个卷积层和多个ShuffleNet构成。ShuffleNet单元结构与ResNet相似,深层卷积由3*3层构成。可由组数和规模参数管理计算量。
4)MobileNetv2:提出了一种新的层模块——具有线性瓶颈的反向残差,能够减少计算和提高精度。它能把低位输入转成高维,用深度卷积过滤,最后投影为低维。MobileNetv2包含一个卷积层,随后是19个剩余瓶颈模块,随后是两个卷积层,用ReLU6作为非线性激活层来限制计算量。
5)PeleeNet:以DenseNet为基础,并且加入了双路密集层,stem block,动态数量通道等模块。避免使用压缩因素而造成精度损失。PeLeeNet由一个stem block,四个阶段的改性致密层和过渡层,最后是分类层构成。PeleeNet表现较好,但是慢。
6)ShuffleNetv2:它有4个准则:1、输入输出通道相同以减小内存消耗;2、基于目标精心挑选卷积组;3、多路结果达到高的精确度;4、按元素的操作不能忽略。它通过信道分离层将输入分为两部分,然后是三个卷积层,然后与剩余连接连接并通过信道混洗层。
7)MnasNet:他们将搜索问题表述为以高精度和低延迟为目标的多目标优化。它通过将CNN划分为独特的块,然后分别搜索这些块中的操作和连接,从而缩小搜索空间,从而将搜索空间因子化。这也使得每个块都有独特的设计。
8)MobileNet3:以MnasNet为基准,在因子化的分层搜索空间中执行平台感知的自动神经架构搜索,并因此由NetAdapt进行优化,这在多次迭代中去除了网络中未充分利用的组件。
9)Once-For-All(OFA):首先,训练最大的网络,将所有参数设置为最大值。随后,通过逐渐减小内核大小、深度和宽度等参数维度,对网络进行微调。为了改变深度,使用前几层,其余的从大型网络中跳过。OFA表现好,且计算量小。
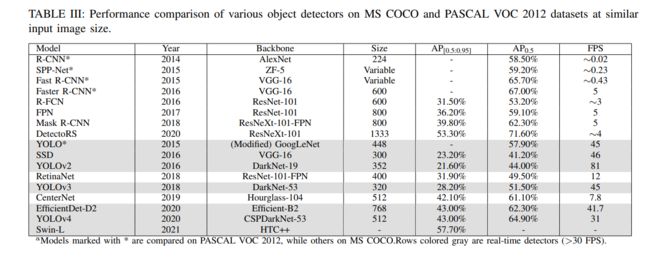
六、比较结果
七、未来趋势
目标识别在过去几十年取得了极大的进展,某些领域已达到人类水平。但是仍有有一些问题需要解决:
1)AutoML:用自动神经结构搜索来设计检测器。
2)轻量化检测器:目前的轻量化检测器精度不高,需要小型的,有效的,精确的模型。
3)弱监督:目前的先进模型资源消耗大,需要检测消耗。
4)领域转移:鼓励训练的模型再利用。
5)3D物体检测:在自动驾驶领域很重要,低于人类的标准都不安全。
6)视频中物体检测:物体检测器被设计时缺乏对相邻图像关系的考虑,在视频中物体检测有很大的用处。
八、总结
过去几十年物体检测走过了很长一段路,但是目前最好的检测器仍不是最理想的,并且轻量化模型的应用需求是指数级的。两阶段检测器越来越准确,但是慢,不能用于实时的需求。单阶段检测器改变了这一现象,使目物体检测能够运用在自动驾驶上。目前Swin Transformer是最准确的检测器,我们仍需要更准确更快的检测器。
参考资料:
如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法
深度学习中的FPN详解
YOLO家族进化史(v1-v7)